
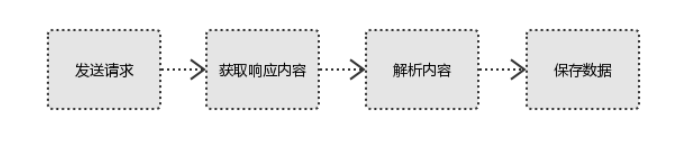
向网站发送http请求,就会拿回一些页面/jason格式的数据(request)
处理数据,解析出需要的数据(惹,bs4)
存储(mysql,文件,cvs,redis,es,mongodb)
分析
#GET请求 HTTP默认的请求方法就是GET * 没有请求体 * 数据必须在1K之内! * GET请求数据会暴露在浏览器的地址栏中 GET请求常用的操作: 1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求 2. 点击页面上的超链接也一定是GET请求 3. 提交表单时,表单默认使用GET请求,但可以设置为POST #POST请求 (1). 数据不会出现在地址栏中 (2). 数据的大小没有上限 (3). 有请求体 (4). 请求体中如果存在中文,会使用URL编码! #!!!requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
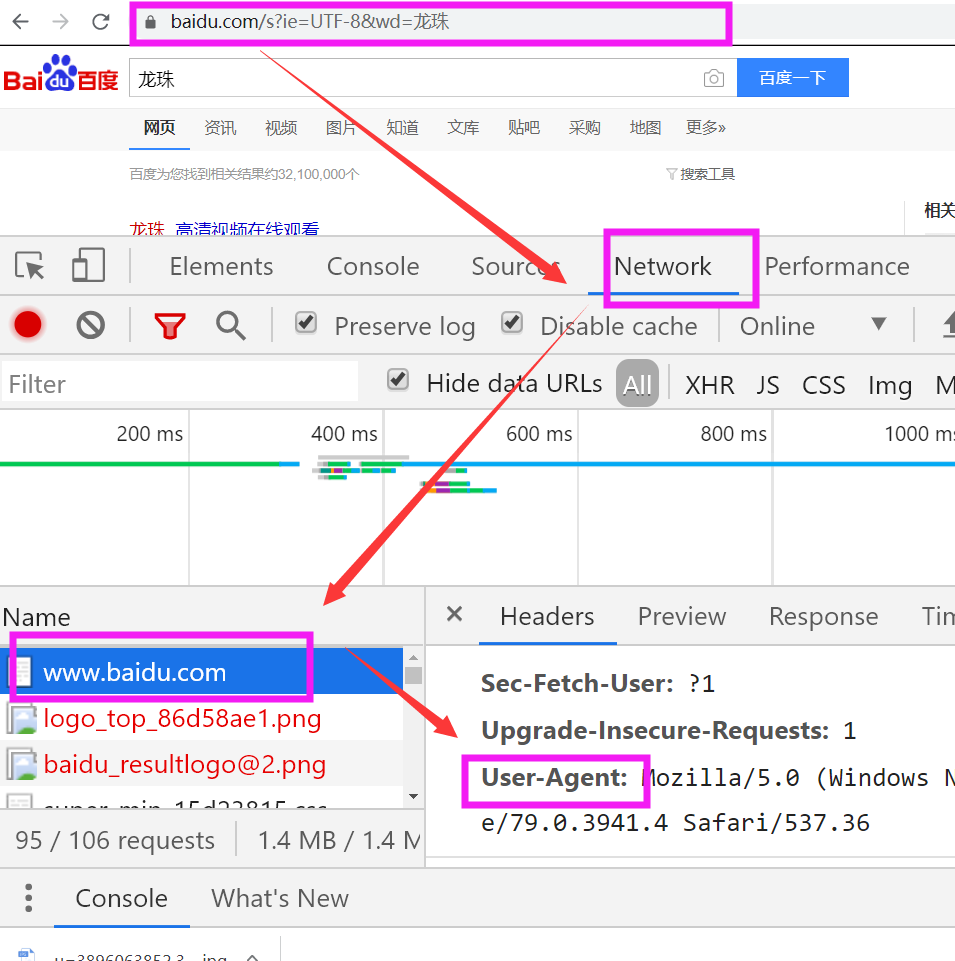
res = requests.get('https://www.baidu.com/s',
params={'wd':'龙珠'},
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36',
'Cookie':'BIDUPSID=EB554F672DACF0CF7F8A80E3DFCBC0AC; PSTM=1566226674; BD_UPN=12314753; BDUSS=dvbH4wVUxRUVowQnlrelZyWHpUaC1nSFVNZTB3cHdRbUl0VjFXWX5YcFR6NFJkSVFBQUFBJCQAAAAAAAAAAAEAAADflCyqZWFydGhteWhvbmV5AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFNCXV1TQl1dSk; BAIDUID=D229E7F2B78BC3ED8BDE85C2FE092B8B:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_WISE_SIDS=130610_137150_137735_138198_138181_137596_114745_135847_120149_138490_133995_137979_132911_137690_131247_132552_137746_136681_118885_118862_118845_118818_118786_137890_107316_136431_133351_137900_136862_138148_136196_124636_131861_137104_133847_138476_138343_137468_134047_137817_138510_137971_136034_110085_127969_137830_138233_138274_128200_136636_137208_138250_138582_137450_138239; H_PS_PSSID=1454_21120_29568_29700_29220_26350; delPer=0; BD_CK_SAM=1; PSINO=3; H_PS_645EC=1de7OVsxMAz0hst%2Fv5rRZB2OCaz1TFEBuKj%2FI8jjyNNnhoE0sunZfd4R%2B9k; BDSVRTM=126',
'Referer':'https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=%E4%B8%83%E9%BE%99%E7%8F%A0%E5%9B%BE%E7%89%87&oq=%25E7%2581%25AB%25E5%25BD%25B1%25E5%25BF%258D%25E8%2580%2585%25E5%259B%25BE%25E7%2589%2587&rsv_pq=df6237cf0000f87f&rsv_t=eb63SHI9vzjE6%2FtAqJglOe22%2FdP5Wq8W2OnTXamN7CiQFFRed10XneNXpzM&rqlang=cn&rsv_enter=1&rsv_dl=tb&inputT=2&rsv_sug3=19&rsv_sug1=19&rsv_sug7=101&bs=%E7%81%AB%E5%BD%B1%E5%BF%8D%E8%80%85%E5%9B%BE%E7%89%87'
},
)
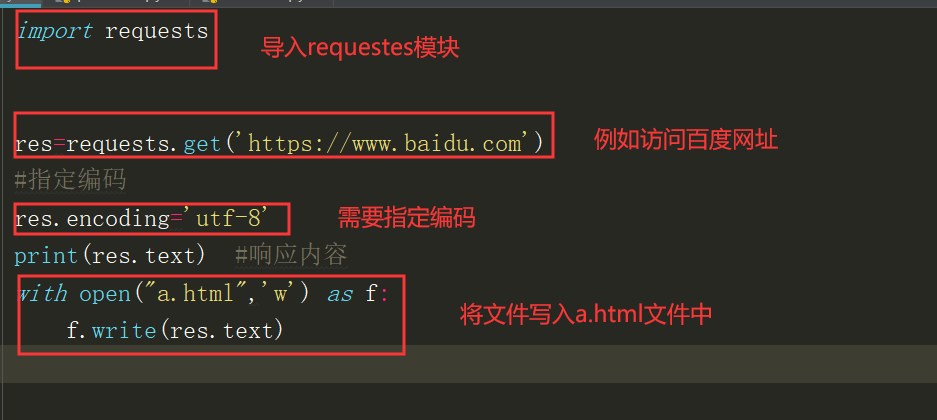
res.encoding = 'utf-8'
print(res.text)
with open("a.html",'w',encoding='utf-8') as f:
f.write(res.text)
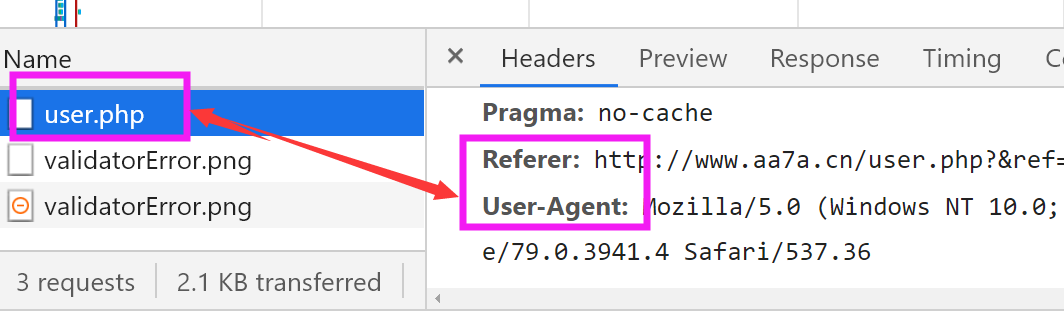
import requests headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36', 'Referer':'http://www.aa7a.cn/user.php?&ref=http%3A%2F%2Fwww.aa7a.cn%2F' } res = requests.post('http://www.aa7a.cn/user.php', headers=headers, data={ 'username':'1356487595@163.com', # 登录的用户名 'password':'5698587592', # 密码 'captcha':'egu2', # 验证码 'remember':1, # 记住密码 'ref':'http://www.aa7a.cn/', # 网站网址 'act':'act_login' # 为登录状态 } ) # 如果登录成功,cookie会存在于res对象中 cookie = res.cookies.get_dict() # 向首页发请求 res = requests.get('http://www.aa7a.cn/', headers=headers, cookies=cookie,) if '1356487595@163.com'in res.text: print('登录成功') else: print('没有登录')

import requests,re res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0') reg_text = '<a href="(.*?)" class="vervideo-lilink actplay">' # 使用“.*?”进行分组 obj = re.findall(reg_text,res.text) # 获取全部内容 print(obj) for url in obj: # 从url中获取对象 url = 'https://www.pearvideo.com/'+url res1 = requests.get(url) obj1 = re.findall('srcUrl="(.*?)"',res1.text) print(obj1[0]) name = obj1[0].rsplit('/',1)[1] print(name) res2 = requests.get(obj1[0]) with open(name,'wb') as f: for line in res2.iter_content(): # stream参数:一点一点的取,比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的 f.write(line)