python基础和pycharm使用
1.pycharm
1.1 为特定格式文件添加头信息
File--Settings--Editor--File and Code Templates--Python Script:
"""
===============
author:${USER}
time:${DATE}
E-mail:1399892035@qq.com
===============
"""
${PROJECT_NAME} - 当前Project名称;
${NAME} - 在创建文件的对话框中指定的文件名;
${USER} - 当前用户名;
${DATE} - 当前系统日期;
${TIME} - 当前系统时间;
${YEAR} - 年;
${MONTH} - 月;
${DAY} - 日;
${HOUR} - 小时;
${MINUTE} - 分钟;
${PRODUCT_NAME} - 创建文件的IDE名称;
${MONTH_NAME_SHORT} - 英文月份缩写, 如: Jan, Feb, etc;
${MONTH_NAME_FULL} - 英文月份全称, 如: January, February, etc;
1.2 Directory和Package的区别(__init__文件)
Package会多了一个_init_.py文件,说明该目录下的py文件可以当做模块被其他py文件导入
使用模块的好处:避免函数名和变量名冲突;实现代码复用;
使用包的好处:避免模块名冲突,实现代码复用;
_init_.py文件的用处:
(1)用于标志一个文件夹是一个python包
(2)通过定义_all_ 变量定义模糊导入时from package import *要导入的内容,_
注意__all__只能定义通过import * 的方式导入的变量,对from package.module import obj 不起作用!
# 在pakcage1里面有module1(func1, func2), module2, module3模块,在package2要导入
from package1 import module1, module2, module3
# 有时偷懒会写成,虽然pep8不推荐,这种方式会导入所有非下划线开头的方法和变量
from package1 import *
# 如果有些非下划线开头的方法和变量也不想被导入,可以在模块里面和包的__init__.py文件定义__all__,把允许import的对象暴露出来。譬如不允许导入module1的func1,和module3
# module1.py里面加上
__all__ = ['func1', 'func2']
# package1的__init__.py文件,这样就无法通过from package1 import *的方式导入module3,但仍可通过from package1 import module3导入
__all__ = ['module1','module2']
(3)简化导入一个包里面的模块的类的导入语句
# 在package2里面的moudle2中需要导入package1包下的模块包module_package1下的一个模块module1的一个类class1
from package1.module_package1.module1 import class1
# 如果我们在module_package1的__init__.py文件里写了
from module1 import class1
# 那在在package2的module2导入class1就可以写为(少写一个模块名)
from package1.module_package1 import class1
1.3 删除项目
在pycharm里关闭项目,然后去项目所在磁盘位置,删除项目文件
1.4 快捷键
https://blog.csdn.net/weixin_37292229/article/details/81737194
运行py文件:ctrl + shift + F10
调试模式: shift + F9
自动调整为pip8规范:ctrl + shift + alt + l
注释:ctrl + /
展开代码:ctrl + shift + +
收缩代码:ctrl + shift + -
批量缩进(或名"对齐")
缩进:Tab
反向缩进:Shift+Tab
1.5 venv虚拟环境
pycharm为python3提供了虚拟环境,每个虚拟环境里面的第三方库是隔离的,为支持多版本python在同一个机器上开发或运行时的版本兼容。deactivate 退出venv的终端
1.6 pip安装第三方库
修改源为国内镜像地址,加速下载
一次性指定源: -i https://pypi.tuna.tsinghua.edu.cn/simple
永久修改:
linux下,修改 ~/.pip/pip.conf (没有就创建一个), 修改 index-url 为国内镜像地址,内容如下:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
windows下,直接在user目录中创建一个pip目录,如:C:Usersxxpip,新建文件pip.ini,内容如下
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
pip install lib_name
# 其他命令
list
download
uninstall
show
check
search
2.python 基础
2.1 命名规范
命名规范:以字母或下划线开头,由字母,下划线或数字组成.尽量以字母开头,不能是python的关键字,注意下划线开头是有特殊意义的,谨慎使用。
# 查询python关键字
from keyword import kwlist
print(kwlist)
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
命名方式:
- 蛇形:student_name
- 大驼峰:StudentName
- 小驼峰 : studentName
变量名、方法名、模块一般用小写,蛇形,常量用全大写;类名用大驼峰
下划线开头都是有特殊意义的,一般不用,要结合场景
2.2 引号和反斜杠
单引号跟双引号没有区别:当字符串中含有单引/双引,则外层可以用双引/单引括起
三引号2个用处:
(1)保持文本格式,如换行,如字符串即有单引又有双引
(2)表示注释
双引号内换行拼接:加“”后换行,打印出来不会换行,代码不会太长
反斜杠用法
- 用于把后面的字符串转成特殊意义,如n前面加 ,即 ,表示换行符
- 把特殊字符转成普通字符串,如 前面加,即\n 表示n。
- r+字符串,表示不转义,注意r原生字符从不能以奇数个结尾,否则会报错
2.3 数据类型
type(str1) 返回数据类型
isinstance(a, type) 判断a是不是type类型的数据
可变/不可变类型
原文地址:http://www.cnblogs.com/huamingao/p/5809936.html
可变类型 Vs不可变类型
可变类型(mutable):列表,字典
不可变类型(unmutable):数字,字符串,元组
这里的可变不可变,是指内存中的那块内容(value)是否可以被改变
一句话判断最小数:x if x<y and x<z else y if y<z else z
2.3.1 数值
1. 类型
- 整型 int
小整数池:-5~256,该范围内的变量预先创建好的变量。(在pycharm里面看不到下面的效果,因为pycharm做了更大的整数池)。
通过id查看内存地址是否执行同一个地址。== 用于判断值是否相等,is判断是否同一内存地址
>>> a=100
>>> b=100
>>> id(a)
140708647059376
>>> id(b)
140708647059376
>>> a==b
True
>>> a is b
True
>>> c=1000
>>> d=1000
>>> id(c)
2349952671472
>>> id(d)
2349952671280
>>> c == d
True
>>> c is d
False
-
浮点型 float
关于精度
1.可以使用round(float_num, num) 确定精度
2.用math的ceil和floor方法上下取整
3.用更高精度的模块decimal
4.用format格式化输出时指定精度
In [3]: a=21.2345 In [4]: round(a,2) Out[4]: 21.23 2、%nf In [5]: b = '%.2f'%a In [6]: b Out[6]: '21.23' In [7]: b = float('%.2f'%a) 3、'{.%2f}'.format() In [10]: b = '{:.2f}'.format(a) In [11]: b Out[11]: '21.23' -
布尔类型 bool
True:长度不为空的字符的布尔值都是True,注意首字母大写
False:None, 0, '', ' ', [],{},()
-
复数complex
2. 运算符
算术运算符:+ - * / // % **
赋值运算符:= += -= *= /=
比较运算符:> < >= <= == !=
逻辑运算符:and or not
成员运算符:in , not in (数值类型不支持)
身份运算符:is , not is (判断2个标识符是否引用同一个对象,是否指向同一块内存)
优先级:算术可用()括起表示优先计算
a/b 完整结果
a//b 结果取整
a%b 结果取余
3. random模块
randint(a, b) 返回a~b之间的随机整数,包含a和b
random() 返回0-1之间的随机小数,不包含1
uniform(a, b) 返回a~b之间的随机小数,底层通过random()实现
choice(seq) 返回seq可迭代对象里面的元素
2.3.2 字符串
1. 索引与切片
索引: 字符串支持下标索引,从左到右是从0开始,从右往左是从-1开始
切片: 取头不取尾,左闭右开,支持设置步长
拼接:字符串可以用+拼接,用*表示倍数
>>> str1='abcdefg'
>>> str1[0]
'a'
>>> str1[2]
'c'
>>> str1[-1]
'g'
>>> str1[1:]
'bcdefg'
>>> str1[1:3]
'bc'
>>> str1[1:7:3]
'be'
>>> str1[::-1]
'gfedcba'
>>> str2='123'
>>> str1+str2
'abcdefg123'
>>> str1*2
'abcdefgabcdefg'
2. 常用方法
注意,字符串是不可变数据类型,所有操作都不会修改原字符串
‘-’.join(str) 在iterable中间插入短横线,返回替换后的字符串
str.find(sub) 返回sub的下标,如不存在,返回-1
str.index(sub) 返回sub的下标,如不存在,抛出异常
str.split('sub'[,count]) 对str根据sub进行切割,默认是根据空格,换行符,制表符进行切割
str.strip() 去除头尾的空白字符
str.replace(old, new[,count]) 替换字符
>>> str1='abcdefg'
>>> str1[0]
'a'
>>> str1[2]
'c'
>>> str1[-1]
'g'
>>> str1[1:]
'bcdefg'
>>> str1[1:3]
'bc'
>>> str1[1:7:3]
'be'
>>> str1[::-1]
'gfedcba'
>>> str2='123'
>>> str1+str2
'abcdefg123'
>>> str1*2
'abcdefgabcdefg'
>>> '-'.join(str1)
'a-b-c-d-e-f-g'
>>> str1
'abcdefg'
>>> str3='11 A2 3A3
4A4'
>>> str3.split()
['11', 'A2', '3A3', '4A4']
>>> str3
'11 A2 3A3
4A4'
>>> str3.split('A')
['11 ', '2 3', '3
4', '4']
3. 格式化输出
format 强大的格式化输出,用{}占位,%的占位濒临淘汰
-
占位
>>> str = '{}是一个{}岁的姑娘'.format('Ana',18) # 用花括号占位,按顺序 >>> str 'Ana是一个18岁的姑娘' >>> str = '今天是{2}年{1}月{0}日'.format(30,5,2019) # 花括号里面用数字可以指定顺序替换 >>> str '今天是2019年5月30日' >>> str = '{city}今天温度{temperature}度'.format(city='北京',temperature=34) # 指定key >>> str '北京今天温度34度' >>> str = '{0[1]}里面我最喜欢吃{1[3]}'.format(['零食','水果'],['薯片','橙子','牛肉干','葡萄']) >>> str '水果里面我最喜欢吃葡萄' -
补齐
>>> str = '{:a>10d}'.format(12345) # 右对齐,不够10位用a补齐 >>> str 'aaaaa12345' >>> str = '{:b<10d}'.format(12345) # 左对齐,不够10位用b填补 >>> str '12345bbbbb' >>> str = '{:^10}'.format(12345) # 居中,长度为10 >>> str ' 12345 ' -
格式化数字
>>> str = '{:.2f}'.format(12312.123123) # 保留小数点后2位 >>> str '12312.12' >>> str = '{:.2%}'.format(12312.123123) # 转化成百分号并保留2位小数 >>> str '1231212.31%'
2.3.3 列表
可变数据类型,元素也可以是可变的其他数据类型
1. 索引与切片
同字符串
>>> li = [1, 2, 3, 4]
>>> li[1]
2
>>> li[2:4]
[3, 4]
>>> li[-1]
4
>>> li[::-1]
[4, 3, 2, 1]
2. 常用方法
# 查找
>>> li
['b', 1, 4, 'b', 3, 10, (0, 1, 2), ['hello', 'world'], {'key1': 'value1', 'key2': 'value2'}, {1, 2, 3, 4, 5}, 'c', 0, 0]
>>> li.index('b')
0
>>> li.count('b')
2
# 增加
>>> li.insert(2, 'haha') # 在指定位置插入一个元素
>>> li
['b', 1, 'haha', 4, 'b', 3, 10, (0, 1, 2), ['hello', 'world'], {'key1': 'value1', 'key2': 'value2'}, {1, 2, 3, 4, 5}, 'c', 0, 0]
>>> li.append('last') # 追加到尾部
>>> li
['b', 1, 'haha', 4, 'b', 3, 10, (0, 1, 2), ['hello', 'world'], {'key1': 'value1', 'key2': 'value2'}, {1, 2, 3, 4, 5}, 'c', 0, 0, 'last']
>>> li.extend([1,2]) # 在尾部追加另一个列表的元素
>>> li
['b', 1, 'haha', 4, 'b', 3, 10, (0, 1, 2), ['hello', 'world'], {'key1': 'value1', 'key2': 'value2'}, {1, 2, 3, 4, 5}, 'c', 0, 0, 'last', 1, 2]
# 删除
>>> li.pop() # pop默认移除最后一个元素
2
>>> li
['b', 1, 'haha', 4, 'b', 3, 10, (0, 1, 2), ['hello', 'world'], {'key1': 'value1', 'key2': 'value2'}, {1, 2, 3, 4, 5}, 'c', 0, 0, 'last', 1]
>>> li.pop(3) # pop可指定下标移除元素
4
>>> li
['b', 1, 'haha', 'b', 3, 10, (0, 1, 2), ['hello', 'world'], {'key1': 'value1', 'key2': 'value2'}, {1, 2, 3, 4, 5}, 'c', 0, 0, 'last', 1]
>>> li.remove('b') # remove移除指定元素
>>> li
[1, 'haha', 'b', 3, 10, (0, 1, 2), ['hello', 'world'], {'key1': 'value1', 'key2': 'value2'}, {1, 2, 3, 4, 5}, 'c', 0, 0, 'last', 1]
>>> li.clear() # 清空列表的元素
>>> li
[]
>>> del li # 删除对象引用
>>> li
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'li' is not defined
# 其他
>>> li1 = li.copy() # 复制列表的元素,会另外开辟一个内存空间
>>> li2 = li # 直接复制,使用同一个内存空间
>>> id(li1)
3020011212488
>>> id(li)
3020011212424
>>> id(li1)
3020011212488
>>> id(li2)
3020011212424
>>> li3 =[1,2,'a','b']
>>> li3.sort() # 排序,不支持不同类型数据的排序
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'str' and 'int'
>>> li3=['a','d','b']
>>> li3.sort() # 默认是升序
>>> li3
['a', 'b', 'd']
>>> li3.sort(reverse=True) # 可指定降序
>>> li3
['d', 'b', 'a']
2.3.4 元组
不可变序列
1.索引与切片
同字符串,列表操作
2.常用方法
>>> tup1 = (1,2,3,'a')
>>> tup1
(1, 2, 3, 'a')
>>> tup1.index(2)
1
>>> tup1.count(3)
1
2.3.5 字典
可变序列,python3.7后字典在底层存储是有序的,键值对形式,键唯一且不可变
1.支持键索引
>>> food = {'fruit':'apple', 'vegetable':'carrot','meat':'meat'}
>>> food['fruit']
'apple'
>>> food.get('fruit')
'apple'
>>> food['haha']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'haha'
>>> food.get('haha')
2.相关方法
>>> food = {'fruit':'apple', 'vegetable':'carrot','meat':'meat'}
# 增加
>>> food.update({'snacks':'chips'}) # 插入一个字典
>>> food
{'fruit': 'apple', 'vegetable': 'carrot', 'meat': 'meat', 'snacks': 'chips'}
# 修改
>>> food.setdefault('drinks','juice') # 设置key默认值,不存在值插入该key
'juice'
>>> food
{'fruit': 'apple', 'vegetable': 'carrot', 'meat': 'meat', 'snacks': 'chips', 'drinks': 'juice'}
# 查询
>>> food.get('fruit') # 获取某个key的值,如不存在返回空,不会抛出异常
'apple'
>>> food.keys() # 返回所有key
dict_keys(['fruit', 'vegetable', 'meat', 'snacks', 'drinks'])
>>> food.values() # 返回所有值
dict_values(['apple', 'carrot', 'meat', 'chips', 'juice'])
>>> food.items() # 返回键值组成的元组列表
dict_items([('fruit', 'apple'), ('vegetable', 'carrot'), ('meat', 'meat'), ('snacks', 'chips'), ('drinks', 'juice')])
>>> food1 = food.copy() # 拷贝字典的所有元素
>>> food1
{'fruit': 'apple', 'vegetable': 'carrot', 'meat': 'meat', 'snacks': 'chips', 'drinks': 'juice'}
# 删除
>>> food.pop() # pop必须指定key
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: pop expected at least 1 arguments, got 0
>>> food.pop('meat') # 移除指定key
'meat'
>>> food
{'fruit': 'apple', 'vegetable': 'carrot', 'snacks': 'chips', 'drinks': 'juice'}
>>> food.popitem() # 移除最后一个元素,python3.7支持
('drinks', 'juice')
>>> food
{'fruit': 'apple', 'vegetable': 'carrot', 'snacks': 'chips'}
>>> food.clear() # 清除所有元素
>>> food
{}
>>> del food # 删除对象
>>> food
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'food' is not defined
2.3.6 集合
可变类型,无序,元素唯一,一般用于去除重复元素
常用方法
>>> set1 = {1,2,'a',2,3,'b','a'} # 用花括号括起
>>> set1
{1, 2, 3, 'a', 'b'}
# 添加
>>> set1.add(4) # 添加单个元素
>>> set1
{1, 2, 3, 4, 'a', 'b'}
>>> set1.add(1)
>>> set1
{1, 2, 3, 4, 'a', 'b'}
>>> set1.update({1,2,3}) # 把另一个集合的元素加到本集合
>>> set1
{1, 2, 3, 4, 'a', 'b'}
# 删除
>>> set1.pop() # 随机删除一个元素
1
>>> set1
{2, 3, 4, 'a', 'b'}
>>> set1.remove(3) # 删除某个额元素
>>> set1
{2, 4, 'a', 'b'}
>>> set1.remove(333) # remove不存在的元素会报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 333
>>> set1.discard(333) # discard删除不存在的元素不会报错
>>> set1.clear() # 清空元素
>>> set1
set()
>>> del set1 # 删除对象
>>> set1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'set1' is not defined
3.关于编码格式
1.7 编码格式
https://zhuanlan.zhihu.com/p/67865867
https://zhuanlan.zhihu.com/p/25148581
python2默认是ASCII编码,因为python2比unicode出现得早,所以默认是ASCII编码,不支持中文,需要加上在文件头加上coding=utf8才能处理中文。
python3默认使用utf8编码。
概念
字节
计算机存储单元,一个字节byte等于8个比特
字符
信息单元,英文字符、数字、中文都是成为一个字符
字符集
包含字符的集合成为字符集,如ASCII字符集只包含了127个字符,包括数字,字母和一些符号,不包含中文;GB2312包含7000多个中文,GBK包含2万多个中文
字符码
字符集里面的字符的序号。如ASCII字符集里面字母a的序号是97
字符编码
字符集里的字符到字节流的映射,如ASCII字符集里面的字母a的序号是97,字节流编码即转成二进制,单字节表示是0X51,写入存储设备时是b'01100001'
编码和解码
把字符转换成字节流就是编码过程,把字节流转成字符就是解码过程。不同的编码方式,把不同字符当不同字节处理,如ASCII都是单字节,utf8是可变长字节,unicode2是双字节,unicode4是4个字节。
ASCII编码
较早出现的编码格式,一个字节(8个比特)表示一个字符(没有中文),总共127个字符,小于2的7次方,用7个二进制表示,称为基础ASCII,第8个二进制用于扩展。但由于各国的扩展不统一导致传输很混乱。
ASCII表
-
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(振铃)等。通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;
-
ASCII值为 8、9、10 和 13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响。
-
32~126(共95个)是字符(32sp是空格),其中48~57为0到9十个阿拉伯数字;
-
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等
GB2312,GBK
中国人定义的双字节字符编码GB2312,收纳了7000多个中文,兼容ASCII。GBK是在GB2312的基础上扩展了,包括少数民族文字,英文字符用一个字节表示,中文字符用2个字节表示。但是GBK只能解决中国人使用的问题,全世界流通问题仍存在,于是出现了Unicode
Unicode
为了解决传统字符编码局限而产生,对世界上大部分文字系统进行编码,整理,可以容纳100多万个符号,使电脑可以更方便处理和展示文字。
采用16位编码空间,每个字符占2个字节。Unicode实现方式成为Uincode转换格式,扩展自ASCII码。Unicode有2种格式,UCS-2和UCS-4,因为全世界远不止65535种字符,所以UCS-4定义用4个字节表示一个字符。
但由于固定了字符使用字节长度,造成了浪费,如字母并不需要2个字节。
而且有些是用2个字节,有些是4个字节,存到计算机都是0和1的数字串,无法分别是这4个字节是表示两个英文字符还是一个中文字符。
所以有了后面的utf8
UTF-8
utf8是unicode的一种实现方式,一种变长的字符编码,根据规则用1-4个字节来表示一个字符,如英文是1个字节,中文是3个字节。
utf8规定:对于多字节的字符,第一个字节的前n位是1,第n+1位设为0,后面字节的前两位为10.剩余的二进制位全部用该字符的unicode码填充
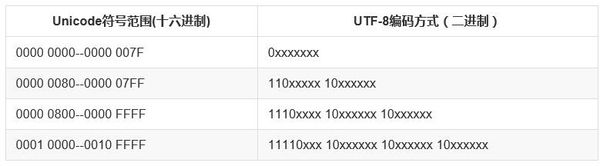
以『好』为例,『好』对应的 Unicode 是597D,对应的区间是 0000 0800—0000 FFFF,因此它用 UTF-8 表示时需要用3个字节来存储,597D用二进制表示是: 0101100101111101,填充到 1110xxxx 10xxxxxx 10xxxxxx 得到 11100101 10100101 10111101,转换成16进制是 e5a5bd,因此『好』的 Unicode 码 U+597D 对应的 UTF-8 编码是 “E5A5BD”。你可以用 Python 代码来验证:
>>> a = u"好"
>>> a
u'u597d'
>>> b = a.encode('utf-8')
>>> len(b)
3
>>> b
'xe5xa5xbd'
```