1.1安装Scrapy框架
先安装vc++运行库,https://blog.csdn.net/qq_38161040/article/details/88203864
pip安装pywin32包,输入命令pip install pywin32,然后按顺序安装Twisted,lxml,Scrapy。
1.2创建一个scrapy项目
新创建一个目录,按住shift-右键-在此处打开命令窗口,输入:scrapy startproject tnt,即可创建一个tnt文件夹
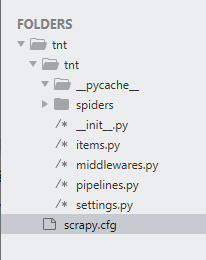
文件的功能:
scrapy.cfg:配置文件
spiders:存放你Spider文件,也就是你爬取的py文件
items.py:抓取内容描述
middlewares.py:定义Downloader Middlewares(下载器中间件)和Spider Middlewares(蜘蛛中间件)的实现
pipelines.py:定义Item Pipeline的实现,实现数据的清洗,储存,验证。
settings.py:全局配置
cd到tnt文件夹下,按住shift-右键-在此处打开命令窗口,输入:scrapy genspider top250 movie.douban.com/top250
top250是爬虫名,movie.douban.com/top250是域名
我们来看一下使用命令创建的有什么。
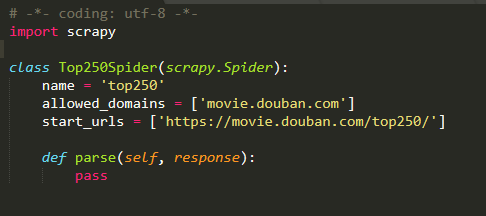
name:爬虫名
allowed_domains:是爬取的域名。
start_urls:是Spider爬取的网站,定义初始的请求url,可以多个。
parse方法:将网页源码生成soup对象,然后解析出数据item通过生成器yield返回,并指定URL的处理函数为self.parse。
response参数:是请求网页后返回的内容,也就是你需要解析的网页。
from scrapy import Item,Field
class TntItem(Item):
# define the fields for your item here like:
name = Field()
fen = Field()
words = Field()
1.5修改爬虫文件top250.py:
# -*- coding: utf-8 -*-
import scrapy
from items import TntItem
from bs4 import BeautifulSoup
import re
class Top250Spider(scrapy.Spider):
name = 'top250'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250/']
def parse(self, response):
soup=BeautifulSoup(response.body.decode('utf-8','ignore'),'lxml')
ol=soup.find('ol',attrs={'class':'grid_view'})
for li in ol.find_all('li'):
tep=[]
titles=[]
for span in li.find_all('span'):
if span.has_attr('class'):
if span.attrs['class'][0]=='title':
titles.append(span.string.strip().replace(',',',')) #获取电影名
elif span.attrs['class'][0]=='rating_num':
tep.append(span.string.strip().replace(',',',')) #获取评分
elif span.attrs['class'][0]=='inq':
tep.append(span.string.strip().replace(',',',')) #获取评论
tep.insert(0,titles[0])
item=TntItem()
item['name']=tep[0]
item['fen']=tep[1]
item['words']=tep[2]
yield item
a=soup.find('a',text=re.compile("^后页"))
if a:
yield scrapy.Request("https://movie.douban.com/top250"+
a.attrs['href'],callback=self.parse)
urllib.parse.urljoin(),构建完整的绝对url
>>>from urllib.parse import urljoin
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "anotherpage.html")
'http://www.chachabei.com/folder/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "/anotherpage.html")
'http://www.chachabei.com/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "folder2/anotherpage.html")
'http://www.chachabei.com/folder/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "/folder2/anotherpage.html")
'http://www.chachabei.com/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/abc/folder/currentpage.html", "/folder2/anotherpage.html")
'http://www.chachabei.com/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/abc/folder/currentpage.html", "../anotherpage.html")
'http://www.chachabei.com/abc/anotherpage.html'
import csv
class TntPipeline(object):
def __init__(self):
self.fp=open('TOP250.csv','w',encoding='utf-8')
self.wrt=csv.DictWriter(self.fp,['name','fen','words'],lineterminator='
') #lineterminator='
'作用是不换行
self.wrt.writeheader()
def __del__(self):
self.fp.close()
def process_item(self, item, spider):
self.wrt.writerow(item)
return item
BOT_NAME = 'tnt'
SPIDER_MODULES = ['tnt.spiders']
NEWSPIDER_MODULE = 'tnt.spiders'
#添加用户代理
USER_AGENT='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
# 当爬取内容不符合该协议且仍要爬取时,设置 ROBOTSTXT_OBEY = False ,不遵守此协议
ROBOTSTXT_OBEY = False
ITEM_PIPELINES={
'tnt.pipelines.TntPipeline':300,
}
from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings from spiders.top250 import Top250Spider #获取settings.py模块的位置 settings=get_project_settings() process=CrawlerProcess(settings=settings) #可以添加多个spider #process.crawl(Spider1) #process.crawl(Spider2) process.crawl(Top250Spider) #启动爬虫,会阻塞,直到爬取完成 process.start()
#1、xpath取文本 response.xpath("//div[@id='images']/text()").extract_first() #取标签属性 response.xpath("//div[@id='images']/@class").extract() #模糊匹配 response.xpath('//div[contains(@href,"image")]/@href').extract() #二次定位 items=response.xpath('//div[@id="images"]') for item in items: #需要加.// title=item.xpath('.//a/text()').extract() #正则匹配 response.xpath('//div').re('sd') response.xpath('//div').re_first('') #正则匹配第一个 #2、css取文本 name = item.css(".images>a::text").extract_first() #取标签属性 link = item.css(".images>a::attr(href)").extract_first() #模糊匹配 response.css('a[href*=image]::attr(href)').extract() #二次定位 items=response.css('div .images') for item in items: #不需要加.// title_1=item.css('a::text').extract()