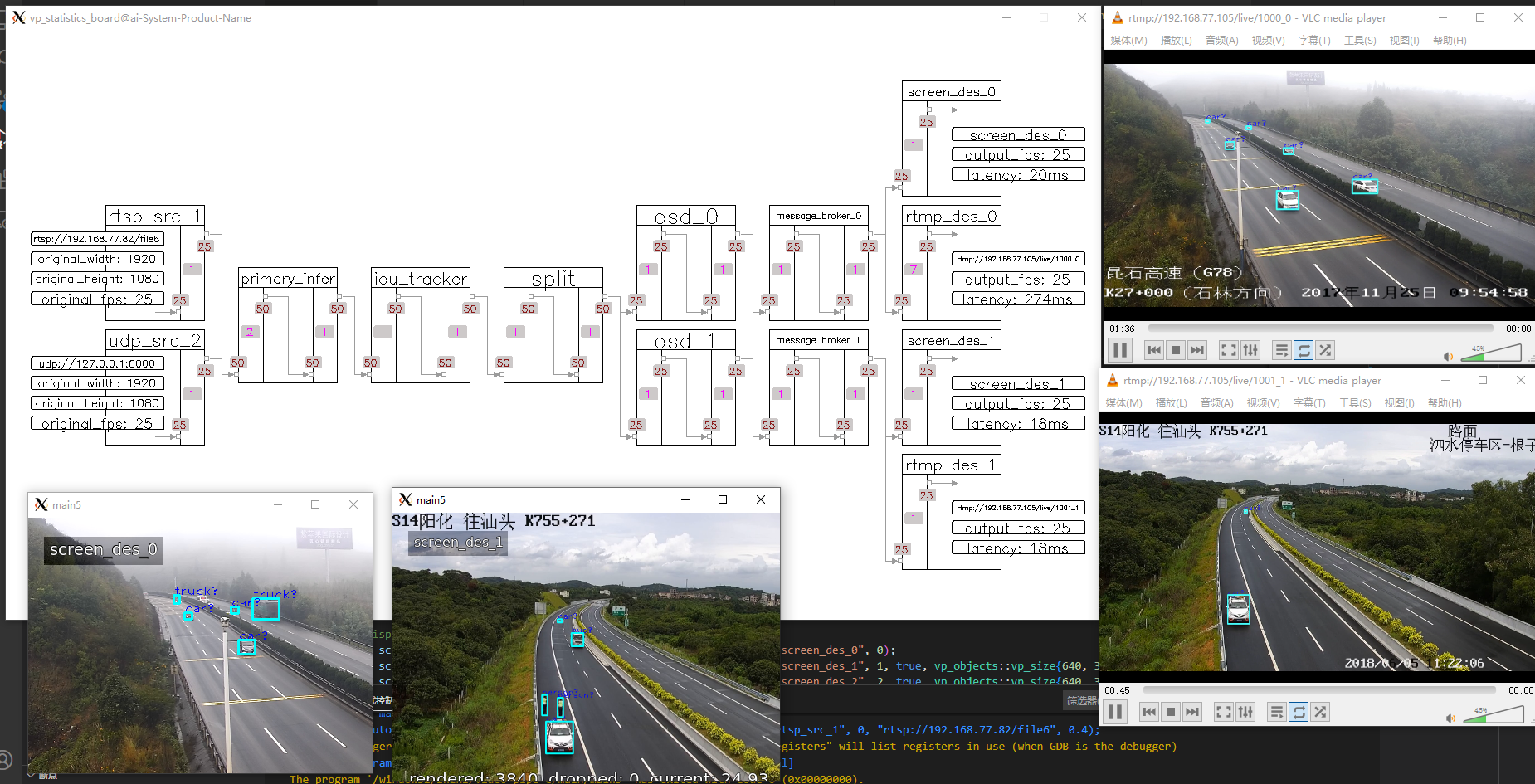
完成多路视频并行接入、解码、多级推理、结构化数据分析、上报、编码推流等过程,插件式/pipe式编程风格,功能上类似英伟达的deepstream和华为的mxvision,但底层核心不依赖复杂难懂的gstreamer框架(少部分地方需要),框架主干部分主要使用原生C++ STL实现,目标是平台高可移植性。框架可用于:视频结构化、以图搜图、目标行为分析等应用领域。
源码地址:https://github.com/sherlockchou86/video_pipe_c
主要功能
- 视频接入,支持file/rtsp/udp/rtmp等主流视频流协议;
- 多级推理,自带检测/分类/特征提取等推理插件。默认使用opencv.dnn实现,可基于其他类似tensorrt、甚至原生的pytorch/tensorflow扩展新的推理插件;
- 目标跟踪,自带基于iou的跟踪插件,可基于其他算法扩展新的跟踪插件;
- 行为分析,自带若干行为分析插件,比如目标跨线、拥堵/目标聚集判断;
- 图像叠加,结构化数据和视频融合显示;
- 消息推送,自带基于kafka的消息推送插件,可基于其他消息中间件扩展新的插件;
- 录像/截图,自带截图/录像插件;
- 编码输出,支持file/screen/rtmp/rtsp等主流方式输出编码结果;
主要特点
- 可视化调试,自带pipe可视化功能,可在界面实时显示pipe的运行状态,如pipe中各个环节的fps/缓存队列大小,以及计算pipe起/止插件之间的时间延时,帮助程序员快速定位性能瓶颈位置;
- 插件与插件之间默认采用“smart pointer”传递数据,数据从头到尾,只需创建一次,不存在拷贝操作。当然,可根据需要设置“深拷贝”方式在插件之间传递数据;
- pipe中各通道视频的fps、分辨率、编码方式、来源均可不同,并且可单独暂停某一通道;
- pipe中可传递的数据只有两种,一种frame_meta数据、一种control_meta数据,结构清晰明了;
- 插件组合方式自由,在满足客观逻辑的前提下,可合并、可拆分,根据需要设计不同的pipe结构。同时自带pipe结构检查功能,识别出不合规的pipe结构;
- pipe支持各种hook,外部通过hook可以实时获取pipe的运行情况(第1点就是基于该特性实现);
- 支持一个Pipe处理多路视频(多路共用一个推理模型,Pipe分支涉及到merge和split操作),批处理提速;也支持一个Pipe只处理一路视频(各路使用自己的推理模型,Pipe呈直线状、多个Pipe并存),基于不同视频做不同的推理任务;
- 基于指定基类,所有自带插件全部可自定义重新实现;
- 框架主干代码完全基于原生C++ STL实现,跨平台编译部署简单。
目前进度
开发环境:vs code/ubuntu 18.04/C++17/opencv 4.6/ffmpeg 3.4.8/gstreamer 1.20。之前使用wsl1/2+ubuntu22.04,但是wsl坑太多,后放弃。
- 2022/9/30:完成基于tensorrt的检测插件(一级推理和二级推理),非默认的opencv::dnn。源码上线
- 2022/9/15:完成基于paddle的ocr文字识别相关插件,基于paddle推理库(非默认的opencv::dnn)
- 2022/9/1:完成基于yunet/sface的人脸检测、识别以及显示相关插件开发,实现多pipe并行运行的机制,多个pipe可加载不同模型、基于不同视频完成不同的推理任务。(单个pipe接入多路视频、共用相同的模型之前已实现)
- 2022/8/15:完成openpose肢体检测器相关插件开发,完成图像二级分类插件开发。
- 2022/8/5:完成infer相关基类、yolo检测器派生类的实现,走通整个一级推理流程,rtmp/screen 2种输出。
- 2022/7/22:已完成主干框架开发,预估占总体进度的1/3。等基本完成后开源,有兴趣的朋友可以关注。