一、动机
我们已经学了很多在 Spark 中对已分发的数据执行的操作。到目前为止,所展示的示例都是从本地集合或者普通文件中进行数据读取和保存的。但有时候,数据量可能大到无法放在一台机器中,这时就需要探索别的数据读取和保存的方法了。
Spark 及其生态系统提供了很多可选方案。本章会介绍以下三类常见的数据源。
• 文件格式与文件系统:对于存储在本地文件系统或分布式文件系统(比如 NFS、HDFS、Amazon S3 等)中的数据,Spark 可以访问很多种不同的文件格式,包括文本文件、JSON、SequenceFile,以及 protocol buffer。我们会展示几种常见格式的用法,以及 Spark 针对不同文件系统的配置和压缩选项。
• Spark SQL中的结构化数据源:后面会学习 Spark SQL 模块,它针对包括 JSON 和 Apache Hive 在内的结构化数据源,为我们提供了一套更加简洁高效的 API。此处会粗略地介绍一下如何使用 SparkSQL。
• 数据库与键值存储:概述 Spark 自带的库和一些第三方库,它们可以用来连接 Cassandra、HBase、Elasticsearch 以及 JDBC 源。
二、文件格式
Spark 对很多种文件格式的读取和保存方式都很简单。从诸如文本文件的非结构化的文件,到诸如 JSON 格式的半结构化的文件,再到诸如 SequenceFile 这样的结构化的文件,Spark都可以支持(见表)。Spark 会根据文件扩展名选择对应的处理方式。这一过程是封装好的,对用户透明。

1、文本文件
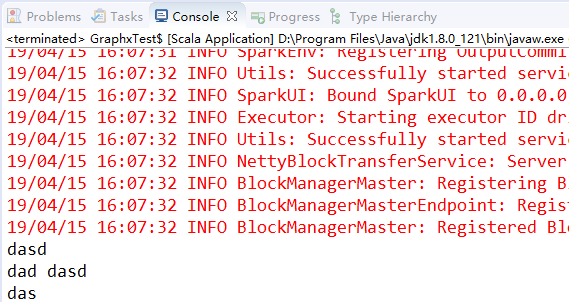
在 Spark 中读写文本文件很容易。当我们将一个文本文件读取为 RDD 时,输入的每一行都会成为 RDD 的一个元素。( SparkContext.wholeTextFiles() 方法)也可以将多个完整的文本文件一次性读取为一个 pair RDD,其中键是文件名,值是文件内容。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Test {
def main(args: Array[String]): Unit = {
// Scala 中读取一个文本文件
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val input = sc.textFile("words.txt")
input.foreach(println)
}
}
2、保存文本文件
输出文本文件也相当简单。saveAsTextFile(outputFile) 方法接收一个路径,并将RDD 中的内容都输入到路径对应的文件中。Spark 将传入的路径作为目录对待,会在那个目录下输出多个文件。这样,Spark 就可以从多个节点上并行输出了。在这个方法中,我们不能控制数据的哪一部分输出到哪个文件中,不过有些输出格式支持控制。
3、读取JSON
JSON 是一种使用较广的半结构化数据格式。这里有两种方式解析JSON数据,一种是通过Scala自带的JSON包(import scala.util.parsing.json.JSON)。后面还会展示使用Spark SQL读取JSON数据。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import scala.util.parsing.json.JSON
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("JSONTest").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val inputFile = "pandainfo.json"//读取json文件
val jsonStr = sc.textFile(inputFile);
val result = jsonStr.map(s => JSON.parseFull(s));//逐个JSON字符串解析
result.foreach(
{
r => r match {
case Some(map:Map[String,Any]) => println(map)
case None => println("parsing failed!")
case other => println("unknown data structure" + other)
}
}
);
}
}


第二种方法是通过json4s来解析JSON文件。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.json4s.jackson.Serialization
import org.json4s.ShortTypeHints
import org.json4s.jackson.JsonMethods._
import org.json4s.DefaultFormats
object Test {
def main(args: Array[String]): Unit = {
// 第二种方法解析json文件
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
implicit val formats = Serialization.formats(ShortTypeHints(List()))
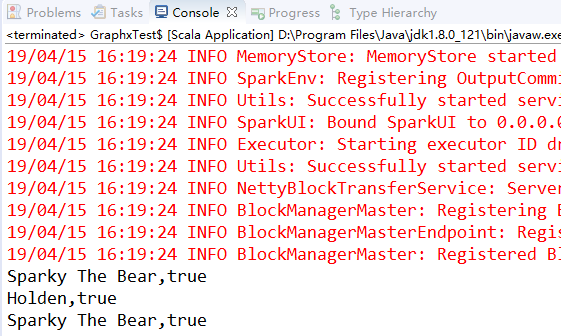
val input = sc.textFile("pandainfo.json")
input.collect().foreach(x=>{
var c = parse(x).extract[Panda]
println(c.name+","+c.lovesPandas)
})
case class Panda(name:String,lovesPandas:Boolean)
}
}
4、保存JSON
写出 JSON 文件比读取它要简单得多。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.json4s.jackson.Serialization
import org.json4s.ShortTypeHints
import org.json4s.jackson.JsonMethods._
import org.json4s.DefaultFormats
object Test {
def main(args: Array[String]): Unit = {
// 第二种方法解析json文件
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
implicit val formats = Serialization.formats(ShortTypeHints(List()))
val input = sc.textFile("pandainfo.json")
input.collect().foreach(x=>{
var c = parse(x).extract[Panda]
println(c.name+","+c.lovesPandas)
})
case class Panda(name:String,lovesPandas:Boolean)
// 保存json
val datasave = input.map{ myrecord =>
implicit val formats = DefaultFormats
val jsonObj = parse(myrecord)
jsonObj.extract[Panda]
}
datasave.saveAsTextFile("savejson")
}
}

5、逗号分隔值与制表符分隔值
逗号分隔值(CSV)文件每行都有固定数目的字段,字段间用逗号隔开(在制表符分隔值文件,即 TSV 文件中用制表符隔开)。记录通常是一行一条,不过也不总是这样,有时也可以跨行。读取 CSV/TSV 数据和读取 JSON 数据相似,都需要先把文件当作普通文本文件来读取数据,再对数据进行处理。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import au.com.bytecode.opencsv.CSVReader
import java.io.StringReader
import java.io.StringWriter
import au.com.bytecode.opencsv.CSVWriter
object Test {
def main(args: Array[String]): Unit = {
// 在Scala中使用textFile()读取CSV
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
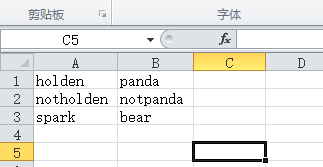
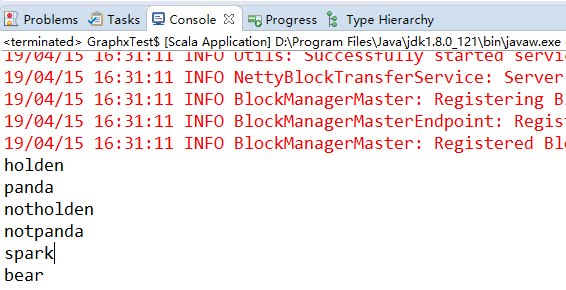
val inputFile = "favourite_animals.csv"//读取csv文件
val input = sc.textFile(inputFile)
val result = input.map{
line => val reader = new CSVReader(new StringReader(line))
reader.readNext()
}
// result.foreach(println)
for(res <- result)
for(r <- res)
println(r)
}
}
6、SequenceFile
SequenceFile 是由没有相对关系结构的键值对文件组成的常用 Hadoop 格式。SequenceFile文件有同步标记,Spark 可以用它来定位到文件中的某个点,然后再与记录的边界对齐。这可以让 Spark 使用多个节点高效地并行读取 SequenceFile 文件。SequenceFile 也是Hadoop MapReduce 作业中常用的输入输出格式,所以如果你在使用一个已有的 Hadoop 系统,数据很有可能是以 SequenceFile 的格式供你使用的。
由于 Hadoop 使用了一套自定义的序列化框架,因此 SequenceFile 是由实现 Hadoop 的 Writable接口的元素组成。下表 列出了一些常见的数据类型以及它们对应的 Writable 类。标准的经验法则是尝试在类名的后面加上 Writable 这个词,然后检查它是否是 org.apache.hadoop.io.Writable 已知的子类。如果你无法为要写出的数据找到对应的 Writable 类型(比如自定义的 case class),你可以通过重载 org.apache.hadoop.io.Writable 中的 readfields 和 write 来实现自己的 Writable 类。

读取SequenceFile:Spark 有专门用来读取 SequenceFile 的接口。在 SparkContext 中,可以调用 sequenceFile(path,keyClass, valueClass, minPartitions) 。前面提到过,SequenceFile 使用 Writable 类,因此 keyClass 和 valueClass 参数都必须使用正确的 Writable 类。
保存SequenceFile:在 Scala 中将数据写出到 SequenceFile 的做法也很类似。可以直接调用 saveSequenceFile(path) 保存你的 PairRDD ,它会帮你写出数据。
7、对象文件
对象文件看起来就像是对 SequenceFile 的简单封装,它允许存储只包含值的 RDD。和SequenceFile 不一样的是,对象文件是使用 Java 序列化写出的。要保存对象文件,只需在 RDD 上调用 saveAsObjectFile 就行了。读回对象文件也相当简单:用 SparkContext 中的 objectFile() 函数接收一个路径,返回对应的 RDD。