第4章 Flink运行架构
4.1 运行架构
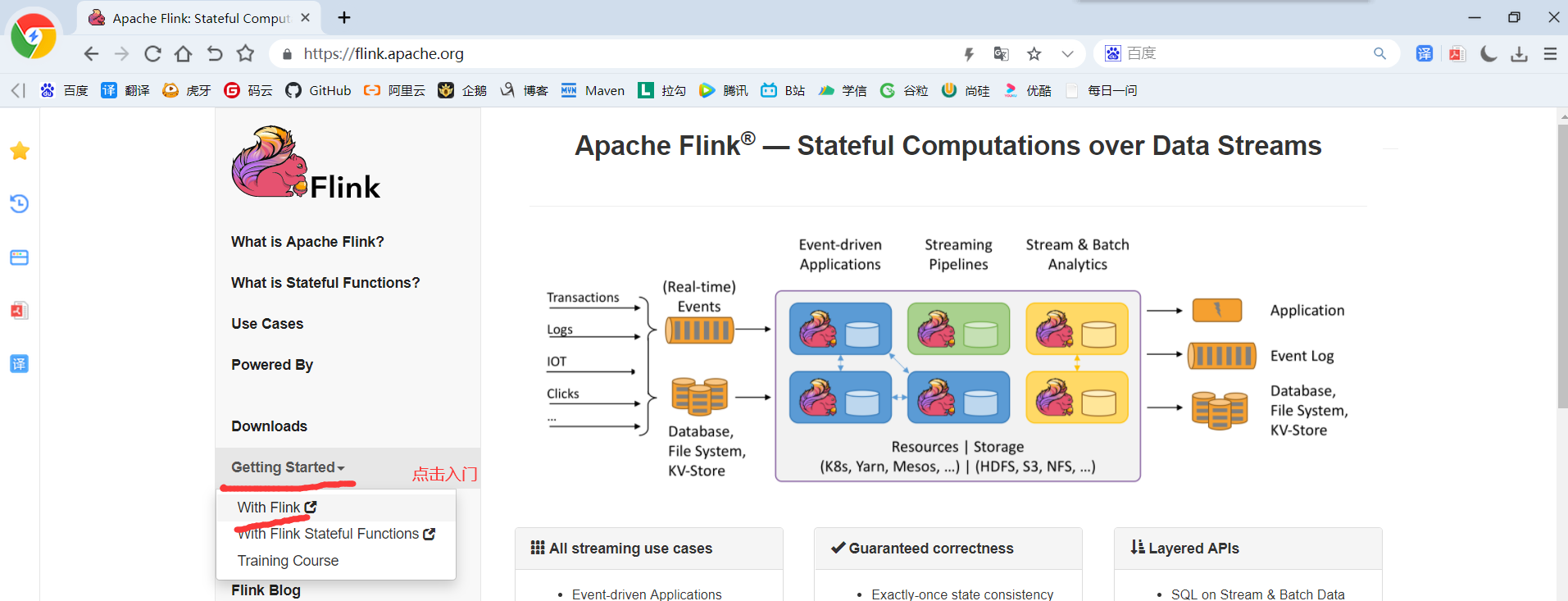
查看官网介绍之后得出结论:Flink运行时包含2种进程------1个JobManager和至少1个TaskManager
4.1.1 客户端
严格上说, 客户端不是运行和程序执行的一部分, 而是用于准备和发送dataflow(数据流)到JobManager,然后客户端可以断开与JobManager的连接(detached mode), 也可以继续保持与JobManager的连接(attached mode)
客户端作为触发执行的java或者scala代码的一部分运行, 也可以在命令行运行:bin/flink run ...

4.1.2 JobManager
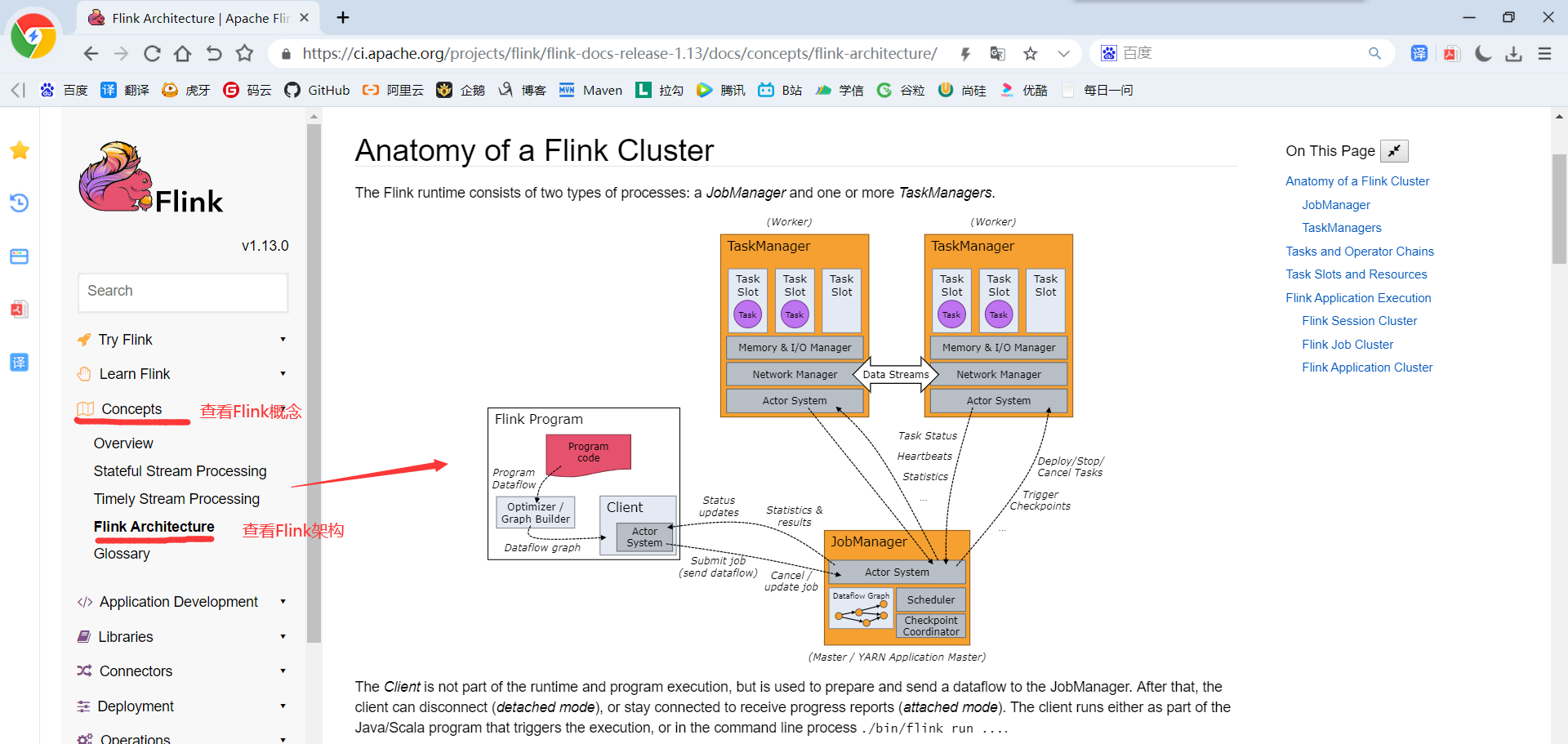
控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个的JobManager所控制执行。JobManager会先接收到要执行的应用程序,这个应用程序会包括:作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它资源的JAR包。
JobManager会把JobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。JobManager会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。这个进程包含3个不同的组件
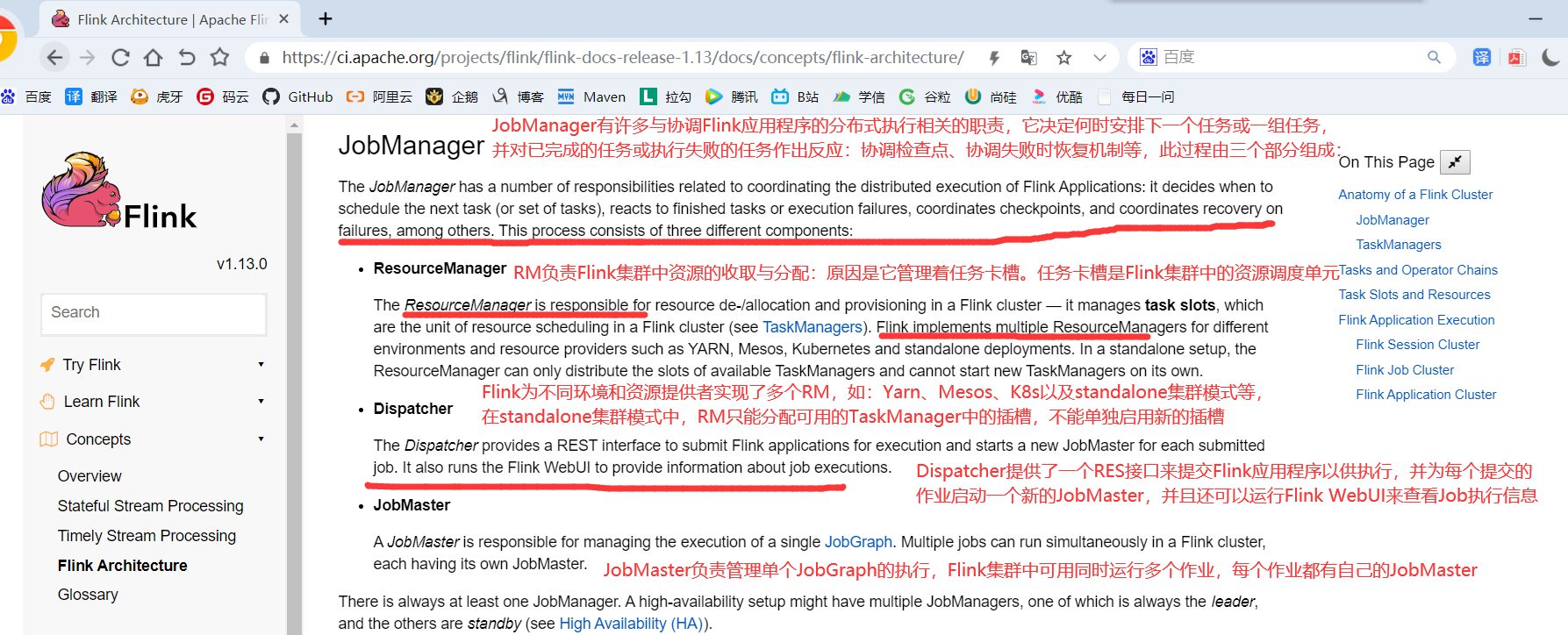
4.1.2.1 ResourceManager
负责资源的管理,在整个 Flink 集群中只有一个 ResourceManager. 注意这个ResourceManager不是Yarn中的ResourceManager, 是Flink中内置的, 只是赶巧重名了而已.
主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger插槽是Flink中定义的处理资源单元。当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。另外,ResourceManager还负责终止空闲的TaskManager,释放计算资源。
4.1.2.2 Dispatcher
负责接收用户提供的作业,并且负责为这个新提交的作业启动一个新的JobMaster 组件. Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
4.1.2.3 JobMaster
JobMaster负责管理单个JobGraph的执行.多个Job可以同时运行在一个Flink集群中, 每个Job都有一个自己的JobMaster.
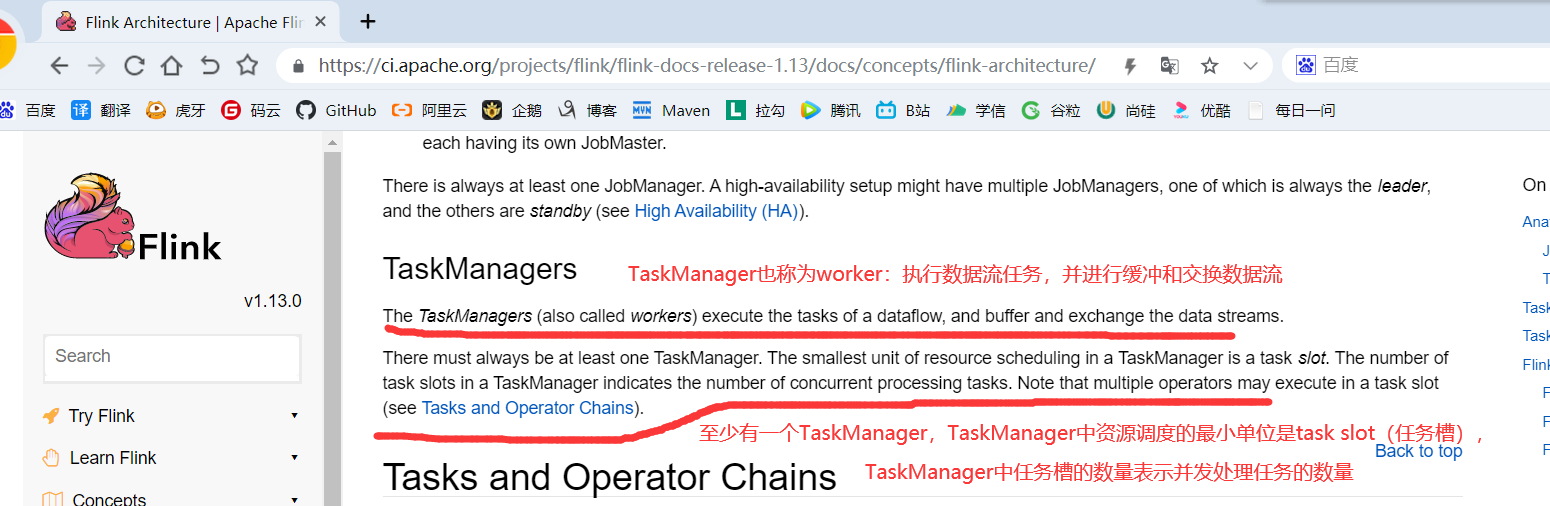
4.1.3 TaskManager
Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
程序启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据。
4.2 核心概念
4.2.1 TaskManager与Slots
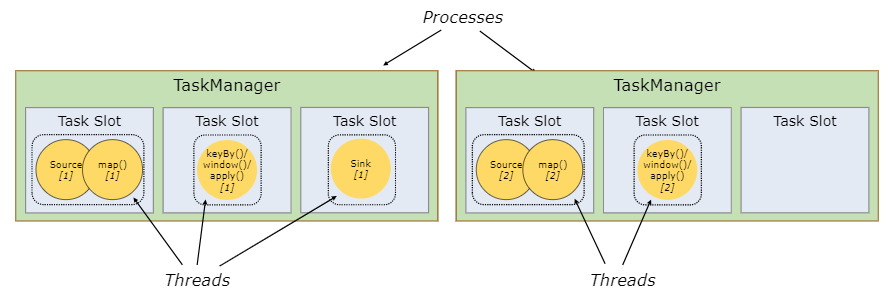
Flink中每一个worker(TaskManager)都是一个JVM进程,它可能会在独立的线程上执行一个Task。为了控制一个worker能接收多少个task,worker通过Task Slot来进行控制(一个worker至少有一个Task Slot)。
这里的Slot如何来理解呢?很多的文章中经常会和Spark框架进行类比,将Slot类比为Core,其实简单这么类比是可以的,可实际上,可以考虑下,当Spark申请资源后,这个Core执行任务时有可能是空闲的,但是这个时候Spark并不能将这个空闲下来的Core共享给其他Job使用,所以这里的Core是Job内部共享使用的。接下来我们再回想一下,之前在Yarn Session-Cluster模式时,其实是可以并行执行多个Job的,那如果申请两个Slot,而执行Job时,只用到了一个,剩下的一个怎么办?那我们自认而然就会想到可以将这个Slot给并行的其他Job,对吗?所以Flink中的Slot和Spark中的Core还是有很大区别的。
每个task slot表示TaskManager拥有资源的一个固定大小的子集。假如一个TaskManager有三个slot,那么它会将其管理的内存分成三份给各个slot。资源slot化意味着一个task将不需要跟来自其他job的task竞争被管理的内存,取而代之的是它将拥有一定数量的内存储备。需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离task的受管理的内存。

4.2.2 Parallelism(并行度)
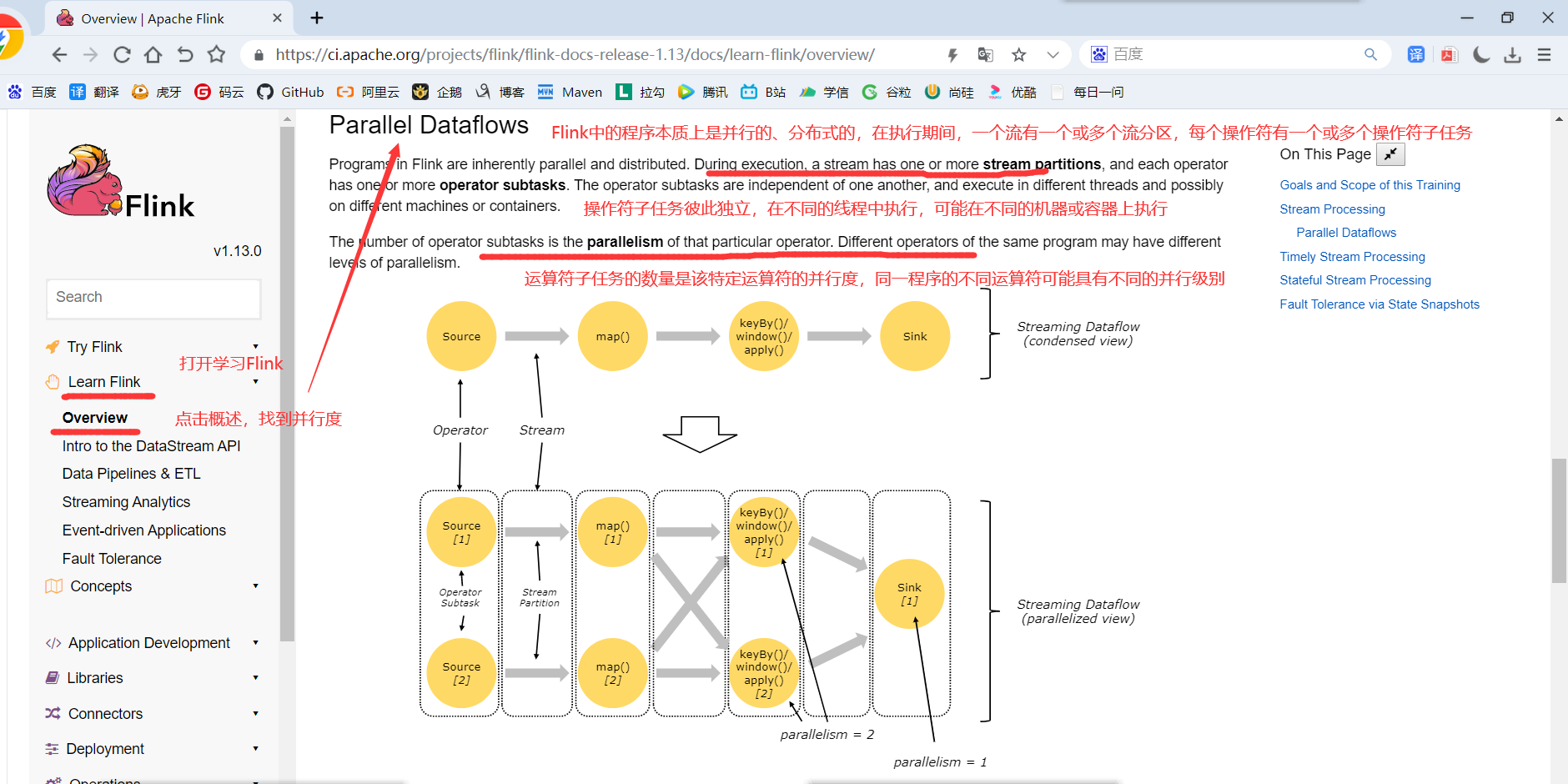
一个特定算子的子任务(subtask)的个数被称之为这个算子的并行度(parallelism),一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
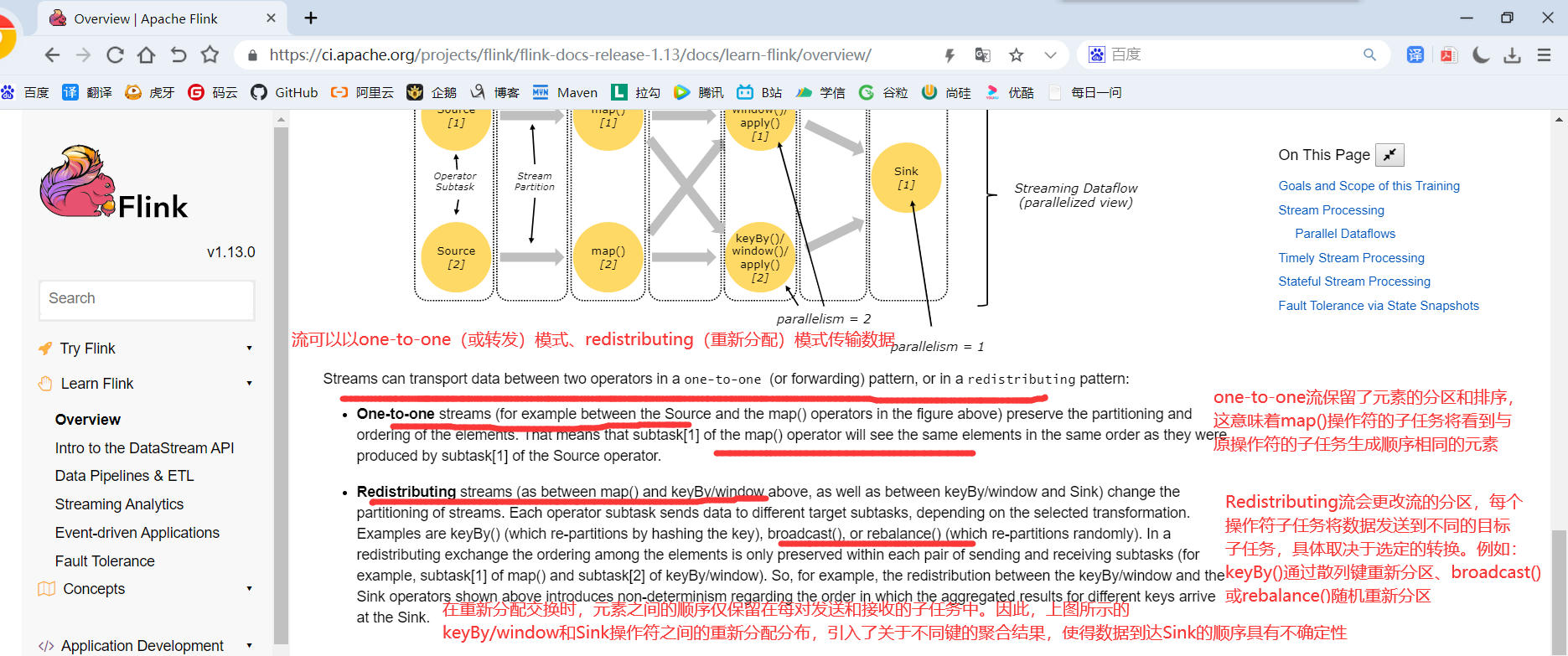
Stream在算子之间传输数据的形式可以是one-to-one(forwarding)的模式也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类。
1)One-to-one:
stream(比如在source和map operator之间)维护着分区以及元素的顺序。那意味着flatmap 算子的子任务看到的元素的个数以及顺序跟source 算子的子任务生产的元素的个数、顺序相同,map、fliter、flatMap等算子都是one-to-one的对应关系。类似于spark中的窄依赖
2)Redistributing:
stream(map()跟keyBy/window之间或者keyBy/window跟sink之间)的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如,keyBy()基于hashCode重分区、broadcast和rebalance会随机重新分区,这些算子都会引起redistribute过程,而redistribute过程就类似于Spark中的shuffle过程。类似于spark中的宽依赖
4.2.3 Task与SubTask
一个算子就是一个Task. 一个算子的并行度是几, 这个Task就有几个SubTask
4.2.4 Operator Chains(任务链)
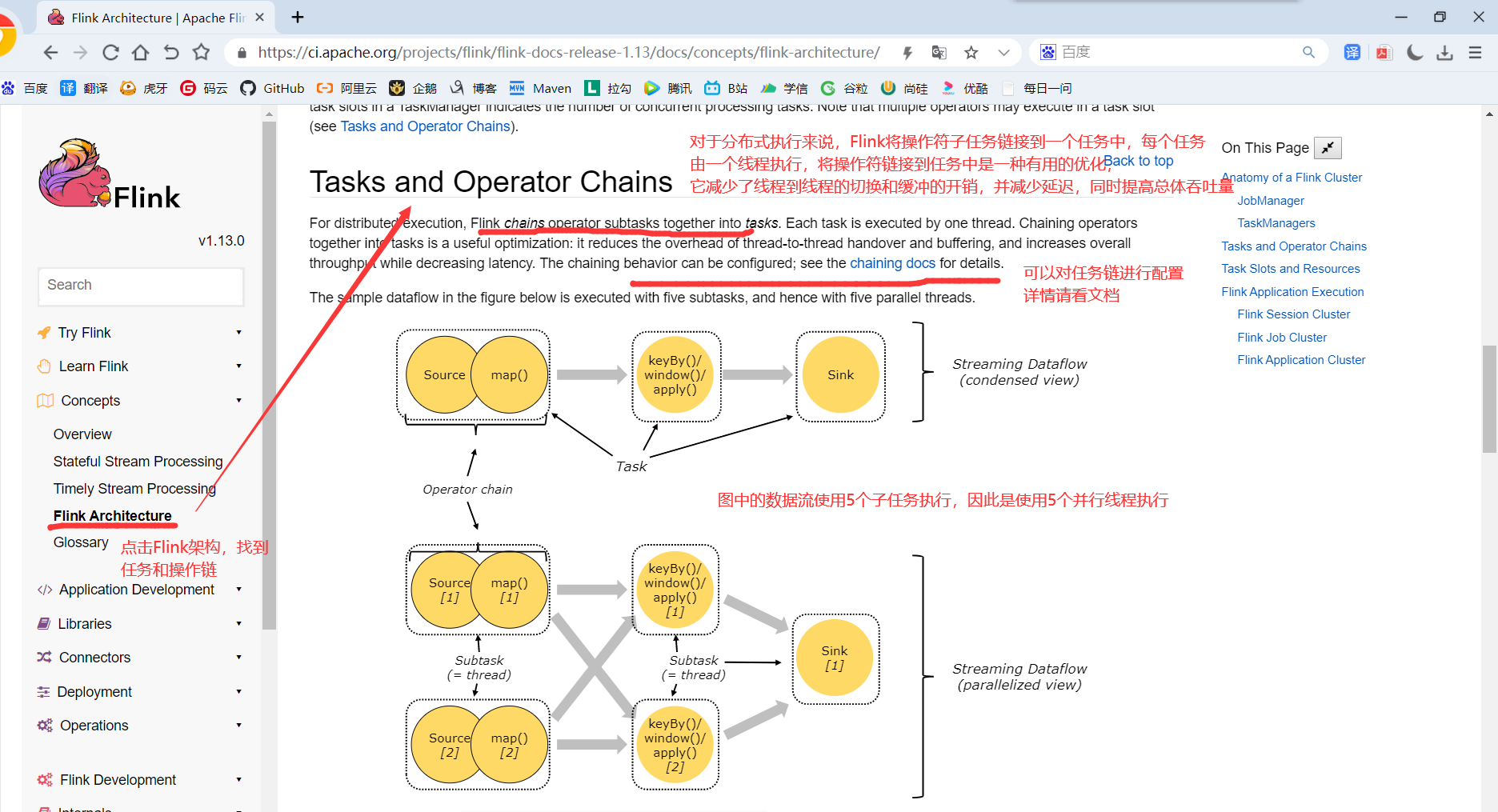
相同并行度的one to one操作,Flink将这样相连的算子链接在一起形成一个task,原来的算子成为里面的一部分。 每个task被一个线程执行,将算子链接成task是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。链接的行为可以在编程API中进行指定。
4.2.5 ExecutionGraph(执行图)
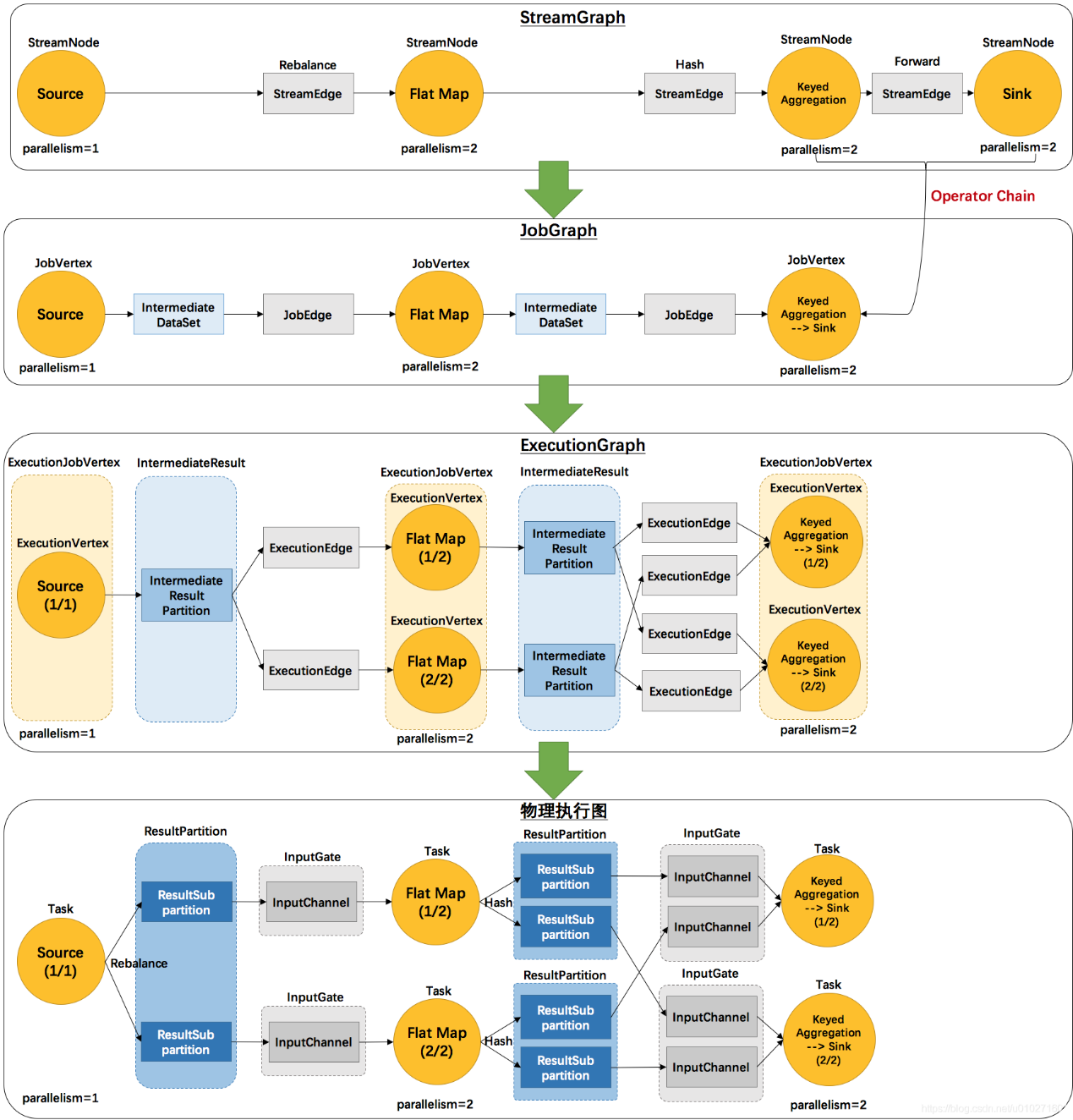
由Flink程序直接映射成的数据流图是StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink需要将逻辑流图转换为物理数据流图(也叫执行图),详细说明程序的执行方式。
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> Physical Graph。
1)StreamGraph:
是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
2)JobGraph:
StreamGraph经过优化后生成了 JobGraph,是提交给 JobManager 的数据结构。主要的优化为: 将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
3)ExecutionGraph:
JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
4)Physical Graph:
JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
以下是2个并发度(Source为1个并发度)的 SocketTextStreamWordCount 四层执行图的演变过程:
env.socketTextStream().flatMap(…).keyBy(0).sum(1).print();
4.3 提交流程
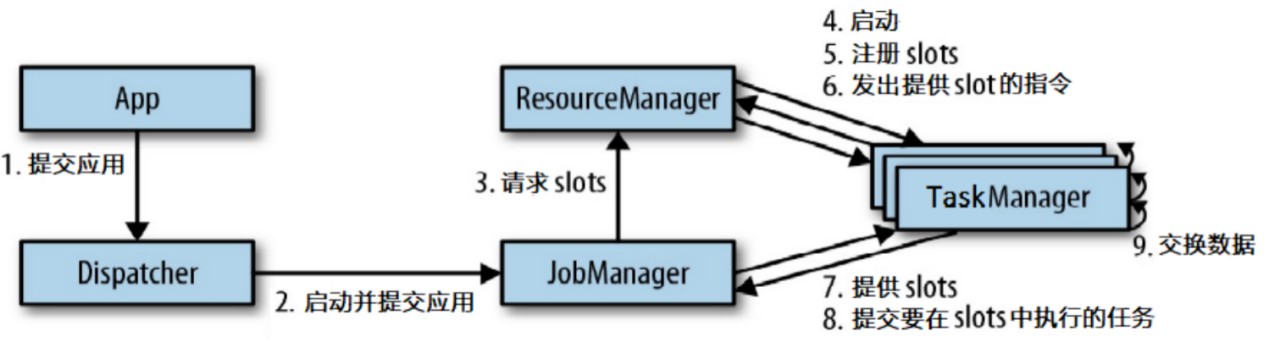
4.3.1 高级视角提交流程(通用提交流程)
我们来看看当一个应用提交执行时,Flink的各个组件是如何交互协作的:
4.3.2 yarn-cluster提交流程per-job

1)Flink任务提交后,Client向HDFS上传Flink的Jar包和配置
2)向Yarn ResourceManager提交任务,ResourceManager分配Container资源
3)通知对应的NodeManager启动ApplicationMaster,ApplicationMaster启动后加载Flink的Jar包和配置构建环境,然后启动JobManager
4)ApplicationMaster向ResourceManager申请资源启动TaskManager
5)ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager
6)NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
7)TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
第5章 Flink流处理核心编程
和其他所有的计算框架一样,Llink也有一些基础的开发步骤以及基础,核心的API,从开发步骤的角度来讲,主要分为四大部分:

5.1 Environment

Flink Job在提交执行计算时,需要首先建立和Flink框架之间的联系,也就指的是当前的flink运行环境,只有获取了环境信息,才能将task调度到不同的taskManager执行。而这个环境对象的获取方式相对比较简单
// 批处理环境 ExecutionEnvironment benv = ExecutionEnvironment.getExecutionEnvironment();
// 流式数据处理环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
5.2 Source

Flink框架可以从不同的来源获取数据,将数据提交给框架进行处理, 我们将获取数据的来源称之为数据源(Source)。
5.2.1 准备工作
1)导入注解工具依赖, 方便生产POJO类
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.16</version> <scope>provided</scope> </dependency>
2)准备一个WaterSensor类方便演示
package com.yuange.flink.day02; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * @作者:袁哥 * @时间:2021/7/16 18:39 * 水位传感器:用于接收水位数据 */ @AllArgsConstructor @NoArgsConstructor @Data public class WaterSensor { private String id; //传感器编号 private Long ts; //时间戳 private Integer vc; //水位 }
5.2.2 从Java的集合中读取数据
一般情况下,可以将数据临时存储到内存中,形成特殊的数据结构后,作为数据源使用。这里的数据结构采用集合类型是比较普遍的。
package com.yuange.flink.day02; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/16 18:55 */ public class Flink_Source_Collection { public static void main(String[] args) throws Exception { //创建执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); List<WaterSensor> waterSensors = Arrays.asList( new WaterSensor("ws_001", 1577844001L, 45), new WaterSensor("ws_002", 1577844015L, 43), new WaterSensor("ws_003", 1577844020L, 42)); environment.fromCollection(waterSensors).print(); environment.execute(); } }

5.2.3 从文件读取数据
package com.yuange.flink.day02; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 19:01 */ public class Flink_Source_File { public static void main(String[] args) throws Exception { //创建执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); // environment.readTextFile("input/words.txt").print(); environment.readTextFile("hdfs://hadoop162:8020/words.txt").print(); environment.execute(); } }
说明:
1)参数可以是目录也可以是文件
2)路径可以是相对路径也可以是绝对路径
3)相对路径是从系统属性user.dir获取路径: idea下是project的根目录, standalone模式下是集群节点根目录
4)也可以从hdfs目录下读取, 使用路径:hdfs://...., 由于Flink没有提供hadoop相关依赖, 需要pom中添加相关依赖:
<!-- 添加Hadoop客户端 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
<scope>provided</scope>
</dependency>
5.2.4 从Socket读取数据
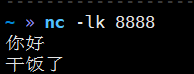
1)启动监控hadoop164的8888端口
nc -lk 8888
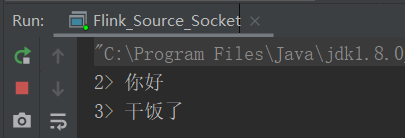
2)启动如下代码的main方法
package com.yuange.flink.day02; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 19:12 */ public class Flink_Source_Socket { public static void main(String[] args) throws Exception { //创建执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.socketTextStream("hadoop164",8888).print(); environment.execute(); } }
3)结果
5.2.5 从Kafka读取数据
1)打开官网:https://flink.apache.org

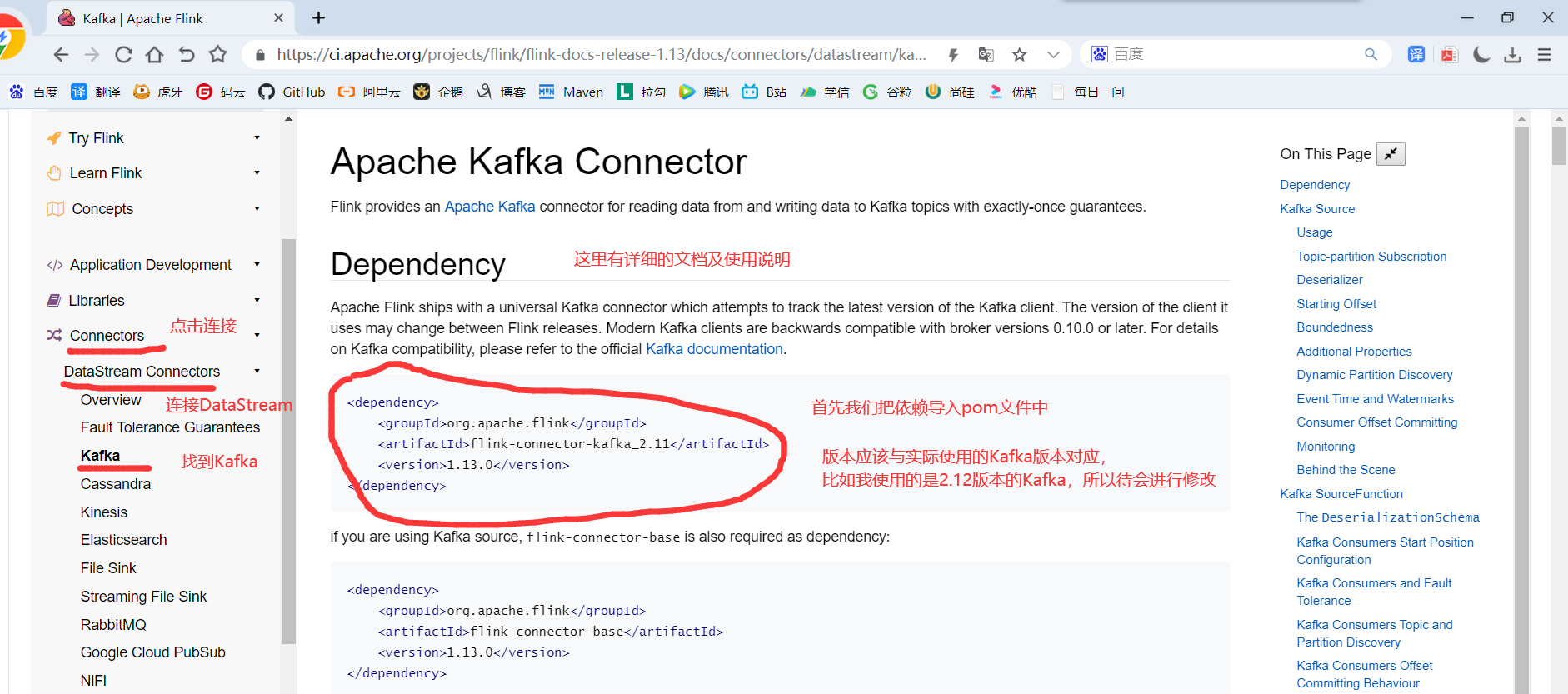
2)添加相应的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.13.1</version>
</dependency>
3)启动Kafka并开启生产者(使用脚本进入生产者客户端)
producer test_kafka_to_flink
4)代码一
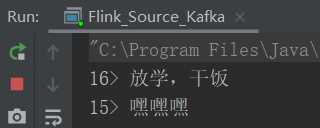
package com.yuange.flink.day02; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import java.util.Properties; /** * @作者:袁哥 * @时间:2021/7/16 19:28 */ public class Flink_Source_Kafka { public static void main(String[] args) throws Exception { //创建执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); Properties process = new Properties(); process.setProperty("bootstrap.servers","hadoop162:9092,hadoop163:9092,hadoop164:9092"); process.setProperty("group.id","Flink_Source_Kafka"); process.setProperty("auto.reset.offset","latest"); DataStreamSource<String> source = environment.addSource( new FlinkKafkaConsumer<String>( "test_kafka_to_flink", new SimpleStringSchema(), process ) ); source.print(); environment.execute(); } }
5)结果一

6)代码二
package com.yuange.flink.day02; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.streaming.util.serialization.JSONKeyValueDeserializationSchema; import java.util.Properties; /** * @作者:袁哥 * @时间:2021/7/16 19:28 */ public class Flink_Source_Kafka02 { public static void main(String[] args) throws Exception { //创建执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); Properties process = new Properties(); process.setProperty("bootstrap.servers","hadoop162:9092,hadoop163:9092,hadoop164:9092"); process.setProperty("group.id","Flink_Source_Kafka"); process.setProperty("auto.reset.offset","latest"); DataStreamSource<ObjectNode> source = environment.addSource( new FlinkKafkaConsumer<ObjectNode>( "test_kafka_to_flink", new JSONKeyValueDeserializationSchema(true), //解析JSON,为true时可以将元数据也加入其中 process ) ); source.print(); environment.execute(); } }
7)结果二


5.2.6 自定义Source
大多数情况下,前面的数据源已经能够满足需要,但是难免会存在特殊情况的场合,所以flink也提供了能自定义数据源的方式.
1)启动hadoop164的8888端口
nc -lk 8888
2)启动如下代码的main方法
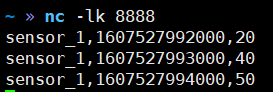
package com.yuange.flink.day02; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.SourceFunction; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.net.Socket; import java.nio.charset.StandardCharsets; /** * @作者:袁哥 * @时间:2021/7/16 19:56 * sensor_1,1607527992000,20 * sensor_1,1607527993000,40 * sensor_1,1607527994000,50 */ public class Flink_Source_Custom { public static void main(String[] args) throws Exception { //创建执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.addSource(new MySource("hadoop164",8888)); environment.execute(); } public static class MySource implements SourceFunction<WaterSensor>{ private String host; private int port; private boolean isRunning = true; private Socket socket; public MySource(String host, int port) { this.host = host; this.port = port; } @Override public void run(SourceContext<WaterSensor> ctx) throws Exception { //实现一个从socket读取数据的source socket = new Socket(host, port); InputStreamReader inputStreamReader = new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); String line = null; while (isRunning && (line = bufferedReader.readLine()) != null){ String[] split = line.split(","); ctx.collect(new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2]))); } } @Override public void cancel() { isRunning = false; try { socket.close(); } catch (IOException e) { e.printStackTrace(); } } } }
3)结果

5.3 Transform

转换算子可以把一个或多个DataStream转成一个新的DataStream.程序可以把多个复杂的转换组合成复杂的数据流拓扑
5.3.1 map
1)作用:将数据流中的数据进行转换, 形成新的数据流,消费一个元素并产出一个元素

2)参数:lambda表达式或MapFunction实现类
3)返回:DataStream → DataStream
4)示例:得到一个新的数据流: 新的流的元素是原来流的元素的平方
(1)匿名内部类对象
package com.yuange.flink.day02; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 21:25 */ public class Flink_TransForm_Map_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.fromElements(1,3,5,7,9) .map(new MapFunction<Integer, Integer>() { @Override public Integer map(Integer value) throws Exception { return value * value; } }).print(); environment.execute(); } }
(2)Lambda表达式表达式
package com.yuange.flink.day02; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 21:25 */ public class Flink_TransForm_Map_Anonymous_Lambda { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.fromElements(1,3,5,7,9) .map(value -> value * value) .print(); environment.execute(); } }
(3)静态内部类
package com.yuange.flink.day02; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 21:30 */ public class Flink_TransForm_Map_StaticClass { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.fromElements(1,3,5,7,9) .map(new MyMapFunction()) .print(); environment.execute(); } public static class MyMapFunction implements MapFunction<Integer,Integer>{ @Override public Integer map(Integer value) throws Exception { return value * value; } } }
(4)Rich...Function类
所有Flink函数类都有其Rich版本。它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。也有意味着提供了更多的,更丰富的功能。例如:RichMapFunction等
package com.yuange.flink.day02; import org.apache.flink.api.common.functions.RichMapFunction; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 21:33 */ public class Flink_TransForm_Map_RichMapFunction { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(5); environment.fromElements(1,3,5,7,9) .map(new MyRichMapFunction()).setParallelism(2) .print(); environment.execute(); } public static class MyRichMapFunction extends RichMapFunction<Integer,Integer>{ //CTRL + o 快捷键,实现父类中的方法 // 默认生命周期方法, 初始化方法, 在每个并行度上只会被调用一次 @Override public void open(Configuration parameters) throws Exception { System.out.println("open ... 执行一次"); } // 默认生命周期方法, 最后一个方法, 做一些清理工作, 在每个并行度上只调用一次 @Override public void close() throws Exception { System.out.println("close ... 执行一次"); } @Override public Integer map(Integer value) throws Exception { System.out.println("map ... 一个元素执行一次"); return value * value; } } }
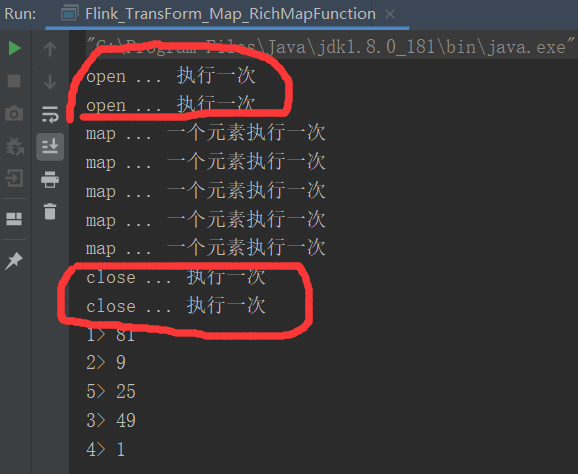
1)默认生命周期方法, 初始化方法, 在每个并行度上只会被调用一次, 而且先被调用
2)默认生命周期方法, 最后一个方法, 做一些清理工作, 在每个并行度上只调用一次, 而且是最后被调用
3)getRuntimeContext()方法提供了函数的RuntimeContext的一些信息,例如函数执行的并行度,任务的名字,以及state状态. 开发人员在需要的时候自行调用获取运行时上下文对象.
5.3.2 flatMap
1)作用:消费一个元素并产生零个或多个元素
2)参数:FlatMapFunction实现类
3)返回:DataStream → DataStream
4)示例:
(1)匿名内部类写法
package com.yuange.flink.day02; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/16 23:10 */ public class Flink_TransForm_FlatMap_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.fromElements(1,3,5,7,9) .flatMap(new FlatMapFunction<Integer, Integer>() { @Override public void flatMap(Integer value, Collector<Integer> collector) throws Exception { collector.collect(value * value); collector.collect(value * value * value); } }) .print(); environment.execute(); } }
(2)Lambda表达式写法
package com.yuange.flink.day02; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/16 23:10 */ public class Flink_TransForm_FlatMap_Anonymous_Lambda { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.fromElements(1,3,5,7,9) //在使用Lambda表达式表达式的时候, 由于泛型擦除的存在, 在运行的时候无法获取泛型的具体类型, // 全部当做Object来处理, 及其低效, 所以Flink要求当参数中有泛型的时候, 必须明确指定泛型的类型 .flatMap((Integer value, Collector<Integer> collector) ->{ collector.collect(value * value); collector.collect(value * value * value); }).returns(Types.INT) .print(); environment.execute(); } }
5.3.3 filter
1)作用:根据指定的规则将满足条件(true)的数据保留,不满足条件(false)的数据丢弃

2)参数:FlatMapFunction实现类
3)返回:DataStream → DataStream
4)示例:
(1)匿名内部类写法
package com.yuange.flink.day02; import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/16 23:10 */ public class Flink_TransForm_Filter_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.fromElements(1,2,3,4,5) .filter(new FilterFunction<Integer>() { @Override public boolean filter(Integer value) throws Exception { return value % 2 == 0; } }) .print(); environment.execute(); } }
(2)Lambda表达式写法
package com.yuange.flink.day02; import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 23:10 */ public class Flink_TransForm_Filter_Anonymous_Lambda { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.fromElements(1,2,3,4,5) .filter(value -> value % 2 == 0) .print(); environment.execute(); } }
5.3.4 keyBy
1)作用:把流中的数据分到不同的分区(并行度)中.具有相同key的元素会分到同一个分区中.一个分区中可以有多重不同的key,在内部是使用的是key的hash分区来实现的

2)参数:Key选择器函数:Interface KeySelector<IN, KEY> (什么值不可以作为KeySelector的Key)
(1)没有覆写hashCode方法的POJO, 而是依赖Object的hashCode. 因为这样分组没有任何的意义: 每个元素都会得到一个独立无二的组. 实际情况是:可以运行, 但是分的组没有意义
(2)任何类型的数组
3)返回:DataStream → KeyedStream
4)示例:
(1)匿名内部类写法
package com.yuange.flink.day02; import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 23:10 */ public class Flink_TransForm_KeyBy_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.fromElements(1,3,3,6,5) .keyBy(new KeySelector<Integer, String>() { @Override public String getKey(Integer value) throws Exception { return value % 2 == 0 ? "偶数" : "奇数"; } }) .print(); environment.execute(); } }
(2)Lambda表达式写法
package com.yuange.flink.day02; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 23:10 */ public class Flink_TransForm_KeyBy_Anonymous_Lambda { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.fromElements(1,3,3,6,5) .keyBy(value -> value % 2 == 0 ? "偶数" : "奇数") .print(); environment.execute(); } }
5.3.5 shuffle
1)作用:把流中的元素随机打乱. 对同一个组数据, 每次执行得到的结果都不同.
2)参数:无
3)返回:DataStream → DataStream
4)示例:
package com.yuange.flink.day02; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 23:10 */ public class Flink_TransForm_Shuffle_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.fromElements(1,3,3,6,5) .shuffle() .print(); environment.execute(); } }
5.3.7 connect
1)作用:在某些情况下,我们需要将两个不同来源的数据流进行连接,实现数据匹配,比如订单支付和第三方交易信息,这两个信息的数据就来自于不同数据源,连接后,将订单支付和第三方交易信息进行对账,此时,才能算真正的支付完成。
Flink中的connect算子可以连接两个保持他们类型的数据流,两个数据流被connect之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
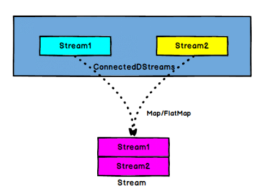
2)参数:另外一个流
3)返回:DataStream[A], DataStream[B] -> ConnectedStreams[A,B]
4)示例:
package com.yuange.flink.day02; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.ConnectedStreams; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 23:10 */ public class Flink_TransForm_Connect_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); //两个流中存储的数据类型可以不同 //只是机械的合并在一起, 内部仍然是分离的2个流 //只能2个流进行connect, 不能有第3个参与 DataStreamSource<Integer> integerDataStreamSource = environment.fromElements(1, 3, 5, 6, 7, 8); DataStreamSource<String> stringDataStreamSource = environment.fromElements("a", "b", "f"); // 把两个流连接在一起: 貌合神离 ConnectedStreams<Integer, String> connect = integerDataStreamSource.connect(stringDataStreamSource); connect.getFirstInput().print("first"); connect.getSecondInput().print("second"); environment.execute(); } }
5.3.8 union
1)作用:对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream
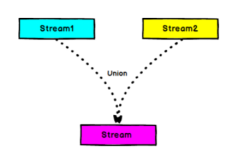
2)示例
package com.yuange.flink.day03; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/17 21:21 */ public class Flink_TransForm_Union_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<Integer> dataStreamSource = environment.fromElements(1, 3, 45,6, 7, 8); DataStreamSource<Integer> dataStreamSource2 = environment.fromElements(10, 30, 450,60, 70, 80); DataStreamSource<Integer> dataStreamSource3 = environment.fromElements(100, 30, 4500,600, 700, 800); //把多个流union在一起成为一个流, 这些流中存储的数据类型必须一样: 水乳交融 dataStreamSource.union(dataStreamSource2) .union(dataStreamSource3) .print(); environment.execute(); } }
connect与 union 区别:
(1)union之前两个或多个流的类型必须是一样,connect可以不一样
(2)connect只能操作两个流,union可以操作多个
5.3.9 简单滚动聚合算子
1)常见的滚动聚合算子:sum、min、max、minBy、maxBy
2)作用:KeyedStream的每一个支流做聚合。执行完成后,会将聚合的结果合成一个流返回,所以结果都是DataStream
3)参数:如果流中存储的是POJO或者scala的样例类, 参数使用字段名. 如果流中存储的是元组, 参数就是位置(基于0...)
4)返回:KeyedStream -> SingleOutputStreamOperator
5)示例:
(1)示例1:
package com.yuange.flink.day03; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/17 21:21 */ public class Flink_TransForm_roll_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<Integer> dataStreamSource = environment.fromElements(1, 3, 45,6, 7, 8); KeyedStream<Integer, String> integerStringKeyedStream = dataStreamSource.keyBy(value -> value % 2 == 0 ? "奇数" : "偶数"); integerStringKeyedStream.sum(0).print("sum"); integerStringKeyedStream.max(0).print("max"); integerStringKeyedStream.min(0).print("min"); environment.execute(); } }
(2)示例2:分组聚合后, 理论上只能取分组字段和聚合结果, 但是Flink允许其他的字段也可以取出来, 其他字段默认情况是取的是这个组内第一个元素的字段值
package com.yuange.flink.day03; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/17 21:21 */ public class Flink_TransForm_roll2_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 30)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = environment.fromCollection(waterSensors) .keyBy(WaterSensor::getId); waterSensorStringKeyedStream .sum("vc") .print("MaxBy"); environment.execute(); } }
(3)示例3:
package com.yuange.flink.day03; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/17 21:21 */ public class Flink_TransForm_roll3_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 30)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); KeyedStream<WaterSensor, String> waterSensorStringKeyedStream = environment.fromCollection(waterSensors) .keyBy(WaterSensor::getId); //maxBy和minBy可以指定当出现相同值的时候,其他字段是否取第一个 //true表示取第一个, false表示取与最大值(最小值)同一行的 waterSensorStringKeyedStream .maxBy("vc",false) .print("max"); environment.execute(); } }
5.3.10 reduce
1)作用:一个分组数据流的聚合操作,合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
2)疑问:为什么还要把中间值也保存下来? 考虑流式数据的特点: 没有终点, 也就没有最终的概念了,任何一个中间的聚合结果都是值!
3)参数:interface ReduceFunction<T>
4)返回:KeyedStream -> SingleOutputStreamOperator
5)示例:
(1)匿名内部类写法
package com.yuange.flink.day03; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/17 21:21 */ public class Flink_TransForm_reduce_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); KeyedStream<WaterSensor, String> kbStream = environment.fromCollection(waterSensors) .keyBy(WaterSensor::getId); kbStream.reduce(new ReduceFunction<WaterSensor>() { @Override public WaterSensor reduce(WaterSensor value1, WaterSensor value2) throws Exception { System.out.println("ReduceFunction-------"); return new WaterSensor(value1.getId(),value1.getTs(),value1.getVc() + value2.getVc()); } }).print(); environment.execute(); } }
(2)Lambda表达式写法
package com.yuange.flink.day03; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/17 21:21 */ public class Flink_TransForm_reduce_Anonymous_Lambda { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); KeyedStream<WaterSensor, String> kbStream = environment.fromCollection(waterSensors) .keyBy(WaterSensor::getId); //聚合后结果的类型, 必须和原来流中元素的类型保持一致 kbStream.reduce( (value1, value2) -> { System.out.println("ReduceFunction-------"); return new WaterSensor(value1.getId(),value1.getTs(),value1.getVc() + value2.getVc()); }).print(); environment.execute(); } }
5.3.11 process
1)作用:process算子在Flink算是一个比较底层的算子, 很多类型的流上都可以调用, 可以从流中获取更多的信息(不仅仅数据本身)
2)示例1: 在keyBy之前的流上使用
package com.yuange.flink.day03; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.util.Collector; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/17 21:21 */ public class Flink_TransForm_process_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); environment.fromCollection(waterSensors) .process(new ProcessFunction<WaterSensor, Tuple2<String,Integer>>() { @Override public void processElement(WaterSensor value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception { out.collect(new Tuple2<>(value.getId(),value.getVc())); } }) .print(); environment.execute(); } }

3)示例2: 在keyBy之后的流上使用
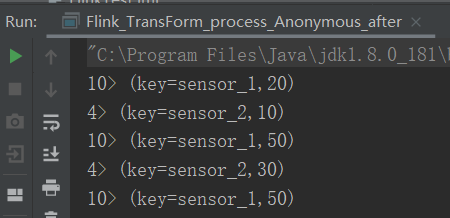
package com.yuange.flink.day03; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.util.Collector; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/17 21:21 */ public class Flink_TransForm_process_Anonymous_after { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); environment.fromCollection(waterSensors) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, Tuple2<String,Integer>>() { @Override public void processElement(WaterSensor value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception { out.collect(new Tuple2<>("key=" + ctx.getCurrentKey(),value.getVc())); } }) .print(); environment.execute(); } }
5.3.12 对流重新分区的几个算子
1)KeyBy:先按照key分组, 按照key的双重hash来选择后面的分区
package com.yuange.flink.day02; import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/16 23:10 */ public class Flink_TransForm_KeyBy_Anonymous { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.fromElements(1,3,3,6,5) .keyBy(new KeySelector<Integer, String>() { @Override public String getKey(Integer value) throws Exception { return value % 2 == 0 ? "偶数" : "奇数"; } }) .print(); environment.execute(); } }
2)shuffle:对流中的元素随机分区
package com.yuange.flink.day02; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/17 22:42 */ public class Flink_Shuffle { public static void main(String[] args) { StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment(); executionEnvironment.setParallelism(1); DataStreamSource<Integer> s1 = executionEnvironment.fromElements(1, 13, 11, 2, 3, 6); s1.shuffle().print().setParallelism(2); try { executionEnvironment.execute(); } catch (Exception e) { e.printStackTrace(); } } }
3)rebalance:对流中的元素平均分布到每个区.当处理倾斜数据的时候, 进行性能优化
package com.yuange.flink.day02; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/17 22:40 */ public class Flink_Rebalance { public static void main(String[] args) { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(2); DataStreamSource<WaterSensor> s1 = env.fromElements( new WaterSensor("sensor_1", 1L, 10), new WaterSensor("sensor_1", 4L, 40), new WaterSensor("sensor_2", 3L, 30), new WaterSensor("sensor_1", 2L, 40), new WaterSensor("sensor_3", 2L, 40), new WaterSensor("sensor_1", 5L, 50) ); s1 .rebalance() .print().setParallelism(3); try { env.execute(); } catch (Exception e) { e.printStackTrace(); } } }
4)rescale:同 rebalance一样, 也是平均循环的分布数据. 但是要比rebalance更高效, 因为rescale不需要通过网络, 完全走的"管道"
5.4 Sink

Sink有下沉的意思,在Flink中所谓的Sink其实可以表示为将数据存储起来的意思,也可以将范围扩大,表示将处理完的数据发送到指定的存储系统的输出操作,之前我们一直在使用的print方法其实就是一种Sink
public DataStreamSink<T> print(String sinkIdentifier) { PrintSinkFunction<T> printFunction = new PrintSinkFunction<>(sinkIdentifier, false); return addSink(printFunction).name("Print to Std. Out"); }
Flink内置了一些Sink, 除此之外的Sink需要用户自定义
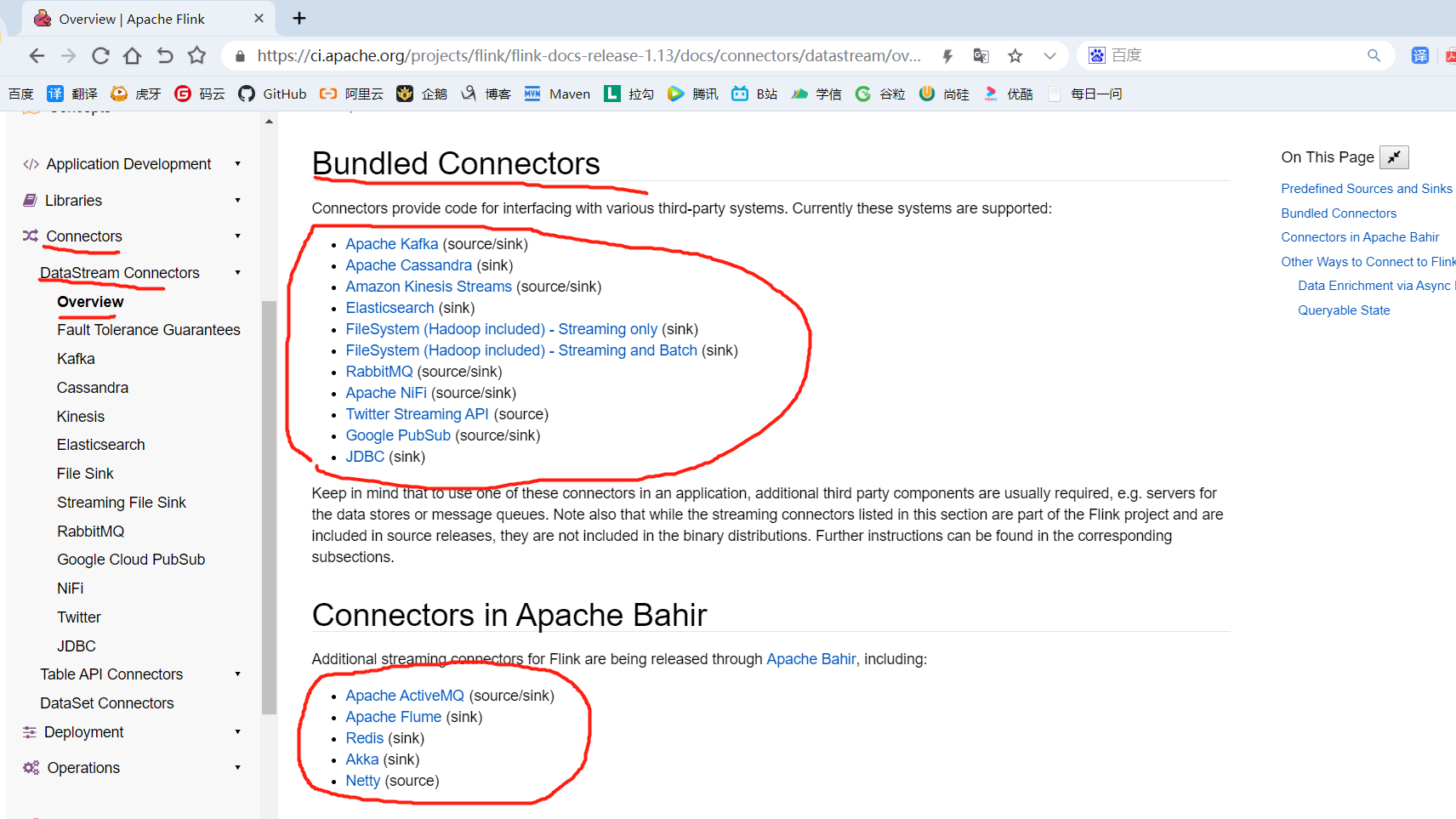
5.4.1 KafkaSink
1)添加Kafka Connector依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
2)启动Zookeeper集群
zk start
3)启动Kafka集群
kafka.sh start
4)Sink到Kafka的示例代码一:
package com.yuange.flink.day03; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/17 23:17 */ public class Flink_Sink_Kafka { public static void main(String[] args) throws Exception { ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); env.fromCollection(waterSensors) .map(WaterSensor::toString) .addSink(new FlinkKafkaProducer<String>( "hadoop162:9092,hadoop163:9092,hadoop164:9092", "kafka_sink_yuange", new SimpleStringSchema() )); env.execute(); } }
5)在linux启动一个消费者, 查看是否收到数据
/opt/module/kafka-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server hadoop162:9092,hadoop163:9092,hadoop164:9092 --topic kafka_sink_yuange

6)Sink到Kafka的示例代码二:
package com.yuange.flink.day03; import com.alibaba.fastjson.JSON; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema; import org.apache.kafka.clients.producer.ProducerRecord; import javax.annotation.Nullable; import java.nio.charset.StandardCharsets; import java.util.ArrayList; import java.util.Properties; /** * @作者:袁哥 * @时间:2021/7/17 23:17 */ public class Flink_Sink_Kafka_Two { public static void main(String[] args) throws Exception { ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); Properties props = new Properties(); props.setProperty("bootstrap.servers","hadoop162:9092,hadoop163:9092,hadoop164:9092"); env.fromCollection(waterSensors) .addSink(new FlinkKafkaProducer<WaterSensor>( "default", new KafkaSerializationSchema<WaterSensor>() { @Override public ProducerRecord<byte[], byte[]> serialize(WaterSensor waterSensor, @Nullable Long aLong) { String s = JSON.toJSONString(waterSensor); return new ProducerRecord<>("kafka_sink_yuange",s.getBytes(StandardCharsets.UTF_8)); } }, props, FlinkKafkaProducer.Semantic.NONE )); env.execute(); } }
7)在linux启动一个消费者, 查看是否收到数据
/opt/module/kafka-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server hadoop162:9092,hadoop163:9092,hadoop164:9092 --topic kafka_sink_yuange

5.4.2 RedisSink
1)添加Redis Connector依赖
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-redis_2.11</artifactId> <version>1.1.5</version> </dependency>
2)启动Redis服务器
redis-server /etc/redis.conf
3)Sink到Redis的示例代码
package com.yuange.flink.day03; import com.alibaba.fastjson.JSON; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.redis.RedisSink; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisConfigBase; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/18 0:33 */ public class Flink_Sink_Redis { public static void main(String[] args) throws Exception { ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); waterSensors.add(new WaterSensor("传感器", 1607527995000L, 30)); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); FlinkJedisConfigBase conf = new FlinkJedisPoolConfig.Builder() .setHost("hadoop162") .setPort(6379) .setDatabase(0) .setMaxTotal(100) .setMinIdle(10) .setTimeout(10 * 1000) .setMinIdle(1) .build(); environment.fromCollection(waterSensors) .keyBy(WaterSensor::getId) .max("vc") .addSink(new RedisSink<>(conf, new RedisMapper<WaterSensor>() { @Override public RedisCommandDescription getCommandDescription() { // 参数1: 根据要写的数据类型, 选择对应的命令 // 参数2: 只针对hash和zset有效, 其他的数据结构忽略 return new RedisCommandDescription(RedisCommand.SET,null); } // 返回要写的这条数据的key @Override public String getKeyFromData(WaterSensor waterSensor) { return waterSensor.getId(); } @Override public String getValueFromData(WaterSensor waterSensor) { return JSON.toJSONString(waterSensor); } })); environment.execute(); } }
4)Redis查看是否收到数据(发送了5条数据, redis中只有2条数据. 原因是hash的field的重复了, 后面的会把前面的覆盖掉)
redis-cli --raw

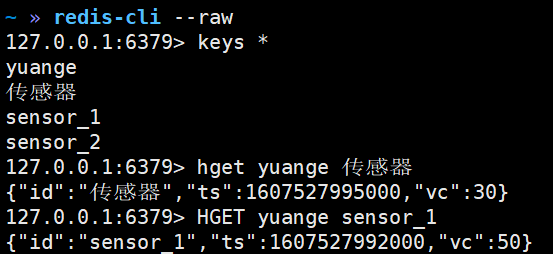
5)Sink到Redis的示例代码(Hash)
package com.yuange.flink.day03; import com.alibaba.fastjson.JSON; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.redis.RedisSink; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisConfigBase; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/18 0:33 */ public class Flink_Sink_Redis_Hash { public static void main(String[] args) throws Exception { ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); waterSensors.add(new WaterSensor("传感器", 1607527995000L, 30)); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); FlinkJedisConfigBase conf = new FlinkJedisPoolConfig.Builder() .setHost("hadoop162") .setPort(6379) .setDatabase(0) .setMaxTotal(100) .setMinIdle(10) .setTimeout(10 * 1000) .setMinIdle(1) .build(); environment.fromCollection(waterSensors) .keyBy(WaterSensor::getId) .max("vc") .addSink(new RedisSink<>(conf, new RedisMapper<WaterSensor>() { @Override public RedisCommandDescription getCommandDescription() { // 参数1: 根据要写的数据类型, 选择对应的命令 // 参数2: 只针对hash和zset有效, 其他的数据结构忽略 return new RedisCommandDescription(RedisCommand.HSET,"yuange"); } // 返回要写的这条数据的key @Override public String getKeyFromData(WaterSensor waterSensor) { return waterSensor.getId(); } @Override public String getValueFromData(WaterSensor waterSensor) { return JSON.toJSONString(waterSensor); } })); environment.execute(); } }
6)Redis查看是否收到数据(Hash)
redis-cli --raw
7)清空数据库
flushall
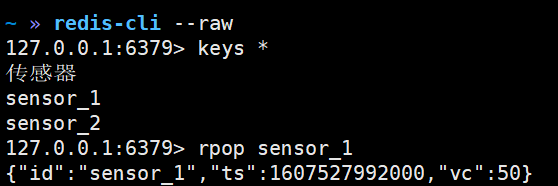
8)Sink到Redis的示例代码(List)
package com.yuange.flink.day03; import com.alibaba.fastjson.JSON; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.redis.RedisSink; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisConfigBase; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/18 0:33 */ public class Flink_Sink_Redis_List { public static void main(String[] args) throws Exception { ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); waterSensors.add(new WaterSensor("传感器", 1607527995000L, 30)); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); FlinkJedisConfigBase conf = new FlinkJedisPoolConfig.Builder() .setHost("hadoop162") .setPort(6379) .setDatabase(0) .setMaxTotal(100) .setMinIdle(10) .setTimeout(10 * 1000) .setMinIdle(1) .build(); environment.fromCollection(waterSensors) .keyBy(WaterSensor::getId) .max("vc") .addSink(new RedisSink<>(conf, new RedisMapper<WaterSensor>() { @Override public RedisCommandDescription getCommandDescription() { // 参数1: 根据要写的数据类型, 选择对应的命令 // 参数2: 只针对hash和zset有效, 其他的数据结构忽略 return new RedisCommandDescription(RedisCommand.RPUSH,null); } // 返回要写的这条数据的key @Override public String getKeyFromData(WaterSensor waterSensor) { return waterSensor.getId(); } @Override public String getValueFromData(WaterSensor waterSensor) { return JSON.toJSONString(waterSensor); } })); environment.execute(); } }
9)Redis查看是否收到数据(List)
redis-cli --raw
10)清空数据库
flushall
11)Sink到Redis的示例代码(Set)
package com.yuange.flink.day03; import com.alibaba.fastjson.JSON; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.redis.RedisSink; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisConfigBase; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/18 0:33 */ public class Flink_Sink_Redis_Set { public static void main(String[] args) throws Exception { ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); waterSensors.add(new WaterSensor("传感器", 1607527995000L, 30)); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); FlinkJedisConfigBase conf = new FlinkJedisPoolConfig.Builder() .setHost("hadoop162") .setPort(6379) .setDatabase(0) .setMaxTotal(100) .setMinIdle(10) .setTimeout(10 * 1000) .setMinIdle(1) .build(); environment.fromCollection(waterSensors) .keyBy(WaterSensor::getId) .max("vc") .addSink(new RedisSink<>(conf, new RedisMapper<WaterSensor>() { @Override public RedisCommandDescription getCommandDescription() { // 参数1: 根据要写的数据类型, 选择对应的命令 // 参数2: 只针对hash和zset有效, 其他的数据结构忽略 return new RedisCommandDescription(RedisCommand.SADD,null); } // 返回要写的这条数据的key @Override public String getKeyFromData(WaterSensor waterSensor) { return waterSensor.getId(); } @Override public String getValueFromData(WaterSensor waterSensor) { return JSON.toJSONString(waterSensor); } })); environment.execute(); } }
12)Redis查看是否收到数据(Set)
redis-cli --raw

5.4.3 ElasticsearchSink
1)添加Elasticsearch Connector依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_2.12</artifactId>
<version>1.13.1</version>
</dependency>
2)启动Elasticsearch集群
es.sh start
3)Sink到Elasticsearch的示例代码
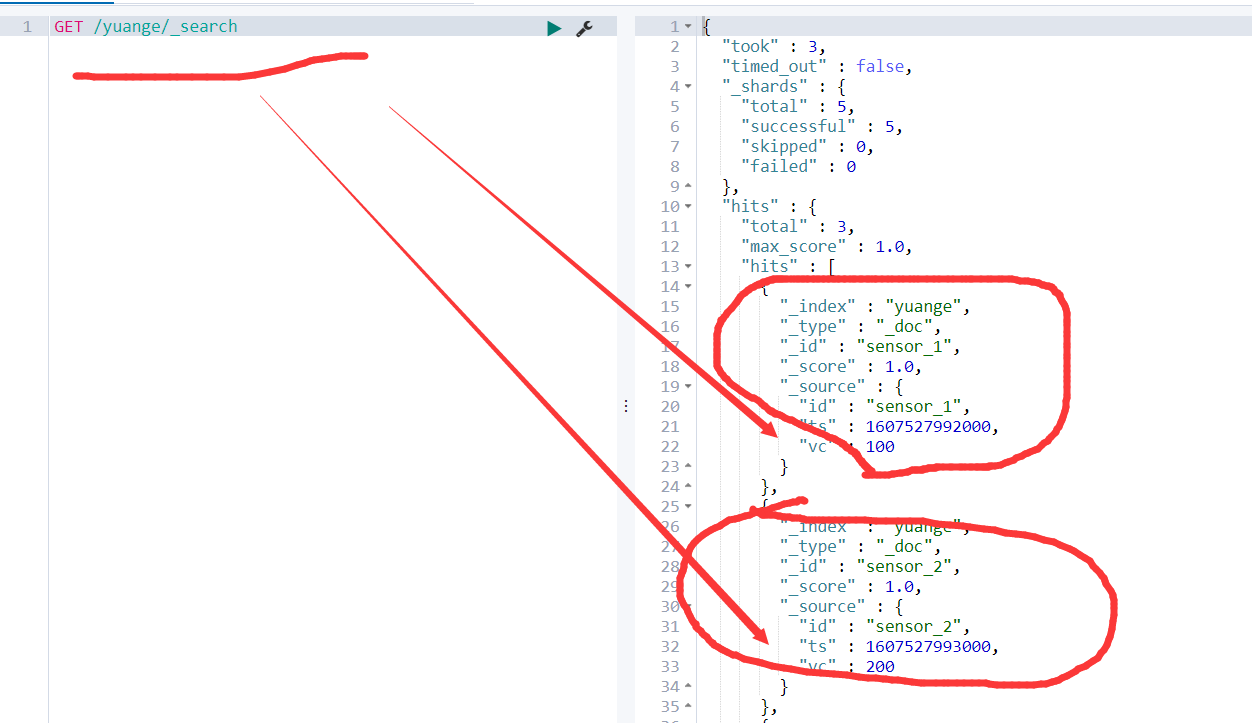
package com.yuange.flink.day03; import com.alibaba.fastjson.JSON; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.functions.RuntimeContext; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction; import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer; import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink; import org.apache.http.HttpHost; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.client.Request; import org.elasticsearch.client.Requests; import org.elasticsearch.common.xcontent.XContentType; import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/19 18:00 */ public class Flink_Sink_ES { public static void main(String[] args) throws Exception { ArrayList<WaterSensor> waterSensors = new ArrayList<>(); waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20)); waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50)); waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50)); waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10)); waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30)); waterSensors.add(new WaterSensor("传感器", 1607527995000L, 30)); StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); List<HttpHost> hosts = Arrays.asList( new HttpHost("hadoop162",9200), new HttpHost("hadoop163",9200), new HttpHost("hadoop164",9200)); executionEnvironment.fromCollection(waterSensors) .keyBy(WaterSensor::getId) .max("vc") .addSink( new ElasticsearchSink.Builder<WaterSensor>( hosts, new ElasticsearchSinkFunction<WaterSensor>() { @Override public void process(WaterSensor waterSensor, RuntimeContext runtimeContext, RequestIndexer requestIndexer) { IndexRequest source = Requests.indexRequest() .index("yuange") .type("_doc") .id(waterSensor.getId()) .source(JSON.toJSONString(waterSensor), XContentType.JSON); requestIndexer.add(source); } } ).build() ); executionEnvironment.execute(); } }
4)Elasticsearch查看是否收到数据
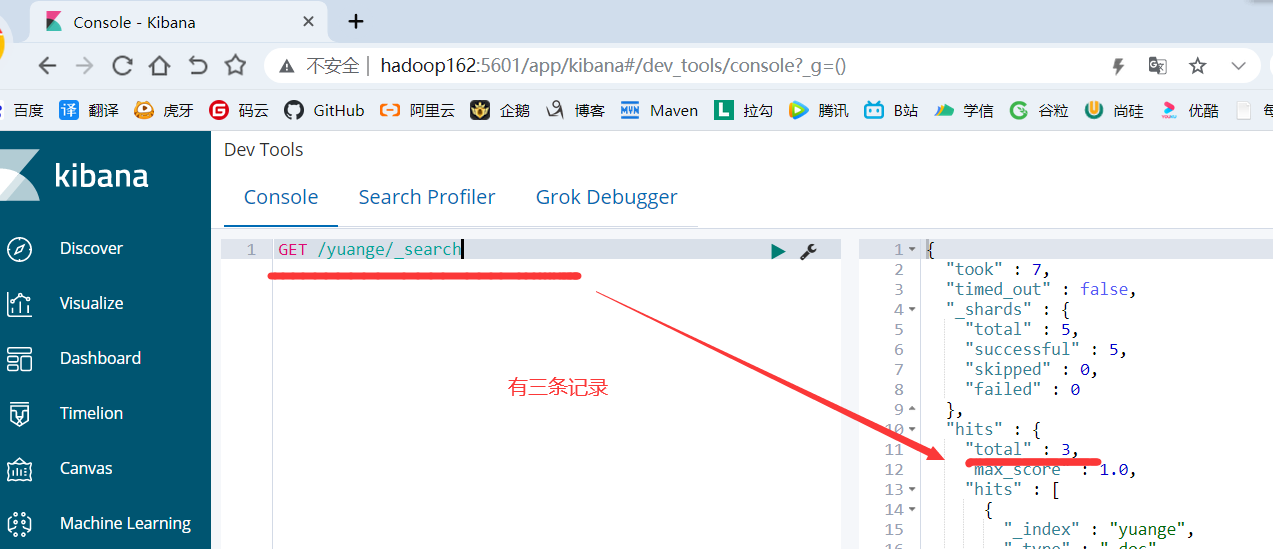
5)如果出现如下错误:

<!-- 添加log4j2的依赖 --> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.14.0</version> </dependency>
6)如果是无界流, 需要配置bulk的缓存,代码如下:
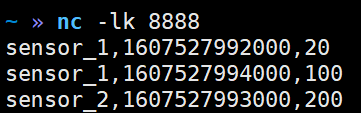
package com.yuange.flink.day03; import com.alibaba.fastjson.JSON; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.functions.RuntimeContext; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction; import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer; import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink; import org.apache.http.HttpHost; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.client.Requests; import org.elasticsearch.common.xcontent.XContentType; import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/19 18:00 */ public class Flink_Sink_ES_Unbouded { public static void main(String[] args) throws Exception { StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); List<HttpHost> hosts = Arrays.asList( new HttpHost("hadoop162",9200), new HttpHost("hadoop163",9200), new HttpHost("hadoop164",9200)); ElasticsearchSink.Builder<WaterSensor> esBuilder = new ElasticsearchSink.Builder<>( hosts, new ElasticsearchSinkFunction<WaterSensor>() { @Override public void process(WaterSensor waterSensor, RuntimeContext runtimeContext, RequestIndexer requestIndexer) { IndexRequest source = Requests.indexRequest() .index("yuange") .type("_doc") .id(waterSensor.getId()) .source(JSON.toJSONString(waterSensor), XContentType.JSON); requestIndexer.add(source); } } ); //设置批量刷新间隔,以毫秒为单位。你可以通过 -1 来禁用它 esBuilder.setBulkFlushInterval(1000); //为每个批量请求设置要缓冲的最大操作数。您可以将 -1 传递给 * 禁用它 esBuilder.setBulkFlushMaxActions(1); //sensor_1,1607527992000,20 //sensor_1,1607527994000,100 //sensor_2,1607527993000,200 executionEnvironment.socketTextStream("hadoop164",8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); }) .keyBy(WaterSensor::getId) .max("vc") .addSink(esBuilder.build()); executionEnvironment.execute(); } }
7)启动hadoop164的8888端口
nc -lk 8888
8)查看结果
5.4.4 自定义Sink
如果Flink没有提供给我们可以直接使用的连接器,那我们如果想将数据存储到我们自己的存储设备中,怎么办?我们自定义一个到Mysql的Sink
1)在mysql中创建数据库和表
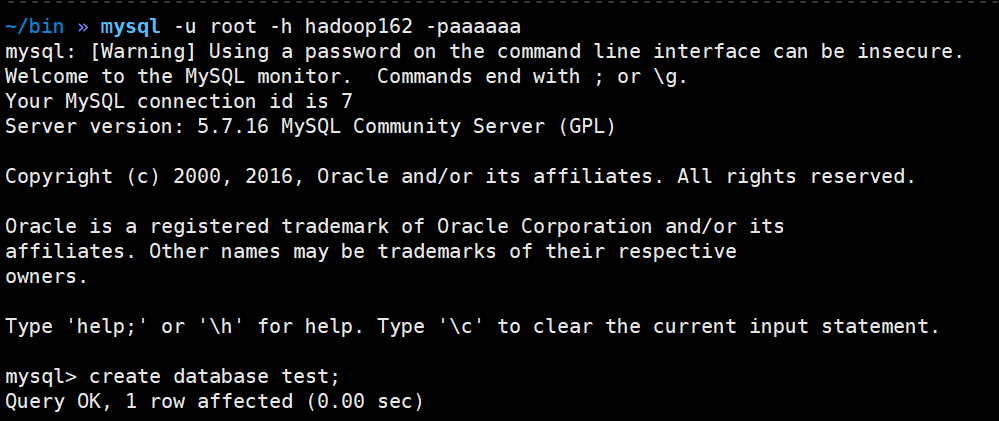

create database test; use test; CREATE TABLE `sensor` ( `id` varchar(20) NOT NULL, `ts` bigint(20) NOT NULL, `vc` int(11) NOT NULL, PRIMARY KEY (`id`,`ts`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2)导入Mysql驱动
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.49</version> </dependency>
3)写到Mysql的自定义Sink示例代码
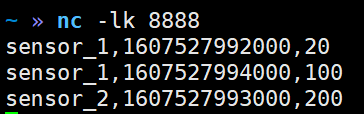
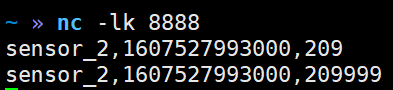
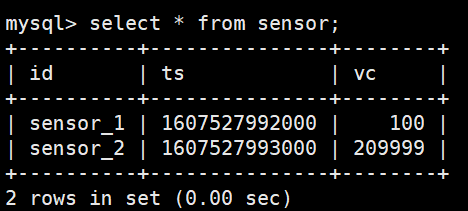
package com.yuange.flink.day03; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.RichSinkFunction; import java.sql.Connection; import java.sql.Driver; import java.sql.DriverManager; import java.sql.PreparedStatement; /** * @作者:袁哥 * @时间:2021/7/19 18:44 */ public class Flink_Sink_Custom_Mysql { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); environment.socketTextStream("hadoop164",8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); }) .keyBy(WaterSensor::getId) .max("vc") .addSink(new MysqlSink()); environment.execute(); } public static class MysqlSink extends RichSinkFunction<WaterSensor> { Connection connection; PreparedStatement preparedStatement; @Override public void open(Configuration parameters) throws Exception { // 建立到Mysql的连接 //加载驱动 Class.forName("com.mysql.jdbc.Driver"); //获取连接对象 connection = DriverManager.getConnection("jdbc:mysql://hadoop162:3306/test", "root", "aaaaaa"); //预处理 String sql = "replace into sensor values(?,?,?)"; preparedStatement = connection.prepareStatement(sql); } @Override public void close() throws Exception { // 关闭到Mysql的连接 if (preparedStatement != null) { preparedStatement.close(); } if (connection != null) { connection.close(); } } @Override public void invoke(WaterSensor value, Context context) throws Exception { preparedStatement.setString(1,value.getId()); preparedStatement.setLong(2,value.getTs()); preparedStatement.setInt(3,value.getVc()); preparedStatement.execute(); } } }
4)启动hadoop164的8888端口
nc -lk 8888
5)查看结果
6)JDBC模式代码
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-jdbc_2.12</artifactId> <version>1.13.1</version> </dependency>
package com.yuange.flink.day03; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.connector.jdbc.JdbcConnectionOptions; import org.apache.flink.connector.jdbc.JdbcExecutionOptions; import org.apache.flink.connector.jdbc.JdbcSink; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/19 19:00 */ public class Flink_Sink_JDBC { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.socketTextStream("hadoop164",8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); }) .keyBy(WaterSensor::getId) .max("vc") .addSink(JdbcSink.sink( "replace into sensor values(?,?,?)", (ps,ws) ->{ ps.setString(1, ws.getId()); ps.setLong(2, ws.getTs()); ps.setInt(3, ws.getVc()); }, JdbcExecutionOptions.builder() .withBatchSize(1000) .withBatchIntervalMs(200) .withMaxRetries(5) .build(), new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withUrl("jdbc:mysql://hadoop162:3306/test") .withDriverName("com.mysql.jdbc.Driver") .withUsername("root") .withPassword("aaaaaa") .build() )); environment.execute(); } }
7)结果
5.5 执行模式(Execution Mode)
Flink从1.12.0上对流式API新增一项特性:可以根据你的使用情况和Job的特点, 可以选择不同的运行时执行模式(runtime execution modes).
流式API的传统执行模式我们称之为STREAMING 执行模式, 这种模式一般用于无界流, 需要持续的在线处理
1.12.0新增了一个BATCH执行模式, 这种执行模式在执行方式上类似于MapReduce框架. 这种执行模式一般用于有界数据.
默认是使用的STREAMING 执行模式
5.5.1 选择执行模式
BATCH执行模式仅仅用于有界数据, 而STREAMING 执行模式可以用在有界数据和无界数据.
一个公用的规则就是: 当你处理的数据是有界的就应该使用BATCH执行模式, 因为它更加高效. 当你的数据是无界的, 则必须使用STREAMING 执行模式, 因为只有这种模式才能处理持续的数据流.
5.5.2 配置BATH执行模式
执行模式有3个选择可配:
1)STREAMING(默认)
2)BATCH
3)AUTOMATIC
(1)通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH ...
(2)通过代码配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
建议: 不要在运行时配置(代码中配置), 而是使用命令行配置, 引用这样会灵活: 同一个应用即可以用于无界数据也可以用于有界数据
5.5.3 有界数据用STREAMING和BATCH的区别
STREAMING模式下, 数据是来一条输出一次结果.
BATCH模式下, 数据处理完之后, 一次性输出结果.
下面展示WordCount的程序读取文件内容的不同执行模式下:
1)流式模式
// 默认流式模式, 可以不用配置 env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
2)批处理模式
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
3)自动模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);