sql执行顺序:
(8)select (9)distinct (11)<top Num> <select list>
(1)from[ left_table]
(3)<join_type> JOIN<right_table>
(2) ON<join_condition>
(4)Where<where_condition>
(5)Group by<group_by_list>
(6)with<cube|rollup>
(7)having<having_condition>
(10)order by<order_by_list>
select语句
语法:select 列名称 from 表名称
distinct语句:
在表中,可能会包含重复值,关键字distinct用于返回唯一不同的值,就是去重
语法:select distinct 列名称 from 表名称
Top语句
top自居用于规定返回的记录的数目。注释:并非所有的数据库系统都支持top子句
语法:select top number|percent columns from table_name
例如: select top 2 * from customers :结果是返回customers表中的前两行
select top 50 percent * from customers:结果返回表格中的一半。注释:记录中有5条,那么总条数的50%,会向上取整。
Top主要用于对查询结果进行分页,这样可以减少显示的数据量,提高查询效率。后面接数字则显示指定的条数,后面接百分比则显示总体数据的百分比,一般于order by结合使用。
where语句
如需有条件的从表中选取数据,可将where子句添加到select语句;where的作用其实就是过滤数据的作用,根据where后面的条件,将需要的数据列出来,已排除那些不需要的数据。
语法:select 列名称 from 表名称 where 列 运算符 值
下面的运算符可在where子句中使用
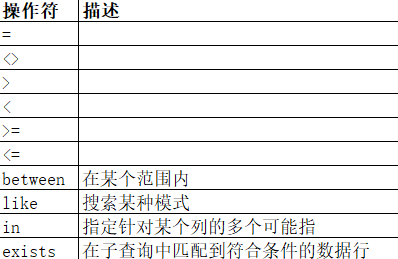
实例:
select * from customers where 城市='北京' 注意:sql使用单引号来环绕文本值,如果是数值,不需要使用引号。
and和or语句
and和or可在where子语句中把来给你个或多个条件结合起来。
实例:SELECT * FROM customers WHERE 姓名=‘张三’ AND 城市=‘上海’
我们也可以把and和or结合起来(使用圆括号来组成复杂的表达式):
实例:SELECT * FROM orders WHERE(客户id=3 or 客户id=1) AND 发货id=4
order by语句:
作用:order by关键字用于对结果集进行排序
关键字:关键字用于按升序(ASC)或降序(DESC)对结果集进行排序,默认是升序(ASC)排序记录。
order By 语法:SELECT column1,column2....FROM table_name ORDER BY column1,column2....ASC|DESC
实例:select * from customers order by 省份:按照省份排序。
注意:这里的排序规则,是按照省份里的拼音首字母的ASCII规则排序的,如果排序的首字母相同,则比较第二个字母,以此类推。
实例:select * from costomers order by 省份 DESC:降序
select * from costomers order by 省份,姓名
批注:order by 作用就是排序,常于top关键字一起使用。
group by 语句:
作用:用于结合聚合函数,根据一个或多个列对结果集进行分组。(没明白,看顶端执行顺序)
语法: select column_name,aggregate_function(column_name)
from table_name
where column_name operator value
group by column_name
实例: select 城市,count(*) as 客户数量
from customers
group by 城市
group by 将城市名称相同的客户聚集在一起,然后通过count函数计算出他们的数量。
批注:group by主要作用是用来进行分组聚合,也有时侯会用来进行排重,于distinct关键字作用类似。常用having关键字一起使用,用来对分完组后的数据进一步的筛选,属于常用关键字之一。此外还经常和结合进行一起使用。
having语句:
having子句使你能够指定过滤条件,从而控制查询结果中那些组可以出现再最终结果里面。
where子句对被选择的列施加条件,而having子句则对group by子句所产生的组施加条件。
having语法:
having子句在select查询中的位置:
select
from
where
group by
having
order by
在slect查询中,having子句必须紧随group by子句,并出现在order by子句之前,带有having子句的select语句的语法如下:
select column1,column2
from table1,table2
where [conditions]
group by column1,column2
having [conditions]
order by column1,column2
实例:
select * from customers
where 城市 in (
select 城市 from customers
group by 城市
having count(1)>1 )
注释:代码用了一个子查询,主要是因为在sql 中group by 分组后,在select后面显示的列里面只能显示分组的列,例如
select 城市,省份,from customers
group by 城市
having count(1)>1
在程序中就会报错。
所以将筛选出来符合条件的内容,通过子查询再传递给外面的主查询,主查询就可以不受group by的约束显示你想显示的内容了。
insert into 语句:
作用:用于向表中插入新纪录
语法:有两种形式
第一个表没有指定要插入数据的列的名称,只提供要插入的值
insert into table_name(column1,column2,,,,)
values(value1,value2,,,,,,)
如果要为表中的所有列添加值,则不需要再sql查询中指定列名称。但是,要确保值的顺序与表中的列顺序相同。insert into语法如下:
insert into table_name
values(value1,value2....)
实例:
insert into customers(姓名,地址)
values(‘张三’,'高老庄‘)
update语句:
作用:用于更新表中的现有记录。
语法:
update table_name
set column1 = value1,column2=value2....
where condition.
注意:更新表中的记录时要小心,update语句中where子句,where子句指定哪些记录需要更新。如果省略where子句,所有记录都将更新!
所以在进行更新操作前,最好先备份一下当前要更新的表,即创建一个临时表
实例:
update customers
set 姓名=’张三‘,城市='高老庄'
where 姓名=’张三‘
delete语句
作用:用户删除表中现有记录。
语法:delete from table_name where condition;
注意:删除表格中的记录时要小心,delete语句中的where子句,where子句指定需要删除那些记录,如果省略了where子句,表中所有记录都将被删除。
delete from customers
where 姓名=’张三‘
删除所有数据
可以删除表中的所有行,而不需要删除该表,这意味着表的结构,属性和索引将保持不变。
delete from table_name
like运算符
作用:在where子句中使用lik运算符来搜索列中的指定模式,like是针对where 后面条件列的模糊筛选。
有两个通配符于like运算符一起使用:
%:百分号表示零个,一个或多个字符
_ :下划线表示单个字符
注意: MS Access使用问好(?)而不是下划线(_)
百分号和下划线也可以组合使用!
like语法:
select column1......
from table_name
where columnN like pattern
实例:
select * from customers
where 地址 like '花%'
查找以‘花’开头的’地址‘的所有客户。
select * from customers
where 地址 like '花__%'
选择客户地址以‘花’开头且长度至少为3个字符的所有客户
in运算符
作用:允许在where子句中指定多个值。
in运算符是多个or条件的简写
语法:
select column_name(s) from table_name
where column_name in (value1.....)
或者
select column_name(s) from table_name
where column_name in (select statement)
实例:
select * from customers
where 省份 in('上海',’北京‘)
选择省份位于’上海‘,’北京‘的所有客户。
也可以
select * from costomers
where 省份 not in ('上海',’北京‘)
嵌套
select * from customers
where 城市 in(select 城市 from suppliers)
批注:in的作用就是将需要查找的内容列出来放在后面的括号里,也可以将子查询的结果放在括号内,这样in就只找符合括号里的内容,从而起到筛选的作用。另外in里面可以放多种数据类型,常见的包括日期,字符,数值等类型。
between操作符
作用:用户选取介于两个值之间的数据范围内的值。
between的边界:包括开始和结束值,等价于>= and <=
语法:
select column_name(s) from table_name
where column_nam between value1 and value2
实例:
select * from products
where 价格 between 30 and 60
not between 实例
select * from products
where 价格 not between 30 and 60
或
select * from products
where not 价格 between 30 and 60
not位置可以在列的前面或者后面,结果都是一样的。
带有in的between操作符实例
实例:
select * from products
where(价格 between 10 and 60)
and 名称 not in ('大米',‘香蕉’)
选择价格在10 到60 之间但名称不是大米和香蕉的所有产品
带有文本值的between操作符实例
select * from products
where 名称 between ‘面包’and‘香蕉’
选择所有带有名称between ‘面包’和‘香蕉’的产品
为什么会出现苹果呢?
筛选是按照名称拼音首字母的ASCII进行排序的,面包的首字母是M,香蕉的首字母是X,而苹果的首字母是P正好介于他们之间,所有被包含了。
为什么没有雪梨,雪梨的首字母也是V啊?
数据库在首字母相同时会继续比较第二个字母,如果第二个也相同依次往下比较,直到全部对比完。
实例:
select* from products
where 名称 not between '面包'and'香蕉'
日期边界问题
在sql中between and是包括边界值的,not between 不包括边界值,不过如果使用 between and 限定日期需要注意,如果and后的日期是到天的,那么默认为00:00:00 例如:and后的日期为2018年09月28日,就等价于 2018-09-28 00:00:00,那么2018-09-28 11:24:54.000的数据就查不到了,如果要查到2018-09-29这一整天的数据,那么在取值的时候要加1天。
join连接
作用:连接用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
常见的join类型: inner join 。inner join 从多个表中返回满足join条件的所用行。
实例:
select o.订单ID,c.姓名,o.订单日期 (没明白,学了as别名就知道了)
from orders o
inner join customers c
on o.客户ID=c.客户ID
不同join
inner join:如果表中有至少一个匹配,则返回行
left join:即使右表中没有匹配,也从左表返回所有行
right join:即使左表中没有匹配,也从右表返回所有的行
full join:只有其中一个表中存在匹配,则返回行
inner join :内部连接inner join 关键字选择两个表中具有匹配值的记录
语法:
select column_name(s) from table1
inner join table2 on
table1.column_name
table2.column_name
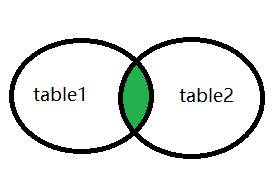 inner join 与 join是相同的
inner join 与 join是相同的
left join:
sql左连接left join 关键字返回左表(表1)中的所有行,即使在右表(表2)中没有匹配。如果在正确的表中没有匹配,结果是null.
语法:
select column_name(s)
from table1
left join table2
on table1.column_name=table2.column_name
或
select column_name(s)
from table1
left outer join table2
on table1.column_name=table2.column_name
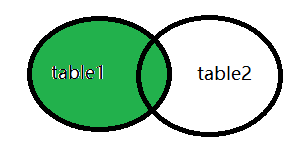 在一些数据库中,left join 称为left outer join
在一些数据库中,left join 称为left outer join
实例:
select c.姓名,o.订单id,o.订单日期
from customers c
left join orders o
on o.客户id = c.客户id
right join:和left join 的意思刚好相反
语法:
select column_name(s)from table1
right join table2 on
table2.column_name
table2.column_name
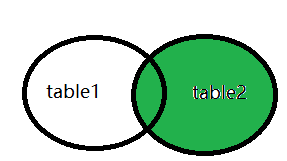 在一些数据中,right join 称为right outer join
在一些数据中,right join 称为right outer join
右连接与左连接的主表刚好相反,会将table2中的数据完全显示,如果table1中没有匹配上的就不显示。
full outer join:
当左(表1)或右(表2)表记录匹配时,full outer join关键字将返回所有记录。
注意:full outer join 可能会返回非常大的结果集。
语法:
select column_name(s) from table1
full outer join table2 on
table1.column_name
table2.column_name
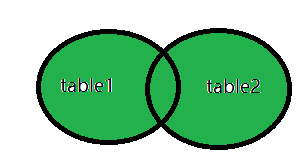 全连接就是将table1和table2的内容完全显示,不管有没有匹配上。
全连接就是将table1和table2的内容完全显示,不管有没有匹配上。
批注:join在sql中占右重要的地位,通过join我们可以将有匹配关系的两张表或更多表进行关联,来获取我们想要的数据。关联的方式也比较灵活,常用的就是inner join。
union运算符:
作用:用于组合两个或更多select语句的结果集。
使用前提:union中的每个select语句必须具有相同的列数
这些列也必须具有相似的数据类型
每个select语句中的列也必须以相同的顺序排列。
语法:
select column_name(s) from table1
union
select column_name(s)from table2
注意:默认情况下,union运算符选择一个不同的值,如果允许重复值,请使用union all
union all 语法:
select column_name(s) from table1
union all
select column_name(s)from table2
注意:union结果集中的列总是等于union中第一个select语句中的列名
实例:
select 城市 from customers
union
select 城市 from suppliers
批注:
union就是将多段功能类似的sql连接起来,并且可以去掉重复的行,有distinct的功能,union all 则只是单纯的将多端类似sql连接起来。他们的好处时可以将复杂的sql按不同的功能或作用拆分成一小段sql进行拼接,可以提高查询效率。
select into 和insert into select语句
select into 作用:从一个表中复制数据,然后将数据插入到另一个新表中。
select into语法:
把所有的列都复制到新表中
select *
into newtable[in externaldb]
from table1
后者只复制希望的列插入到新表中
select column_name(s)
into newtable[in externaldb]
from table1
提示:将使用select语句中定义的列名和类型创建新表。可以使用as子句来应用一个新名称。
实例:
select 姓名,地址
into customers1(新表)
from customers
加入条件查询
select *
into customers1(新表)
from customers
where 省份='广东省'
复制多个表中的数据插入到新表中
select c.姓名,o.订单id
into customers1
from customers c
left join orders o
on c.客户id=o.客户id
提示:select into 语句可以用于在另一种模式下创建一个新的空表,即只有表结构,没有数据。只需添加where子句,使查询返回时没有数据
select *
into newtable
from table1
where 1 =0 (where 1 = 0表示这个条件为false,不返回任何值。)
insert into select 作用:从表中复制数据,并将数据插入现有的表中。目标表中的任何现有行都不会受到影响。
insert into select语法:
可以将所有列从一个表中复制到另一个已经存在的表中
insert into table2
select * from table1
也可以把想要的列复制到另一个现有的表中。
insert into table2
(column_name(s))
select column_name(s)
from table1
实例
insert into customers(姓名,省份)
select 供应商名称,省份 from suppliers
批注:select into 用来复制表和表结构时非常方便的,特别是在进行表之间计算时,可以将部分数据先插入到一个临时表中,计算完成再删除该临时表。
insert into select 则是插入语句的另外的一种写法,可以直接将查询的结构插入到需要的表中,从而省去逐条手工插入数据的过程。
create语句
作用:可以创建数据库,表,索引等
create database语句:用于创建数据库
语法:create database detabase_name
实例:创建一个sql_road数据库
create database sql_road
create table语句:用于创建表
语法:
create table table_name(
column_name1 data_type(size)
column_name2 data_type(size)
column_name3 data_type(size)
...)
实例:
create table customers(
客户id int identity(1,1) not null,
姓名 varchar(10) null,
地址 varchar(50) null,
城市 varchar(20) null,
邮编 char(6) null,
省份 varchar(20) null)
create index语句:用于创建索引
在表上创建一个普通可以重复数据的索引
语法:
create index index_name
on table_name(column_name)
实例:
在表customers上创建一个城市列的索引
create index index_city
on cusomers(城市)
在表上创建一个唯一(数据不重复)的索引,只需添加unique关键字即可
语法:create unique index index_name
on table_name(column_name)
在表上创建一个普通的联合索引
语法: create index index_name
on table_name(column_name1,column_name2)
实例: 在表customers中创建一个城市和省份的联合索引,并对身份进行倒序排列
create index index_city_province
on customers(城市,省份 desc)
批注:create是一个数据定义语言(DLL),主要用来定义各种对象(数据库,表,索引,视图等)
alter table语句
作用:用于在已有的表中添加,修改或删除列。当我们新建一个表后,相对其进行修改,可以使用它。
语法:
若要向表中添加列“
alter table table_name
add column_name datatype
若要删除表中的列,请使用以下语法(一些数据库系统不允许这样删除数据库表中的列):
alter table table_name
drop column column_name
若要更改表中列的数据类型:
SQL Server/ Ms Access:如下
alter table table_name
alter column column_name datatype
My sql:如下
alter table table_name
modify column column_name datatype
或
alter table table_name
change column_name column_name datatype
Oracle:如下
alter table table_name
modify column_name datatype
实例:
alter table customers
add 出生日期 date;
update customers
set 出生日期=‘1990-05-14’
改变customers表中出生日期列的数据类型:
alter table customers
alter column 出生日期 datetime
drop column实例
alter table customers
drop column 出生日期
view视图
视图的定义:视图时可视化的表。
create view 语句
在sql中,视图是基于sql语句的结果集的可视化表。视图包含行和列,就像真正的表一样,视图中的字段是一个或多个数据库中真实表中的字段。可以添加sql函数,在哪里添加,并将语句连接到视图,或者可以呈现数据,就像数据来自单个表一样。
create view语法:
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
注释:视图总是显示最新数据!每当用户查询视图时,数据库引擎就使用视图的sql语句重新构建数据。
实例:
Customer_GD(广东客户列表)视图从‘customers’表中列出所有广东省的客户。这个视图使用下面的sql创建:
create view Customers_GD as
select *
from customers
where 省份=‘广东省’
可以这样查询上面的视图:
select * from Customer_GD
选取‘Products'表中所有价格高于平均价格的产品:
creave view [Products_Above_Average_Price] as
select 名称,价格
from Products
Where 价格>(select avg(价格) from Products)
可以这样查询上面的视图
select * from [Products_Above_Average_Price] #加[]防止使用到关键字报错
更新视图:添加列
create or replace view 语法:
alter view view_name as
select column_name(s)
from table_name
where condition
实例:
向’Products_Above_Average_Price‘视图添加’规格‘列。
alter view [Products_Above_Average_Price] as
select 名称,价格,规格
from Products
where 价格>(select avg(价格) from Products)
重新查询该视图:
select * from [Products_Above_Averge_Price]
删除视图 :因为视图是个虚表,里面的数据删除不了的,只能通过删除其对应的物理表数据才可以
可以通过drop view 命令来删除视图
语法:drop view view_name
批注:视图时数据库中一个比较重要的组成部分,在隔离实体表的前提下还可以让用户查询到需要的数据,可以起到保护底层数据的作用。
视图时一张虚表,表是实际存在的,视图里的内容会根据表中的数据变化而变化。
Null空值:
代表丢失的未知数据,默认情况下,表列可以保存NULL值。
NULL值:如果表中的列是可选的,那么我们可以插入一个新纪录或更新一个现有记录,而无需向列添加一个值。这意味着该字段将存储为NULL
NULL值的处理与其他值不同。
NULL为未知或不适当的占位符
注释:无法比较NULL和0,它们是不等价的
如何测试null的值?
使用is null和is not null操作符
IS NULL:
select * from Customers
where 地址 is null #查询地址列中null的值
IS NOT NULL:
select * from Customers
where 地址 IS NOT NULL #查询地址列中不是null的值
批注:NULL值在建表的时候就可以默认分配,在查询过程中不能使用比较操作符来进行筛选或查找,只能使用is null和is not null ,否则就会报语法错误。
AS别名
别名的作用:
用于为表或表中的列提供临时名称
通过用于使列名更具可读性
一个别名只存在于查询期间
使用别名的场景:
查询涉及多个表
用于查询函数
需要把两个或更多的列放在一起
列名长或可读性查
列的别名语法:
SELECT column_name AS alias_name
FROM table_name
表的别名语法:
SELECT column_name(s)
FROM table_name AS alias_name
实例:
select 客户id as customerid,
姓名 as customer
from customers
以下SQL语句创建两个别名,一个用于姓名列,一个用于城市列
注:如果别名包好空格,则需要双引号或方括号:
实例:
select 姓名 as customer,
城市 as [city name]
from Customers;
创建一个名为‘地址’的别名,它包含四列(姓名,省份,城市,地址和邮编):
select 姓名,
省份 +
城市 +
地址 +‘邮编:’ +
邮编 as 地址
from customers
结果:
姓名 地址
张三 上海市上海北京路27号,邮编:200000
注:如果我们不使用AS,上面的地址列就会显示(无列名)
注意:要使上面的sql语句在MYSql中工作,使用以下命令:
select 姓名,
concat(地址,
省份,
城市,
‘,邮编:’,
邮编
) as 地址
from customers;
注:Mysql中的字符拼接需要使用concat函数,不能直接使用+
表别名实例:
select
c.姓名 as customer,
o.订单日期 as orderdate
from customers as c
join orders as o
on c.客户id=o.客户id
注:在进行重命名时AS是可以省略的。表名重命名的,后面where,group by语句都可以用重命名的名称,因为from先执行,列名重命名的名称,where, group by 不能用,因为select后执行。
批注:AS别名在多表进行关联时可以很好的处理表名相同的情况,比如两个表都存在姓名列,可以将A表的姓名命名成A_NAME,B表姓名命名成B_NAME,这样在阅读代码时候可以一目了然。此外AS一般支队查询的列和表以及order by重命名后的别名才有效,其他地方还是需要使用原始列名。
约束(语法):
作用:约束时作用与数据表中列上的规则,用于限制表中的数据类型。约束的存在保证了数据库中数据的精准性和可靠性。
约束有列级和表集之分,列级约束作用于单一的列,而表级约束作用于整张数据表。SQL中常用的约束:
NOT NULL约束:保证列中数据不能有NULL值
default约束:提供该列数据未指定时所采用的默认值。
unique约束:保证列中的所有数据各不相同。
主键约束:唯一标识数据表中的行/记录。
外键约束:唯一 表示其他表中的一条行/记录。
check约束:此约束保证列中的所有值满足某一条件。
索引:用于在数据库中快速创建或检索数据。
约束可以在创建表时规定(通过create table语句),或者在表创建之后规定(通过alter table语句)。
创建约束:
create table table_name
(column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name
....)
删除约束
任何现有约束都可以通过在alter table命令中指定drop constraint 选项的方法删除掉
例如:要去除employees表中的主键约束,可以使用下述命令:
alter table employees drop constraint
某些数据库实现允许禁用约束,这样与某从数据库中永久删除约束,你可以只是临时禁用掉它,过一段时间后再重新启用。
完整性约束
完整性约束用于保证关系型数据库中数据的精确型和一致性。对于关系型数据库来说,数据完整性由参照完整性来保证。
有很多中约束可以起到参照完整性的作用,这些约束包括主键约束(Primary key)外键约束(foreign key)唯一型约束(unique constraint )以及上面提到的其他约束。
NOT NULL约束:
not null约束强制列不接受null值。not null约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录。
unique约束:unique约束唯一标识数据库表中的每条记录。unique和primary key 约束均为列或列集合提供了唯一性的保证。
实例:
create table customers(
客户id int not null,
姓名 varchar(10) not null,
地址 varchar(50) null,
邮编 char(6) null)
unique约束:
约束唯一标志数据库表中的每条记录。
unique和primary key约束为列或列集合提供了唯一性的保证。
primary key约束拥有自动定义的unique约束。
请注意,每个表可以有多个unique约束,但是每个表只能有一个primary key约束。
create table时的sql unique约束
mysql:
create table dbo.orders(
订单id int not null,
客户id int null,
员工id int null,
订单日期 fatetime null,
发货id int null,
unique(订单id))
sql server/orcle/ms access:
create table dbo.orders(
订单id int not null unique,
客户id int null,
员工id int null,
订单日期 datetime null,
发货id int null)
唯一约束是被约束的列在插入新数据时,如果和已经存在的列有相同的值,则会报错。
如需命名unique约束,并定义多个列的unique约束,使用以下sql语法:
MYsql/sql server/oracle/ms access:
create table dbo.orders(
订单id int not null,
客户id int null,
员工id int null,
订单日期 datetime null,
发货id int null,
constraint us_orderid unique(订单id,发货id))
alter table时的unique约束
当表已被创建时,如需在‘订单id’列创建unique约束,使用下面的sql:
Mysql/sql server/oracle/Ms Access:
alter table orders
add unique(订单id)
如需命名unique约束,并定义多个列的uniquey约束,请使用下面的sql语法:
Mysql/sql server/orcle.Ms access:
alter table customers
add constraint us_CustomerID unique(客户id,姓名)
alter table时得unique约束
当表已被创建时,如需在‘订单id’列创建unique约束,使用下面sql:
Mysql/sql server/oracle/Ms access:
alter table orders
add unique (订单id)
如需命名unique约束,并定义多个列得unique约束,使用下面sql:
Mysql/sql server/oracle/Ms Access:
ALTER TABLE customers
ADD CONSTRAINT uc_CustomersID UNIQUE(客户id,姓名)
删除unique约束
如需删除unique约束,使用下面sql:
Mysql:
alter table orders
drop index uc_orderID
Sql server/oracle/Ms Access:
ALTER TABLE Customers
DROP CONSTRAINT uc_customerID
primary key约束
primary key 约束唯一标识数据库表中的每条记录。
主键必须包含唯一的值。
主键列不能包含NULL值。
每个表都应该有一个主键,并且每个表只能有一个主键。
create table时的primary key约束
在‘customers’表创建时在‘客户id’列上创建primary key约束:
Mysql:
create table dbo.customers(
客户id int not null,
姓名 varchar(10) null,
地址 varchar(50) null,
城市 varchar(20) null,
邮编 char(6) null,
省份 varchar(20) null,
primary key (客户id)
)
Sql server/oracle/Ms Access:
create table dbo.customers(
客户id int not null primary key,
姓名 varchar(10) null,
地址 varchar(50) null,
城市 varchar(20) null,
邮编 char(6) null,
省份 varchar(20) null
)
alter table时的primary key约束
当表已被创建时,如需在‘客户’列创建primary key约束:
Mysql/sql server/oracle/ms access:
alter table customers
add primary key(客户id)
如需命名primary key约束,并定义多个列的primary key约束,使用下面的sql语法:
Mysql/sql server/oracle/ms access:
alter table customers
add constraint pk_customerID primary key(客户id,姓名)
注释:如果使用alter table语句添加主键,必须把主键列声明为不包含NULL值(在表首次创建时)。
。。。。。。。。。还有其他约束,暂时不写。。。。。。。。。
索引
什么时索引:索引是一种特殊的查询表,可以被数据库搜索引擎用来加速数据的检索。简单说来,索引就是指向表中数据的指针。数据库的索引同数据后面的索引非常相像。
例如:如果想要查阅一本书中与某个特定主题相关的所有页面,你会先去查询索引,然后从索引中找到一页或者多页与该主题相关的页面。
索引的作用:索引能够提高select查询和where子句的速度,但是却降低了包含update语句和insert语句的数据输入过程的速度。索引的创建与删除不会对表中的数据产生影响。
创建索引需要使用create index语句,该语句允许对索引命名,指定要创建索引的表以及对那些列进行索引,还可以指定索引按照升序或者降序排列。
同unique约束一样,索引可以是唯一的。这种情况下,索引会阻止列中(或者列的组合,其中某些列有索引)出现重复的条目。
create index命令
语法:create index index_name on table_name
单列索引:
单列索引基于单一的字段创建,其基础语法如下:
create index index_name on
table_name(column_name)
唯一索引
唯一索引不止用于提升查询性能,还用于保证数据完整性。唯一索引不允许向表中插入任何重复值。
语法: create unique index index_name on
table_name(column_name)
聚簇索引:
聚簇索引在表中两个或更多的列的基础上建立。
语法:create index index_name on
table_name(column1,column2)
创建单列索引还是聚簇索引,要看每次查询中,那些列在作为过滤条件where子句中最长出现。
如果只需要一列,那么就应当创建单列索引。如果作为过滤条件的where子句用到了两个或者更多的列,那么聚簇索引就是最好的选择。
隐式索引
隐式索引由数据库服务器在创建某些对象的时候自动生成。例如对于主键约束和唯一约束,数据库服务器就会自动创建索引。
删除索引
索引可以用drop命令删除。删除索引时应当特别小心,数据库的性能可能会因此而降低或者提升。
语法:drop index index_name on table_name
什么时候应当避免使用索引
尽管创建索引的目的是提升数据库的性能,但是还是有一些情况应当避免使用索引。下面几条指导原则给出了何时应当重新考虑是否使用索引:
小的数据表不应当使用索引
需要频繁进行大批量的更新或者插入操作的表
如果列中包含大数或者NULL值,不宜创建索引
频繁操作的列不宜创建索引。
批注:索引在查询优化中有很大的作用,在约束上也有一定的作用,如能熟练使用索引,对今后处理比较复杂的查询语句会大有裨益。当然也要注意什么时候该使用所以,切不可盲目的使用索引。
子查询
什么是子查询:子查询或者说内查询,也可以称作嵌套查询,是一种嵌套在其他sql查询的where子句中的查询。
子查询用于为主查询返回其所需数据,或者对检索数据进行进一步的限制。
子查询可以在select, insert, update 和 delete语句中,同=, < ,>, >= , <=,In,between等运算符一起使用。
使用子查询必须遵循以下几个规则:
子查询必须括在圆括号中
子查询的select子句中只能有一个列,除非主查寻中有多个列,用于与子查询选中的列相比较。
子查询不能使用order By,不过主查询可以。在子查询中,group by 可以起到同order by相同的作用。
返回多行数据的子查询只能同多值操作符一起使用,比如in操作符
select 列表中不能包含任何对blob,array,clob或者nclob类型值得引用
子查询不能直接用在集合函数中
between操作符不能同子查询一起使用,但是between操作符可以用在子查询中。
select子查询语句:
SELECT column_name[,column_name]
FROM table[,table2]
WHERE column_name OPERATOR
(SELECT column_name[,column_name]
FROM table1[,table2]
[WHERE])
实例:
select * from customers
where 客户id in
(select 客户id from orders
where 员工id=9)
insert子查询语句
子查询还可以用在insert语句中,insert语句可以将子查询返回得数据插入到其他表中。子查询中选取得数据可以被任何字符,日期或者数值函数所修饰。
语法:
INSERT ITNO
table_name[(column1[,column2])]
SELECT[*|column1,column2]
FROM table1[,table2]
[WHERE VALUE OPERATOR]
实例:
insert into customers_bak
select * from customers
where 客户id in
(select 客户id from orders
where 员工id=9)
update子查询语法
语法:
UPDATE table
SET column_name=new_value
[WHERE OPERATOR[VALUE]
(SELECT column_name
FROM table_name
[WHERE)]
实例:
update customers
set 城市=城市+‘市’
where 客户id in
(select 客户id from orders)
delete子查询语句
语法:
DELETE FROM table_name
[WHERE OPERATOR[VALUE]
(SELECT column_name
FROM table_name
[WHERE)]
实例:
delete from customers
where 客户id in
(select 客户id from orders)