前提
Hadoop可成功在分布式系统下启动
下载scala 链接是https://downloads.lightbend.com/scala/2.12.7/scala-2.12.7.tgz
Master和其他子主机下
wget https://downloads.lightbend.com/scala/2.12.7/scala-2.12.7.tgz
解压
tar -zxvf scala-2.12.7.tgz
将解压后的文件复制到自己的文件路径
cp -r ./scala-2.12.7 /usr/scala
配置环境变量
vim /etc/profile
添加
export SCALA_HOME=/usr/scala
export PATH=$PATH:$SCALA_HOME/bin
执行
. /etc/profile
使之生效,后测试
scala -version
[root@xinglichao sbin]# scala -version
Scala code runner version 2.12.7 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
表示成功
下载Spark 链接是http://mirrors.shu.edu.cn/apache/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2.7.tgz(还有很多镜像可供使用)

在Master主机上使用wget下载
wget http://mirrors.shu.edu.cn/apache/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2.7.tgz
同scala一样,要执行解压,复制到指定文件夹
tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz
cp ./spark-2.3.2-bin-hadoop2.7/* /usr/spark/
进入/usr/spark/conf
配置spark-env.sh和slaves
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
vim spark-env.sh
添加配置
#java路径
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64/jre #scala路径
export SCALA_HOME=/usr/scala
#hadoop路径 export HADOOP_HOME=/usr/hadoop/hadoop-2.7.5 #指向包含Hadoop集群的(客户端)配置文件的目录,运行在Yarn上配置此项 export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.5/etc/hadoop #指定默认master的ip或主机名 export SPARK_MASTER_HOST=xinglichao #指定maaster提交任务的默认端口为7077 export SPARK_MASTER_PORT=7077 #指定masster节点的webui端口 export SPARK_MASTER_WEBUI_PORT=8080 #每个worker从节点的端口(可选配置) export SPARK_WORKER_PORT=7078 #每个worker从节点的wwebui端口(可选配置) export SPARK_WORKER_WEBUI_PORT=8081 #每个worker从节点能够支配的内存数 export SPARK_WORKER_MEMORY=1g #允许Spark应用程序在计算机上使用的核心总数(默认值:所有可用核心) export SPARK_WORKER_CORES=1 #每个worker从节点的实例(可选配置) export SPARK_WORKER_INSTANCES=1
vim slaves
子主机的主机名或者ip
将spark分发到子节点主机
scp /usr/spark/* root@192.168.0.102:/usr/spark/
在Master上启动spark
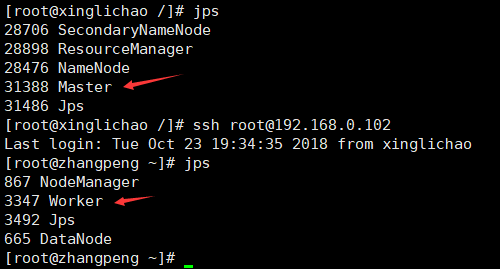
[root@xinglichao sbin]# pwd /usr/spark/sbin [root@xinglichao sbin]# ./start-all.sh starting org.apache.spark.deploy.master.Master, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-xinglichao.out zhangpeng: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-zhangpeng.out [root@xinglichao sbin]#
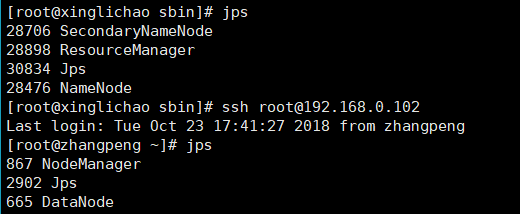
jps查看进程
本节完......