一、准备数据
1、创建 employee_copy 表,为该表创建一个联合索引 idx_name_age_position,表中插入 10 条数据
# 创建 employee_copy 表
CREATE TABLE `employee_copy` (
`id` int AUTO_INCREMENT COMMENT '主键 id',
`name` varchar(32) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int DEFAULT '0' NOT NULL COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
# 存储过程插入 10 条数据
delimiter $$$
create procedure insert_employee_10()
begin
declare i int default 0;
set i=1;
start transaction;
while i <= 10 do
insert into employee_copy(name, age, position, hire_time) values (CONCAT('summer',i),i,'dev',now());
set i=i+1;
end while;
commit;
end;;
delimiter ;
call insert_employee_10();
2、创建 employee 表,该表与 employee_copy 表一致,唯一不同的是 employee_copy 存在 10 条数据,而 employee 存在 100 万条数据
# 创建 employee 表
CREATE TABLE `employee` (
`id` int AUTO_INCREMENT COMMENT '主键 id',
`name` varchar(32) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int DEFAULT '0' NOT NULL COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
# 存储过程插入 100 万条数据
delimiter $$$
create procedure insert_employee_1000000()
begin
declare i int default 0;
set i=1;
start transaction;
while i <= 1000000 do
insert into employee(name, age, position, hire_time) values (CONCAT('summer',i),i,'dev',now());
set i=i+1;
end while;
commit;
end;;
delimiter ;
call insert_employee_1000000();
二、执行计划
1、like '%xxx%' (前后模糊)
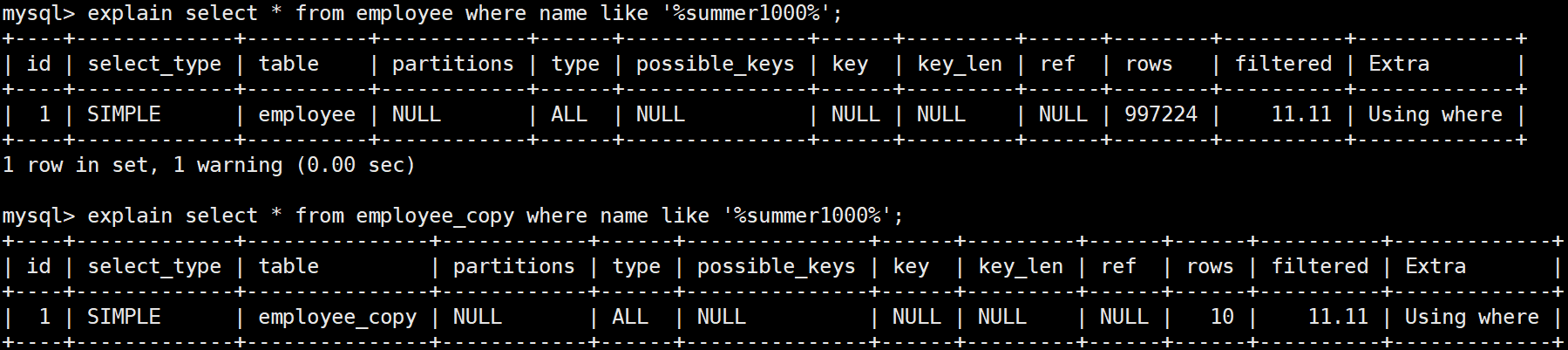
前后模糊查询,两张表不管数据量大还是数据量小,都是全表扫描
2、like '%xxx' (前模糊)
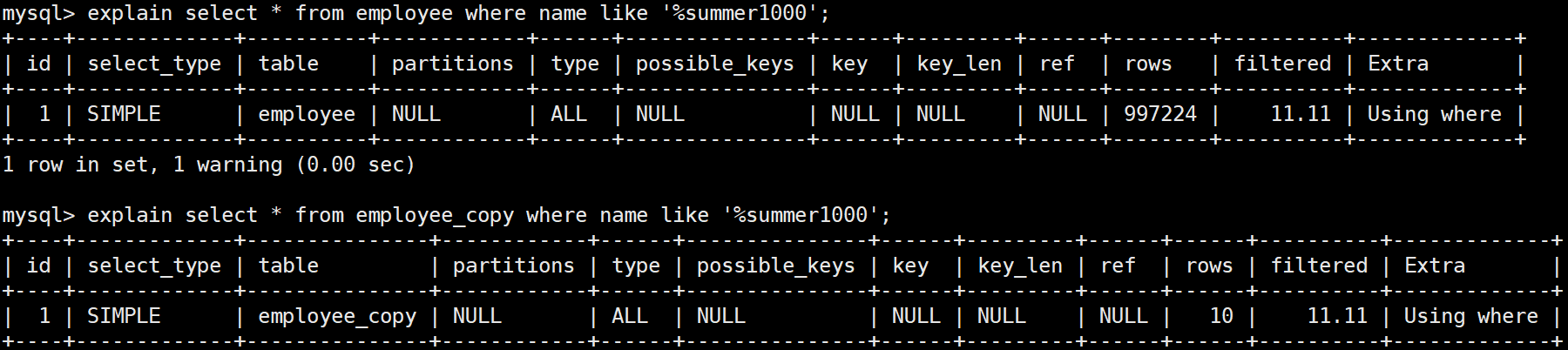
前模糊查询,两张表不管数据量大还是数据量小,都是全表扫描
3、like 'xxx%' (后模糊)

后模糊查询,两张表不管数据量大还是数据量小,都使用了索引
那么后模糊查询就一定会使用到索引吗?
看一个例子
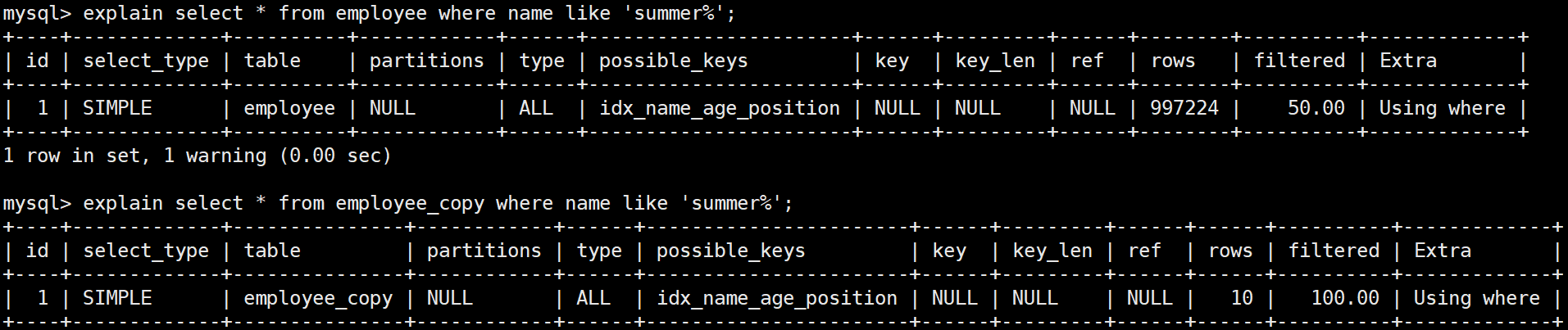
在大家的认知中后模糊查询是可以走索引的,确实,在大多数情况下后模糊查询是可以用到索引的,但是这里为什么没有使用索引,而使用全表扫描呢?
这是由于模糊查询匹配到的数据量过大导致的,看一下我们上面的 Sql 语句查询到的数据量是多少

employee 全表数据是 100 万,根据模糊条件匹配到符合条件的数据也是 100 万,而查询条件又是 select * 这种方式的,这就会涉及到回表,Mysql 在计算 cost 成本的时候大致有两个选择
1、从联合索引上查找到 100 万的数据,拿到每一条数据的主键 id,然后根据主键 id 回表,去主键索引上把 100 万记录查找出来,返回
2、直接全表扫描 100 万条记录,返回
对比上面两个操作,很明显可以看出,全表的 cost 成本更低
前模糊、前后模糊的情况可以优化吗?
答案是有的,尽量使用覆盖索引,保证需要查询的字段都是覆盖索引的字段

从上面的执行计划可以看出,需要查询的 name、age、position 字段都是覆盖索引的字段,Mysql 可以全表扫描索引树,而不用扫描聚集索引,性能是有提升的,但是个人感觉性能提升不是很明显,like 这种模糊查询,如果不能满足后模糊的情况下,尽量使用搜索引擎,类似于 ES
三、总结
1、前模糊('%xxx' )、前后模糊 ('%xxx%') 会导致索引失效,因为
2、后模糊('xxx%') 在大多数情况下是可以使用到索引的,但是不绝对,如果后模糊匹配到的数据过大,需要回表的次数过多,那么使用索引的成本可能会高于全表扫描,Mysql 底层就会选择成本更低的全表扫描,索引就失效了
3、如果模糊查询没有其它的替代方式,可以考虑使用覆盖索引,如果覆盖索引不满足条件,那么尽量使用搜索引擎去替代(例如 ES)