python编码总结:
1).首先python有两种格式的字符串,str和unicode,其中unicode相当于字节码那样,可以跨平台使用。
str转化为unicode可以通过unicode(),u,str.decode三种方式
unicode转化为str,如果有中文的话,一般通过encode的方式
2).如果代码中有中文的话,我们一般会添加 "# coding=utf-8",这个是什么作用呢,一般如下:
- 如果代码中有中文注释,就需要此声明
- 比较高级的编辑器(比如我的emacs),会根据头部声明,将此作为代码文件的格式。
- 程序会通过头部声明,解码初始化 u”人生苦短”,这样的unicode对象,(所以头部声明和代码的存储格式要一致
所以,当我们填上编码头的时候,使用s="中文",实际上type(s)是一个str,是已经将unicode以utf-8格式编码成str。
其次,如果我们在代码中使用s=u'中文',相当于将str以utf-8解码成unicode.
1 # coding=utf-8 2 __author__ = 'lenovo' 3 4 a='中文' 5 print a,type(a) 6 7 a2=unicode(a,"utf-8") 8 print a2,type(a2) 9 10 a3=u'中文' 11 print a3,type(a3)
这样的输出如下,说明声明头的作用一方面是自动将unicode转化为utf-8,另一方面是使用u的时候指定了utf-8:

3)如果在unicode上面再unicode的话,实际上并没有起到效果
1 a='中文' 2 a2=unicode(a,"utf-8") 3 print a2,type(a2) 4 5 a3=unicode(a2) 6 print a3,type(a3)
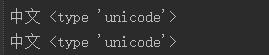
4)u,unicode()和str.decode等价,都可以将str转化成unicode。但是decode不能像unicode()那样连续调用
1 a='中文' 2 a2=unicode(a,"utf-8") 3 a3=a.decode("utf-8") 4 print a2,type(a2) 5 print a3,type(a3)
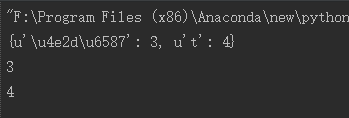
5)当使用map存储的key为中文的时候,可以str转化成unicode才行,这样就可以跨平台
1 a='中文' 2 map={} 3 map[a.decode('utf-8')]=3 4 map[unicode('t')]=4 5 print map 6 print map[u'中文'] 7 print map['t']
6)一个需要注意的点就是ascii码的话,unicode和str等价,也就是unicode('t')=='t'
7)文件操作时,open(filename),要求文件的格式和编码头一致,这样读取后是str类型
如果不一致,可以调用io.open()并且指定编码,这样读取后是unicode