本博客内容来自 Stanford University CS231N 2017 Lecture 2 - Image Classification
课程官网:http://cs231n.stanford.edu/syllabus.html
从课程官网可以查询到更详细的信息,查看视频需要FQ上YouTube,如果不能FQ或觉得比较麻烦,也可以从我给出的百度云链接中下载。
课程视频&讲义下载:http://pan.baidu.com/s/1gfu51KJ
问题背景
现在我有一张关于猫的图片,如何让计算机识别出这是只猫呢?
算法思路
我们人眼虽然可以很轻松的辨认出一只猫,但却说不出是怎么辨别的,这个过程对我们来说其实是一个黑匣子。自己说都说不出来,那就更没法用编程的方式写下来了。所以显式定义规则识别的思路不可取。
换一种思考的角度,我们采用一种叫做 “Data-Driven Approach” 的思路 。 这个思路顾名思义,不是显式的定义规则,而是让计算机沉浸在海量的数据中,试图让计算机自己从中学会某种规律,某种技巧。
def train(images, labels): # Machine learning! return model def predict(model, test_images): # Use model to predict labels return test_labels
在这种情况下,我们的代码结构应该是上面这段代码所呈现的。
首先将海量的数据输送给计算机
- images:代表图片的信息(比如说图片所有像素的rgb值)
- labels:代表图片所属类别的信息(比如说“猫”)
然后计算机通过这海量的数据,训练出一个模型——model
最后给计算机一个刚刚训练好的模型和一张测试用的图片,计算机用接受的模型对图片作出预测。
算法原理
谈起KNN之间,我们先介绍NN(Nearest Neighbor)。
NN的原理及其简单,模型训练的过程就是记住所有的数据以及对应的标签。而在预测的过程,我们将测试图片与已经记住的数据逐一对比,选出相似度最高的一张图片,然后预测他们属于同一类别。
那怎么定义相似度呢?简单的方式有两种——L1距离和L2距离。用两点间的距离代表相似程度,距离越小,二者越相似。
- L1 (Manhattan) distanc
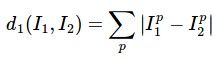
- L2 (Euclidean) distance
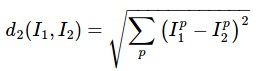
为了更直观的表述整个算法,我们想象每一条数据都是二维平面中的一个点。

在这张图中,不同颜色的点代表不同类别的数据,而不同颜色的区域对应了NN的分类结果,颜色相近的点和区域属于同一类别。
这样我们就能看出NN算法的某些缺陷了,图片正中间有一块孤立的黄色区域,而按照常理,这块区域更可能是属于绿色类别,这个黄色的数据点很有可能是因为某些误差造成的。
为了解决这个问题,KNN出现了。
现在我们不是仅考虑最相似的一个数据点,我们考虑最相似的K个数据点,在这K个数据点中,我们采取多数表决的方式决定最终的结果。举个例子,如果我们采用K=3,而与某个区域最接近的三个点中有两个属于黄色标签,一个属于绿色标签,那么这一点属于黄色范围。
 上述图片演示了不同K取值的时候形成的分类结果。可以看出当K变大的时候,不同区域之间的分界线变得更加圆滑。而白色的区域则是因为有多个相等的多数表决结果。举个例子,当K=3的时候,如果距离最近的三个点分别是蓝色、红色、绿色,这个区域就被表为白色。
上述图片演示了不同K取值的时候形成的分类结果。可以看出当K变大的时候,不同区域之间的分界线变得更加圆滑。而白色的区域则是因为有多个相等的多数表决结果。举个例子,当K=3的时候,如果距离最近的三个点分别是蓝色、红色、绿色,这个区域就被表为白色。
下面的网站是 Stanford 的大佬自己做的,可以动手尝试不同的k取值、不同距离函数的选择对KNN分类结果的影响,有兴趣可以去玩一玩。
http://vision.stanford.edu/teaching/cs231n-demos/knn/
超参数——Hyperparameters
K这样的参数被称之为超参数,超参数也包括距离公式的选择(L1或者L2),它不是可以计算机通过数据能够学习到的,而是在学习之前,由我们人为的规定的。
那么具体而言,如何选择超参数呢?
其实并没有很好的办法,能普遍的方法是尝试,尝试不同的超参数,然后选取效果最好的一组超参数。
那如何衡量效果的好坏呢?
首先我们不能在训练集上衡量,试想,在K=1的KNN算法中,每一个训练数据都被算法“正确”得划分了,准确率是100%,难道这就是最好的超参数么?
显然不是,模型就是在训练集上训练得来的,在训练集上的准确率不具有代表性。
那我们可以将数据划分为训练集、测试集两部分么,在训练集上训练模型,在测试集上选择超参数。
也不行,因为如果根据测试集上的表现选择超参数,我们选择的必然是在测试机上表现最好的超参数,很可能过度拟合测试集,也不具有代表性,不能反映一般情况。
最常规的方式:将数据划分为训练集(training set)、验证集(validation set)、测试集(test set)三部分。在训练集上训练模型,在验证集上选择最合适的超参数,在测试集上测出最终结果。
这里要特别注意,在得出了测试集的结果之后,我们不能根据这个结果再修改参数。尽管这样可能在测试集上得到更高的准确率,但这事实上属于一种“作弊”的行为,我们的模型就又会又过度拟合测试集的问题,丧失了代表性。况且这样做无疑让验证集与测试集的划分毫无意义,他们此时起到了相同的作用,情况又回到了上一种划分方式。
KNN的缺陷
- 训练耗时短,测试耗时长
训练的时候仅需记忆所有数据即可,如果是传递指针的话,能够常数时间内完成 O(1)。
- 两点间距离公式不能提供足够的信息
 上图中右侧的三张图片是在左侧图片上分别作出了某些修改后形成的,而通过精心的构建,这三张图片与左侧原本的图片有相同的距离,也就是说距离公式无法将他们区分开。
上图中右侧的三张图片是在左侧图片上分别作出了某些修改后形成的,而通过精心的构建,这三张图片与左侧原本的图片有相同的距离,也就是说距离公式无法将他们区分开。
而事实上,如果进行精心的设计,我们甚至可以让任意两张修改后的图片都与某张照片具有相同的距离。
- 维度灾难

KNN算法翻译过来,是K-最临近算法,而为了能够有效的体现出“最邻近”这个概念,我们势必需要样本能够均匀的分布在整个空间中,将整个空间支撑起来。在一维或者二维的情况下还好说,如果是上图的例子中,一维需要4个样本点,二维需要16个样本点,而到了三维就需要64个样本点。所需的样本数量随着维数的增加呈现指数级增长的趋势,这无疑是灾难性的,所以被称作“维度灾难”。我们一张图片就算很小,10像素*10像素,再乘上rgb三个颜色值,一共有300个数值,这就意味着300维度,而 4300 是一个无法想象的天文数字,我们永远不可能取得足够多的数据。