二、通过DataFrame实战电影点评系统
DataFrameAPI是从Spark 1.3开始就有的,它是一种以RDD为基础的分布式无类型数据集,它的出现大幅度降低了普通Spark用户的学习门槛。
DataFrame类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以解析到具体数据的结构信息,从而对DataFrame中的数据源以及对DataFrame的操作进行了非常有效的优化,从而大幅提升了运行效率。
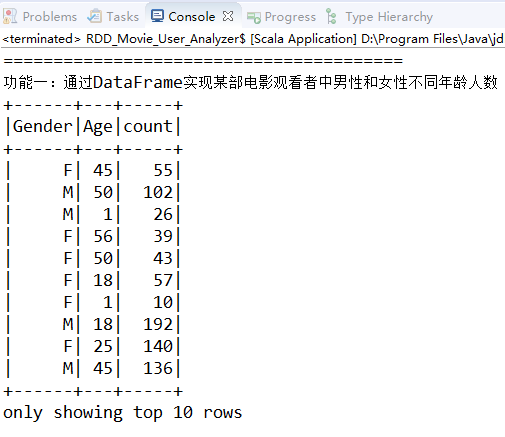
现在我们通过实现几个功能来了解DataFrame的具体用法。先来看第一个功能:通过DataFrame实现某部电影观看者中男性和女性不同年龄分别有多少人。
println("========================================")
println("功能一:通过DataFrame实现某部电影观看者中男性和女性不同年龄人数")
// 首先把User的数据格式化,即在RDD的基础上增加数据的元数据信息
val schemaForUsers = StructType(
"UserID::Gender::Age::OccupationID::Zip-code".split("::")
.map(column => StructField(column,StringType,true))
)
// 然后把我们的每一条数据变成以Row为单位的数据
val usersRDDRows = usersRDD.map(_.split("::")).map(
line => Row(line(0).trim(),line(1).trim(),line(2).trim(),line(3).trim(),line(4).trim())
)
// 使用SparkSession的createDataFrame方法,结合Row和StructType的元数据信息 基于RDD创建DataFrame,
// 这时RDD就有了元数据信息的描述
val usersDataFrame = spark.createDataFrame(usersRDDRows, schemaForUsers)
// 也可以对StructType调用add方法来对不同的StructField赋予不同的类型
val schemaforratings = StructType(
"UserID::MovieID".split("::")
.map(column => StructField(column,StringType,true)))
.add("Rating",DoubleType,true)
.add("Timestamp",StringType,true)
val ratingsRDDRows = ratingsRDD.map(_.split("::")).map(
line => Row(line(0).trim(),line(1).trim(),line(2).trim().toDouble,line(3).trim())
)
val ratingsDataFrame = spark.createDataFrame(ratingsRDDRows, schemaforratings)
// 接着构建movies的DataFrame
val schemaformovies = StructType(
"MovieID::Title::Genres".split("::")
.map(column => StructField(column,StringType,true))
)
val moviesRDDRows = moviesRDD.map(_.split("::")).map(line => Row(line(0).trim(),line(1).trim(),line(2).trim()))
val moviesDataFrame = spark.createDataFrame(moviesRDDRows, schemaformovies)
// 这里能够直接通过列名MovieID为1193过滤出这部电影,这些列名都是在上面指定的
/*
* Join的时候直接指定基于UserID进行Join,这相对于原生的RDD操作而言更加方便快捷
* 直接通过元数据信息中的Gender和Age进行数据的筛选
* 直接通过元数据信息中的Gender和Age进行数据的groupBy操作
* 基于groupBy分组信息进行count统计操作,并显示出分组统计后的前10条信息
*/
ratingsDataFrame.filter(s"MovieID==1193")
.join(usersDataFrame,"UserID")
.select("Gender", "Age")
.groupBy("Gender", "Age")
.count().show(10)
上面案例中的代码无论是从思路上,还是从结构上都和SQL语句十分类似,下面通过写SQL语句的方式来实现上面的案例。
println("========================================")
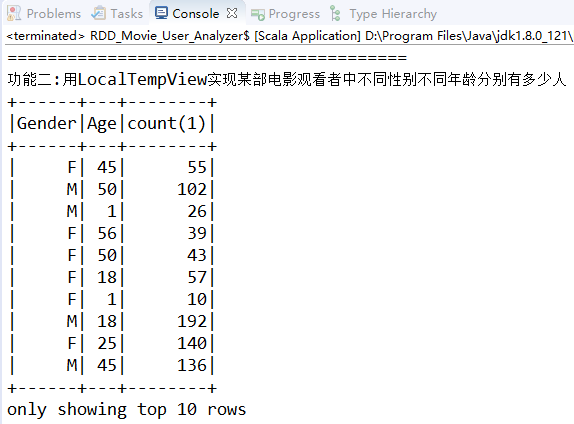
println("功能二:用LocalTempView实现某部电影观看者中不同性别不同年龄分别有多少人")
// 既然使用SQL语句,那么表肯定是要有的,所以需要先把DataFrame注册为临时表
ratingsDataFrame.createTempView("ratings")
usersDataFrame.createTempView("users")
// 然后写SQL语句,直接使用SparkSession的sql方法执行SQL语句即可。
val sql_local = "SELECT Gender,Age,count(*) from users u join ratings as r on u.UserID=r.UserID where MovieID=1193 group by Gender,Age"
spark.sql(sql_local).show(10)
这篇博文主要来自《Spark大数据商业实战三部曲》这本书里面的第一章,内容有删减,还有本书的一些代码的实验结果。随书附赠的代码库链接为:https://github.com/duanzhihua/code-of-spark-big-data-business-trilogy