1.1 分桶表
1.1.1 分桶表概念
分区和分桶可以同时,分桶是更细粒度的分配方式。分区是追求效率,分桶又解决什么问题呢?海量数据的分开存储。
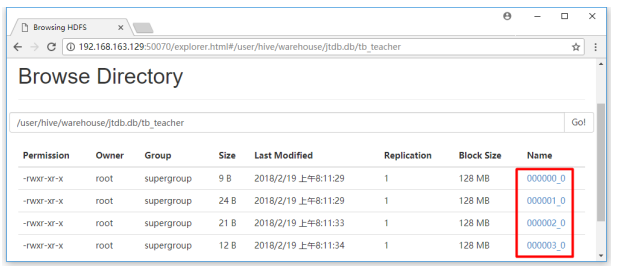
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以大大减少JOIN的数据量。
使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
1.1.2 创建分桶表
创建带桶的表:
use jtdb;
create table tb_teacher(id int,name string) clustered by (id) into 4 buckets row format delimited fields terminated by ',';
默认桶功能是关闭的
Hive的底层是MapReduce,默认Reduce就一个,就只能输出一个位置,强制多个 reduce 进行输出。
hive> set hive.enforce.bucketing=true;
teacher.txt
1,王海涛
2,花倩
3,张慎正
4,齐雷
5,刘昱江
6,陈子枢
分桶表不允许直接从外部导入数据,先创建临时表,通过临时表把数据插过去
hive> create table tb_teacher_tmp(id int,name string) row format delimited fields terminated by ',';
hive> load data local inpath '/usr/local/src/teacher.txt' into table tb_teacher_tmp;
查看数据
hive> select * from tb_teacher_tmp;
OK
1 王海涛
2 花倩
3 张慎正
4 齐雷
5 刘昱江
6 陈子枢
Time taken: 0.728 seconds, Fetched: 6 row(s)
hive>
假设我们现在的tb_teacher_tmp表的数据太多了,这时就可以用分桶。
导入数据
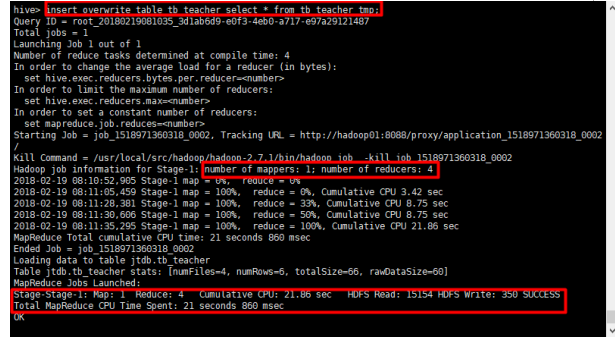
hive> insert overwrite table tb_teacher select * from tb_teacher_tmp;
注意,分桶时会产生多个reduce,时间会比较慢,稍等片刻
1.1.3 存放结构
1.1.4 数据块取样
所谓桶其实就是产生了不同的文件,tablesample为样本。
table_sample: TABLESAMPLE (BUCKET x OUT OF y [ON colname])
在colname上分桶的行随机进入1到y个桶中,返回属于桶x的行。
例如:
hive> select * from tb_teacher tablesample(bucket 1 out of 4 on id);
hive> select * from tb_teacher tablesample(bucket 1 out of 2 on id);
按百分比返回数据,返回一半数据
hive> select * from tb_teacher tablesample(50 percent);
1.2 利用hive进行数据的离线分析
1.2.1 准备环境
如果重启了服务器,需要重新启动各服务
|
|
程序 |
路径 |
启动命令 |
|
ZooKeeper |
/usr/local/src/zk /zookeeper-3.4.8/bin |
./zkServer.sh start ./zkServer.sh status |
|
|
Hadoop+HDFS |
/usr/local/src/hadoop /hadoop-2.7.1/sbin |
Start-all.sh |
|
|
Flume |
/usr/local/src/flume /apache-flume-1.6.0-bin/conf |
下面有,暂时不用启动 |
|
|
启动项目 |
必须在Flume后面启动 |
启动jtlogserver项目 |
|
|
Hive |
/usr/local/src/hive /apache-hive-1.2.0-bin/bin |
./hive |
检查防火墙状态
[root@hadoop01 ~]# firewall-cmd --state #检查防火墙状态
not running #返回值,未运行
关闭防火墙
systemctl stop firewalld.service #关闭防火墙服务
systemctl disable firewalld.service #禁止防火墙开启启动
检查进程
[root@hadoop01 bin]# jps
3034 ResourceManager #yarn
2882 SecondaryNameNode #Hadoop
4591 Application #Flume
2713 DataNode #Hadoop
5772 QuorumPeerMain #ZooKeeper
2586 NameNode #Hadoop
1.2.2 数据清洗
由于数据的来源和格式的不同和字段的缺失等等问题,在处理数据之前,对数据要进行加工处理,这个过程被称为数据的清洗。保障数据的格式统一,字段不会有明显的缺失。
先要跟业务人员沟通,基于业务处理这些数据。
数据量大就用MR进行清洗,数据量小可以用SQL,Hive进行清洗,也可以用shell脚本进行清洗。方式很多,哪种都可以,根据实际情况进行处理。
并不是所有数据都需要,可以先去除,只保留url+urlname+uvid+ssid+sscount+sstime+cip。
1.2.3 创建外部分区表
1.2.3.1 业务系统处理过程
利用外部表的方式,由浏览器访问页面从而触发埋点js,从而调用logServlet,从而写log4j日志信息到flume中,flume又直接写入到HDFS中,然后hive对指定的目录创建外部表。从而hive就获取到用户的网站流量日志信息。
1.2.3.2 修改配置文件
利用flume的拦截器在heads中添加时间戳,这样就可以获取并格式化这个时间戳%Y-%m-%d,还要注意hive指定的外部表路径一致(创建动态的路径)。
flume-jt.properties
a1.sources.r1.interceptors = t1
a1.sources.r1.interceptors.t1.type = timestamp
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop01:9000/flux/reportTime=%Y-%m-%d
注意:如果是配置的Hadoop HA,则对应flume要做调整
先要将hadoop集群的core-site.xml和hdfs-site.xml放在flume的conf目录下,然后访问时要写成hdfs://ns,ns为在hdfs-site.xml中定义的
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
修改地址为:
a1.sinks.k1.hdfs.path = hdfs://ns/flux/reportTime=%Y-%m-%d
1.2.3.3 启动flume的agent
cd /usr/local/src/flume/apache-flume-1.6.0-bin/conf
[root@hadoop01 conf]# ../bin/flume-ng agent -c ./ -f ./flume-jt.properties -n a1 -Dflume.root.logger=INFO,console &
参数说明:
-c --conf配置目录 ./当前路径
-f --config-file 配置文件
-n –name 指定agent的名称
1.2.3.4 创建外部分区表
cd /usr/local/src/hive/apache-hive-1.2.0-bin/bin
./hive #启动hive
hive> create database jtlogdb;
hive> use jtlogdb;
hive> create external table flux (url string,urlname string,title string,chset string,src string,col string,lg string, je string,ec string,fv string,cn string,ref string,uagent string,stat_uv string,stat_ss string,cip string) partitioned by (reportTime string) row format delimited fields terminated by '|' location '/flux';
1.1.1.1 访问页面a.jsp
1.2.3.5 查询数据
hive> select * from flux;
查询不到数据,因为分区信息还不能识别。
1.2.3.6 增加分区信息
hive> alter table flux add partition (reportTime='2018-03-01') location '/flux/reportTime=2018-03-01';
hive> select * from flux;
注意:Xshell会自动在最下面加信息, 执行后面命令时删除即可。
配置错误可以删除重新配置:
alter table flux drop partition(reportTime='2018-03-01');
1.2.3.7 删除HDFS重来
前面测试,会导致数据没有按照我们设定的标准,不方便查看,删除重来。
删除HDFS目录
./hdfs dfs -rm -r /fluxx/reportTime=2018-03-01
删除分区:
alter table flux drop partition (reportTime='2018-03-01');
1.2.3.8 访问页面
数据有点少
先清除IE浏览器缓存
注意:访问地址不能用localhost,前面已经介绍过,IE浏览器处理特殊localhost再次请求时不会发送参数,所以必须用IP地址或者域名。
3次a
2次b
不同的浏览器多访问几次,访问2次a.jsp,再访问1次b.jsp,把谷歌浏览器关掉(当浏览器关闭,设置ss_id会话就关闭,cookie临时文件就被删除,如果再次打开就是一个新会话),打开访问1次b.jsp,共计9条访问。
注意:Flume不是一条就立即形成一个hdfs文件,而是有一定的缓冲或者时间。所以造成FlumeData HDFS文件中数据的条数不一样。
1.1.1.1 查询数据
hive> select * from flux;
1.1.1.1 注意事项
一定要等所有数据写完,再创建外部分区表!!
这里是一个大大的坑,flume写hfds过程中,我们不能创建外部表,一旦创建flume后面写入的数据就不会出现在外部表中。就会造成hdfs的记录数和外部表中的记录数不一致。
怎么解决呢?一般每天凌晨两点时,无人访问时,我们再创建外部表;或者发现记录数不一致时,重新建立外部表。
drop table fluxx;
drop table dataclear;
1.2.4 创建数据库仓库
1.1.1.2 创建新表
hive> create table dataclear(reportTime string,url string,urlname string,uvid string,ssid string,sscount string,sstime string,cip string) row format delimited fields terminated by '|';
表名:dataclear
字段:类型就都设置为string,sscount也设置为string
row formate delimited fileds terminated by ‘|’用下划线分割数据
hive> show tables;
OK
dataclear
flux
Time taken: 0.023 seconds, Fetched: 2 row(s)
hive>
把一个字段拆分成3个字段,利用hive的内置函数split进行拆分
hive> select stat_ss from flux limit 1; #方便厕所只取一条
OK
7447647975_5_1519085238365
Time taken: 0.106 seconds, Fetched: 1 row(s)
hive> select stat_ss,split(stat_ss,"_") from flux limit 1;
OK
7447647975_5_1519085238365 ["7447647975","5","1519085238365"]
Time taken: 0.123 seconds, Fetched: 1 row(s)
hive> select stat_ss,split(stat_ss,"_"),split(stat_ss,"_")[0] from flux limit 1;
OK
7447647975_5_1519085238365 ["7447647975","5","1519085238365"] 7447647975
Time taken: 0.111 seconds, Fetched: 1 row(s)
1.1.1.3 获取数组中的数据
hive> insert overwrite table dataclear select reportTime,url,urlname,
stat_uv,split(stat_ss,"_")[0],split(stat_ss,"_")[1],split(stat_ss,"_")[2],cip from flux;
执行很慢
1.2.5 业务处理数据分析
1.2.5.1 PV
select count(*) as pv from dataclear
where reportTime='2018-03-01';
实际就是记录个数
1.2.5.2 UV
独立访客数量,一天之内所有的访问的数量,一天之内uvid去重后的总数
select count(distinct uvid) as uv from dataclear
where reportTime='2018-03-01';
不同浏览器,结果2条
1.2.5.3 VV
独立会话数,一天之内所有的会话的数量,一天之内ssid去重后的总数
select count(distinct ssid) as vv from dataclear
where reportTime='2018-03-01';
一个IE浏览器,一个chrome浏览器,结果2。如果中间可以把浏览器缓存情况,这样又是一个新的会话。MR计算时间比较长。
1.2.5.4 BR
跳出率,一天之内跳出的会话总数/会话总数,会话总数就是vv
跳出的会话总数,就是访问页面的个数,怎么计算呢?
hive中所有的子表都必须有别名。
select br_taba.a/br_tabb.b as br from
(
select count(*) as a from
(
select ssid from dataclear
where reportTime='2018-03-01'
group by ssid having count(ssid)=1
) as br_tab
) as br_taba,
(
select count(distinct ssid) as b from dataclear
where reportTime='2018-03-01'
) as br_tabb;
select br_taba.a/br_tabb.b as br from (select count(*) as a from (select ssid from dataclear where reportTime='2018-03-01' group by ssid having count(ssid)=1) as br_tab) as br_taba,(select count(distinct ssid) as b from dataclear where reportTime='2018-03-01') as br_tabb;
转成6个MR过程
保留4位小数
select round(br_taba.a/br_tabb.b,4) as br from (select count(*) as a from (select ssid from dataclear where reportTime='2018-03-01' group by ssid having count(ssid)=1) as br_tab) as br_taba,(select count(distinct ssid) as b from dataclear where reportTime='2018-03-01') as br_tabb;
分解为6个job,在不同服务器中并行计算,所以非常耗时:
1.2.5.5 NewIP
新增ip总数,一天内所有ip去重后在历史数据中从未出现过的数量
select count(distinct dataclear.cip) from dataclear
where dataclear.reportTime='2018-03-01'
and cip not in
(select dc2.cip from dataclear as dc2
where dc2.reportTime<'2018-03-01');
select count(distinct dataclear.cip) from dataclear where dataclear.reportTime='2018-03-01' and cip not in (select dc2.cip from dataclear as dc2 where dc2.reportTime<'2018-03-01');
就一个IP来访问,所以结果是1
注意:子查询中不能和主查询中有相同字段名称,这样SQL无法区分。所以对子查询表重新命名dc2,这样字段就能判断其出处。
1.2.5.6 NewCust
新增客户数,一天内所有的uvid去重在历史数据中从未出现的总数
select count(distinct dataclear.uvid) from dataclear
where dataclear.reportTime='2018-03-01'
and uvid not in
(select dc2.uvid from dataclear as dc2 where
dc2.reportTime < '2018-03-01');
select count(distinct dataclear.uvid) from dataclear where dataclear.reportTime='2018-03-01' and uvid not in (select dc2.uvid from dataclear as dc2 where dc2.reportTime < '2018-03-01');
一个IE一个chrome,结果为2
1.2.5.7 AvgTime
平均访问时长,一天内所有会话的访问时长的平均值,一个会话的时长=会话中所有访问的时间的最大值-会话中所有访问时间的最小值
select round(avg(atTab.usetime),4) as avgtime from
(
select max(sstime) - min(sstime) as usetime from dataclear
where reportTime='2018-03-01'
group by ssid
) as atTab;
select round(avg(atTab.usetime),4) as avgtime from (select max(sstime) -min(sstime) as usetime from dataclear where reportTime='2018-03-01' group by ssid) as atTab;
1.2.5.8 AvgDeep
平均访问深度,一天内所有会话访问深度的平均值,一个会话的访问深度
select round(avg(deep),2) as viewdeep from
(
select count(distinct urlname) as deep from flux
where reportTime='2018-03-01'
group by split(stat_uv,'_')[0]
) as tviewdeep;
select round(avg(deep),2) as viewdeep from (select count(distinct urlname) as deep from flux where reportTime='2018-03-01' group by split(stat_uv,'_')[0]) as tviewdeep;