性能监测着重于计算机系统资源监测,是对系统进行预防性维护的必要工作,可通过分析监视数据来了解系统存在哪些瓶颈,应当采取何种措施来调整或更新受影响的资源, Linux系 统提供了多种性能监测工具来帮助管理员完成系统监控工作;
1》性能监测概述:
系统性能监测与调整是Linux系统管理员日常维护工作的一项非常重要的内容,要衡量一个系统的性能状态,可以从系统的响应时间以及系统吞吐量两个角度来进行分析,响应 时间是指发出请求的时刻到用户获得返回结果所需要的时间,吞吐量是指在给定时间段内系统完成的交易数量,系统的吞吐量越大,系统的处理能力也就越强;管理员在进行性能监 测中的一个主要任务就是要找出系统的性能瓶颈所在,然后有针对性地进行调整,性能瓶颈是指那些对系统的性能起决定性影响的因素,不同的应用系统,性能瓶颈也有所不同,繁 忙的文件服务器的性能瓶颈大多是磁盘子系统,大量用户在线的应用程序服务器的性能瓶颈可能是CPU子系统,而各种Internet网络服务器的性能瓶颈通常是网络带宽,需要进行监测 的系统资源主要是CPU,内存,磁盘和网络;
红帽5图形界面提供有一个类似于Windows任务管理器的性能监测-----系统监视器;从主菜单“系统”中选择“管理”>“系统监视器”命令即可打开系统监视器,实时地查看进程, CPU,内存,网络和文件系统等信息;
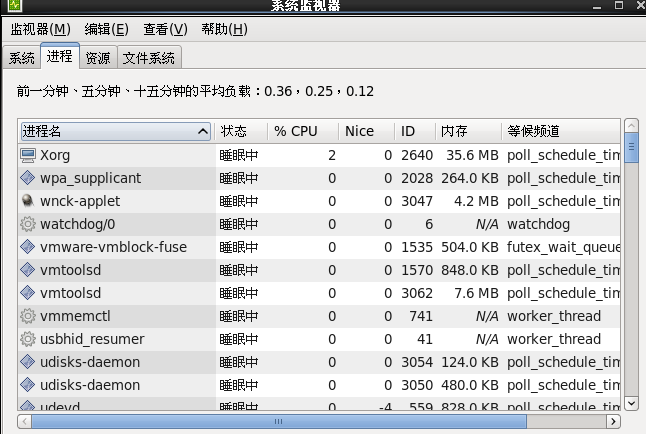
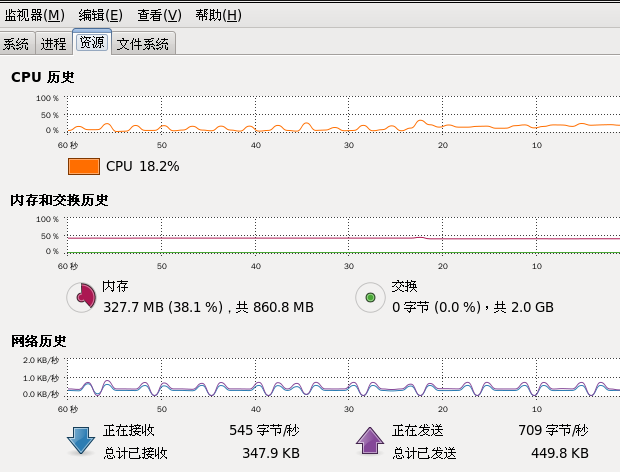
系统监视器虽然很方便,但功能有限,如果要对系统性能 做进一步分析,必须要借助一些性能监视工具,如vmstat,mpstat,iostat,sar和top等,mpstat提供CPU相关数据;sar用 于收集,报告并存储系统活动的信息;iostat提供CPU使用率及硬盘吞吐率的数据,vmstat可对虚拟内存,进程,CPU活动的总体情况进行统计;top是一个非常优秀的交互式综合性 能监测工具;iostat和sar命令由sysstat软件包提供,默认没有安装,安装红帽5的第三张光盘中的sysstat软件包sysstat-7.0.0-3.el5.i386.rpm即可;
2》CPU性能监测:
CPU决定着系统的运算能力,系统内所有的程序指令都是经过CPU处理的,由于Linux自身是一个多用户多任务的操作系统,因此CPU同时处理着来自不同优先等级的程序,如 果过多的程序同时执行,CPU就有可能形成系统的性能瓶颈;关于CPU的总体性能情况,可以使用sar命令进行查看,sar命令的基本用法如下:
sar [选项] [采样间隔] [采样次数]
采样的时间间隔单位是秒,管理员可以根据需要按照一定的采样间隔收集一定时间段的性能数据进行分析,以了解系统的性能状况,为更准确地评估系统的性能,应该分析一 段时间内而不是单纯某个具体时刻的性能数据,列如每隔5秒收集一次CPU性能数据,共收集三次,可以运行以下命令:
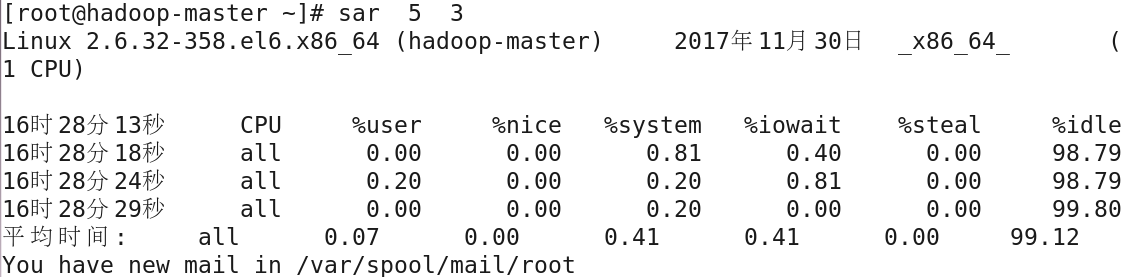
上述信息中列出了采样时间,并对CPU的使用率按类目分类统计,最后一行是平均值,其中,%user表示用户进程的CPU时间占用率;%nice表示用户进程的nice操作(特 权进程)的CPU时间占用率;%system表示系统进程的CPU时间占用率;%iowait表示等待磁盘I/O所消耗的CPU时间占用率;%steal表示虚拟设备的CPU时间占用率;%idel表示 CPU空闲时间所占百分比;sar命令显示CPU总的性能情况,对于有多处理器系统或者多核心的处理器,可以使用mpstat命令分别查看各个CPU的情况,语法格式如下:
mpstat [-P CPU编号|ALL] [采样间隔] [采样次数]
通过选项-P来指定要查看的CPU,CPU编号从0开始,例如查看第一个CPU:

该命令提供的信息比sar多3种,%irq列表表示硬中断的CPU时间占用率,%soft列表示软中断的CPU时间占用率,intr/s列表示每秒钟处理的中断次数(次/秒);
3》内存性能监测:
计算机的内存是有一定容量的,当所需要的内存数量超过物理内存的容量时,系统会使用虚拟内存的分页技术和交换技术,即将程序进程的一部分或全部移到硬盘上,以便为 新的进程腾出空间,当分页和交换不太频繁时,系统是完全可以接受的,当频繁地进行分页和交换时,系统性能就会受到影响,从而形成性能瓶颈;
1>使用free命令显示系统的各种内存情况:
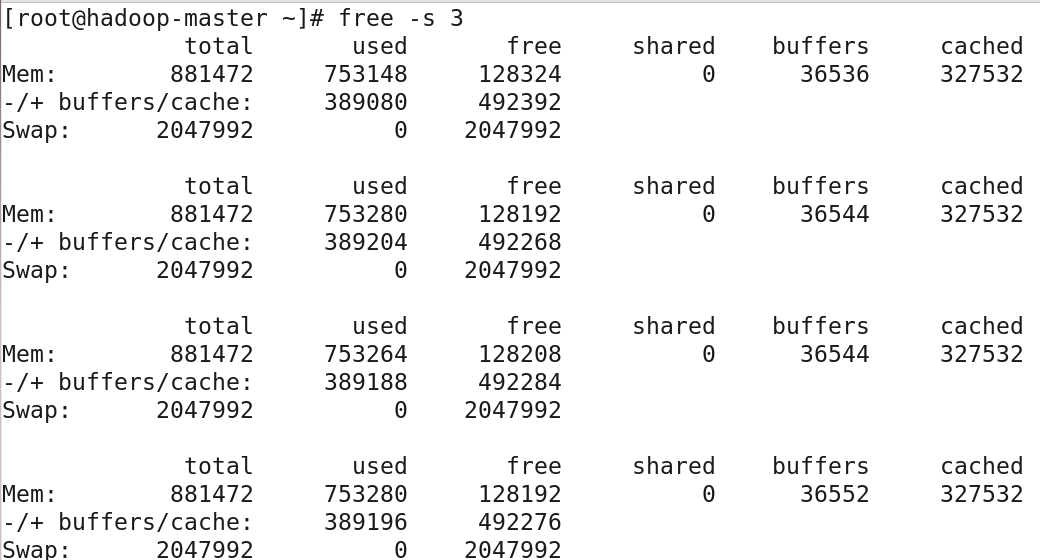
free命令可以用来查看内存和虚拟内存的使用情况,默认单位KB,这里给出一个实例:

Mem行显示的是物理内存,total列显示物理内存总量,used列显示使用量(分配给缓存使用的数量,其中可能部分缓存并未实际使用),free列表示可用量(未被分 配的内存),shared列显示多个进程共享的内存,buffers列显示系统分配但未被使用的缓冲(用作缓冲区的内存数量),cache列显示系统分配但未被使用的缓存(用作高 速缓存的内存数量);
提示:buffers与cache都占用内存,应注意他们的区别,buffers是块设备的读写缓存区,是存放待写到磁盘上的数据的内存,是物理级的,它根据磁盘的读写设 计,将分散的写操作集中进行,以减少磁盘碎片和反复寻道,提高系统性能;cache一般意思是缓存,是作为页面高速缓存的内存,属于文件系统,存放从磁 盘读取后待处理的数据,它将读取过的数据保存起来,重新读取时若命中(找到需要的数据)就不去读取硬盘,若没有命中就读硬盘,当然,其中的数据根据 读取频率进行组织,会将最频繁读取的内容放在最容易找到的位置;
接下来的一行显示应用程序的内存使用,两列分别显示真正用掉的内存(分配给缓存使用的数量减去未被使用的buffers与cache,也就是实际使用的buffers与cache总 量)和系统当前实际可用的内存(未被使用的buffers与cache和未被分配的内存之和),“-/+”符号表示buffers/cache的大小是可以改变的,不是实际占内存的;
最后一行Swap显示交换空间内存的使用状态,3列分别显示交换的容量(total),使用量(used)和可用的空闲交换区(free);要通过free进行一段时间的内存使用 监测,可以使用-s选项指定一个时间间隔(单位s)进行持续的监测:
2>使用vmstat命令全面监测内存:
要全面监测内存性能,可以使用vmstat命令,vmstat命令可以用来显示物理内存和虚拟内存的有关状态,同时也可以显示CPU的有关信息:

vmstat命令监测的数据比较多,分成几大类来显示:
procs(进程)部分的r,b列分别显示准备就绪等待运行的进程数量和处于不可中断的休眠状态的进程数量,所谓不可中断的休眠状态是指进程收到任何信号都不 会被唤醒成为可运行状态,将一直等待硬件状态的改变;
memore(内存)部分的swpd,free,buff和cache列分别显示虚拟内存的使用量,空闲物理内存,内存缓冲区和高速缓存的大小;
swap(交换)部分的si和so列分别显示每秒交换到磁盘和从磁盘中读取的字节数;
io(输入输出)部分的bi和bo列分别显示每秒写入块设备和从块设备中读取的快数;
system(系统)部分的in和cs列分别显示每秒中断(包括时钟中断)和上下文切换(context switches)的次数,当一个进程用完时间片或者被更高优先级的 进程抢占时间块后,它会被转到CPU的等待运行队列中,同时让其他进程在CPU上运行,这个进程切换的过程被称作上下文切换,过多的上 下文切换会造成系统很大的开销;
cpu部分是显示占用CPU时间的百分比,u表示用户进程时间,sy表示系统进程时间,id表示空闲时间,wa表示等待时间,st表示虚拟机占用时间;
vmstat命令也可以指定数据采样间隔和采样次数,即使用以下格式:
vmstat [采样间隔] [采样次数]

4》磁盘I/O性能监测:
由于磁盘设备的运行速度比CPU的指令处理速度要慢很多,因此涉及磁盘操作的部分是整个过程执行过程中最慢的操作,尽管磁盘自身硬件技术如转速,缓存等不断提 高,但是磁盘依然很容易形成系统性能的瓶颈;iostat工具可以对系统的磁盘操作活动进行监测,并报告磁盘活动统计情况,包括数据吞吐量和传输请求等数据,基本用法如下:
iostat [选项] [采样间隔] [采样次数]
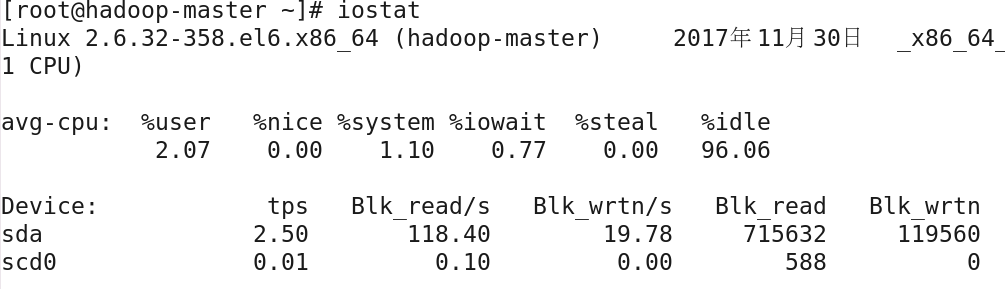
默认情况下,iostat命令按磁盘设备(Device列)来显示汇总的使用情况,并显示CPU使用情况(avg-cpu部分),如果加上选项-d将只统计磁盘使用情况,关于磁盘的 数据使用情况,具体的统计数据包括5项:tps表示每秒发送到设备上的I/O请求次数;BLK_read/s和BLK_wrtn/s分别表示设备每秒读取和写入数据的快数;BLK_read和 BLK_wrtn分别表示设备读取和写入数据的总快数;如果要查看磁盘中分区的使用情况,可以使用-p选项指定分区;选项-t表示在每次的统计结果中显示时间,如果要改变磁盘使 用统计单位块,使用选项-k以KB代替块,-m以MB代替块;
另外,还可以使用sar -b命令统计I/O和传输速率,默认以10分钟作为一个间隔显示最近一段时间以来的数据,统计内容包括5项:tps表示每秒从物理磁盘I/O请求的次 数(多个逻辑请求会被合并为一个I/O磁盘请求,一次传输的大小不确定),rtps和wtps分别表示每秒钟读请求和写请求的次数,bread/s和bwrtn/s分别表示每秒钟从磁盘读取和 写入到磁盘的数据的快数;
5》通过top实现综合监控:
top命令是一个非常优秀的交互式性能监测工具,可以在一个统一的界面中按照用户指定的时间间隔刷新显示包括内存,CPU,进程,用户数据,运行时间等的性能信息, 其命令格式如下:
top -hv | -bcHisS -d 刷新间隔 -n 刷新次数 -p pid [,pid....]
选项-p pid表示只显示指定的pid进程信息,top命令运行结果如下:

第一行(top):显示系统运行时间,用户数以及负载的平均值信息;
第二行(Tasks):显示进程的概要信息,分别是当前进程总数,正在运行的进程数,正在休眠的进程数,已停止的进程数和僵死的进程数;
第三行(CPU):显示CPU占用百分比,分别是用户进程,系统进程,改变过优先级的用户进程,空闲状态,等待I/O,硬件中断,软件中断和虚拟设备所占的CPU百分 比;
第四行(Mem):显示物理内存信息,分别是物理内存总量,已使用的物理内存数量,未被使用的物理内存数量,用作缓冲区的内存数量;
第五行(Swap):显示虚拟内存信息,分别是虚拟内存总量,已使用的虚拟内存数量,空闲的虚拟内存数量,用作缓存的虚拟内存数量;
最后一部分是每个进程的性能统计信息,每个进程有12项信息:PID(进程ID),USER(执行进程的用户),PR(优先级),NI(nice值),VIRT(进程使用 的虚拟内存大小),RES(进程使用的物理内存大小),SHR(共享内存),S(进程状态),%CPU(占用CPU百分比),%MEM(使用物理内存的百分比), TIME+(使用CPU的时间),COMMAND(进程的名称);
6》优化系统性能:
优化系统性能的基本步骤可以归纳 如下:
1)使用监测工具监视系统的活动;
2)分析得到的性能数据,找出不能满足性能要求的环节;
3)分析造成性能降低的原因,采取相应的优化措施;
提高系统性能常用的方法是从硬件配置上提高性能,例如用SCSI接口硬盘代替IDE硬盘,使用多个硬盘建立RAID,使用尽可能大的物理内存,使用多处理系统等;
如果只是进行Linux默认的安装,而不对其中涉及性能的选项进行具体详细的配置,系统的性能往往不会达到最优化的效果,通过对内核的调整可以使系统整体性能达 到最优,建议在调整内核的时候,先将内核升级到一个比较新的内核版本,一般来说,新的内核版本对于性能方面有更多的选项给予支持,为使性能达到最优,应该根据用户 自己的需要,主动舍弃一些占用资源太多的功能,配置一个适合自己的自定义内核;
系统目前CPU使用率高是由于IO等待所造成的,并非由于CPU资源不足,用户应检查系统中正在进行IO操作的进程,并进行调整和优化;
系统的空闲内存少不一定说明系统性能有问题,这需要结合si和so(内存和磁盘的页面交换)两个指标进行分析,当物理内存能足以存放所有进程的数据,物理内存 和磁盘(虚拟内存)是不应该存在频繁的页面交换操作的,只有当物理内存不能满足需要时系统才会把内存中的数据交换到磁盘中,由于磁盘的性能是比内存慢很多的,所以 如果存在大量的页面交换,那么系统的性能必然会受到很大影响;