手写数字数据集是个非常有名的用于图像识别的数据集。数字识别的过程就是将这些图片与分类结果0-9一一对应起来。我们可以直接从sklearn中加载自带的手写数字数据集:
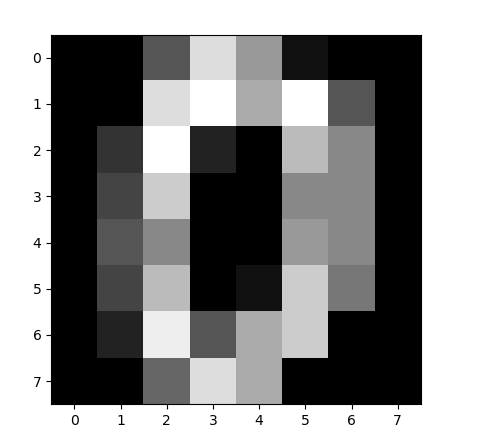
from sklearn.model_selection import train_test_split from sklearn import preprocessing from sklearn.metrics import accuracy_score from sklearn.datasets import load_digits from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.naive_bayes import MultinomialNB from sklearn.tree import DecisionTreeClassifier import matplotlib.pyplot as plt #加载数据 digits = load_digits() data = digits.data #数据探索 print('数据形式:',data.shape) #查看第一幅图像 print('查看第一幅图像:',digits.images[0]) #第一幅图像代表的数字含义 print('第一幅图像代表的数字含义:',digits.target[0]) #将第一幅图像显示出来 plt.gray() plt.imshow(digits.images[0]) plt.show() #分割数据,将25%的数据作为测试集,其余作为训练集 train_x,test_x,train_y,test_y = train_test_split(data,digits.target,test_size=0.25,random_state=33) #采用Z-Score规范化 ss = preprocessing.StandardScaler() train_ss_x = ss.fit_transform(train_x) test_ss_x = ss.transform(test_x) #创建KNN分类器 knn = KNeighborsClassifier() knn.fit(train_ss_x,train_y) predict_y = knn.predict(test_ss_x) print("KNN准确率:%.4lf"% accuracy_score(predict_y,test_y)) #创建SVM分类器 svm = SVC() svm.fit(train_ss_x,train_y) predict_y = svm.predict(test_ss_x) print('SVM准确率:%0.4lf'% accuracy_score(predict_y,test_y)) #采用Min-Max规范化 mm = preprocessing.MinMaxScaler() train_mm_x = mm.fit_transform(train_x) test_mm_x = mm.transform(test_x) #创建Naive Bayes分类器 mnb = MultinomialNB() mnb.fit(train_mm_x,train_y) predict_y = mnb.predict(test_mm_x) print("多项式朴素贝叶斯准确率:%.4lf" % accuracy_score(predict_y,test_y)) #创建CART决策树分类器 dtc = DecisionTreeClassifier() dtc.fit(train_mm_x,train_y) predict_y = dtc.predict(test_mm_x) print("CART决策树准确率:%.4lf"% accuracy_score(predict_y,test_y))
运行结果:
数据形式: (1797, 64) 查看第一幅图像: [[ 0. 0. 5. 13. 9. 1. 0. 0.] [ 0. 0. 13. 15. 10. 15. 5. 0.] [ 0. 3. 15. 2. 0. 11. 8. 0.] [ 0. 4. 12. 0. 0. 8. 8. 0.] [ 0. 5. 8. 0. 0. 9. 8. 0.] [ 0. 4. 11. 0. 1. 12. 7. 0.] [ 0. 2. 14. 5. 10. 12. 0. 0.] [ 0. 0. 6. 13. 10. 0. 0. 0.]] 第一幅图像代表的数字含义: 0
KNN准确率:0.9756 SVM准确率:0.9867 多项式朴素贝叶斯准确率:0.8844 CART决策树准确率:0.8533
