周期结束
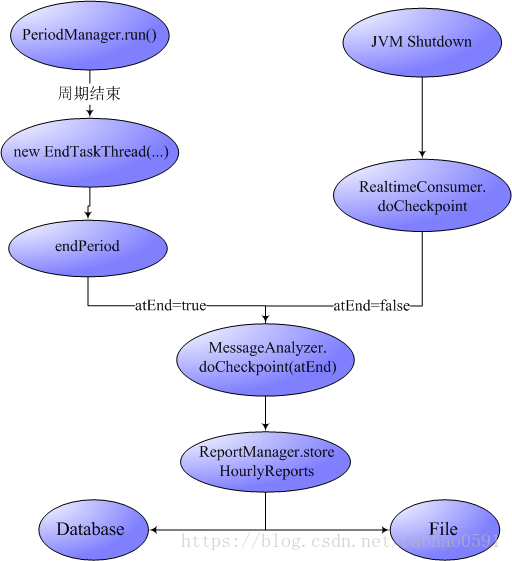
我们从消息分发章节知道,RealtimeConsumer在初始化的时候,会启动一个线程,每隔1秒钟就去从判断是否需要开启或结束一个周期(Period),如下源码,如果 value < 0 的时候,就会启动一个周期结束线程,线程会调用endPeriod函数,找到需要结束的周期,完成周期的结束以及清理工作,并将周期对象从PeriodManager中移除。
public class PeriodManager implements Task { private List<Period> m_periods = new ArrayList<Period>(); @Override public void run() { while (m_active) { try { long now = System.currentTimeMillis(); long value = m_strategy.next(now); if (value > 0) { startPeriod(value); } else if (value < 0) { // last period is over,make it asynchronous Threads.forGroup("cat").start(new EndTaskThread(-value)); } } ... } } private void endPeriod(long startTime) { int len = m_periods.size(); for (int i = 0; i < len; i++) { Period period = m_periods.get(i); if (period.isIn(startTime)) { period.finish(); m_periods.remove(i); break; } } } private class EndTaskThread implements Task { public void run() { endPeriod(m_startTime); } } }
我们知道,周期是由许多的周期任务(PeriodTask)构成,所以事实上,一个周期的结束,就是周期内所有周期任务的结束,每个周期任务对应着一个任务队列和一个消息分析器(MessageAnalyzer),归根结底是对MessageAnalyzer的结束。
public class PeriodTask implements Task, LogEnabled { private MessageAnalyzer m_analyzer; public void finish() { try { m_analyzer.doCheckpoint(true); m_analyzer.destroy(); } catch (Exception e) { Cat.logError(e); } } }
doCheckpoint 我们似曾相识,在CatHomeModule初始化的最后,我们会向虚拟机注册shutdownhook,保证在虚拟机关闭时,未被正常结束的周期会被RealtimeConsumer结束,RealtimeConsumer.doCheckpoint与上面正常结束周期所做的工作是一样的,都是调用分析器的doCheckpoint方法,唯一的区别是,分析器doCheckpoint函数的传入的atEnd参数不同,表示周期是否在到期后正常结束的。
Runtime.getRuntime().addShutdownHook(new Thread() { @Override public void run() { consumer.doCheckpoint(); } });
分析器的结束 -- 报表持久化
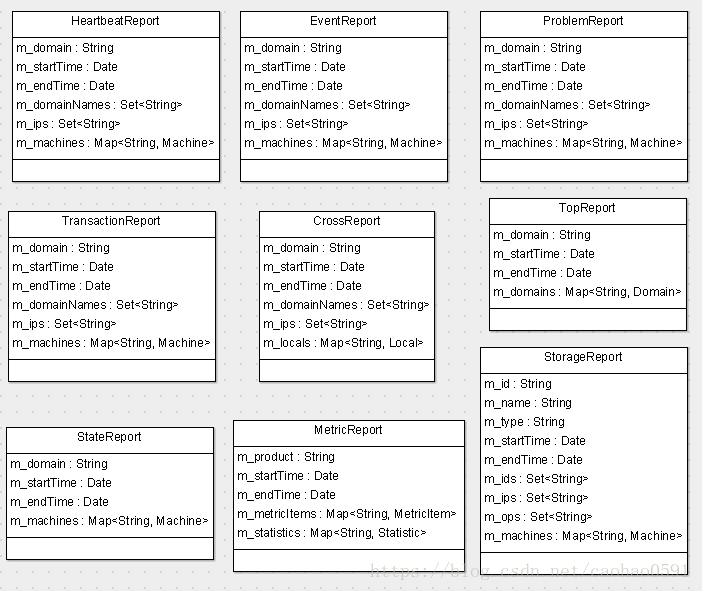
分析器的结束实际上就是报表的持久化的一个过程,分析器处理消息的过程中,我们一共形成了9个报表,图1展示了这9个报表的结构:
我们知道每个周期的消息分析器(MessageAnalyzer)的结束都是在doCheckpoint来实现的,实际运行中一共有10种消息分析器参与消息分析工作,那么不同类别的分析器,他的结束逻辑都是一样的吗?
除了几个特殊的分析器(如Metric、Dump)之外,其它消息分析器结束逻辑都同下面源码,调用storeHourlyReports方法存储报表,所有报表都会被存到文件,atEnd 和 localMode 参数决定我们是否将报表存到数据库。
其中State报表有点特殊,因为State是对CAT本身的监控,在周期任务(PeriodTask)运行过程中并没有收集任何数据,而是在doCheckpoint的时候对CAT消息监控情况汇总生成的一个报表,所以调用storeHourlyReports之前,他需要首先收集State报表数据。
public class XxxAnalyzer extends AbstractMessageAnalyzer<XxxReport> implements LogEnabled { private ReportManager<XxxReport> m_reportManager; public synchronized void doCheckpoint(boolean atEnd) { if (atEnd && !isLocalMode()) { m_reportManager.storeHourlyReports(getStartTime(), StoragePolicy.FILE_AND_DB, m_index); } else { m_reportManager.storeHourlyReports(getStartTime(), StoragePolicy.FILE, m_index); } } }
我们先详细剖析storeHourlyReports 的过程,然后再看看几个特殊的分析器的结束逻辑。storeHourlyReports 首先将该分析器生成的所有报表都取出,然后我们会校验报表的domain名称是否合法,不合法的报表将被移除,在序列化之前,我们会调用ReportDelegate.beforeSave(...)方法做一些预处理的工作。不同种类的报表,预处理所做的工作是不同的,后续我们分别讲解,做完预处理的工作之后,我们就正式持久化了,支持文件和数据库两种持久化方式,我们会根据传入的序列化策略(StoragePolicy) 来选择需要进行哪种序列化,一般来说,如果是正常的周期结束,数据会持久化到文件和数据库,如果是JVM Shutdown导致的结束,只持久化到文件,两种持久化的细节后续我们也会分别详细讲解。
public class DefaultReportManager<T> extends ContainerHolder implements ReportManager<T>, Initializable, LogEnabled { @Override public void storeHourlyReports(long startTime, StoragePolicy policy, int index) { Map<String, T> reports = m_reports.get(startTime); ReportBucket bucket = null; try { if (reports != null) { //校验、移除不合法Domain名字的报表 ... m_reportDelegate.beforeSave(reports); if (policy.forFile()) { bucket = m_bucketManager.getReportBucket(startTime, m_name, index); try { storeFile(reports, bucket); } finally { m_bucketManager.closeBucket(bucket); } } if (policy.forDatabase()) { storeDatabase(startTime, reports); } } } catch (Throwable e) { //报告异常 ... } finally { cleanup(startTime); t.complete(); if (bucket != null) { m_bucketManager.closeBucket(bucket); } } } }
报表预处理
在继续讲解序列化之前,我们来说一说报表的预处理工作(beforeSave),各报表的预处理逻辑,有相同、也有异同的地方,Top、State报表预处理不做任何事情,其它报表都有处理逻辑,以Transaction报表的预处理工作为例,分为两个部分。
第一部分是将所有Transaction报表的domain都收集起来,写入报表的成员变量 m_domainNames,这样每个报表都会知道一共都有哪些domain参与监控, 从图1的报表结构来看,Heartbeat、Event、Problem、Cross报表也包含m_domainNames字段,事实上这些报表的预处理也确实会收集所有domain。其中Heartbeat和Cross的预处理仅仅包含这部分逻辑。
第二部分是聚合报表,所谓聚合,就是创建一个命名为ALL的聚合报表,将同一个Domain下不同IP地址的数据汇总起来,写到报表ALL的同一个Machine对象内,Machine的ip不再是地址,而是Domain名,所有Domain数据都汇总到ALL报表的不同Machine下。因为现在服务端几乎都是采用集群,有可能10几台机器上运行着同一个项目,这时我们可以通过聚合报表去站在项目角度去看待统计结果,报表的聚合大量采用了访问者模式。
也不是所有类型的事务都会参与聚合,配置 all-report-config 会指定哪些事务会参与聚合,如下默认type="URL"的事务,这是因为通常URL是代表一个项目的接口对外服务的最完整链路耗时,从以下配置可以看到,除了Transaction消息之外,Event消息也会参与聚合,逻辑与Transaction大同小异,在此不再赘述。
<all-config>
<report id="transaction">
<type id="URL">
<name id="*"></name>
</type>
</report>
<report id="event">
<type id="URL">
<name id="*"></name>
</type>
<type id="SQL">
<name id="*"></name>
</type>
</report>
</all-config>
Problem有一个独有的预处理流程,就是通过ProblemReportFilter对象将长时URL访问(long-url)的记录总数控制在100条之内,防止长时访问数量过多,导致报表数据过大。
Storage报表的预处理只有一个 updateStorageIds 调用,他的功能和Transaction预处理第一部分类似,也是让每个Storage报表都知道目前有哪些数据库/缓存在被访问、监控,我们知道Storage报表的ID是由 数据库/缓存名 + 类型(SQL/Cache) 组成,updateStorageIds会将所有数据库/缓存名收集,然后写入StorageReport的成员变量m_ids。
下面将所有报表持久化的预处理做了一个汇总,放在一个函数内,呈现在以下伪代码中:
public class XxxDelegate implements ReportDelegate<XxxReport> { @Override public void beforeSave(Map<String, XxxReport> reports) { //Top、State不干任何事直接返回 return; //storage 仅有下面 updateStorageIds 步骤,完成后返回。 for (StorageReport report : reports.values()) { m_reportUpdater.updateStorageIds(report.getId(), reports.keySet(), report); } //Problem、Transaction、Event、Heartbeat、Cross都有的步骤 for (XxxReport report : reports.values()) { Set<String> domainNames = report.getDomainNames(); domainNames.clear(); domainNames.addAll(reports.keySet()); } //报表聚合,Transaction、Event 独有 if (reports.size() > 0) { TransactionReport all = createAggregatedReport(reports); reports.put(all.getDomain(), all); } //Problem独有,控制long-url消息量。 ProblemReportFilter problemReportURLFilter = new ProblemReportFilter(); for (Entry<String, ProblemReport> entry : reports.entrySet()) { ProblemReport report = entry.getValue(); problemReportURLFilter.visitProblemReport(report); } } }
报表的文件存储 -- 重入锁
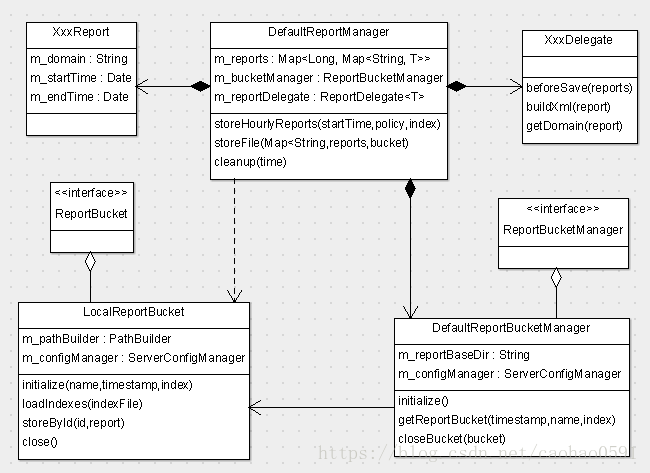
在做完预处理之后,所有报表都将被持久化到文件,在DefaultReportManager调用storeFile存储文件之前,我们先调用 m_bucketManager.getReportBucket(...) 来创建并初始化ReportBucket,文件的读写相关操作都封装于ReportBucket里面,文件的读写同步采用重入锁(ReentrantLock)保证读写安全。
public class LocalReportBucket implements ReportBucket, LogEnabled { @Override public void initialize(String name, Date timestamp, int index) throws IOException { m_baseDir = m_configManager.getHdfsLocalBaseDir("report"); m_writeLock = new ReentrantLock(); m_readLock = new ReentrantLock(); String logicalPath = m_pathBuilder.getReportPath(name, timestamp, index); File dataFile = new File(m_baseDir, logicalPath); File indexFile = new File(m_baseDir, logicalPath + ".idx"); if (indexFile.exists()) { loadIndexes(indexFile); } final File dir = dataFile.getParentFile(); if (!dir.exists() && !dir.mkdirs()) { throw new IOException(String.format("Fail to create directory(%s)!", dir)); } m_logicalPath = logicalPath; m_writeDataFile = new BufferedOutputStream(new FileOutputStream(dataFile, true), 8192); m_writeIndexFile = new BufferedOutputStream(new FileOutputStream(indexFile, true), 8192); m_writeDataFileLength = dataFile.length(); m_readDataFile = new RandomAccessFile(dataFile, "r"); } }
报表存储基础路径(m_baseDir)在配置 server.xml 中指定,每个分析器实例都会最终生成若干个报表,我们会为这个分析器产生的这些报表生成一个数据文件和报表索引文件,存于逻辑路径(logicalPath )下,逻辑路径以日期/小时/index来划分,例如:20180604/15/1/report-cross , 20180604为日期, 15为下午3点的周期,1是分析器实例index,之前说过有些分析器处理过程复杂,可能会有多个实例,例如Cross、Event、Problem、Transaction报表, 数据文件名取 m_baseDir + logicalPath, 索引文件是在数据文件名加上 ".idx" 后缀,如下: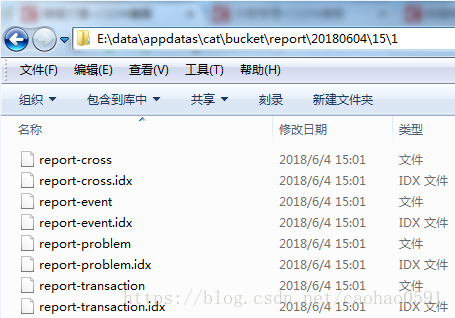
数据文件存储该分析器下所有转化为xml格式的报表数据,索引文件是对数据文件内报表的一个位置索引,比如 report-problem.idx索引文件内容如下,每一行都记录一个报表名称和报表在数据文件的起始位置。
RpcService 0 Cat 1388 RpcClient2 4600 RpcClient 5807
现在再来看看storeFile的逻辑就非常简单了, 获取domain,将报表对象转化为xml数据,最后调用storeById将xml写入数据文件和索引文件。
public class DefaultReportManager<T> extends ContainerHolder implements ReportManager<T>, Initializable, LogEnabled { private void storeFile(Map<String, T> reports, ReportBucket bucket) { for (T report : reports.values()) { try { String domain = m_reportDelegate.getDomain(report); String xml = m_reportDelegate.buildXml(report); bucket.storeById(domain, xml); } catch (Exception e) { Cat.logError(e); } } } }
报表的数据库存储
如果是正常的周期结束之后,发起的持久化,而不是由于虚拟机关闭引起的,数据除了被持久化到文件之外,还会被持久化到数据库。
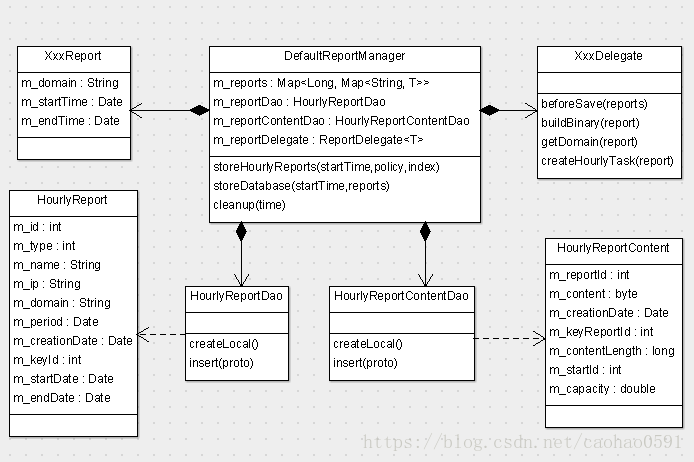
所有的数据库持久化逻辑都在 storeDatabase(...) 方法中完成,每个分析器中的每个报表的描述信息,都会被插入数据库report表中,在程序中,HourlyReport实体与该表对应,如图3, 报表具体内容会通过m_reportDelegate.buildBinary(report)转化成二进制数据,然后插入数据库report_content 表,在程序中,HourlyReportContent实体与该表对应,如图4,report_content 表的主键来自report的主键。
public class DefaultReportManager<T> extends ContainerHolder implements ReportManager<T>, Initializable, LogEnabled { @Inject private HourlyReportDao m_reportDao; @Inject private HourlyReportContentDao m_reportContentDao; private void storeDatabase(long startTime, Map<String, T> reports) { Date period = new Date(startTime); String ip = NetworkInterfaceManager.INSTANCE.getLocalHostAddress(); for (T report : reports.values()) { try { String domain = m_reportDelegate.getDomain(report); HourlyReport r = m_reportDao.createLocal(); r.setName(m_name); r.setDomain(domain); r.setPeriod(period); r.setIp(ip); r.setType(1); m_reportDao.insert(r); int id = r.getId(); byte[] binaryContent = m_reportDelegate.buildBinary(report); HourlyReportContent content = m_reportContentDao.createLocal(); content.setReportId(id); content.setContent(binaryContent); m_reportContentDao.insert(content); m_reportDelegate.createHourlyTask(report); } catch (Throwable e) { Cat.getProducer().logError(e); } } } }
CREATE TABLE `report` ( `id` int(11) NOT NULL AUTO_INCREMENT, `type` tinyint(4) NOT NULL COMMENT '报表类型, 1/xml, 9/binary 默认1', `name` varchar(20) NOT NULL COMMENT '报表名称', `ip` varchar(50) DEFAULT NULL COMMENT '报表来自于哪台机器', `domain` varchar(50) NOT NULL COMMENT '报表项目', `period` datetime NOT NULL COMMENT '报表时间段', `creation_date` datetime NOT NULL COMMENT '报表创建时间', PRIMARY KEY (`id`), KEY `IX_Domain_Name_Period` (`domain`,`name`,`period`), KEY `IX_Name_Period` (`name`,`period`), KEY `IX_Period` (`period`) ) ENGINE=InnoDB AUTO_INCREMENT=18497 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED COMMENT='用于存放实时报表信息,处理之后的结果';
CREATE TABLE `report_content` ( `report_id` int(11) NOT NULL COMMENT '报表ID', `content` longblob NOT NULL COMMENT '二进制报表内容', `creation_date` datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (`report_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED COMMENT='小时报表二进制内容';
定时任务生产者
数据库的持久化完成标志着一个完整周期的结束,CAT实时处理报表都是产生小时级别统计,小时级报表中会带有最低分钟级别粒度的统计,在数据库持久化完成之后,我们会调用 m_reportDelegate.createHourlyTask(report) 创建一些定时任务,去创建小时模式、天模式、周模式、月模式等等粒度更粗的视图,为什么这里还会创建小时任务,因为在集群情况下,同一周期下的多张报表可能分散在几台CAT服务器上,这时我们创建小时定时任务去合并报表形成小时视图。
但是,针对不同报表、不同domain,创建的定时任务也不同,有些可能小时模式、天模式、周模式、月模式视图定时任务都有,有些也可能只创建天任务,在解释完以下几个domain的描述之后我们看下定时任务的列表:
- crashLogDomain:客户端崩溃日志埋点,默认有:AndroidCrashLog/iOSCrashLog/MerchantAndroidCrashLog/MerchantIOSCrashLog/ApolloAndroidCrashLog/ApolloIOSCrashLog/TVAndroidCrashLog
- serverFilterDomain:配置serverFilter中过滤的domain,默认有:空/PhoenixAgent/cat-agent/All/FrontEnd/paas/SMS-RECEIVER
- validateDomain:非ServerFilterLog 和 非CrashLog
- ALL:聚合报表,Transaction和Event特有。
- *:所有domain
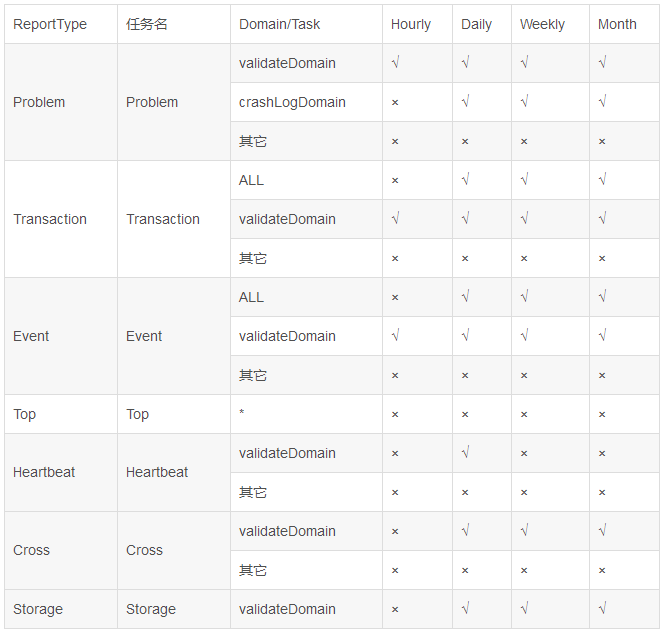
State比较特殊,他会创建比较多的定时任务,我们单独列在下面:

定时任务在 TaskManager.createTask(...) 中生产,这里就是将需要执行的定时任务插入数据库task表中,以供消费者(TaskConsumer)到时候去表里取定时任务然后执行,表字段如下:
TABLE `task` ( `id` int(11) NOT NULL AUTO_INCREMENT, `producer` varchar(20) NOT NULL COMMENT '任务创建者ip', `consumer` varchar(20) DEFAULT NULL COMMENT '任务执行者ip', `failure_count` tinyint(4) NOT NULL COMMENT '任务失败次数', `report_name` varchar(20) NOT NULL COMMENT '报表名称, transaction, problem...', `report_domain` varchar(50) NOT NULL COMMENT '报表处理的Domain信息', `report_period` datetime NOT NULL COMMENT '报表时间', `status` tinyint(4) NOT NULL COMMENT '执行状态: 1/todo, 2/doing, 3/done 4/failed', `task_type` tinyint(4) NOT NULL DEFAULT '1' COMMENT '0表示小时任务,1表示天任务', `creation_date` datetime NOT NULL COMMENT '任务创建时间', `start_date` datetime DEFAULT NULL COMMENT '开始时间, 这次执行开始时间', `end_date` datetime DEFAULT NULL COMMENT '结束时间, 这次执行结束时间', PRIMARY KEY (`id`), UNIQUE KEY `task_period_domain_name_type` (`report_period`,`report_domain`,`report_name`,`task_type`) ) ENGINE=InnoDB AUTO_INCREMENT=42594 DEFAULT CHARSET=utf8 COMMENT='后台任务';
其中producer就是生产定时任务的机器IP,stauts是执行状态,这里TaskManager作为生产者插入的记录状态都是todo=1,task_type指的任务类别,包含下面4种类别:
0-小时任务,有小时任务需求的在生产者中都会被创建,合并CAT服务器集群的多台机器的小时报表。
1-天任务, 对于有天任务需求的,会在当天创建前一天的天视图,
2-周任务,有周任务需求的会创建上周六到这周五的周视图,
3-月任务,有月任务需求的会在每月1号创建上个月的月视图。
当然由于task表的report_period, report_domain, report_name, task_type 是联合唯一键,所以,同一个类型、周期、domain、名称的定时任务,只会插入一条。
public class TaskManager { @Inject private TaskDao m_taskDao; private static final int STATUS_TODO = 1; public static final int REPORT_HOUR = 0; public static final int REPORT_DAILY = 1; public static final int REPORT_WEEK = 2; public static final int REPORT_MONTH = 3; public boolean createTask(Date period, String domain, String name, TaskCreationPolicy prolicy) { try { if (prolicy.shouldCreateHourlyTask()) { createHourlyTask(period, domain, name); } Calendar cal = Calendar.getInstance(); cal.setTime(period); int hour = cal.get(Calendar.HOUR_OF_DAY); cal.add(Calendar.HOUR_OF_DAY, -hour); Date currentDay = cal.getTime(); if (prolicy.shouldCreateDailyTask()) { createDailyTask(new Date(currentDay.getTime() - ONE_DAY), domain, name); } if (prolicy.shouldCreateWeeklyTask()) { int dayOfWeek = cal.get(Calendar.DAY_OF_WEEK); if (dayOfWeek == 7) { createWeeklyTask(new Date(currentDay.getTime() - 7 * ONE_DAY), domain, name); } } if (prolicy.shouldCreateMonthTask()) { int dayOfMonth = cal.get(Calendar.DAY_OF_MONTH); if (dayOfMonth == 1) { cal.add(Calendar.MONTH, -1); createMonthlyTask(cal.getTime(), domain, name); } } return true; } catch (DalException e) { Cat.logError(e); return false; } } }
定时任务消费者
我们再次回到CatHomeModule的初始化函数中,有如下一段代码,它会读取server.xml中的配置 job-machine="true",用于指定是否开启定时任务消费者线程。
if (serverConfigManager.isJobMachine()) { DefaultTaskConsumer taskConsumer = ctx.lookup(DefaultTaskConsumer.class); Threads.forGroup("cat").start(taskConsumer); }
线程会每隔1分钟轮训从数据库取状态为todo的定时任务,以及consumer为本机ip,然后状态为doing的定时任务,即上次处理失败,需要重试的,将任务状态都修改为 doing,然后调用 processTask处理定时任务,如果处理失败则间隔一段时间后重试,注意,这里的间隔会阻塞任务线程,超过最大重试次数,状态标为failed,成功则标为done。
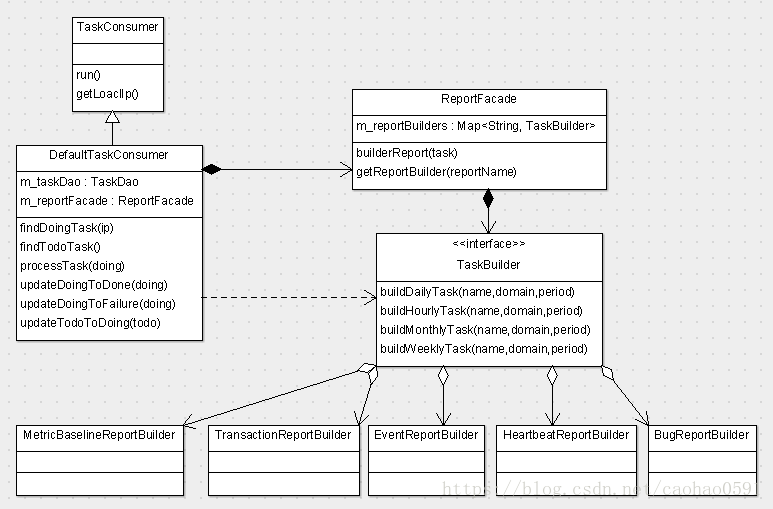
public abstract class TaskConsumer implements org.unidal.helper.Threads.Task { @Override public void run() { String localIp = getLoaclIp(); while (running) { if (checkTime()) { Task task = findDoingTask(localIp); if (task == null) { task = findTodoTask(); } boolean again = false; if (task != null) { task.setConsumer(localIp); if (task.getStatus() == TaskConsumer.STATUS_DOING || updateTodoToDoing(task)) { int retryTimes = 0; while (!processTask(task)) { retryTimes++; if (retryTimes < MAX_TODO_RETRY_TIMES) { taskRetryDuration(); } else { updateDoingToFailure(task); again = true; break; } } if (!again) { updateDoingToDone(task); } } } else { taskNotFoundDuration(); //sleep 2 min } } else { Thread.sleep(60 * 1000); } } this.stopped = true; } }
processTask(...)处理的核心是将Task交给ReportFacade去构建视图,我们可以认为ReportFacade是一个视图构建工厂,工厂在初始化的时候,从plexus配置中读取所有的任务构建器(TaskBuilder),并将他们装入ReportFacade的成员变量m_reportBuilders中,TaskBuilder是一个接口,有4个方法,buildHourlyTask、buildDailyTask、buildWeeklyTask、buildMonthlyTask,我们从图3可以看到该接口一共有24个实现,当有定时任务交付时,ReportFacade会根据任务名找到具体的任务构建类,然后根据任务是小时、天、周还是月分别调用以上4个方法。