1. group by的常规用法
group by的常规用法是配合聚合函数,利用分组信息进行统计,常见的是配合max等聚合函数筛选数据后分析,以及配合having进行筛选后过滤。
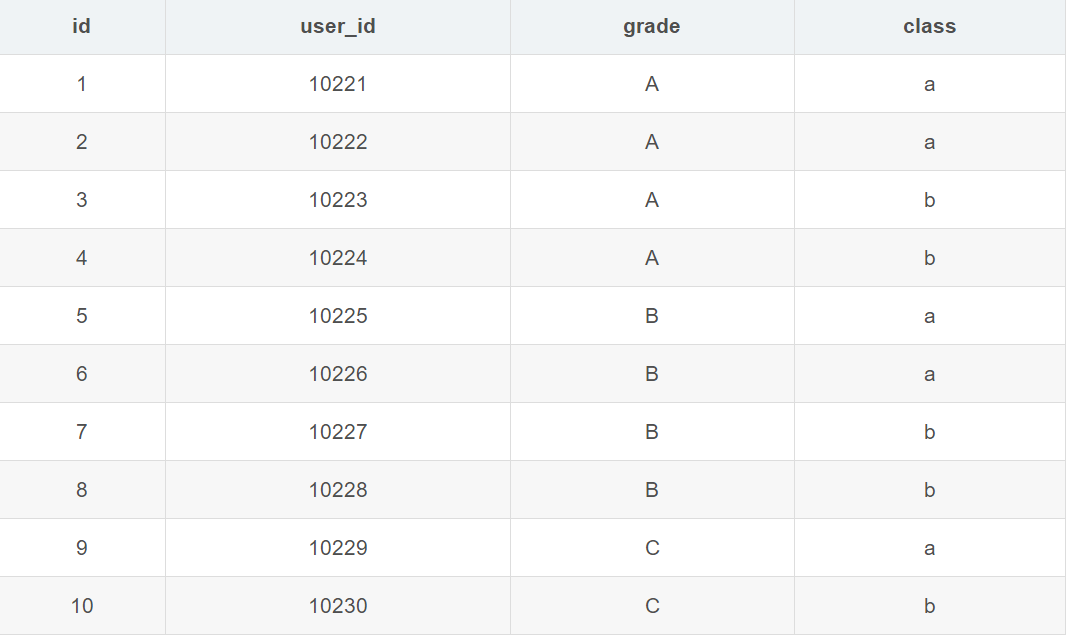
- 聚合函数max
- select max(user_id),grade from user_info group by grade ;

这条sql的含义很明确,将数据按照grade字段分组,查询每组最大的user_id以及当前组内容。注意,这里分组条件是grade,查询的非聚合条件也是grade。这里不产生冲突。
having
select max(user_id),grade from user_info group by grade having grade>'A'
这条sql与上面例子中的基本相同,不过后面跟了having过滤条件。将grade不满足’>A’的过滤掉了。注意,这里分组条件是grade,查询的非聚合条件也是grade。这里不产生冲突。
2. group by的非常规用法
- select max(user_id),id,grade from user_info group by grade
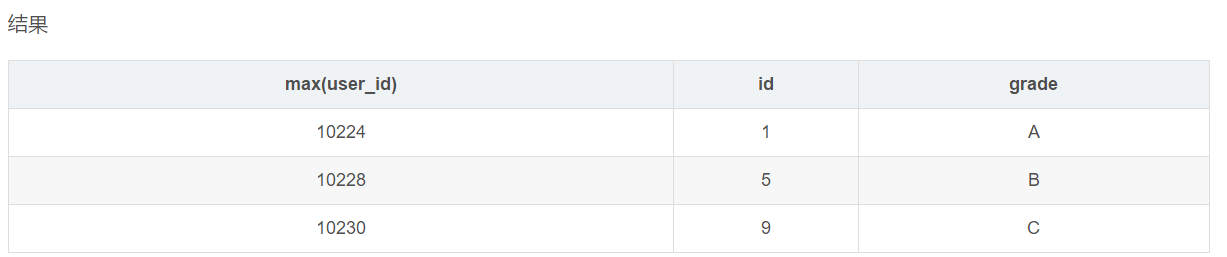
这条sql的结果就值得讨论了,与上述例子不同的是,查询条件多了id一列。数据按照grade分组后,grade一列是相同的,max(user_id)按照数据进行计算也是唯一的,id一列是如何取值的?看上述的数据结果,
推论:id是物理内存的第一个匹配项。
究竟是与不是需要继续探讨。修改数据
-
- 修改id按照上述数据结果,将id=1,改为id=99,执行sql后结论:

显然,与上述例子的结果不同。第一条数据id变成了99,查出的结果第一条数据的id从1变成了2。表明,id这个非聚合条件字段的取值与数据写入的时间无关,因为id=1的记录是先于id=2存在的,修改的数据不过是修改了这条数据的内容。结合mysql的数据存储理论,由于id是主键,所以数据在检索是是按照主键排序后进行过滤的,因此
推论:id字段的选取是按照mysql存储的检索数据匹配的第一条。
将id改为1后恢复了原始结果,无法推翻上述推论。
更改查询条件- select max(user_id),user_id,id,grade from user_info group by grade

将数据user_id改为10999后,执行结果为
-
结论
-
- 当group by 与聚合函数配合使用时,功能为分组后计算
- 当group by 与having配合使用时,功能为分组后过滤
- 当group by 与聚合函数,同时非聚合字段同时使用时,非聚合字段的取值是第一个匹配到的字段内容,即id小的条目对应的字段内容。