数据的标准化
数据标准化就是将不同取值范围的数据,在保留各自数据相对大小顺序不变的情况下,整体映射到一个固定的区间中。根据具体的实现方法不同,有的时候会映射到 [ 0 ,1 ],有时映射到 0 附近的一个较小区间内。
这样做的目的是消除数据不同取值范围带来的干扰。
数据标准化的方法,我在这里介绍两种
- min-max标准化
min-man 标准化会把结果映射到 0 与 1 之间,下面是映射的公式。
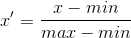
min 是整个样本的最小值,max是整个样本的最大值
- Z-score标准化
Z-score会把结果映射到 0 附近,并服从标准正态分布(平均值为 0,标准差为1),下面是映射的公式
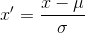
μ 是样本的平均值,σ 是样本的标准差,这些在python中都有函数支持,不用担心计算的问题。
数据的哑编码
哑编码是处理离散型数据的手段。离散型数据的取值范围是有限的(严格在数学上的定义中,无限但可数也就是 countably infinite 的取值空间也属于离散型,但在实际问题中不会碰到,这里不作考虑),比如说星期几就是一个离散型数据,因为一周只有七天,也就只有七种可能的取值。在处理这样的数据的时候,哑编码会把一列数据转换成多列,有多少中可能的取值就转换成多少列。在刚刚提到的星期几的例子中,哑编码会把这一列数据转换成七列数据。
那具体是如何转换的呢?
还是从星期几的例子开始讲
| 编号 | 星期几 |
| 0 | 星期二 |
| 1 | 星期一 |
| 2 | 星期五 |
| 3 | 星期日 |
| 4 | 星期三 |
| 5 | 星期六 |
| 6 | 星期四 |
| 7 | 星期日 |
| 8 | 星期二 |
| 9 | 星期四 |
假设我们有这样的十条数据,现在数据除了编号以外只有一个字段——“星期几”。
哑编码会讲这一个字段扩展成七个字段,也就是七列,每一个新的字段代表原来字段的一种取值,现在表格变成了
| 编号 | 星期几 | 星期一 | 星期二 | 星期三 | 星期四 | 星期五 | 星期六 | 星期日 |
| 0 | 星期二 | |||||||
| 1 | 星期一 | |||||||
| 2 | 星期五 | |||||||
| 3 | 星期日 | |||||||
| 4 | 星期三 | |||||||
| 5 | 星期六 | |||||||
| 6 | 星期四 | |||||||
| 7 | 星期日 | |||||||
| 8 | 星期二 | |||||||
| 9 | 星期四 |
那如何表示原来的数据呢?很简单,如果编号0的数据是星期一,那么在星期一这个字段上的数值是1,在其他所有字段上都是0,现在数据变成了这样
| 编号 | 星期一 | 星期二 | 星期三 | 星期四 | 星期五 | 星期六 | 星期日 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 6 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 8 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
最后再删去原来的字段,大功告成!
pandas
我们一会儿会用python里的pandas来处理数据,所以这里先简单介绍一下我们一会儿会用到的知识。
- dataframe
简单的理解,dataframe就是一张二维表,和上面例子中关于星期几的表格完全一样。
我们可以通过行号和列明的方式定位表中的某一个元素,dataframe也是这样。
假设我们有一个变量叫df,它是一个dataframe
df[0] # 访问第0行元素 df['column_name'] # 访问列名为 column_name 的一列数据 df.loc[0,'column_name'] # 访问第0行列名为 column_name 的元素
- dtype
dtype是 dataframe中每一列的数据类型,常用的有 float32 float64 int32 int16 等等
可以通过 dtypes 或 dtype 访问数据类型
df.dtypes # 所有列的数据类型 df['column_name'].dtype # 列名为 column_name 的数据类型
数据类型可以通过 astype 函数更改
df["column_name"] = df["column_name"].astype(np.int16) # 讲列名为 column_name 的列的数据类型改为 np.int16
数据标准化的代码实现
下面就是代码实现部分了,我会把我写整个代码的思路一点点的剖析开
首先当然是将要用到的包导入了
import pandas as pd import numpy as np
上面提到了两种实现方式,但为了便于使用,我不想写两个函数,我希望只暴露给用户一个函数,将这两种实现方法融合在一起。
具体来说,就是用一个参数来确定用户本次调用的到底是哪种实现方式,并可以通过给出参数默认值的方式给出默认实现方式。
def normalize(data, columns, function='min-max'): if function == 'min-max': return min_max_scalar(data, columns) elif function == 'standard': return standard_scalar(data, columns) else: raise ValueError("invalid parameter: function must be 'min-max' or 'standard'.") def min_max_scalar(data, columns): pass def standard_scalar(data, columns): pass
- data : 代表需要处理的数据表格,类型是 dataframe
- columns :代表需要处理的列的列明的集合,类型是 list,其中每个元素应该是字符串或是可以转换成字符串
- function :具体指定实现方式,默认为 min-max 标准化
整体的思路就是判断一下function的数值,然后调用相应的函数
现在整个函数的框架搭起来了,接下来的就是具体实现 min_max_scalar(data, columns) 和 standard_scalar(data, columns) 两个函数了
先来实现 min_max_scalar(data, columns)
def min_max_scalar(data, columns): for column in columns: maxi = max(data[column]) mini = min(data[column]) if maxi == mini: raise ValueError("invalid parameter value: maximum element equals to minimum element in the '" + column + "' column.") else: diff = maxi - mini data[column] = ( data[column] - mini ) / diff return data
很简单吧?不过一定要随时记得处理异常,在这种实现方式中,如果数据的最大值最小值相同,就会造成 ZeroDivisionError 这个异常,所以我们单独判断,处理了一下这种情况。
然后我们实现 standard_scalar(data, columns)
def standard_scalar(data, columns): for column in columns: std = np.std(data[column]) if std == 0: raise ValueError("invalid parameter: standard deviation is 0 in the '" + column + "' column.") else: mean = sum(data[column]) / len(data[column]) data[column] = ( data[column] - mean ) / std return data
这里处理了一下标准差为零的异常情况
图省事的同学就可以往下看哑编码部分的代码了,不过,如果你想让你的函数更加 robust,我们还得加入大量的异常处理代码
我们需要做哪些异常处理?
- 判断 data 的数据类型是否是 dataframe?
- columns 的数据类型是否是list,或者是否能转换成list?
- columns 中每个元素是不是字符串,或者是否能转换成字符串?
- columns 中每个元素代表的列是否真的存在?
- 如果存在,这个列的数据是数值类型的数据么?
- function 是一个字符串么?
- 如果是,那这个字符串是否是 ‘min-max’ 或 ‘standard’ 二者之一么?
直接看代码吧
def normalize(data, columns, function='min-max'): if type(data) != pd.core.frame.DataFrame: raise TypeError("invalid parameter: data must be a dataframe.") try: columns = list(columns) except TypeError: raise TypeError("invalid parameter: columns must be a list or can be converted to a list.") try: for counter in range(len(columns)): columns[counter] = str(columns[counter]) except TypeError: raise TypeError("invalid parameter: each column element in columns should be a string or can be converted to a string.") for column in columns: if column not in data.columns: raise ValueError("invalid parameter: column '" + column + "' doesn't exist.") is_int = data[column].dtype == np.int8 or data[column].dtype == np.int16 or data[column].dtype == np.int32 or data[column].dtype == np.int64 is_uint = data[column].dtype == np.uint8 or data[column].dtype == np.uint16 or data[column].dtype == np.uint32 or data[column].dtype == np.uint64 is_float = data[column].dtype == np.float16 or data[column].dtype == np.float32 or data[column].dtype == np.float64 if is_int or is_uint or is_float: data[column] = data[column].astype(np.float64) else: raise TypeError("invalid parameter: values in column '" + column + "' should be numbers ") try: function = str(function) except TypeError: raise TypeError("invalid parameter: function must be a string or can be converted to a string.") if function == 'min-max': return min_max_scalar(data, columns) elif function == 'standard': return standard_scalar(data, columns) else: raise ValueError("invalid parameter: function must be 'min-max' or 'standard'.")
是不是懵逼了?这异常处理代码写出来比主程序还长 orz~
数据哑编码的代码实现
还是先把大致的框架搭起来
def one_hot_encoder(data, columns): # 异常处理 pass # 处理数据
data 和 columns 的含义与上文相同,不再赘述。
这次我们先来处理异常,我们需要考虑
- 判断 data 的数据类型是否是 dataframe?
- columns 的数据类型是否是list,或者是否能转换成list?
- columns 中每个元素是不是字符串,或者是否能转换成字符串?
- columns 中有没有重复的元素?
- columns 中每个元素代表的列是否真的存在?
- columns 中每个元素代表的列的数据是否是字符串,或者是否能转换成字符串?
下面看代码~
def one_hot_encoder(data, columns): # 异常处理 if type(data) != pd.core.frame.DataFrame: raise TypeError("invalid parameter: data must be a dataframe.") try: columns = list(columns) except TypeError: raise TypeError("invalid parameter: columns must be a list or can be converted to a list.") try: for counter in range(len(columns)): columns[counter] = str(columns[counter]) except TypeError: raise TypeError("invalid parameter: each element in columns should be a string or can be converted to a string.") columns = np.unique(columns) # rule out duplicate column name to avoid error for column in columns: if column not in data.columns: raise ValueError("invalid parameter: column '" + column + "' doesn't exist.") try: data[column] =data[column].astype(str) except Exception: raise TypeError("invalid parameter: value in '" + column + "' must be a string or can be converted to a string.") # 处理数据 return help_encoder(data, columns)
我把处理数据的部分写到 help_encoder(data, columns) 函数中了,这里只做调用
接下来就剩下下最后一步,处理数据了,相比于数据标准化,这块的代码稍微复杂一点,需要细心点看。
def help_encoder(data, columns): for column in columns: unique_values = np.unique(data[column]) sub_column_names = [] for unique_value in unique_values: sub_column_names.append(column + '_' + unique_value) # insert new columns for sub_column_counter in range(len(sub_column_names)): data[sub_column_names[sub_column_counter]] = -1 for data_counter in range(len(data)): data.loc[data_counter, sub_column_names[sub_column_counter]] = int(data[column][data_counter] == unique_values[sub_column_counter]) # remove old columns del data[column] return data
最后我们测试一下哑编码部分的代码
data = pd.DataFrame([['A'], ['B'], ['C'], ['D'], ['A'], ['E']] ,columns=list('A')) # 创建 dataframe print('哑编码之前') print(data) one_hot_encoder(data, ['A']) #进行哑编码处理 print('哑编码之后') print(data)
运行结果
哑编码之前 A 0 A 1 B 2 C 3 D 4 A 5 E 哑编码之后 A_A A_B A_C A_D A_E 0 1 0 0 0 0 1 0 1 0 0 0 2 0 0 1 0 0 3 0 0 0 1 0 4 1 0 0 0 0 5 0 0 0 0 1 [Finished in 1.5s]
大功告成!