(1)冒泡排序
解决方案有两种:第一种是以当前位置的元素与后面的元素作比较,将如果比这个当前元素小,就交换,一轮循环下来,保证当前元素的值是最小的。
第二种是它重复地走访过要排序的元素,依次比较相邻两个元素,如果他们的顺序错误就把他们调换过来,直到没有元素再需要交换,排序完成。这个算法 名字由来是因为越小(或越大)的元素会经由交换慢慢“浮”到数列的顶端
对序列{ 6, 5, 3, 1, 8, 7, 2, 4 }进行冒泡排序的实现过程如下:
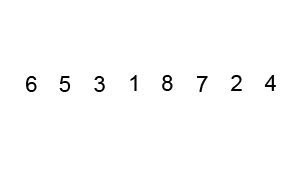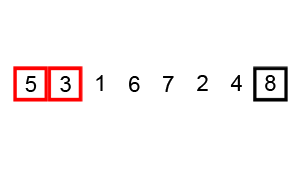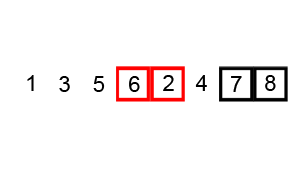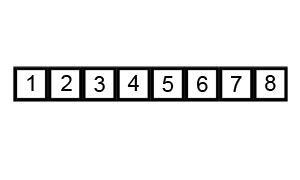
(2)选择排序
原理如下:现在现有序列当中找到最大(最小)的元素,放在序列的起始位置。然后再从剩余未排序的元素当中寻找最大(最小)的元素,接着放在已排好序列的后面。
冒泡排序和选择排序的区别如下:
冒泡排序是通过依次交换相邻两个顺序不合法的元素位置,从而将当前最小(大)元素放到合适的位置;而选择排序每遍历一次都记住了当前最小(大)元素的位置,最后仅需一次交换操作即可将其放到合适的位置。
// 分类 -------------- 内部比较排序 // 数据结构 ---------- 数组 // 最差时间复杂度 ---- O(n^2) // 最优时间复杂度 ---- O(n^2) // 平均时间复杂度 ---- O(n^2) // 所需辅助空间 ------ O(1) // 稳定性 ------------ 不稳定
上述代码对序列{ 8, 5, 2, 6, 9, 3, 1, 4, 0, 7 }进行选择排序的实现过程如右图 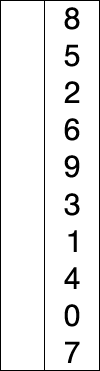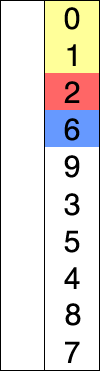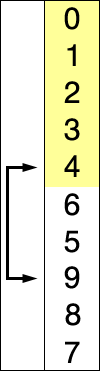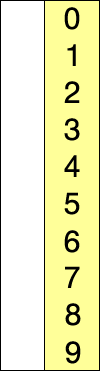
(3)插入排序
具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
// 分类 ------------- 内部比较排序 // 数据结构 ---------- 数组 // 最差时间复杂度 ---- 最坏情况为输入序列是降序排列的,此时时间复杂度O(n^2) // 最优时间复杂度 ---- 最好情况为输入序列是升序排列的,此时时间复杂度O(n) // 平均时间复杂度 ---- O(n^2) // 所需辅助空间 ------ O(1) // 稳定性 ------------ 稳定
(4)归并排序
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。
分而治之

// 分类 -------------- 内部比较排序 // 数据结构 ---------- 数组 // 最差时间复杂度 ---- O(nlogn) // 最优时间复杂度 ---- O(nlogn) // 平均时间复杂度 ---- O(nlogn) // 所需辅助空间 ------ O(n) // 稳定性 ------------ 稳定
(5)快速排序)
选择一个基数,并且设置数组的两端left和right,将比base大的数字放在右边,比基数小的则放在左边。具体操作如下:
先从右端开始,如果遇到比基数大的数字,则right--,如果遇到比基数小的数字,和A[left]进行调换,并且将left++,从左端开始。依次循环,知道left == right。此时将基数的值放在A[left]。并且在每次两端靠近的时候,也要判断left<right。
// 最差时间复杂度 ---- 每次选取的基准都是最大(或最小)的元素,导致每次只划分出了一个分区,需要进行n-1次划分才能结束递归,时间复杂度为O(n^2) // 最优时间复杂度 ---- 每次选取的基准都是中位数,这样每次都均匀的划分出两个分区,只需要logn次划分就能结束递归,时间复杂度为O(nlogn) // 平均时间复杂度 ---- O(nlogn) // 所需辅助空间 ------ 主要是递归造成的栈空间的使用(用来保存left和right等局部变量),取决于递归树的深度,一般为O(logn),最差为O(n) // 稳定性 ---------- 不稳定
(6)堆排序
步骤如下:
(1)将待排序的数组首先要变成大顶堆(从最后一个不是叶子节点开始)
(2)将最顶的元素与最后一个元素进行调换,并且使得节点数目减一
(3)进行调换后,可能存在不是大顶堆的情况,调用自身函数,将其变成大顶堆
(6)希尔排序
是插入排序的一种更高效的改进版本。希尔排序是不稳定的排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
希尔排序通过将比较的全部元素分为几个区域来提升插入排序的性能。这样可以让一个元素可以一次性地朝最终位置前进一大步。然后算法再取越来越小的步长进行排序,算法的最后一步就是普通的插入排序,但是到了这步,需排序的数据几乎是已排好的了(此时插入排序较快)。
假设有一个很小的数据在一个已按升序排好序的数组的末端。如果用复杂度为O(n^2)的排序(冒泡排序或直接插入排序),可能会进行n次的比较和交换才能将该数据移至正确位置。而希尔排序会用较大的步长移动数据,所以小数据只需进行少数比较和交换即可到正确位置。