近年来,大数据的计算引擎越来越受到关注,spark作为最受欢迎的大数据计算框架,也在不断的学习和完善中。在Spark2.x中,新开放了一个基于DataFrame的无下限的流式处理组件——Structured Streaming,它也是本系列的主角,废话不多说,进入正题吧!
简单介绍
在有过1.6的streaming和2.x的streaming开发体验之后,再来使用Structured Streaming会有一种完全不同的体验,尤其是在代码设计上。
在过去使用streaming时,我们很容易的理解为一次处理是当前batch的所有数据,只要针对这波数据进行各种处理即可。如果要做一些类似pv uv的统计,那就得借助有状态的state的DStream,或者借助一些分布式缓存系统,如Redis、Alluxio都能实现。需要关注的就是尽量快速的处理完当前的batch数据,以及7*24小时的运行即可。
可以看到想要去做一些类似Group by的操作,Streaming是非常不便的。Structured Streaming则完美的解决了这个问题。
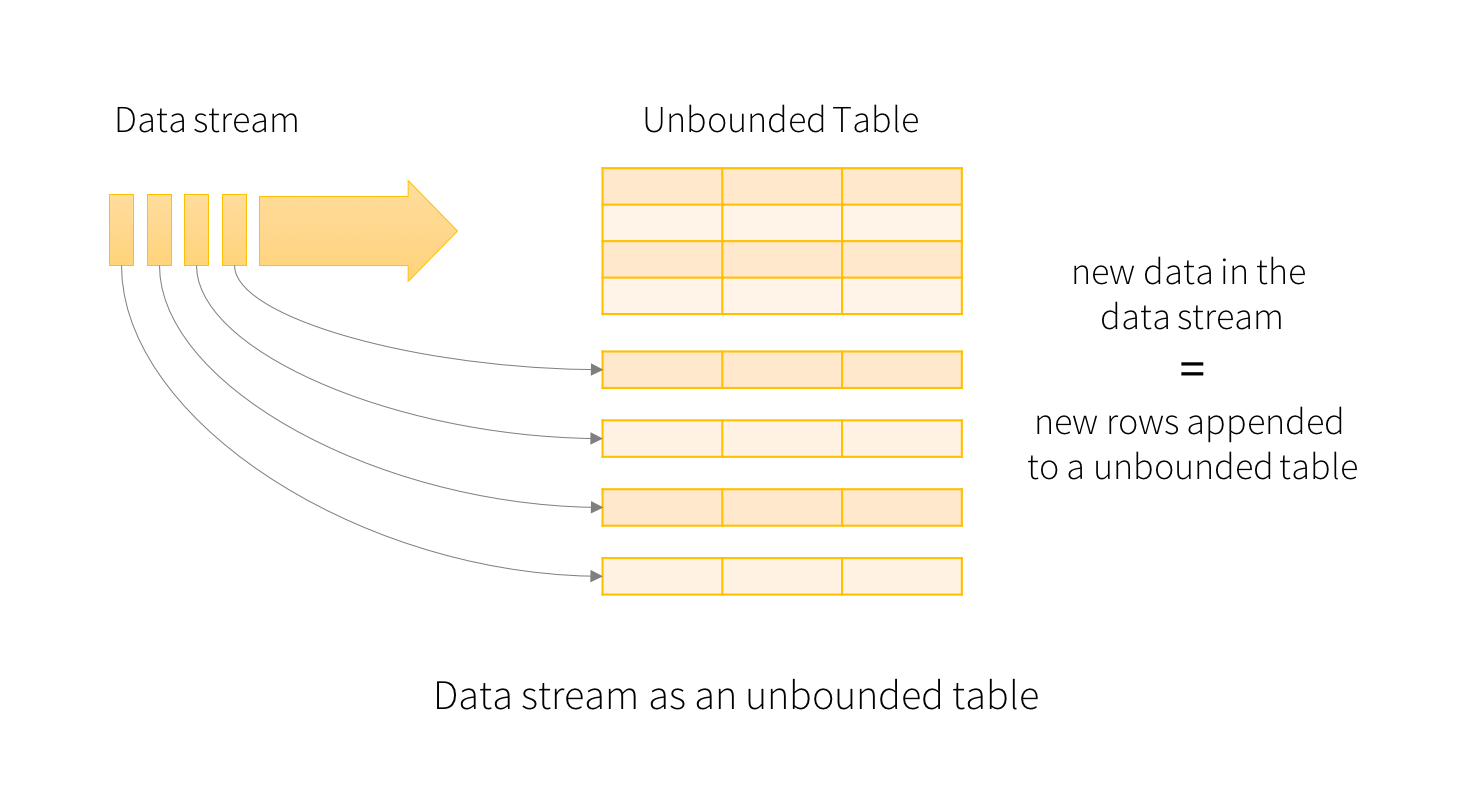
在Structured Streaming中,把源源不断到来的数据通过固定的模式“追加”或者“更新”到了上面无下限的DataFrame中。剩余的工作则跟普通的DataFrame一样,可以去map、filter,也可以去groupby().count()。甚至还可以把流处理的dataframe跟其他的“静态”DataFrame进行join。另外,还提供了基于window时间的流式处理。总之,Structured Streaming提供了快速、可扩展、高可用、高可靠的流式处理。
小栗子
在大数据开发中,Word Count就是基本的演示示例,所以这里也模仿官网的例子,做一下演示。
直接看一下完整的例子:
package xingoo.sstreaming
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local")
.appName("StructuredNetworkWordCount")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
// 创建DataFrame
// Create DataFrame representing the stream of input lines from connection to localhost:9999
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Split the lines into words
val words = lines.as[String].flatMap(_.split(" "))
// Generate running word count
val wordCounts = words.groupBy("value").count()
// Start running the query that prints the running counts to the console
// 三种模式:
// 1 complete 所有内容都输出
// 2 append 新增的行才输出
// 3 update 更新的行才输出
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
}
}
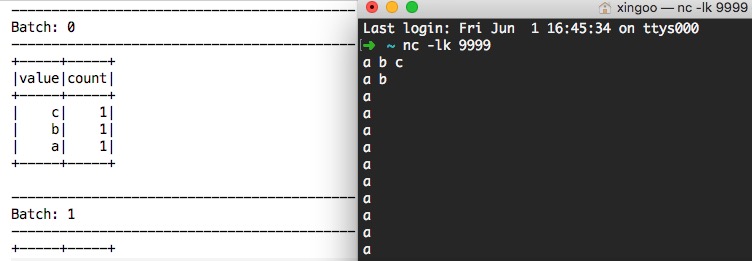
效果就是在控制台输入nc -lk 9999,然后输入一大堆的字符,控制台就输出了对应的结果:
然后来详细看一下代码:
val spark = SparkSession
.builder
.master("local")
.appName("StructuredNetworkWordCount")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
上面就不用太多解释了吧,创建一个本地的sparkSession,设置日志的级别为WARN,要不控制台太乱。然后引入spark sql必要的方法(如果没有import spark.implicits._,基本类型是无法直接转化成DataFrame的)。
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
创建了一个Socket连接的DataStream,并通过load()方法获取当前批次的DataFrame。
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
先把DataFrame转成单列的DataSet,然后通过空格切分每一行,再根据value做groupby,并统计个数。
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
调用DataFrame的writeStream方法,转换成输出流,设置模式为"complete",指定输出对象为控制台"console",然后调用start()方法启动计算。并返回queryStreaming,进行控制。
这里的outputmode和format都会后续详细介绍。
query.awaitTermination()
通过QueryStreaming的对象,调用awaitTermination阻塞主线程。程序就可以不断循环调用了。
观察一下Spark UI,可以发现程序稳定的在运行~

总结
这就是一个最基本的wordcount的例子,想象一下,如果没有Structured Streaming,想要统计全局的wordcount,还是很费劲的(即便使用streaming的state,其实也不是那么好用的)。