1. 爬取图片并下载
准备工作:
pip install requests
pip install BeautifulSoup4
pip install lxml
目录结构
代码实例:
import os import re from uuid import uuid1 import requests from bs4 import BeautifulSoup from random import choice # 获取随机请求头 def get_headers(): file = open('user_agent.txt', 'r') user_agent_list = file.readlines() user_agent = str(choice(user_agent_list)).replace(' ', '') user_agent = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0' if len( user_agent) < 10 else user_agent headers = { "User-Agent": user_agent, } return headers # 负责下载图片 def download(src, end): try: headers = get_headers() response = requests.get(src, headers=headers) # 获取的文本实际上是图片的二进制文本 img = response.content print(img) path = "images/" + str(uuid1()) + end # 将他拷贝到本地文件 w 写 b 二进制 wb代表写入二进制文本 with open(path, 'wb') as f: f.write(img) except Exception as e: pass # 负责请求页面 def requests_get(url): try: headers = get_headers() # 请求页面 response = requests.get(url, headers=headers) # 解析 soup = BeautifulSoup(response.text, 'lxml') image_list = soup.find_all(attrs={"class": "img-responsive"}) for image in image_list[:-1]: # 获取图片链接 src = image.attrs["data-backup"] # 获取图片后缀 end = os.path.splitext(src)[1] if src and end: # 去除特殊字符 end = re.sub(r'[,。??,/\·]', '', end) # 调用下载函数 download(src, end) else: pass except Exception as e: print(e) pass if __name__ == '__main__': # 负责翻页 for page in range(1, 5): url = 'https://www.doutula.com/photo/list/?page=%d' % page requests_get(url)
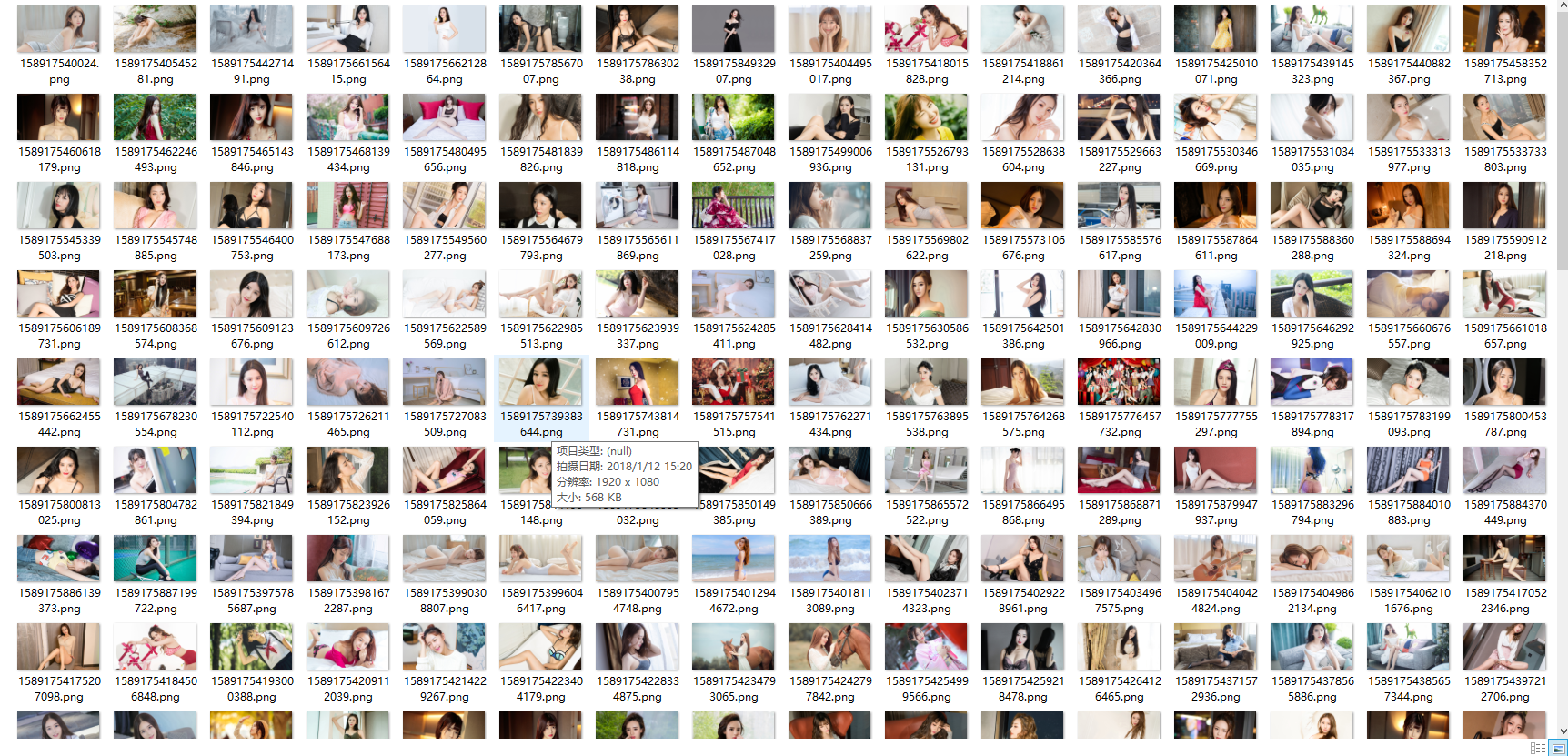
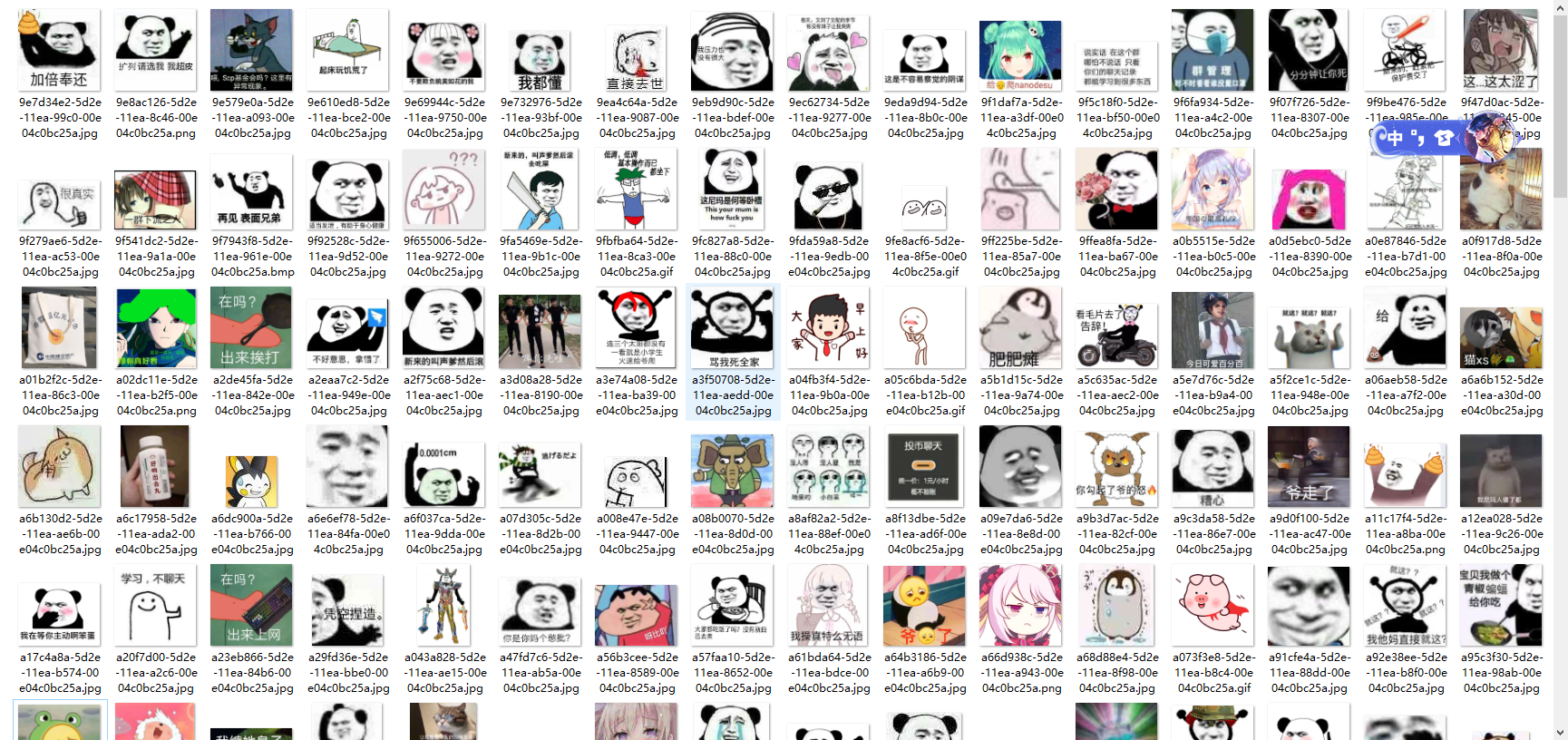
结果:
2. 爬取汽车之家新闻
代码实例:
import requests from bs4 import BeautifulSoup # 请求网页 response = requests.get("https://www.autohome.com.cn/news/") # 设置编码格式 response.encoding = 'gbk' # 页面解析 soup = BeautifulSoup(response.text,'html.parser') # 找到id="auto-channel-lazyload-article" 的div节点 div = soup.find(name='div',attrs={'id':'auto-channel-lazyload-article'}) # 在div中找到所有的li标签 li_list = div.find_all(name='li') for li in li_list: # 获取新闻标题 title = li.find(name='h3') if not title: continue # 获取简介 p = li.find(name='p') # 获取连接 a = li.find(name='a') # 获取图片链接 img = li.find(name='img') src = img.get('src') src = "https:" + src print(title.text) print(a.attrs.get('href')) print(p.text) print(src) # 再次发起请求,下载图片 file_name = src.rsplit('images/',maxsplit=1)[1] ret = requests.get(src) with open(file_name,'wb') as f: f.write(ret.content)
结果:

3. 爬取unsplash图片并下载
目录结构:
代码实例:
# 爬取图片 import time import requests import json # 获取图片列表 def get_image_list(url): response = requests.get(url=url) data_list = json.loads(response.text) for data in data_list: id = data["id"] image_list = [ { "file_path" : "static/images/" + id + "-raw.png", "url": data["urls"]["raw"] }, { "file_path": "static/images/" + id + "-full.png", "url": data["urls"]["full"] }, { "file_path": "static/images/" + id + "-regular.png", "url": data["urls"]["regular"] }, { "file_path": "static/images/" + id + "-thumb.png", "url": data["urls"]["thumb"] }, { "file_path": "static/images/" + id + "-small.png", "url": data["urls"]["small"] } ] for image in image_list: download_image(image) # 下载图片 def download_image(image): print(image) url = image["url"] response = requests.get(url) # 获取的文本实际上是图片的二进制文本 img = response.content # 将他拷贝到本地文件 w 写 b 二进制 wb代表写入二进制文本 with open(image["file_path"],'wb' ) as f: f.write(img) if __name__ == '__main__': for i in range(2,100): url = "https://unsplash.com/napi/photos?page={}&per_page=12".format(i) get_image_list(url) time.sleep(60)
结果:(每个图片有五种大小)
4. 爬取美女壁纸
目录结构:
代码实例:
# 爬取图片 import time import requests from bs4 import BeautifulSoup class Aaa(): headers = { "Cookie": "__cfduid=db706111980f98a948035ea8ddd8b79c11589173916", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36" } def get_cookies(self): url = "http://www.netbian.com/" response = requests.get(url=url) self.headers ={ "Cookie":"__cfduid=" + response.cookies["__cfduid"], "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36" } # 获取图片列表 def get_image_list(self,url): try: response = requests.get(url=url,headers=self.headers) response.encoding = 'gbk' soup = BeautifulSoup(response.text,'lxml') li_list = soup.select("#main > div.list > ul > li") for li in li_list: href = "http://www.netbian.com" + li.select_one("a").attrs["href"] self.get_image(href) except: self.get_cookies() def get_image(self,href): try: response = requests.get(url=href,headers=self.headers) response.encoding = 'gbk' soup = BeautifulSoup(response.text, 'lxml') image_href = "http://www.netbian.com" + soup.select_one("#main > div.endpage > div > p > a").attrs["href"] self.get_image_src(image_href) except: self.get_cookies() def get_image_src(self,href): try: response = requests.get(url=href,headers=self.headers) response.encoding = 'gbk' soup = BeautifulSoup(response.text, 'lxml') src = soup.select("img")[1].attrs["src"] self.download_image(src) except: self.get_cookies() # 下载图片 def download_image(self,image_src): try: title = str(time.time()).replace('.', '') image_path = "static/images/" + title + ".png", image_path = list(image_path) response = requests.get(image_src,headers=self.headers) # 获取的文本实际上是图片的二进制文本 img = response.content # 将他拷贝到本地文件 w 写 b 二进制 wb代表写入二进制文本 with open(image_path[0],'wb' ) as f: f.write(img) except: self.get_cookies() if __name__ == '__main__': aaa = Aaa() aaa.get_cookies() for i in range(2,100): url = "http://www.netbian.com/meinv/index_{}.htm".format(i) aaa.get_image_list(url) time.sleep(10)
结果: