第1章 需求分析和实现思路
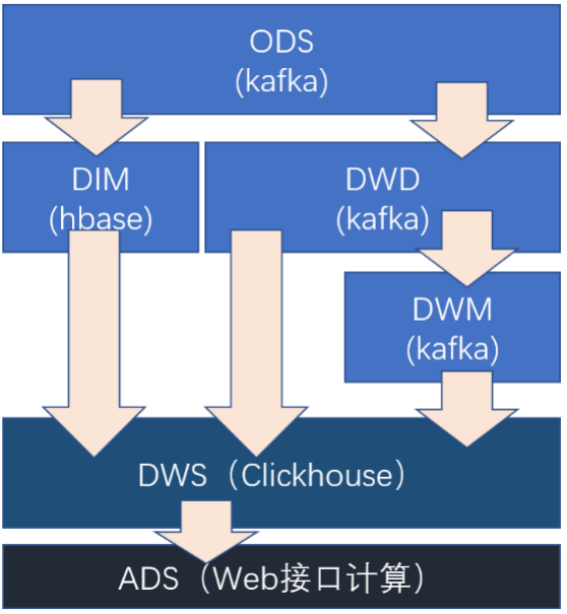
1.1 实时数仓分层
在之前介绍实时数仓概念时讨论过,建设实时数仓的目的,主要是增加数据计算的复用性。每次新增加统计需求时,不至于从原始数据进行计算,而是从半成品继续加工而成。我们这里从kafka的ods层读取用户行为日志以及业务数据,并进行简单处理,写回到kafka作为dwd层。
1.2 每层职能
|
分层 |
数据描述 |
生成计算工具 |
存储媒介 |
|
ODS |
原始数据,日志和业务数据 |
日志服务器,maxwell |
kafka |
|
DWD |
根据数据对象为单位进行分流,比如订单、页面访问等等。 |
FLINK |
kafka |
|
DWM |
对于部分数据对象进行进一步加工,比如独立访问、跳出行为。依旧是明细数据。 进行了维度冗余(宽表) |
FLINK |
kafka |
|
DIM |
维度数据 |
FLINK |
HBase |
|
DWS |
根据某个维度主题将多个事实数据轻度聚合,形成主题宽表。 |
FLINK |
Clickhouse |
|
ADS |
把Clickhouse中的数据根据可视化需要进行筛选聚合。 |
Clickhouse SQL |
可视化展示 |
第2章 Flink计算环境搭建
2.1 创建实时计算module
2.2 添加需要的依赖
<properties> <flink.version>1.13.1</flink.version> <scala.binary.version>2.12</scala.binary.version> <hadoop.version>3.1.3</hadoop.version> <slf4j.version>1.7.30</slf4j.version> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime-web_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.14.0</version> <scope>provided</scope> </dependency> <!-- https://mvnrepository.com/artifact/org.projectlombok/lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.16</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.75</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-cep_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-csv</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-json</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.16</version> </dependency> <!--commons-beanutils是Apache开源组织提供的用于操作JAVA BEAN的工具包。 使用commons-beanutils,我们可以很方便的对bean对象的属性进行操作--> <dependency> <groupId>commons-beanutils</groupId> <artifactId>commons-beanutils</artifactId> <version>1.9.3</version> </dependency> <dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>flink-connector-mysql-cdc</artifactId> <version>1.4.0</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.1.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <artifactSet> <excludes> <exclude>com.google.code.findbugs:jsr305</exclude> <exclude>org.slf4j:*</exclude> <exclude>log4j:*</exclude> </excludes> </artifactSet> <filters> <filter> <!-- Do not copy the signatures in the META-INF folder. Otherwise, this might cause SecurityExceptions when using the JAR. --> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers combine.children="append"> <transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build>
2.3 添加log4j.properties
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
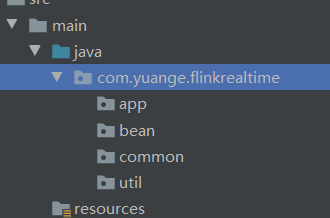
2.4 创建包结构
|
包 |
作用 |
|
app |
产生各层数据的flink任务 |
|
bean |
数据对象 |
|
common |
公共常量 |
|
util |
工具类 |
第3章 DWD层: 用户行为日志
我们前面采集的日志数据已经保存到Kafka中,作为日志数据的ODS层,从kafka的ODS层读取的日志数据分为3类: 页面日志、启动日志和曝光日志。这三类数据虽然都是用户行为数据,但是有着完全不一样的数据结构,所以要拆分处理。将拆分后的不同的日志写回Kafka不同主题中,作为日志DWD层。
页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光侧输出流
3.1 日志格式
1)页面日志格式
{ "common":{ "ar":"110000", "ba":"Xiaomi", "ch":"xiaomi", "is_new":"0", "md":"Xiaomi 9", "mid":"mid_20", "os":"Android 11.0", "uid":"47", "vc":"v2.1.134" }, "page":{ "during_time":13968, "last_page_id":"home", "page_id":"search" }, "ts":1614575952000 }
2)启动日志格式
{ "common":{ "ar":"110000", "ba":"iPhone", "ch":"Appstore", "is_new":"0", "md":"iPhone 8", "mid":"mid_19", "os":"iOS 13.3.1", "uid":"50", "vc":"v2.1.134" }, "start":{ "entry":"notice", "loading_time":9286, "open_ad_id":15, "open_ad_ms":6825, "open_ad_skip_ms":0 }, "ts":1614575950000 }
3)曝光日志格式
{ "common":{ "ar":"110000", "ba":"iPhone", "ch":"Appstore", "is_new":"0", "md":"iPhone 8", "mid":"mid_19", "os":"iOS 13.3.1", "uid":"50", "vc":"v2.1.134" }, "displays":[ { "display_type":"activity", "item":"2", "item_type":"activity_id", "order":1, "pos_id":4 }, { "display_type":"activity", "item":"2", "item_type":"activity_id", "order":2, "pos_id":4 }, { "display_type":"promotion", "item":"4", "item_type":"sku_id", "order":3, "pos_id":5 }, { "display_type":"query", "item":"6", "item_type":"sku_id", "order":4, "pos_id":1 }, { "display_type":"promotion", "item":"3", "item_type":"sku_id", "order":5, "pos_id":5 }, { "display_type":"query", "item":"2", "item_type":"sku_id", "order":6, "pos_id":2 }, { "display_type":"query", "item":"7", "item_type":"sku_id", "order":7, "pos_id":3 }, { "display_type":"query", "item":"3", "item_type":"sku_id", "order":8, "pos_id":4 }, { "display_type":"query", "item":"9", "item_type":"sku_id", "order":9, "pos_id":1 }, { "display_type":"promotion", "item":"3", "item_type":"sku_id", "order":10, "pos_id":5 }, { "display_type":"query", "item":"8", "item_type":"sku_id", "order":11, "pos_id":2 } ], "page":{ "during_time":8319, "page_id":"home" }, "ts":1614575950000 }
3.2 主要任务
1)识别新老客户
本身客户端业务有新老用户的标识,但是不够准确,需要用实时计算再次确认(不涉及业务操作,只是单纯的做个状态确认)。
2)数据拆分
3)不同数据写入Kafka不同的Topic中(dwd层数据)
3.3 具体实现代码清单
3.3.1 封装kafka工具类
1)FlinkSourceUtil
package com.yuange.flinkrealtime.util; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import java.util.Properties; /** * @作者:袁哥 * @时间:2021/7/28 18:42 */ public class FlinkSourceUtil { public static FlinkKafkaConsumer<String> getKafkaSource(String groupId, String topic){ Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092"); properties.setProperty("group.id", groupId); //如果启动的时候, 这个消费者对这个topic的消费没有上次的消费记录, 就从这个配置的位置开始消费 //如果有消费记录, 则从上次的位置开始消费 properties.setProperty("auto.offset.reset", "latest"); properties.setProperty("isolation.level", "read_committed"); return new FlinkKafkaConsumer<>( topic, new SimpleStringSchema(), properties ); } }
2)FlinkSinkUtil
package com.yuange.flinkrealtime.util; import lombok.SneakyThrows; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema; import org.apache.kafka.clients.producer.ProducerRecord; import javax.annotation.Nullable; import java.util.Properties; /** * @作者:袁哥 * @时间:2021/7/28 18:33 */ public class FlinkSinkUtil { public static FlinkKafkaProducer<String> getKafkaSink(final String topic){ Properties conf = new Properties(); conf.setProperty("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092"); conf.setProperty("transaction.timeout.ms", 15 * 60 * 1000 + ""); return new FlinkKafkaProducer<String>( "default", new KafkaSerializationSchema<String>() { @SneakyThrows public ProducerRecord<byte[], byte[]> serialize(String s, @Nullable Long aLong) { return new ProducerRecord<byte[], byte[]>(topic,null,s.getBytes("utf-8")); } }, conf, FlinkKafkaProducer.Semantic.EXACTLY_ONCE ); }; }
3)YuangeCommonUtil
package com.yuange.flinkrealtime.util; import java.util.ArrayList; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/28 18:48 */ public class YuangeCommonUtil { public static<T> List<T> toList(Iterable<T> it){ List<T> list = new ArrayList<>(); for (T t : it) { list.add(t); } return list; } }
3.3.2 封装消费Kafka数据的BaseApp类
package com.yuange.flinkrealtime.app; import com.yuange.flinkrealtime.util.FlinkSourceUtil; import org.apache.flink.configuration.Configuration; import org.apache.flink.runtime.state.hashmap.HashMapStateBackend; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.CheckpointConfig; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/28 18:53 */ public abstract class BaseAppV1 { public void init(int port, int p, String ck, String groupId, String topic){ System.setProperty("HADOOP_USER_NAME","atguigu"); Configuration configuration = new Configuration(); configuration.setInteger("rest.port",port); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(configuration).setParallelism(p); environment.enableCheckpointing(5000); //检查点之间的时间间隔,单位是毫秒 environment.setStateBackend(new HashMapStateBackend()); //定义状态后端,以保证将检查点状态写入远程(HDFS) environment.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop162:8020/FlinkParent/ck/" + ck); //配置检查点存放地址 environment.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); //设置检查点模式:精准一次 environment.getCheckpointConfig().setMaxConcurrentCheckpoints(1); //设置检查点失败时重试次数 environment.getCheckpointConfig() .enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); //设置检查点持久化:取消作业时保留外部化检查点 DataStreamSource<String> sourceStream = environment.addSource(FlinkSourceUtil.getKafkaSource(groupId, topic)); run(environment,sourceStream); try { environment.execute(ck); } catch (Exception e) { e.printStackTrace(); } } protected abstract void run(StreamExecutionEnvironment environment, DataStreamSource<String> sourceStream); }
3.3.3 常量
package com.yuange.flinkrealtime.common; /** * @作者:袁哥 * @时间:2021/7/28 19:31 */ public class Constant { public static final String TOPIC_ODS_LOG = "ods_log"; public static final String TOPIC_ODS_DB = "ods_db"; public static final String TOPIC_DWD_START = "dwd_start"; public static final String TOPIC_DWD_PAGE = "dwd_page"; public static final String TOPIC_DWD_DISPLAY = "dwd_display"; }
3.3.4 DWDLogApp具体实现
3.3.4.1 识别新老访客
1)实现思路:
(1)考虑数据的乱序, 使用event-time语义
(2)按照mid分组
(3)添加5s的滚动窗口
(4)使用状态记录首次访问的时间戳
(5)如果状态为空, 则此窗口内的最小时间戳的事件为首次访问, 其他均为非首次访问
(6)如果状态不为空, 则此窗口内所有的事件均为非首次访问
2)实现代码
package com.yuange.flinkrealtime.app.dwd; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import com.yuange.flinkrealtime.app.BaseAppV1; import com.yuange.flinkrealtime.common.Constant; import com.yuange.flinkrealtime.util.YuangeCommonUtil; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import java.time.Duration; import java.util.Comparator; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/28 19:32 */ public class DwdLogApp extends BaseAppV1 { final String START_STREAM = "start"; final String PAGE_STREAM = "page"; final String DISPLAY_STREAM = "display"; public static void main(String[] args) { new DwdLogApp().init( 2001, //端口号 2, //并行度 "DwdLogApp", //检查点的存放目录名称 "DwdLogApp", //消费者组id Constant.TOPIC_ODS_LOG //主题 ); } @Override protected void run(StreamExecutionEnvironment environment, DataStreamSource<String> sourceStream) { //业务 //一、对新老用户进行确认 SingleOutputStreamOperator<JSONObject> validatedStream = distinguishNewOrOld(sourceStream); validatedStream.print(); } private SingleOutputStreamOperator<JSONObject> distinguishNewOrOld(DataStreamSource<String> sourceStream) { /** * 如何实现识别新老客户? * 需要利用状态 * 考虑数据的乱序: 使用事件时间, 加窗口 * */ //创建一个新的WatermarkStrategy来封装水印策略 return sourceStream .map(JSON::parseObject) //将数据转为JSON格式 .assignTimestampsAndWatermarks( WatermarkStrategy .<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(3)) //创建水印策略,水印是周期性生成的。这种水印策略引入的延迟是周期间隔长度加上乱序界限 .withTimestampAssigner((element, recordTimestamp) -> element.getLong("ts")) //ts + 3秒 ) .keyBy(obj -> obj.getJSONObject("common").getString("mid")) //以设备id分组 .window(TumblingEventTimeWindows.of(Time.seconds(5))) //滚动事件窗口,每5秒统计一次数据 .process(new ProcessWindowFunction<JSONObject, JSONObject, String, TimeWindow>() { //定义一个状态,以此来判断用户是否是新老用户 ValueState<Long> firstWindowState; @Override public void open(Configuration parameters) throws Exception { firstWindowState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("firstWindowState", Long.class)); } @Override public void process(String key, Context context, Iterable<JSONObject> elements, Collector<JSONObject> out) throws Exception { //如果识别出来某个mid的第一个窗口 if (firstWindowState.value() == null){ //把时间戳最小的那个条记录的is_new设置为1, 其他都为0 List<JSONObject> list = YuangeCommonUtil.toList(elements); list.sort(Comparator.comparing(o -> o.getLong("ts"))); //将JSON数据按ts排序 for (int i = 0; i < list.size(); i++) { JSONObject common = list.get(i).getJSONObject("common"); if (i == 0){ common.put("is_new","1"); //设置is_new为1,表示它是新用户 firstWindowState.update(list.get(i).getLong("ts")); //更新状态 }else { common.put("is_new","0"); //设置is_new为0,表示它是老用户 } out.collect(list.get(i)); //将处理好的数据写出到流中 } }else { //所有的用户都是旧用户, 所有的is_new全部设置为0 for (JSONObject element : elements) { element.getJSONObject("common").put("is_new","0"); out.collect(element); //将处理好的数据写出到流中 } } } }); } }
3)启动DwdLogApp
4)生产日志数据(在此之前必须启动nginx、hadoop、zk、kafka、日志服务器)
cd /opt/software/mock/mock_log
java -jar gmall2020-mock-log-2020-12-18.jar
5)查看控制台,发现有数据
3.3.4.2 数据分流
根据日志数据内容,将日志数据分为3类: 页面日志、启动日志和曝光日志。页面日志输出到主流,启动日志输出到启动侧输出流曝光日志输出到曝光日志侧输出流。
1)具体写入代码
package com.yuange.flinkrealtime.app.dwd; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONArray; import com.alibaba.fastjson.JSONAware; import com.alibaba.fastjson.JSONObject; import com.yuange.flinkrealtime.app.BaseAppV1; import com.yuange.flinkrealtime.common.Constant; import com.yuange.flinkrealtime.util.FlinkSinkUtil; import com.yuange.flinkrealtime.util.YuangeCommonUtil; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; import java.time.Duration; import java.util.Comparator; import java.util.HashMap; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/28 19:32 * 对日志数据进行分流, 写入到dwd层(kafka) * 1. 对新老用户进行确认 * 2. 对ods_log流进行分流(使用侧输出流) * 不同的数据放入不同的流 * 启动日志 * 曝光日志 * 页面日志 * 3. 把数据写入到Kafka中 */ public class DwdLogApp extends BaseAppV1 { final String START_STREAM = "start"; final String PAGE_STREAM = "page"; final String DISPLAY_STREAM = "display"; public static void main(String[] args) { new DwdLogApp().init( 2001, //端口号 2, //并行度 "DwdLogApp", //检查点的存放目录名称 "DwdLogApp", //消费者组id Constant.TOPIC_ODS_LOG //主题 ); } @Override protected void run(StreamExecutionEnvironment environment, DataStreamSource<String> sourceStream) { //业务 //一、对新老用户进行确认 SingleOutputStreamOperator<JSONObject> validatedStream = distinguishNewOrOld(sourceStream); // validatedStream.print(); //二、让不同的日志进入不同的流 HashMap<String, DataStream<JSONObject>> threeStreams = splitSteam(validatedStream); //三、把数据写入到kafka中 sendToKafka(threeStreams); } private void sendToKafka(HashMap<String, DataStream<JSONObject>> threeStreams) { threeStreams .get(START_STREAM) .map(JSONAware::toJSONString) .addSink(FlinkSinkUtil.getKafkaSink(Constant.TOPIC_DWD_START)); threeStreams .get(PAGE_STREAM) .map(JSONAware::toJSONString) .addSink(FlinkSinkUtil.getKafkaSink(Constant.TOPIC_DWD_PAGE)); threeStreams .get(DISPLAY_STREAM) .map(JSONAware::toJSONString) .addSink(FlinkSinkUtil.getKafkaSink(Constant.TOPIC_DWD_DISPLAY)); } private HashMap<String, DataStream<JSONObject>> splitSteam(SingleOutputStreamOperator<JSONObject> validatedStream) { /** * 把日志分成了3类: * 1. 启动日志 主流 * 2. 页面日志 侧输出流 * 3. 曝光日志 侧输出流 * */ OutputTag<JSONObject> pageTag = new OutputTag<JSONObject>("page") { //page侧输出流 }; OutputTag<JSONObject> displayTag = new OutputTag<JSONObject>("display") { //display测输出流 }; SingleOutputStreamOperator<JSONObject> startStream = validatedStream.process(new ProcessFunction<JSONObject, JSONObject>() { @Override public void processElement(JSONObject value, Context ctx, Collector<JSONObject> out) throws Exception { JSONObject start = value.getJSONObject("start"); //获取start日志 if (start != null) { //启动日志放入主流 out.collect(value); } else { JSONObject page = value.getJSONObject("page"); if (page != null) { ctx.output(pageTag, value); //将数据存储pageTag侧输出流 } JSONArray displays = value.getJSONArray("displays"); if (displays != null) { for (int i = 0; i < displays.size(); i++) { JSONObject display = displays.getJSONObject(i); // 在display中补充一些数据 // 1. 补充时间戳 display.put("ts", value.getLong("ts")); // 2. 补充一个page_id display.put("page_id", value.getJSONObject("page").getString("page_id")); // 3. 补充common中所有的字段 display.putAll(value.getJSONObject("common")); ctx.output(displayTag, display); //将处理好的数据存入display侧输出流 } } } } }); //将侧输出流转化为DataStream DataStream<JSONObject> pageStream = startStream.getSideOutput(pageTag); DataStream<JSONObject> displayStream = startStream.getSideOutput(displayTag); //将流汇总到Map集合中 HashMap<String, DataStream<JSONObject>> map = new HashMap<>(); map.put(START_STREAM,startStream); map.put(PAGE_STREAM,pageStream); map.put(DISPLAY_STREAM,displayStream); return map; } private SingleOutputStreamOperator<JSONObject> distinguishNewOrOld(DataStreamSource<String> sourceStream) { /** * 如何实现识别新老客户? * 需要利用状态 * 考虑数据的乱序: 使用事件时间, 加窗口 * */ //创建一个新的WatermarkStrategy来封装水印策略 return sourceStream .map(JSON::parseObject) //将数据转为JSON格式 .assignTimestampsAndWatermarks( WatermarkStrategy .<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(3)) //创建水印策略,水印是周期性生成的。这种水印策略引入的延迟是周期间隔长度加上乱序界限 .withTimestampAssigner((element, recordTimestamp) -> element.getLong("ts")) //ts + 3秒 ) .keyBy(obj -> obj.getJSONObject("common").getString("mid")) //以设备id分组 .window(TumblingEventTimeWindows.of(Time.seconds(5))) //滚动事件窗口,每5秒统计一次数据 .process(new ProcessWindowFunction<JSONObject, JSONObject, String, TimeWindow>() { //定义一个状态,以此来判断用户是否是新老用户 ValueState<Long> firstWindowState; @Override public void open(Configuration parameters) throws Exception { firstWindowState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("firstWindowState", Long.class)); } @Override public void process(String key, Context context, Iterable<JSONObject> elements, Collector<JSONObject> out) throws Exception { //如果识别出来某个mid的第一个窗口 if (firstWindowState.value() == null){ //把时间戳最小的那个条记录的is_new设置为1, 其他都为0 List<JSONObject> list = YuangeCommonUtil.toList(elements); list.sort(Comparator.comparing(o -> o.getLong("ts"))); //将JSON数据按ts排序 for (int i = 0; i < list.size(); i++) { JSONObject common = list.get(i).getJSONObject("common"); if (i == 0){ common.put("is_new","1"); //设置is_new为1,表示它是新用户 firstWindowState.update(list.get(i).getLong("ts")); //更新状态 }else { common.put("is_new","0"); //设置is_new为0,表示它是老用户 } out.collect(list.get(i)); //将处理好的数据写出到流中 } }else { //所有的用户都是旧用户, 所有的is_new全部设置为0 for (JSONObject element : elements) { element.getJSONObject("common").put("is_new","0"); out.collect(element); //将处理好的数据写出到流中 } } } }); } }
2)生产数据
cd /opt/software/mock/mock_log
java -jar gmall2020-mock-log-2020-12-18.jar
3)启动kafka消费数据
/opt/module/kafka-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server hadoop162:9092 --topic dwd_start
/opt/module/kafka-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server hadoop162:9092 --topic dwd_page
/opt/module/kafka-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server hadoop162:9092 --topic dwd_display
4)查看消费情况即可
第4章 DWD层: 业务数据
业务数据的变化,我们可以通过Maxwell采集到,但是MaxWell是把全部数据统一写入一个Topic中, 这些数据包括业务数据,也包含维度数据,这样显然不利于日后的数据处理,所以这个功能是从Kafka的业务数据ODS层读取数据,经过处理后,将维度数据保存到Hbase,将事实数据写回Kafka作为业务数据的DWD层。
4.1 主要任务
4.1.1 接收Kafka数据,过滤空值数据
4.1.2 实现动态分流功能
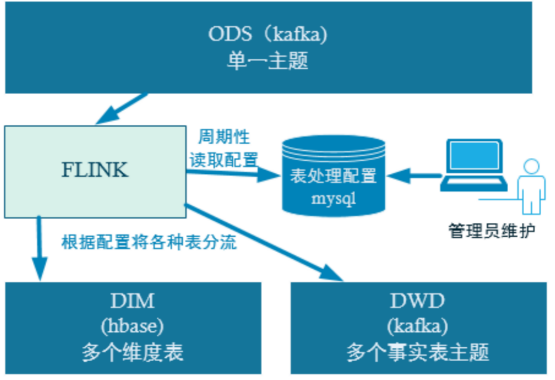
由于MaxWell是把全部数据统一写入一个Topic中, 这样显然不利于日后的数据处理。所以需要把各个表拆开处理。但是由于每个表有不同的特点,有些表是维度表,有些表是事实表,有的表既是事实表在某种情况下也是维度表。在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL等。
一般把事实数据写入流中,进行进一步处理,最终形成宽表。但是作为Flink实时计算任务,如何得知哪些表是维度表,哪些是事实表呢?而这些表又应该采集哪些字段呢?
这样的配置不适合写在配置文件中,因为这样的话,业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
这种可以有两个方案实现:一种是用Zookeeper存储,通过Watch感知数据变化。另一种是用mysql数据库存储。
这里选择第二种方案,主要是mysql对于配置数据初始化和维护管理,用sql都比较方便,虽然周期性操作时效性差一点,但是配置变化并不频繁。所以就有了如下图:
4.1.3 把分好的流保存到对应表、主题中
业务数据保存到Kafka的主题中,维度数据保存到Hbase的表中
4.2 具体实现代码
4.2.1 设计动态配置表
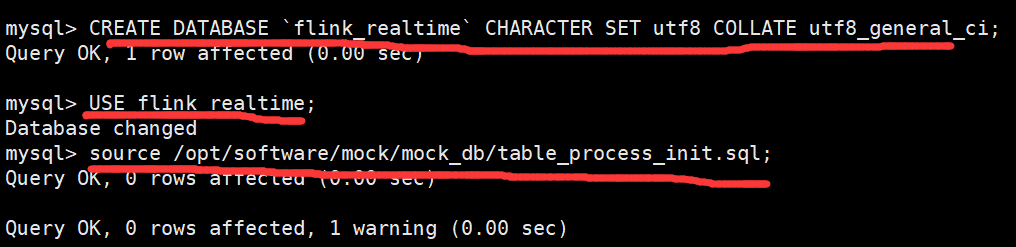
1)创建动态配置表并初始化数据
CREATE DATABASE `flink_realtime` CHARACTER SET utf8 COLLATE utf8_general_ci; USE flink_realtime; source /opt/software/mock/mock_db/table_process_init.sql;
2)配置表实体类
package com.yuange.flinkrealtime.bean; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * @作者:袁哥 * @时间:2021/7/29 11:10 */ @AllArgsConstructor @NoArgsConstructor @Data public class TableProcess { //动态分流Sink常量 public static final String SINK_TYPE_HBASE = "hbase"; public static final String SINK_TYPE_KAFKA = "kafka"; public static final String SINK_TYPE_CK = "clickhouse"; //来源表 private String source_table; //操作类型 insert,update,delete private String operate_type; //输出类型 hbase kafka private String sink_type; //输出表(主题) private String sink_table; //输出字段 private String sink_columns; //主键字段 private String sink_pk; //建表扩展 private String sink_extend; }
4.2.2 实现思路
1)业务数据: mysql->maxwell->kafka->flink
2)动态表配置表的数据: msyql->flink-sql-cdc
3)把动态表配置表做成广播流与业务数据进行connect, 从而实现动态控制业务数据的sink方向
4.2.3 读取动态配置表
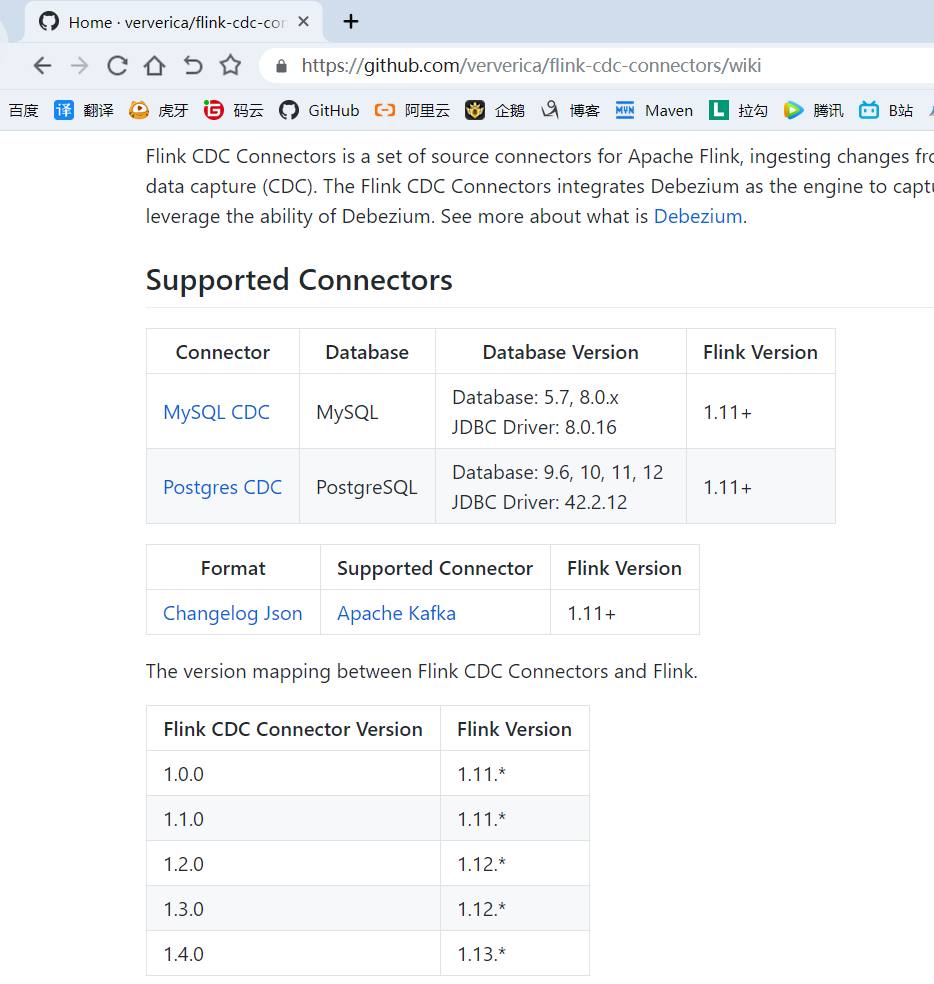
1)Flink SQL CDC 介绍
CDC 全称是 Change Data Capture ,它是一个比较广义的概念,只要能捕获变更的数据,我们都可以称为 CDC 。业界主要有基于查询的 CDC 和基于日志的 CDC ,可以从下面表格对比他们功能和差异点。

2)传统的数据同步场景(咱们前面用的场景):
缺点: 采集端组件过多导致维护繁杂
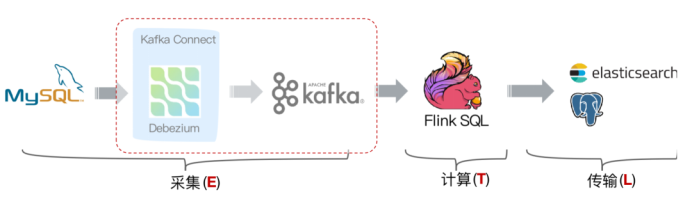
改进后的架构:
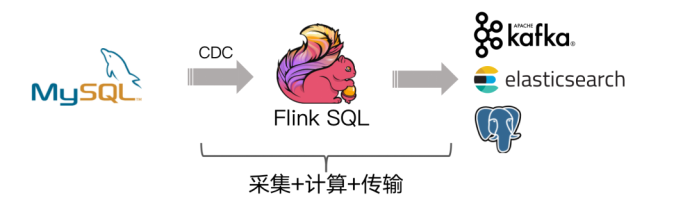
Flink社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。
目前也已开源,开源地址:https://github.com/ververica/flink-cdc-connectors
3)修改mysql配置,增加对数据库flink_realtime监控
(1)修改配置文件
sudo vim /etc/my.cnf
[mysqld] server-id= 1 #日志前缀 log-bin=mysql-bin ##同步策略 binlog_format=row ##同步的库 binlog-do-db=flinkdb binlog-do-db=flink_realtime
(2)需要重启mysql数据库
sudo systemctl restart mysqld
(3)确认msyql有没有启动成功
sudo systemctl status mysqld
#或者
ps -ef | grep mysqld
(4)注意maxwell不要再采集这个数据库的数据,在maxwell的配置中添加如下配置
vim /opt/module/maxwell-1.27.1/config.properties
filter=exclude:flink_realtime.*
4)导入CDC依赖
<!-- https://mvnrepository.com/artifact/com.alibaba.ververica/flink-connector-mysql-cdc --> <dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>flink-connector-mysql-cdc</artifactId> <version>1.4.0</version> </dependency>
5)具体实现代码
package com.yuange.flinkrealtime.app.dwd; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import com.yuange.flinkrealtime.app.BaseAppV1; import com.yuange.flinkrealtime.bean.TableProcess; import com.yuange.flinkrealtime.common.Constant; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; /** * @作者:袁哥 * @时间:2021/7/29 11:33 * 业务数据使用maxwell采集到kafka形成ods层的业务数据,然后再由Flink来接收处理ods层的数据 * 配置数据使用FlinkCDC直接从MySQL中读取,并且进行实时监控,只要配置表中的数据发生变动,FlinkCDC会感知到并进行相应的处理 */ public class DwdDbApp extends BaseAppV1 { public static void main(String[] args) { new DwdDbApp().init( 2002, //端口号 1, //并行度 "DwdDbApp", //检查点存放在HDFS上的目录名称 "DwdDbApp", //消费者组 Constant.TOPIC_ODS_DB //消费的主题 ); } @Override protected void run(StreamExecutionEnvironment environment, DataStreamSource<String> dataStream) { //读取配置表的数据, 得到一个配置流(cdc) SingleOutputStreamOperator<TableProcess> tableProcessStream = readTableProcess(environment); } private SingleOutputStreamOperator<TableProcess> readTableProcess(StreamExecutionEnvironment environment) { /** * 第一次读取全部数据 * 以后监控mysql中这个配置表的数据的更新 * */ StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment); tableEnvironment.executeSql("create table `table_process` (\n" + " `source_table` string,\n" + " `operate_type` string,\n" + " `sink_type` string,\n" + " `sink_table` string,\n" + " `sink_columns` string,\n" + " `sink_pk` string,\n" + " `sink_extend` string,\n" + " primary key (`source_table`,`operate_type`) not enforced\n" + ")with(" + " 'connector' = 'mysql-cdc', " + " 'hostname' = 'hadoop162', " + " 'port' = '3306', " + " 'username' = 'root', " + " 'password' = 'aaaaaa', " + " 'database-name' = 'flink_realtime', " + " 'table-name' = 'table_process', " + " 'debezium.snapshot.mode' = 'initial', " + ")" ); /** * initial: 启动的时候会读取表中所有的数据, 放在内存中, 全部数据读取完成之后, 会使用binlog来监控mysql的变化 * never: 只用binlog来监控mysql的变化 */ Table table_process = tableEnvironment.from("table_process"); return tableEnvironment .toRetractStream(table_process, TableProcess.class) //将table转化为可以新增和变化的dataStream .filter(t -> t.f0) //过滤出变化的数据 .map(t -> t.f1); //返回数据:TableProcess } }
4.2.4 读取业务数据并ETL
package com.yuange.flinkrealtime.app.dwd; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import com.yuange.flinkrealtime.app.BaseAppV1; import com.yuange.flinkrealtime.bean.TableProcess; import com.yuange.flinkrealtime.common.Constant; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; /** * @作者:袁哥 * @时间:2021/7/29 11:33 * 业务数据使用maxwell采集到kafka形成ods层的业务数据,然后再由Flink来接收处理ods层的数据 * 配置数据使用FlinkCDC直接从MySQL中读取,并且进行实时监控,只要配置表中的数据发生变动,FlinkCDC会感知到并进行相应的处理 */ public class DwdDbApp extends BaseAppV1 { public static void main(String[] args) { new DwdDbApp().init( 2002, //端口号 1, //并行度 "DwdDbApp", //检查点存放在HDFS上的目录名称 "DwdDbApp", //消费者组 Constant.TOPIC_ODS_DB //消费的主题 ); } @Override protected void run(StreamExecutionEnvironment environment, DataStreamSource<String> dataStream) { //1. 对数据进行etl SingleOutputStreamOperator<JSONObject> etledStream = etlDataStream(dataStream); //2. 读取配置表的数据, 得到一个配置流(cdc) SingleOutputStreamOperator<TableProcess> tableProcessStream = readTableProcess(environment); } private SingleOutputStreamOperator<TableProcess> readTableProcess(StreamExecutionEnvironment environment) { /** * 第一次读取全部数据 * 以后监控mysql中这个配置表的数据的更新 * */ StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment); tableEnvironment.executeSql("create table `table_process` (\n" + " `source_table` string,\n" + " `operate_type` string,\n" + " `sink_type` string,\n" + " `sink_table` string,\n" + " `sink_columns` string,\n" + " `sink_pk` string,\n" + " `sink_extend` string,\n" + " primary key (`source_table`,`operate_type`) not enforced\n" + ")with(" + " 'connector' = 'mysql-cdc', " + " 'hostname' = 'hadoop162', " + " 'port' = '3306', " + " 'username' = 'root', " + " 'password' = 'aaaaaa', " + " 'database-name' = 'flink_realtime', " + " 'table-name' = 'table_process', " + " 'debezium.snapshot.mode' = 'initial', " + ")" ); /** * initial: 启动的时候会读取表中所有的数据, 放在内存中, 全部数据读取完成之后, 会使用binlog来监控mysql的变化 * never: 只用binlog来监控mysql的变化 */ Table table_process = tableEnvironment.from("table_process"); return tableEnvironment .toRetractStream(table_process, TableProcess.class) //将table转化为可以新增和变化的dataStream .filter(t -> t.f0) //过滤出变化的数据 .map(t -> t.f1); //返回数据:TableProcess } private SingleOutputStreamOperator<JSONObject> etlDataStream(DataStreamSource<String> dataStream) { return dataStream .map(JSON::parseObject) //将流中的数据转为JSON格式 .filter(obj -> obj.getString("database") != null && obj.getString("table") != null && obj.getString("type") != null && (obj.getString("type").contains("insert") || "update".equals(obj.getString("type"))) && obj.getString("data") != null && obj.getString("data").length() > 10 ); } }
4.2.5 业务数据表和动态配置表connect
1)把动态配置表做成广播流, 和数据表流进行connect, 然后进行数据的分流: 事实表数据在主流, hbase数据在侧输出流
package com.yuange.flinkrealtime.app.dwd; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import com.yuange.flinkrealtime.app.BaseAppV1; import com.yuange.flinkrealtime.bean.TableProcess; import com.yuange.flinkrealtime.common.Constant; import org.apache.flink.api.common.state.BroadcastState; import org.apache.flink.api.common.state.MapStateDescriptor; import org.apache.flink.api.common.state.ReadOnlyBroadcastState; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.BroadcastStream; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; import java.util.Arrays; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/29 11:33 * 业务数据使用maxwell采集到kafka形成ods层的业务数据,然后再由Flink来接收处理ods层的数据 * 配置数据使用FlinkCDC直接从MySQL中读取,并且进行实时监控,只要配置表中的数据发生变动,FlinkCDC会感知到并进行相应的处理 */ public class DwdDbApp extends BaseAppV1 { public static void main(String[] args) { new DwdDbApp().init( 2002, //端口号 1, //并行度 "DwdDbApp", //检查点存放在HDFS上的目录名称 "DwdDbApp", //消费者组 Constant.TOPIC_ODS_DB //消费的主题 ); } @Override protected void run(StreamExecutionEnvironment environment, DataStreamSource<String> dataStream) { //1. 对数据进行etl SingleOutputStreamOperator<JSONObject> etledStream = etlDataStream(dataStream); //2. 读取配置表的数据, 得到一个配置流(cdc) SingleOutputStreamOperator<TableProcess> tableProcessStream = readTableProcess(environment); //3. 数据流和配置流进行connect,返回值就是:一个JSONObject数据对应一个TableProcess配置 SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectedStreams = connectStreams(etledStream, tableProcessStream); //4.每条数据根据他的配置, 进行动态分流 Tuple2<SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>>, DataStream<Tuple2<JSONObject, TableProcess>>> kafkaHbaseStreams = dynamicSplit(connectedStreams); kafkaHbaseStreams.f0.print("kafka"); kafkaHbaseStreams.f1.print("hbase"); } private Tuple2<SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>>, DataStream<Tuple2<JSONObject, TableProcess>>> dynamicSplit(SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectedStreams) { //侧输出流 OutputTag<Tuple2<JSONObject, TableProcess>> hbaseTag = new OutputTag<Tuple2<JSONObject, TableProcess>>("hbase") { }; SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> kafkaStream = connectedStreams.process(new ProcessFunction<Tuple2<JSONObject, TableProcess>, Tuple2<JSONObject, TableProcess>>() { @Override public void processElement(Tuple2<JSONObject, TableProcess> value, Context ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception { //只取出JSONObject中的data数据,相当于做了一次过滤,我们只需要data数据 Tuple2<JSONObject, TableProcess> data = Tuple2.of(value.f0.getJSONObject("data"), value.f1); //其实这个地方应该根据sink_cloumns的值进行一个过滤, 只保留需要sink的字段 filterColumns(data); /** * 从TableProcess配置中获取每条数据应该去往哪里:getSink_type * hbase * kafka * */ String sink_type = value.f1.getSink_type(); if (TableProcess.SINK_TYPE_KAFKA.equals(sink_type)) { //如果这条数据中的配置显示是kafka,则将数据发往kafka(使用主流) //事实数据较多,使用主流发往kafka out.collect(data); } else if (TableProcess.SINK_TYPE_HBASE.equals(sink_type)) { //如果这条数据中的配置显示是hbase,则将数据发往hbase(使用侧输出流) //因为维度数据较少,故使用侧输出流发往hbase ctx.output(hbaseTag, data); } } private void filterColumns(Tuple2<JSONObject, TableProcess> data) { JSONObject jsonObject = data.f0; //将配置表中的配个字段切分开来,放到一个List集合中 /* id,activity_name,activity_type,activity_desc,start_time,end_time,create_time id,activity_id,activity_type,condition_amount,condition_num,benefit_amount,benefit_discount,benefit_level */ List<String> columns = Arrays.asList(data.f1.getSink_columns().split(",")); //如果columns集合中没有对应的key值,那么JSONObject中的这条数据就删除它 jsonObject.keySet().removeIf(key -> !columns.contains(key)); } }); //将侧输出流转换为DataStream DataStream<Tuple2<JSONObject, TableProcess>> hbaseStream = kafkaStream.getSideOutput(hbaseTag); return Tuple2.of(kafkaStream,hbaseStream); } private SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectStreams(SingleOutputStreamOperator<JSONObject> etledStream, SingleOutputStreamOperator<TableProcess> tableProcessStream) { MapStateDescriptor<String, TableProcess> tpStateDesc = new MapStateDescriptor<>("tpStateDesc", String.class, TableProcess.class); /* 动态分流 目标: 应该得到一个新的流, 新的流存储的数据类型应该是一个二维元组 <JSONObject, TableProcess> 碰到一条数据流中的数据, 找一个TableProcess key: source_table:operate_type value: TableProcess */ //1.将配置流做成广播流 BroadcastStream<TableProcess> tpBroadcastStream = tableProcessStream.broadcast(tpStateDesc); //2.广播流与数据流进行connect return etledStream.keyBy(obj -> obj.getString("table")) //以table分组,然后将每个table与广播流connect .connect(tpBroadcastStream) .process(new KeyedBroadcastProcessFunction<String, JSONObject, TableProcess, Tuple2<JSONObject,TableProcess>>() { @Override public void processElement(JSONObject value, ReadOnlyContext ctx, Collector<Tuple2<JSONObject,TableProcess>> out) throws Exception { //获取广播状态,因为所有的配置信息都保存在了广播状态中 ReadOnlyBroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(tpStateDesc); //拼接table:type作为key值 String key = value.getString("table") + ":" + value.getString("type").replaceAll("bootstrap-", ""); //根据在数据流中拼接出来的key值,从广播状态中取出对应的配置信息(即给每一条数据找一个TableProcess配置) TableProcess tableProcess = broadcastState.get(key); //如果tableProcess是null,证明这条数据不需要后面处理 if (tableProcess != null){ out.collect(Tuple2.of(value,tableProcess)); //将Json数据和配置数据返回(一个table对应一个配置信息) } } @Override public void processBroadcastElement(TableProcess value, Context ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception { //把来的每条配置都写入到广播状态中 BroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(tpStateDesc); //从上下文环境中获取广播状态 //拼接key,以保存到广播状态中 /* Source_table Operate_type activity_info insert activity_info update activity_rule insert activity_rule update activity_sku insert activity_sku update */ String key = value.getSource_table() + ":" + value.getOperate_type(); //一条记录就是一个配置信息 broadcastState.put(key,value); } }); } private SingleOutputStreamOperator<TableProcess> readTableProcess(StreamExecutionEnvironment environment) { /** * 第一次读取全部数据 * 以后监控mysql中这个配置表的数据的更新 * */ StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment); tableEnvironment.executeSql("create table `table_process` (\n" + " `source_table` string,\n" + " `operate_type` string,\n" + " `sink_type` string,\n" + " `sink_table` string,\n" + " `sink_columns` string,\n" + " `sink_pk` string,\n" + " `sink_extend` string,\n" + " primary key (`source_table`,`operate_type`) not enforced\n" + ")with(" + " 'connector' = 'mysql-cdc', " + " 'hostname' = 'hadoop162', " + " 'port' = '3306', " + " 'username' = 'root', " + " 'password' = 'aaaaaa', " + " 'database-name' = 'flink_realtime', " + " 'table-name' = 'table_process', " + " 'debezium.snapshot.mode' = 'initial' " + ")" ); /** * initial: 启动的时候会读取表中所有的数据, 放在内存中, 全部数据读取完成之后, 会使用binlog来监控mysql的变化 * never: 只用binlog来监控mysql的变化 */ Table table_process = tableEnvironment.from("table_process"); return tableEnvironment .toRetractStream(table_process, TableProcess.class) //将table转化为可以新增和变化的dataStream .filter(t -> t.f0) //过滤出变化的数据 .map(t -> t.f1); //返回数据:TableProcess } private SingleOutputStreamOperator<JSONObject> etlDataStream(DataStreamSource<String> dataStream) { return dataStream .map(JSON::parseObject) //将流中的数据转为JSON格式 .filter(obj -> obj.getString("database") != null && obj.getString("table") != null && obj.getString("type") != null && (obj.getString("type").contains("insert") || "update".equals(obj.getString("type"))) && obj.getString("data") != null && obj.getString("data").length() > 10 ); } }
2)启动Hadoop(checkpoint持久化)
hadoop.sh start
3)启动ZK
zk start
4)启动Kafka
kafka.sh start
5)启动DwdDbApp,准备接收Kafka中的数据

6)启动Maxwell,实时监控Mysql中业务数据的变化,并将业务数据导入Kafka中(也可以将旧的数据导入Kafka,使用maxwell-bootstrap即可)
/opt/module/maxwell-1.27.1/bin/maxwell --config /opt/module/maxwell-1.27.1/config.properties --daemon
/opt/module/maxwell-1.27.1/bin/maxwell-bootstrap --user maxwell --password aaaaaa --host hadoop162 --database flinkdb --table user_info --client_id maxwell_1
7)查看数据,发现控制台有打印(数据太多会把kafka主流的数据冲掉,因为控制台长度有限)
8)生产业务数据,模拟新增
cd /opt/software/mock/mock_db
java -jar gmall2020-mock-db-2020-12-23.jar
4.2.6 数据sink到正确的位置
1)Sink到Hbase
(1)导入Phoenix相关依赖
<dependency> <groupId>org.apache.phoenix</groupId> <artifactId>phoenix-core</artifactId> <version>5.0.0-HBase-2.0</version> <exclusions> <exclusion> <groupId>org.glassfish</groupId> <artifactId>javax.el</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>30.1-jre</version> </dependency> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>2.5.0</version> </dependency>
(2)在Constant中新增两个常量
public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver"; //CTRL + N:全局搜索 public static final String PHOENIX_URL = "jdbc:phoenix:hadoop162,hadoop163,hadoop164:2181";
(3)新建一个PhoenixSink,让它继承RichSinkFunction,将数据写入HBase
package com.yuange.flinkrealtime.sink; import com.alibaba.fastjson.JSONObject; import com.yuange.flinkrealtime.bean.TableProcess; import com.yuange.flinkrealtime.util.JdbcUtil; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.functions.sink.RichSinkFunction; import java.io.IOException; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.SQLException; /** * @作者:袁哥 * @时间:2021/7/30 23:25 */ public class PhoenixSink extends RichSinkFunction<Tuple2<JSONObject, TableProcess>> { Connection conn; ValueState<String> tableCreateState; @Override public void open(Configuration parameters) throws Exception { //先加载驱动, 很多情况不是必须. //大部分常用的数据库会根据url自动选择合适的driver //Phoenix 驱动有些时候需要手动加载一下 conn = JdbcUtil.getPhoenixConnection(); //创建一个状态来管理table tableCreateState = getRuntimeContext().getState(new ValueStateDescriptor<String>("tableCreateState", String.class)); } @Override public void invoke(Tuple2<JSONObject, TableProcess> value, Context context) throws Exception { // 1. 检测表, 如果表不存在就需要在Phoenix中新建表 checkTable(value); // 2. 再把数据写入到phoenix中 writeToPhoenix(value); } private void writeToPhoenix(Tuple2<JSONObject, TableProcess> value) throws SQLException { JSONObject data = value.f0; TableProcess tp = value.f1; // upsert into user(id, name, age) values(?,?,?) //拼接SQL语句 StringBuilder insertSql = new StringBuilder(); insertSql .append("upsert into ") .append(tp.getSink_table()) .append("(") //id,activity_name,activity_type,activity_desc,start_time,end_time,create_time .append(tp.getSink_columns()) .append(")values(") //把非,部分替换为? .append(tp.getSink_columns().replaceAll("[^,]+","?")) .append(")"); PreparedStatement ps = conn.prepareStatement(insertSql.toString()); //给ps中的占位符赋值 String[] columnNames = tp.getSink_columns().split(","); for (int i = 0; i < columnNames.length; i++) { //从JSONObject数据中取出对应字段的值 Object str = data.getString(columnNames[i]); ps.setString(i + 1,str == null ? "" : str.toString()); } ps.execute(); conn.commit(); ps.close(); } private void checkTable(Tuple2<JSONObject, TableProcess> value) throws IOException, SQLException { if (tableCreateState.value() == null){ // 执行sql语句 create table if not exists user(id varchar, age varchar ) TableProcess tp = value.f1; // 拼接sql语句 StringBuilder createSql = new StringBuilder(); createSql .append("create table if not exists ") .append(tp.getSink_table()) .append("(") .append(tp.getSink_columns().replaceAll(","," varchar,")) .append(" varchar, constraint pk primary key(") .append(tp.getSink_pk() == null ? "id" : tp.getSink_pk()) .append("))") .append(tp.getSink_extend() == null ? "" : tp.getSink_extend()); PreparedStatement ps = conn.prepareStatement(createSql.toString()); ps.execute(); conn.commit(); ps.close(); //更新状态 tableCreateState.update(tp.getSink_table()); } } }
(4)新建JDBCUtil,获取Phoenix连接
package com.yuange.flinkrealtime.util; import com.yuange.flinkrealtime.common.Constant; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; /** * @作者:袁哥 * @时间:2021/7/30 23:30 */ public class JdbcUtil { public static Connection getPhoenixConnection() throws ClassNotFoundException, SQLException { Class.forName(Constant.PHOENIX_DRIVER); return DriverManager.getConnection(Constant.PHOENIX_URL); } }
(5)在FlinkSinkUtil中添加getHbaseSink()方法,返回值就是一个SinkFunction,而我们新建的PhoenixSink继承了RichSinkFunction,RichSinkFunction又实现了SinkFunction,所以可以直接将PhoenixSink返回即可
public static SinkFunction<Tuple2<JSONObject, TableProcess>> getHbaseSink(){ return new PhoenixSink(); }
(6)DwdDbApp中调用FlinkSinkUtil.getHbaseSink()即可把数据写入hbase
package com.yuange.flinkrealtime.app.dwd; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import com.yuange.flinkrealtime.app.BaseAppV1; import com.yuange.flinkrealtime.bean.TableProcess; import com.yuange.flinkrealtime.common.Constant; import com.yuange.flinkrealtime.util.FlinkSinkUtil; import org.apache.flink.api.common.state.BroadcastState; import org.apache.flink.api.common.state.MapStateDescriptor; import org.apache.flink.api.common.state.ReadOnlyBroadcastState; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.BroadcastStream; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; import java.util.Arrays; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/29 11:33 * 业务数据使用maxwell采集到kafka形成ods层的业务数据,然后再由Flink来接收处理ods层的数据 * 配置数据使用FlinkCDC直接从MySQL中读取,并且进行实时监控,只要配置表中的数据发生变动,FlinkCDC会感知到并进行相应的处理 */ public class DwdDbApp extends BaseAppV1 { public static void main(String[] args) { new DwdDbApp().init( 2002, //端口号 1, //并行度 "DwdDbApp", //检查点存放在HDFS上的目录名称 "DwdDbApp", //消费者组 Constant.TOPIC_ODS_DB //消费的主题 ); } @Override protected void run(StreamExecutionEnvironment environment, DataStreamSource<String> dataStream) { //1. 对数据进行etl SingleOutputStreamOperator<JSONObject> etledStream = etlDataStream(dataStream); //2. 读取配置表的数据, 得到一个配置流(cdc) SingleOutputStreamOperator<TableProcess> tableProcessStream = readTableProcess(environment); //3. 数据流和配置流进行connect,返回值就是:一个JSONObject数据对应一个TableProcess配置 SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectedStreams = connectStreams(etledStream, tableProcessStream); //4.每条数据根据他的配置, 进行动态分流 Tuple2<SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>>, DataStream<Tuple2<JSONObject, TableProcess>>> kafkaHbaseStreams = dynamicSplit(connectedStreams); // kafkaHbaseStreams.f0.print("kafka"); // kafkaHbaseStreams.f1.print("hbase"); //5.维度表写入到hbase sendToHbase(kafkaHbaseStreams.f1); } private void sendToHbase(DataStream<Tuple2<JSONObject, TableProcess>> stream) { /** * 向hbase(Phoenix)写入数据的时候, 表不会自动创建 * 1. 先创建表 动态创建 * 2. 再写入 * */ stream.keyBy(t -> t.f1.getSink_table()) //按照配置表中的Sink_table分组 .addSink(FlinkSinkUtil.getHbaseSink()); } private Tuple2<SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>>, DataStream<Tuple2<JSONObject, TableProcess>>> dynamicSplit(SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectedStreams) { //侧输出流 OutputTag<Tuple2<JSONObject, TableProcess>> hbaseTag = new OutputTag<Tuple2<JSONObject, TableProcess>>("hbase") { }; SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> kafkaStream = connectedStreams.process(new ProcessFunction<Tuple2<JSONObject, TableProcess>, Tuple2<JSONObject, TableProcess>>() { @Override public void processElement(Tuple2<JSONObject, TableProcess> value, Context ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception { //只取出JSONObject中的data数据,相当于做了一次过滤,我们只需要data数据 Tuple2<JSONObject, TableProcess> data = Tuple2.of(value.f0.getJSONObject("data"), value.f1); //其实这个地方应该根据sink_cloumns的值进行一个过滤, 只保留需要sink的字段 filterColumns(data); /** * 从TableProcess配置中获取每条数据应该去往哪里:getSink_type * hbase * kafka * */ String sink_type = value.f1.getSink_type(); if (TableProcess.SINK_TYPE_KAFKA.equals(sink_type)) { //如果这条数据中的配置显示是kafka,则将数据发往kafka(使用主流) //事实数据较多,使用主流发往kafka out.collect(data); } else if (TableProcess.SINK_TYPE_HBASE.equals(sink_type)) { //如果这条数据中的配置显示是hbase,则将数据发往hbase(使用侧输出流) //因为维度数据较少,故使用侧输出流发往hbase ctx.output(hbaseTag, data); } } private void filterColumns(Tuple2<JSONObject, TableProcess> data) { JSONObject jsonObject = data.f0; //将配置表中的配个字段切分开来,放到一个List集合中 /* id,activity_name,activity_type,activity_desc,start_time,end_time,create_time id,activity_id,activity_type,condition_amount,condition_num,benefit_amount,benefit_discount,benefit_level */ List<String> columns = Arrays.asList(data.f1.getSink_columns().split(",")); //如果columns集合中没有对应的key值,那么JSONObject中的这条数据就删除它 jsonObject.keySet().removeIf(key -> !columns.contains(key)); } }); //将侧输出流转换为DataStream DataStream<Tuple2<JSONObject, TableProcess>> hbaseStream = kafkaStream.getSideOutput(hbaseTag); return Tuple2.of(kafkaStream,hbaseStream); } private SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectStreams(SingleOutputStreamOperator<JSONObject> etledStream, SingleOutputStreamOperator<TableProcess> tableProcessStream) { MapStateDescriptor<String, TableProcess> tpStateDesc = new MapStateDescriptor<>("tpStateDesc", String.class, TableProcess.class); /* 动态分流 目标: 应该得到一个新的流, 新的流存储的数据类型应该是一个二维元组 <JSONObject, TableProcess> 碰到一条数据流中的数据, 找一个TableProcess key: source_table:operate_type value: TableProcess */ //1.将配置流做成广播流 BroadcastStream<TableProcess> tpBroadcastStream = tableProcessStream.broadcast(tpStateDesc); //2.广播流与数据流进行connect return etledStream.keyBy(obj -> obj.getString("table")) //以table分组,然后将每个table与广播流connect .connect(tpBroadcastStream) .process(new KeyedBroadcastProcessFunction<String, JSONObject, TableProcess, Tuple2<JSONObject,TableProcess>>() { @Override public void processElement(JSONObject value, ReadOnlyContext ctx, Collector<Tuple2<JSONObject,TableProcess>> out) throws Exception { //获取广播状态,因为所有的配置信息都保存在了广播状态中 ReadOnlyBroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(tpStateDesc); //拼接table:type作为key值 String key = value.getString("table") + ":" + value.getString("type").replaceAll("bootstrap-", ""); //根据在数据流中拼接出来的key值,从广播状态中取出对应的配置信息(即给每一条数据找一个TableProcess配置) TableProcess tableProcess = broadcastState.get(key); //如果tableProcess是null,证明这条数据不需要后面处理 if (tableProcess != null){ out.collect(Tuple2.of(value,tableProcess)); //将Json数据和配置数据返回(一个table对应一个配置信息) } } @Override public void processBroadcastElement(TableProcess value, Context ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception { //把来的每条配置都写入到广播状态中 BroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(tpStateDesc); //从上下文环境中获取广播状态 //拼接key,以保存到广播状态中 /* Source_table Operate_type activity_info insert activity_info update activity_rule insert activity_rule update activity_sku insert activity_sku update */ String key = value.getSource_table() + ":" + value.getOperate_type(); //一条记录就是一个配置信息 broadcastState.put(key,value); } }); } private SingleOutputStreamOperator<TableProcess> readTableProcess(StreamExecutionEnvironment environment) { /** * 第一次读取全部数据 * 以后监控mysql中这个配置表的数据的更新 * */ StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment); tableEnvironment.executeSql("create table `table_process` (\n" + " `source_table` string,\n" + " `operate_type` string,\n" + " `sink_type` string,\n" + " `sink_table` string,\n" + " `sink_columns` string,\n" + " `sink_pk` string,\n" + " `sink_extend` string,\n" + " primary key (`source_table`,`operate_type`) not enforced\n" + ")with(" + " 'connector' = 'mysql-cdc', " + " 'hostname' = 'hadoop162', " + " 'port' = '3306', " + " 'username' = 'root', " + " 'password' = 'aaaaaa', " + " 'database-name' = 'flink_realtime', " + " 'table-name' = 'table_process', " + " 'debezium.snapshot.mode' = 'initial' " + ")" ); /** * initial: 启动的时候会读取表中所有的数据, 放在内存中, 全部数据读取完成之后, 会使用binlog来监控mysql的变化 * never: 只用binlog来监控mysql的变化 */ Table table_process = tableEnvironment.from("table_process"); return tableEnvironment .toRetractStream(table_process, TableProcess.class) //将table转化为可以新增和变化的dataStream .filter(t -> t.f0) //过滤出变化的数据 .map(t -> t.f1); //返回数据:TableProcess } private SingleOutputStreamOperator<JSONObject> etlDataStream(DataStreamSource<String> dataStream) { return dataStream .map(JSON::parseObject) //将流中的数据转为JSON格式 .filter(obj -> obj.getString("database") != null && obj.getString("table") != null && obj.getString("type") != null && (obj.getString("type").contains("insert") || "update".equals(obj.getString("type"))) && obj.getString("data") != null && obj.getString("data").length() > 10 ); } }
(7)启动Hbase
start-hbase.sh
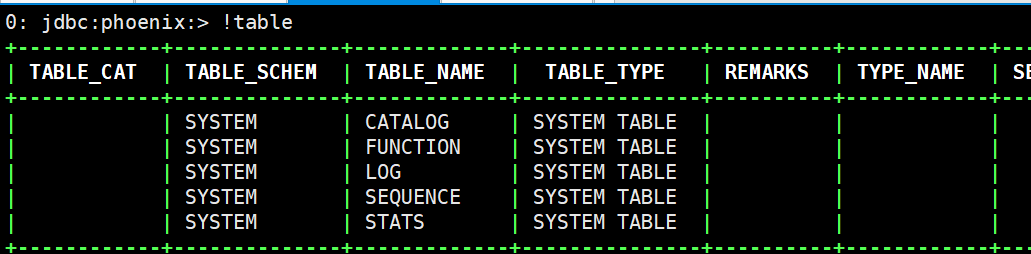
(8)进入Phoenix客户端,查看表,发现目前啥也没有
/opt/module/phoenix-5.0.0/bin/sqlline.py
(9)启动DwdDbApp,接收从kafka中读取的数据以及使用Flink CDC读取的配置表信息
(10)使用maxwell-bootstrap将旧的数据导入kafka中(在此之前必须启动maxwell)
/opt/module/maxwell-1.27.1/bin/maxwell --config /opt/module/maxwell-1.27.1/config.properties --daemon
/opt/module/maxwell-1.27.1/bin/maxwell-bootstrap --user maxwell --password aaaaaa --host hadoop162 --database flinkdb --table user_info --client_id maxwell_1
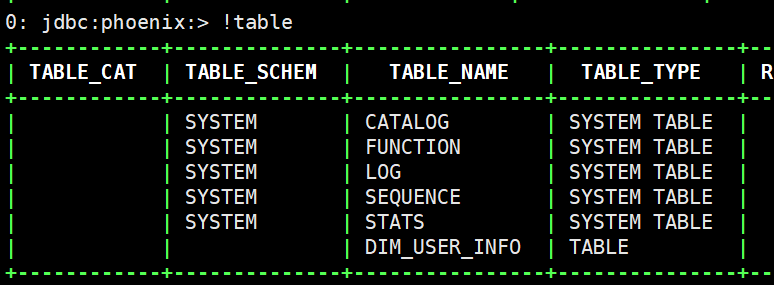
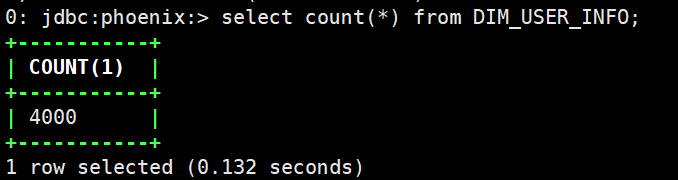
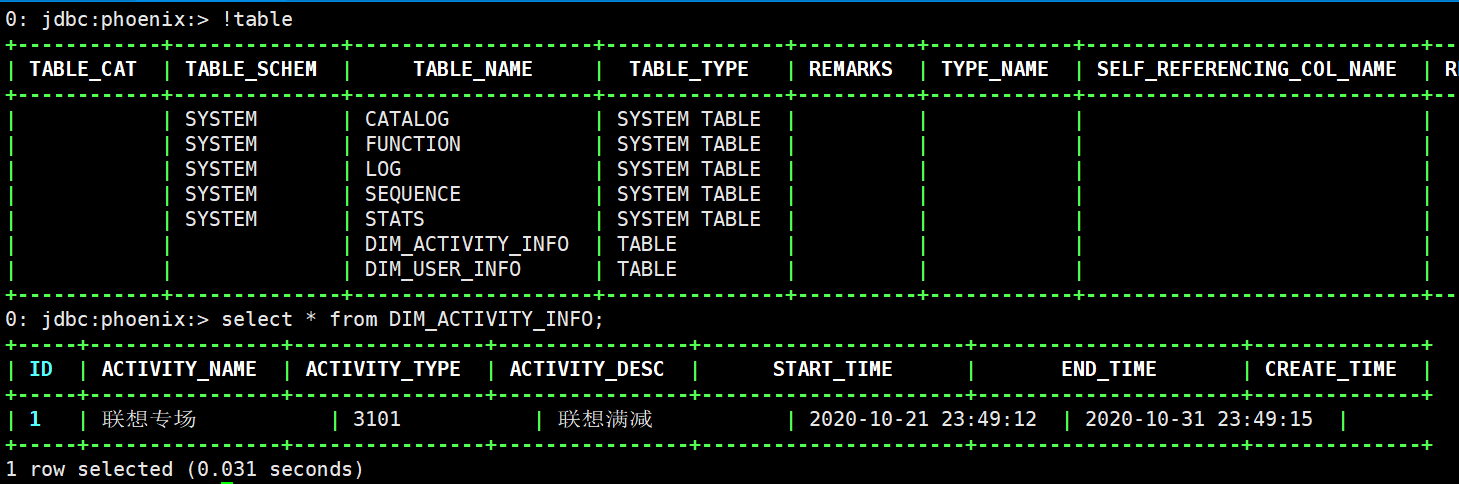
(11)发现user_info表已经创建
(12)再次使用maxwell-bootstrap,将activity_info以前的数据导入kafka,发现activity_info已经生成并且有数据
/opt/module/maxwell-1.27.1/bin/maxwell-bootstrap --user maxwell --password aaaaaa --host hadoop162 --database flinkdb --table activity_info --client_id maxwell_1
2)Sink到Kafka
(1)在FlinkSinkUtil 中添加getKafkaSink方法
public static FlinkKafkaProducer<Tuple2<JSONObject, TableProcess>> getKafkaSink(){ Properties properties = new Properties(); properties.setProperty("bootstrap.servers","hadoop162:9092,hadoop163:9092,hadoop164:9092"); properties.setProperty("transaction.timeout.ms", 15 * 60 * 1000 + ""); return new FlinkKafkaProducer<Tuple2<JSONObject,TableProcess>>( "default", //kafka序列化器 new KafkaSerializationSchema<Tuple2<JSONObject, TableProcess>>() { @Override public ProducerRecord<byte[], byte[]> serialize(Tuple2<JSONObject, TableProcess> element, @Nullable Long aLong) { return new ProducerRecord<>( element.f1.getSink_table(), //每条数据对应一个配置表中的数据,将TableProcess配置表中的Sink_table作为kafka的主题 null, element.f0.toJSONString().getBytes(StandardCharsets.UTF_8) //将JSONObject事实数据作为value写入kafka的topic中 ); } }, properties, FlinkKafkaProducer.Semantic.EXACTLY_ONCE //精准一次 ); }
(2)在DwdDbApp中直接调用即可,完整的DwdDbApp代码如下
package com.yuange.flinkrealtime.app.dwd; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import com.yuange.flinkrealtime.app.BaseAppV1; import com.yuange.flinkrealtime.bean.TableProcess; import com.yuange.flinkrealtime.common.Constant; import com.yuange.flinkrealtime.util.FlinkSinkUtil; import org.apache.flink.api.common.state.BroadcastState; import org.apache.flink.api.common.state.MapStateDescriptor; import org.apache.flink.api.common.state.ReadOnlyBroadcastState; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.BroadcastStream; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; import java.util.Arrays; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/29 11:33 * 业务数据使用maxwell采集到kafka形成ods层的业务数据,然后再由Flink来接收处理ods层的数据 * 配置数据使用FlinkCDC直接从MySQL中读取,并且进行实时监控,只要配置表中的数据发生变动,FlinkCDC会感知到并进行相应的处理 */ public class DwdDbApp extends BaseAppV1 { public static void main(String[] args) { new DwdDbApp().init( 2002, //端口号 1, //并行度 "DwdDbApp", //检查点存放在HDFS上的目录名称 "DwdDbApp", //消费者组 Constant.TOPIC_ODS_DB //消费的主题 ); } @Override protected void run(StreamExecutionEnvironment environment, DataStreamSource<String> dataStream) { //1. 对数据进行etl SingleOutputStreamOperator<JSONObject> etledStream = etlDataStream(dataStream); //2. 读取配置表的数据, 得到一个配置流(cdc) SingleOutputStreamOperator<TableProcess> tableProcessStream = readTableProcess(environment); //3. 数据流和配置流进行connect,返回值就是:一个JSONObject数据对应一个TableProcess配置 SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectedStreams = connectStreams(etledStream, tableProcessStream); //4.每条数据根据他的配置, 进行动态分流 Tuple2<SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>>, DataStream<Tuple2<JSONObject, TableProcess>>> kafkaHbaseStreams = dynamicSplit(connectedStreams); // kafkaHbaseStreams.f0.print("kafka"); // kafkaHbaseStreams.f1.print("hbase"); //5.维度表写入到hbase sendToHbase(kafkaHbaseStreams.f1); //6.事实表写入到kafka sendToKafka(kafkaHbaseStreams.f0); } private void sendToKafka(SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> stream) { stream.addSink(FlinkSinkUtil.getKafkaSink()); } private void sendToHbase(DataStream<Tuple2<JSONObject, TableProcess>> stream) { /** * 向hbase(Phoenix)写入数据的时候, 表不会自动创建 * 1. 先创建表 动态创建 * 2. 再写入 * */ stream.keyBy(t -> t.f1.getSink_table()) //按照配置表中的Sink_table分组 .addSink(FlinkSinkUtil.getHbaseSink()); } private Tuple2<SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>>, DataStream<Tuple2<JSONObject, TableProcess>>> dynamicSplit(SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectedStreams) { //侧输出流 OutputTag<Tuple2<JSONObject, TableProcess>> hbaseTag = new OutputTag<Tuple2<JSONObject, TableProcess>>("hbase") { }; SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> kafkaStream = connectedStreams.process(new ProcessFunction<Tuple2<JSONObject, TableProcess>, Tuple2<JSONObject, TableProcess>>() { @Override public void processElement(Tuple2<JSONObject, TableProcess> value, Context ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception { //只取出JSONObject中的data数据,相当于做了一次过滤,我们只需要data数据 Tuple2<JSONObject, TableProcess> data = Tuple2.of(value.f0.getJSONObject("data"), value.f1); //其实这个地方应该根据sink_cloumns的值进行一个过滤, 只保留需要sink的字段 filterColumns(data); /** * 从TableProcess配置中获取每条数据应该去往哪里:getSink_type * hbase * kafka * */ String sink_type = value.f1.getSink_type(); if (TableProcess.SINK_TYPE_KAFKA.equals(sink_type)) { //如果这条数据中的配置显示是kafka,则将数据发往kafka(使用主流) //事实数据较多,使用主流发往kafka out.collect(data); } else if (TableProcess.SINK_TYPE_HBASE.equals(sink_type)) { //如果这条数据中的配置显示是hbase,则将数据发往hbase(使用侧输出流) //因为维度数据较少,故使用侧输出流发往hbase ctx.output(hbaseTag, data); } } private void filterColumns(Tuple2<JSONObject, TableProcess> data) { JSONObject jsonObject = data.f0; //将配置表中的配个字段切分开来,放到一个List集合中 /* id,activity_name,activity_type,activity_desc,start_time,end_time,create_time id,activity_id,activity_type,condition_amount,condition_num,benefit_amount,benefit_discount,benefit_level */ List<String> columns = Arrays.asList(data.f1.getSink_columns().split(",")); //如果columns集合中没有对应的key值,那么JSONObject中的这条数据就删除它 jsonObject.keySet().removeIf(key -> !columns.contains(key)); } }); //将侧输出流转换为DataStream DataStream<Tuple2<JSONObject, TableProcess>> hbaseStream = kafkaStream.getSideOutput(hbaseTag); return Tuple2.of(kafkaStream,hbaseStream); } private SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectStreams(SingleOutputStreamOperator<JSONObject> etledStream, SingleOutputStreamOperator<TableProcess> tableProcessStream) { MapStateDescriptor<String, TableProcess> tpStateDesc = new MapStateDescriptor<>("tpStateDesc", String.class, TableProcess.class); /* 动态分流 目标: 应该得到一个新的流, 新的流存储的数据类型应该是一个二维元组 <JSONObject, TableProcess> 碰到一条数据流中的数据, 找一个TableProcess key: source_table:operate_type value: TableProcess */ //1.将配置流做成广播流 BroadcastStream<TableProcess> tpBroadcastStream = tableProcessStream.broadcast(tpStateDesc); //2.广播流与数据流进行connect return etledStream.keyBy(obj -> obj.getString("table")) //以table分组,然后将每个table与广播流connect .connect(tpBroadcastStream) .process(new KeyedBroadcastProcessFunction<String, JSONObject, TableProcess, Tuple2<JSONObject,TableProcess>>() { @Override public void processElement(JSONObject value, ReadOnlyContext ctx, Collector<Tuple2<JSONObject,TableProcess>> out) throws Exception { //获取广播状态,因为所有的配置信息都保存在了广播状态中 ReadOnlyBroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(tpStateDesc); //拼接table:type作为key值 String key = value.getString("table") + ":" + value.getString("type").replaceAll("bootstrap-", ""); //根据在数据流中拼接出来的key值,从广播状态中取出对应的配置信息(即给每一条数据找一个TableProcess配置) TableProcess tableProcess = broadcastState.get(key); //如果tableProcess是null,证明这条数据不需要后面处理 if (tableProcess != null){ out.collect(Tuple2.of(value,tableProcess)); //将Json数据和配置数据返回(一个table对应一个配置信息) } } @Override public void processBroadcastElement(TableProcess value, Context ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception { //把来的每条配置都写入到广播状态中 BroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(tpStateDesc); //从上下文环境中获取广播状态 //拼接key,以保存到广播状态中 /* Source_table Operate_type activity_info insert activity_info update activity_rule insert activity_rule update activity_sku insert activity_sku update */ String key = value.getSource_table() + ":" + value.getOperate_type(); //一条记录就是一个配置信息 broadcastState.put(key,value); } }); } private SingleOutputStreamOperator<TableProcess> readTableProcess(StreamExecutionEnvironment environment) { /** * 第一次读取全部数据 * 以后监控mysql中这个配置表的数据的更新 * */ StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment); tableEnvironment.executeSql("create table `table_process` (\n" + " `source_table` string,\n" + " `operate_type` string,\n" + " `sink_type` string,\n" + " `sink_table` string,\n" + " `sink_columns` string,\n" + " `sink_pk` string,\n" + " `sink_extend` string,\n" + " primary key (`source_table`,`operate_type`) not enforced\n" + ")with(" + " 'connector' = 'mysql-cdc', " + " 'hostname' = 'hadoop162', " + " 'port' = '3306', " + " 'username' = 'root', " + " 'password' = 'aaaaaa', " + " 'database-name' = 'flink_realtime', " + " 'table-name' = 'table_process', " + " 'debezium.snapshot.mode' = 'initial' " + ")" ); /** * initial: 启动的时候会读取表中所有的数据, 放在内存中, 全部数据读取完成之后, 会使用binlog来监控mysql的变化 * never: 只用binlog来监控mysql的变化 */ Table table_process = tableEnvironment.from("table_process"); return tableEnvironment .toRetractStream(table_process, TableProcess.class) //将table转化为可以新增和变化的dataStream .filter(t -> t.f0) //过滤出变化的数据 .map(t -> t.f1); //返回数据:TableProcess } private SingleOutputStreamOperator<JSONObject> etlDataStream(DataStreamSource<String> dataStream) { return dataStream .map(JSON::parseObject) //将流中的数据转为JSON格式 .filter(obj -> obj.getString("database") != null && obj.getString("table") != null && obj.getString("type") != null && (obj.getString("type").contains("insert") || "update".equals(obj.getString("type"))) && obj.getString("data") != null && obj.getString("data").length() > 10 ); } }
(3)启动DwdDbApp
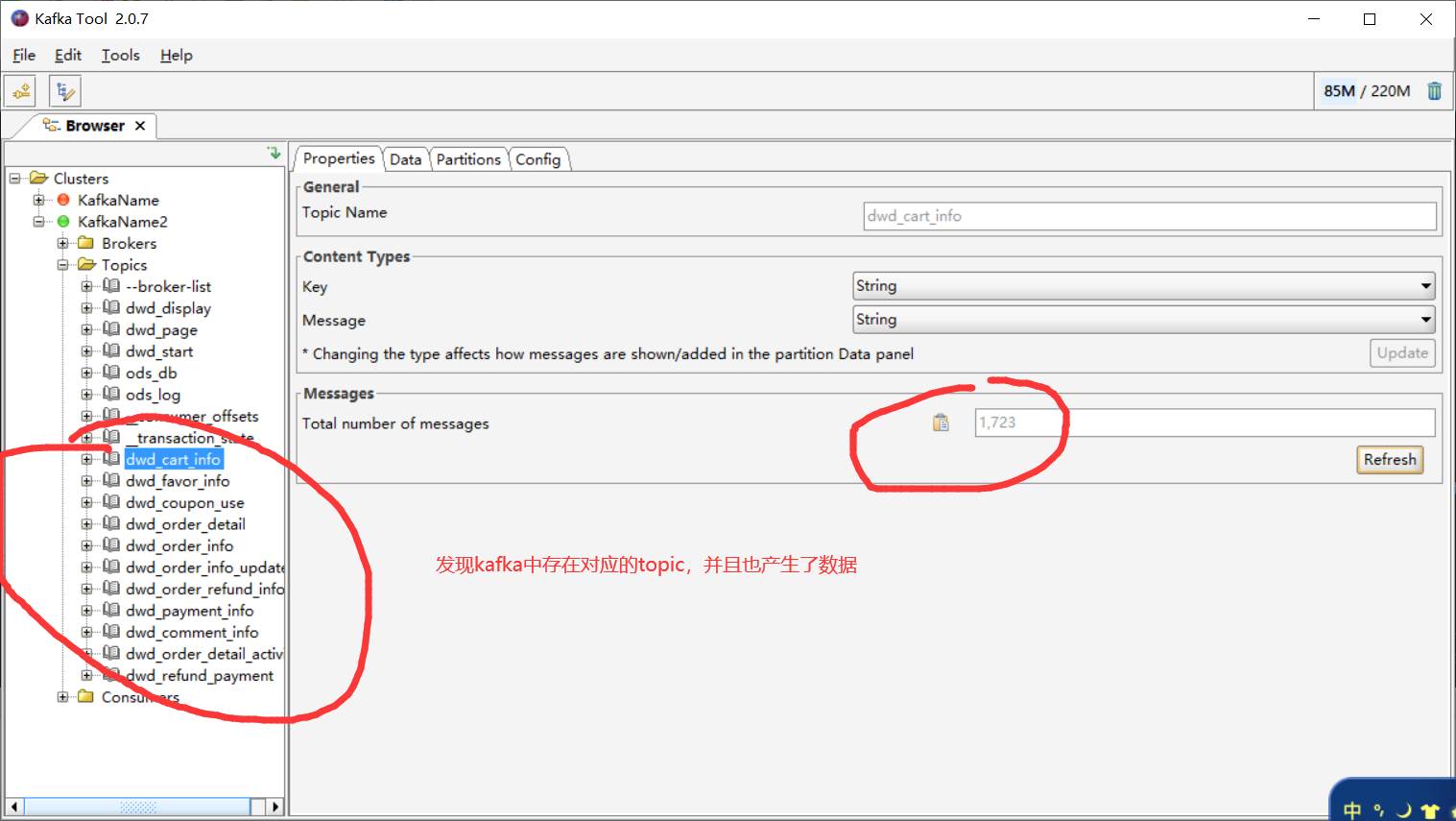
(4)生产业务数据,模拟新增
cd /opt/software/mock/mock_db
java -jar gmall2020-mock-db-2020-12-23.jar
(5)查看Kafka
3)打包部署flink-realtime到Linux上
(1)使用maven打包(打包之前先clear一下,并且停止idea上的DwdDbApp)
(2)将打包好的flink-realtime-1.0-SNAPSHOT.jar上传至/opt/module/applog

(3)启动Yarn-Session(在此之前必须启动Hadoop、ZK、Kafka、Hbase)
/opt/module/flink-yarn/bin/yarn-session.sh -d
(4)提交运行flink-realtime-1.0-SNAPSHOT.jar到Yarn上,编写一个脚本来提交,避免重复性工作
vim /home/atguigu/bin/realtime.sh
#!/bin/bash flink=/opt/module/flink-yarn/bin/flink jar=/opt/module/applog/flink-realtime-1.0-SNAPSHOT.jar apps=( com.yuange.flinkrealtime.app.dwd.DwdLogApp com.yuange.flinkrealtime.app.dwd.DwdDbApp ) for app in ${apps[*]} ; do $flink run -d -c $app $jar done
chmod +x /home/atguigu/bin/realtime.sh
/home/atguigu/bin/realtime.sh
(5)查看程序运行情况,发现出现异常信息

(6)原因是依赖冲突,flink-realtime-1.0-SNAPSHOT.jar中的依赖和Linux中Flink的依赖存在相同的依赖,将其中一放的依赖去除即可
cd /opt/module/flink-yarn/lib
rm -rf flink-connector-jdbc_2.12-1.13.1.jar flink-connector-kafka_2.12-1.13.1.jar mysql-connector-java-5.1.27-bin.jar
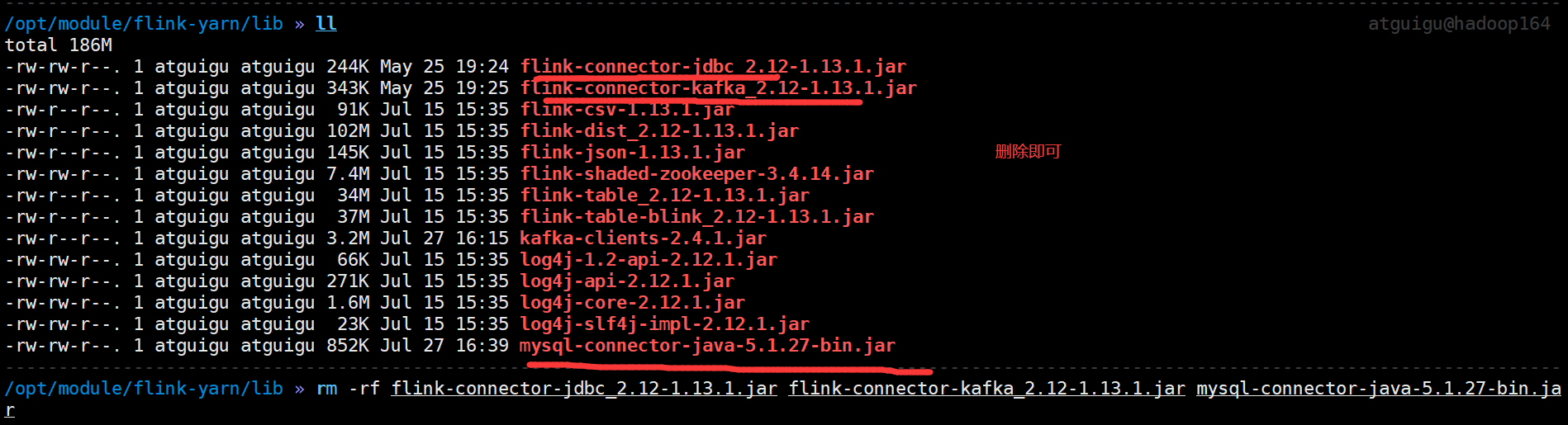
(7)重启yarn-session,然后再次提交flink-realtime-1.0-SNAPSHOT.jar至yarn上运行
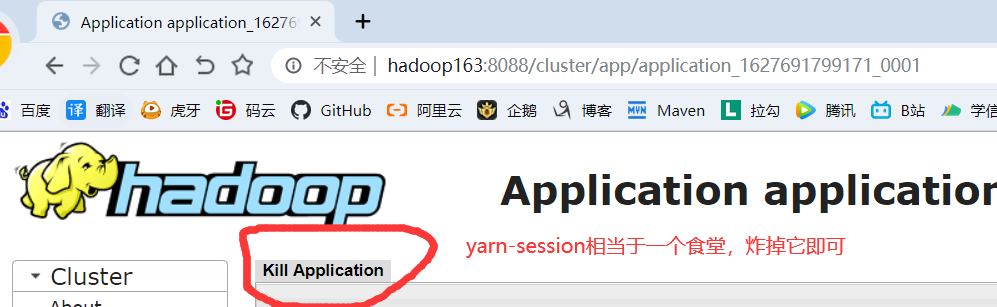
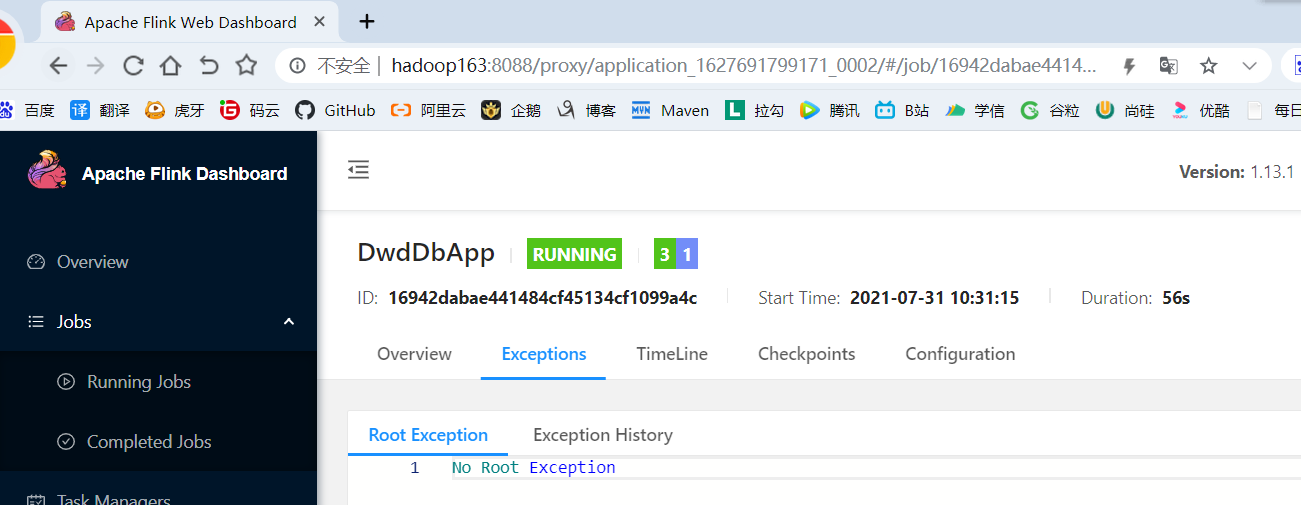
(8)再次查看,发现没有异常日志
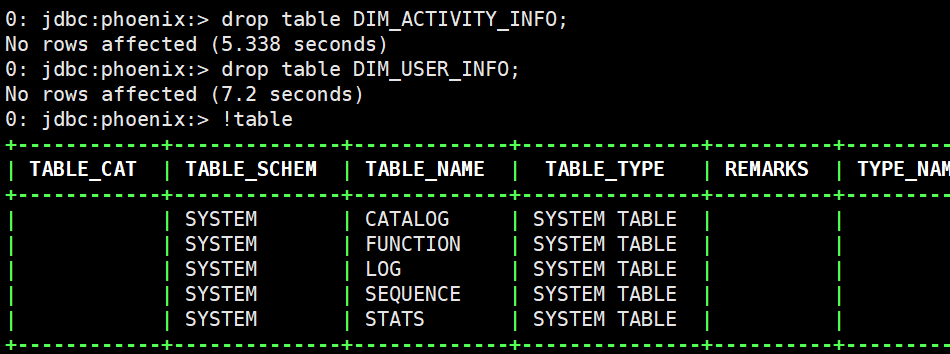
(9)将hbase中的表删除
(10)将kafka中的所有主题删除

(11)启动日志服务器(测试日志能否到达Kafka,在此之前必须保证nginx已启动)
log-lg.sh start
(12)启动maxwell,然后使用maxwell-bootstrap导入数据
vim /home/atguigu/bin/maxwell.sh
#!/bin/bash maxwell_home=/opt/module/maxwell-1.27.1 case $1 in start) echo "========== $host 启动maxwell =========" source /etc/profile $maxwell_home/bin/maxwell --config $maxwell_home/config.properties --daemon ;; stop) echo "========== $host停止 maxwell =========" source /etc/profile jps | awk '/Maxwell/ {print $1}' | xargs kill ;; *) echo "你启动的姿势不对" echo " start 启动maxwell集群" echo " stop 停止maxwwll集群" ;;
chmod +x /home/atguigu/bin/maxwell.sh
maxwell.sh start
/opt/module/maxwell-1.27.1/bin/maxwell-bootstrap --user maxwell --password aaaaaa --host hadoop162 --database flinkdb --table user_info --client_id maxwell_1
(13)查看Hbase是否有user_info表,且是否有数据

(14)生产日志数据,查看Kafka中是否有数据
cd /opt/software/mock/mock_log
java -jar gmall2020-mock-log-2020-12-18.jar
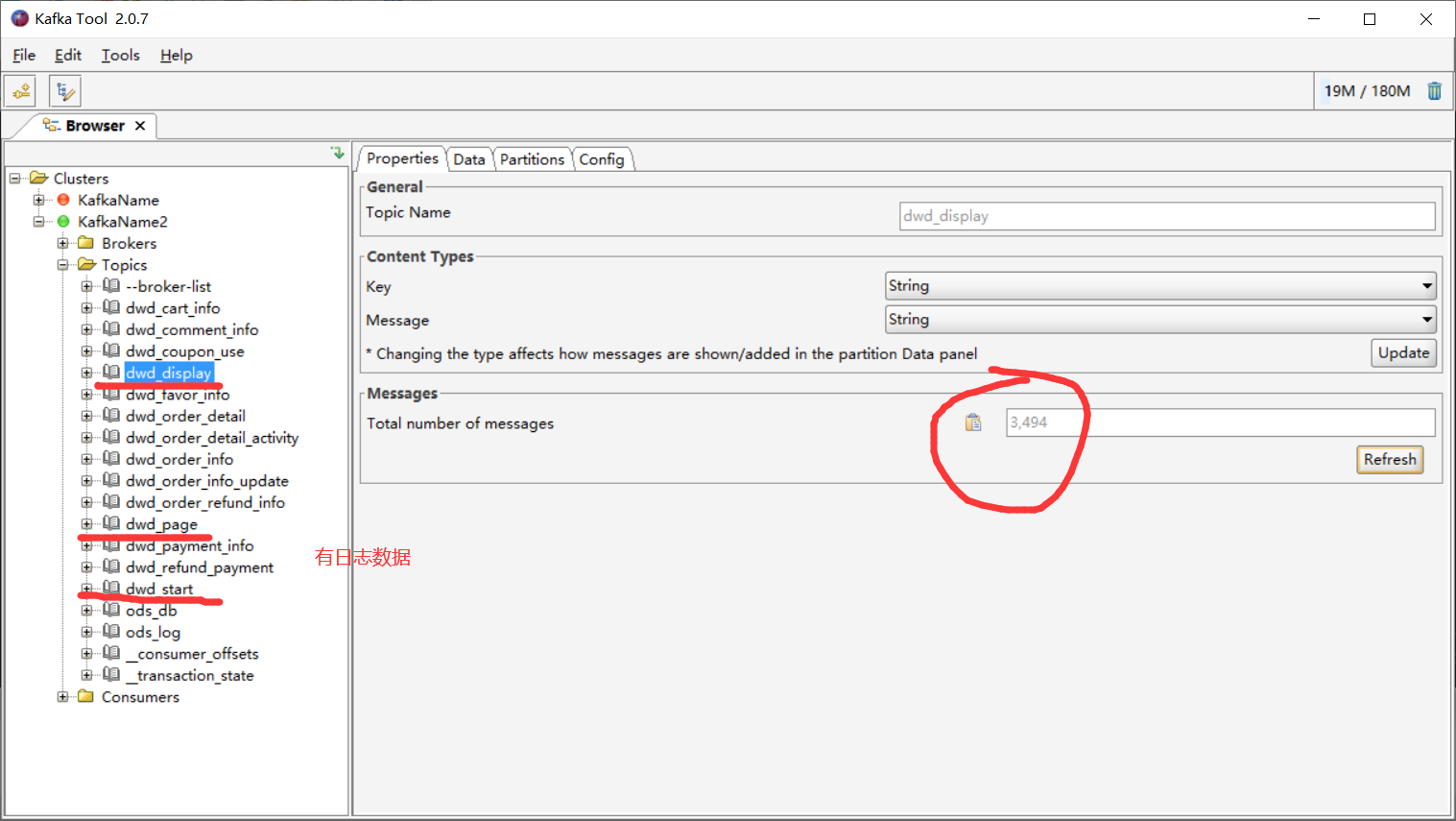
(15)生产业务数据,查看Kafka中是否有数据
cd /opt/software/mock/mock_db
java -jar gmall2020-mock-db-2020-12-23.jar