1. 检查robots.txt
大多数网站都会定义一robots.txt文件,这样可以了解爬取该网站时存在哪些限制,在爬取之前检查robots.txt文件这一宝贵资源可以最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索。
输入http://example.webscraping.com/robots.txt 我们会看到以下内容:
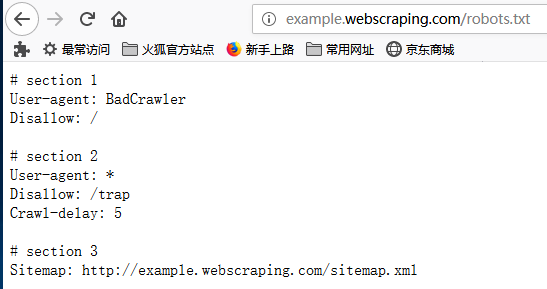
section1:禁止用户代理为BadCrawler的爬虫爬取网站
section2:规定无论使用任何的代理,都应该在两次下载请求之间给出5秒的抓取延时,我们应该遵从该建议避免服务器过载,Disllow:/trap表示禁止爬取/trap链接,如果访问的画,服务器将会封你的ip
section3: 告诉了我们一个网址,该网址内容可以帮助我们定位网站的最新内容
2. 检查网站地图
从robots.txt内容可以看到,网站为我们提供了Sitemap网址,该网址可以帮助我们定位网站最新的内容,而无须爬取每一个网页,关于网站地图标准协议可以查看https://www.sitemaps.org/protocol.html,打开sitemap看看
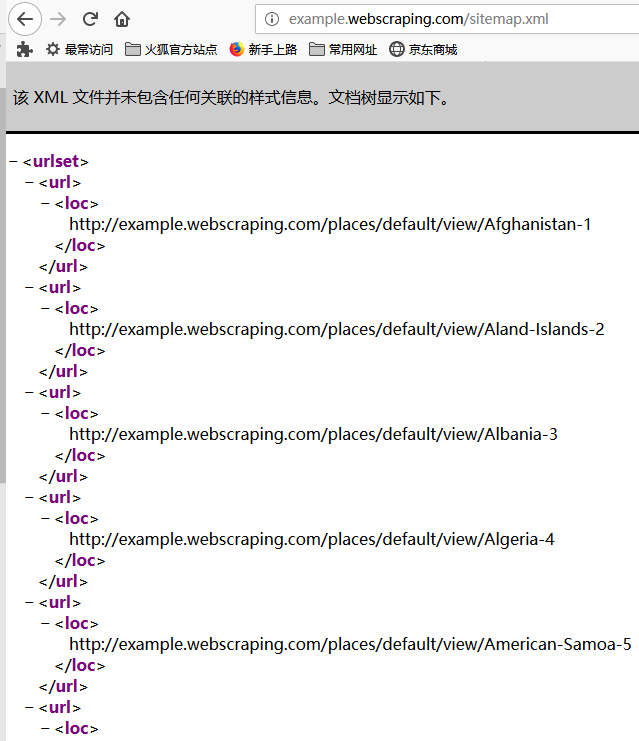
发现该网站地图提供了所有网页链接,虽然网站地图文件提供了一种爬取网站的有效方式,但是我们仍需对其谨慎处理,因为该文件经常存在缺失、过期或不完整的问题
3. 估算网站大小
目标网站的大小会影响我们如何进行爬取,如果网页的数量级特别大,使用串行下载可能需要持续数月才能完成,这时就需要使用分布式下载解决了
4. 识别网站技术
import builtwith print(builtwith.parse("http://example.webscraping.com"))

5. 网站所有者
pip install python-whois
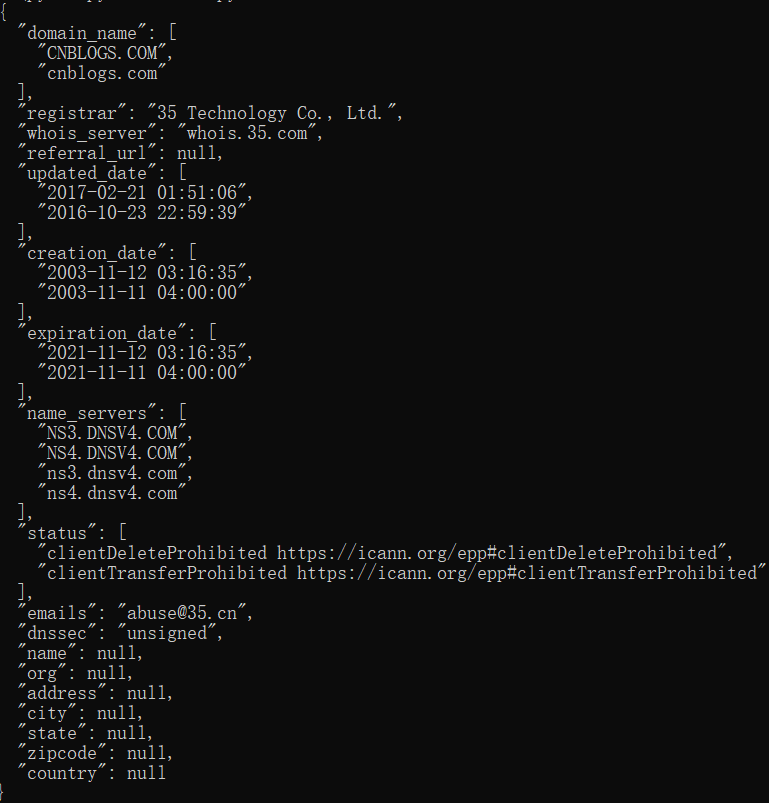
以博客园为例:
import whois print (whois.whois("https://i.cnblogs.com"))