在爬取一些比较友好的网站时,仍然有可能因为单位时间内访问次数过多,使服务器认定为机器访问,导致访问失败或者被封。如果我们使用不同的ip来访问网站的话,就可以绕过服务器的重复验证,使服务器以为使不同的人在访问,就不会被封了。
如何获取动态ip
网络上有很多提供代理ip的网站,我们经常使用的一个是西刺免费代理ip,url='http://www.xicidaili.com/'
我们来看一下这个网站的构成:
【插入图片,西刺代理页面】
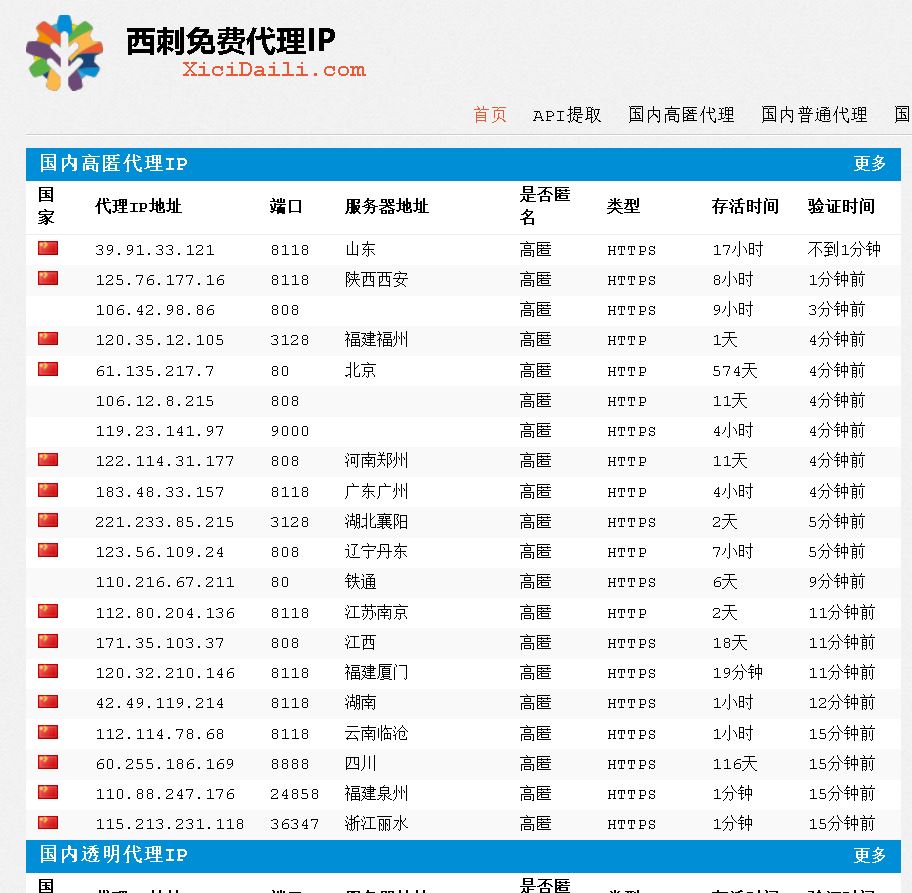
我们获取这个页面上的所有ip即可。
一个合理的代理ip的格式是这样的:
{'http':'http://106.46.136.112:808'}
也就是说每个代理是一个字典,这个字典中可以有很多个ip,每个代理ip都是以http为key。当然考虑到字典的特性,如果我们只获取http为key的代理,那么这个字典中只能有一个元素。
我们就简单点,只考虑http的情况。
通过PyQuery来解析西刺的源代码,所有的ip都在一个tr里面,但是有些tr是标题,我们过滤一下就可以了。
由于页面比较简单,这里就不做介绍了。
如何使用代理ip
我们以requests库为例:
import requests
#这个字典可以只有一个键值对,如果只考虑http的情况
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080"
}
requests.get("http://example.org", proxies=proxies)
全部代码
西刺也是有访问限制的,短时间内多次访问会被封锁,所以最好的办法是每个一个小时访问一下,将所有的代理ip保存到本地。
每次需要ip的时候从本地获取。
在下面的例子中,我们先获取到一个ip池,当然是文本格式的,然后短时间内访问了200次豆瓣主页,都成功了。
import requests
from pyquery import PyQuery
import random
def get_ip_page():
url = 'http://www.xicidaili.com/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
} # 不加请求头信息还不能获取到源代码信息
response = requests.get(url, headers=headers)
try:
if response.status_code == 200:
# print(response.text)
return response.text
except Exception:
print('获取ip出错!')
def parse_save_ip():
html = get_ip_page()
doc = PyQuery(html)
even_ips = doc('tr').items()
result = []
try:
for item in even_ips:
ip = item.find('td').eq(1).text()
port=item.find('td').eq(2).text()
# http=item.find('td').eq(5).text()
# proxy_ip={http:ip}
# result.append(proxy_ip)
if ip != '':
# print(ip)
result.append('http://'+ip+':'+port)
except Exception:
pass
with open('proxy.csv','w') as f:
for item in result:
f.write(item)
def get_random_ip():
#短时间内连续访问多次会被封住,将获取的代理ip存到本地,每个小时获取1次即可。
with open('proxy.csv','r') as f:
ips=f.readlines()
random_ip = random.choice(ips)
proxy_ip = {'http': random_ip}
return proxy_ip
def how_to_use_proxy(proxy):
url='https://www.douban.com/'
webdata=requests.get(url=url,proxies=proxy)
print(webdata)
def main():
proxy = get_random_ip()
print(proxy)
how_to_use_proxy(proxy)
if __name__ == '__main__':
parse_save_ip()
for i in range(200):
main()
print('第%d次访问成功!'%(i+1,))