ARTnet:
caffe实现:代码
1 Motivation:How to model appearance and relation (motion)
主要工作是在3D卷积的基础上,提升了action recognition的准确率,没有使用光流信息,因为光流的提取速度特别慢,这可能是未来的研究趋势,该方法更不会像IDT那套方法一样计算复杂。
实验以C3D-ResNet18实现的,只以rgb为输入,训练的时候采用了TSN的稀疏采样策略。appearance分支对每帧图片提取特征(可以看作two-stream中RGB流)。relation分支利用multiplicative interactions对多帧提取特征,用于捕获帧与帧之间的关系
ARTNet主要是由SMART blocks 通过堆叠的方法组合起来,就好像ResNet主要是由Residual blocks组合起来一样。它是一种直接输入RGB视频图像的端到端的视频理解模型。
ARTNet在Kinetics上实验的结果表明,仅通过RGB的输入,train from scratch, 能够达到RGB上state-of-the-art的性能
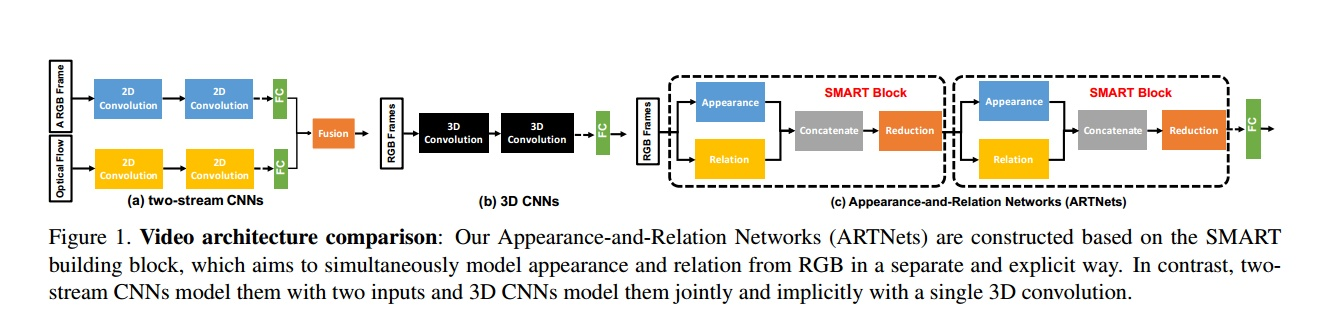
模型深挖rgb中的 appearance 和 relation 信息,smart模块对这个两个信息解耦独立建模后融合,上图可以看出,ARTnet利用了双流和c3d各自的优点。
2.1 Multiplicative interaction的数学原理
假设在连续帧上有两个patches,x和y,我们的目标是学习它们之间的变换关系z。一个常见的解决方案是将两个patches concat起来然后进行特征学习,就像3D conv一样: 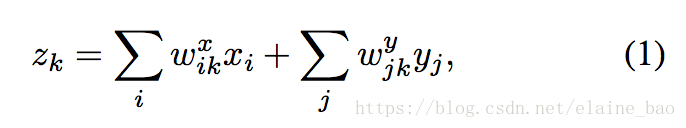
这里学到的zk就是[x,y]和参数w=[wx.k,xy.k]之间的线性组合。然而,这种情况下z的取值是依赖于patches的appearance的而不仅仅是依赖于它们之间的relation。也就是说如果两个patches改变了它们的appearance特征但是没有改变它们之间的时序关系,z的取值也是会发生变化的,因此这个解决方案将appearance和relation的信息结合起来了,这可能导致建模的困难并且增加过拟合的风险。
如双流网络中,假设appearance和relation之间是相互独立的,则可以将两者分开建模。x和y的乘积就能很容易地实现 appearance-independent relation detector,此时zk的形式如下: 
是一个x和y和weight的二次方程, 也就是x和y的外积。这样zk的每个元素都表示x和y之间的一种关系,保证了zk主要受两者relation之间的影响。
Factorization and energy models. (2)式实现起来的一个主要问题是它的参数量相当于像素个数的立方,将其因式分解成3个矩阵能够有效地减少参数量,
![]()
所以(2)式就可以写成:
这个因式分解的公式和energy model很相关,并且可以被表示成energy model的形式。具体地,在energy model中的一个隐含单元zk是通过以下公式计算的:
看出第一项和(3)式一样的,后面2项二次项不会有很大的影响,可以忽略。energy model可以通过3D CNNs实现,并且可以很容易地是一层一层地叠加。
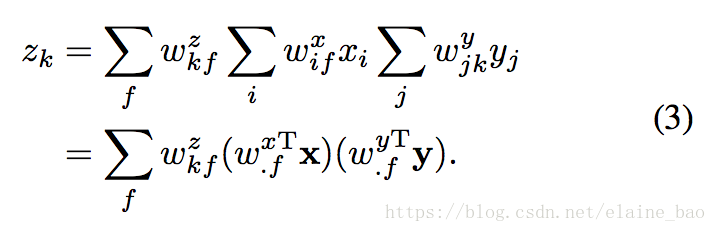
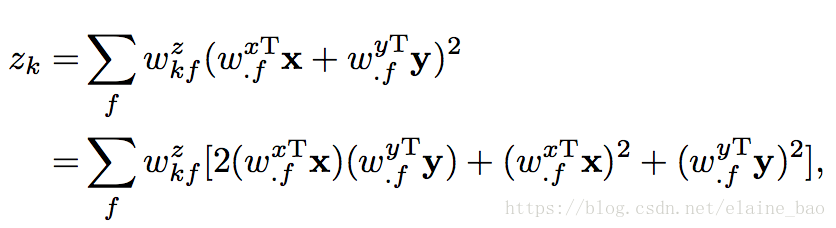
3 网络结构
本文的一大亮点是能量模型,使用了一种近似square-pooling的结构。与原结构不同之处在于三点:第一,从无监督到了有监督;第二,从仅有relation到有appearance和relation;第三,从单层到stacking多层。

appearance分支对位置结构建模,relation分支对时域关系建模
relation分支:C3D加上relation model,其中relation model用到了square-pooling,以及1*1*1的卷积实现的cross-channel-pooling,最后fusion,concat.
cross-channel pooling等于对子空间做sum操作,论文中讲子空间设为2(对应channel的feature map和其相邻的feature map加和),pooling的权重是固定的0.5
其中Z的通道数是U的一半,而U和F通道数相同。reduction layer 的输出channel和appearance的channel一致

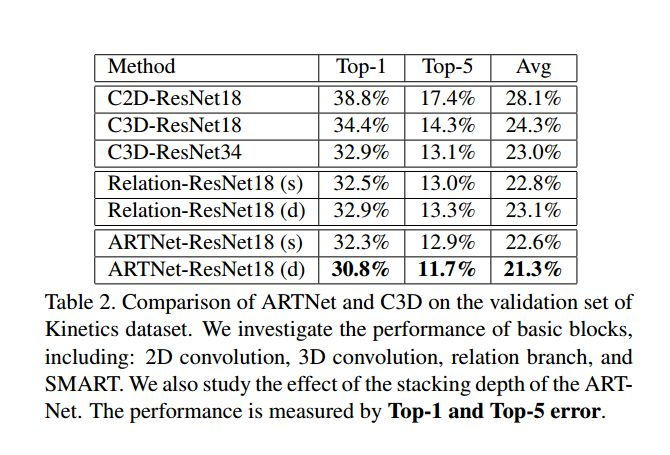
这是三种模型结构,第一种是C3D-ResNet18;第二种是ARTNet-ResNet18(s),就是只在第一层conv换成smart;第三种是ARTNet-ResNet18(d),就是每一层conv都换成smart.
实现细节
训练网络:
bactchsize=256, momentum=0.9, SGD, framed大小128*170,input size112*112*16, 初始学习率为0.1,每当val loss不下降就降10倍。在Kinetics上的总iteration为250000。为减少过拟合,在fc层前加了dropout=0.2。
测试网络:
从整个视频中采样250个clips,具体是随机采取25个128*170*16的clips, 然后10crops(5crops加上水平反转,5crops是中间加上四个角),最后取这250个的平均。
4.实验
文章大部分实验都是在kinetics完成,模型都是从kinetics上train from scratch得到
4.1数据集
(1)Kinectics (2)UCF101 (3)HMDB51
4.2 Kinectics 实验结果
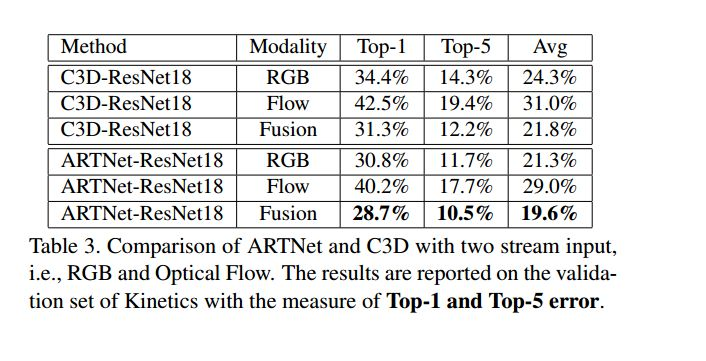
two-stream还是明显有效果的,说明SMART结构提取到的时间空间域的信息和光流还是互补的。值得一提的是ARTNet-ResNet18基于RGB的结果比C3D-ResNet18基于Fusion的结构还要好一些。

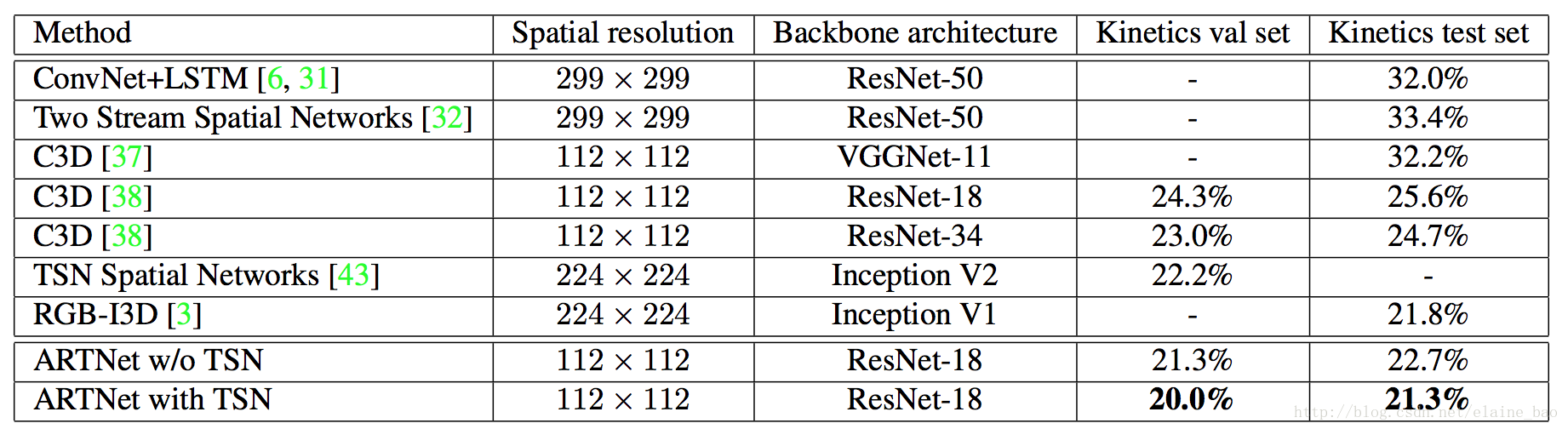
4.3 和其他state-of-the-art模型的对比
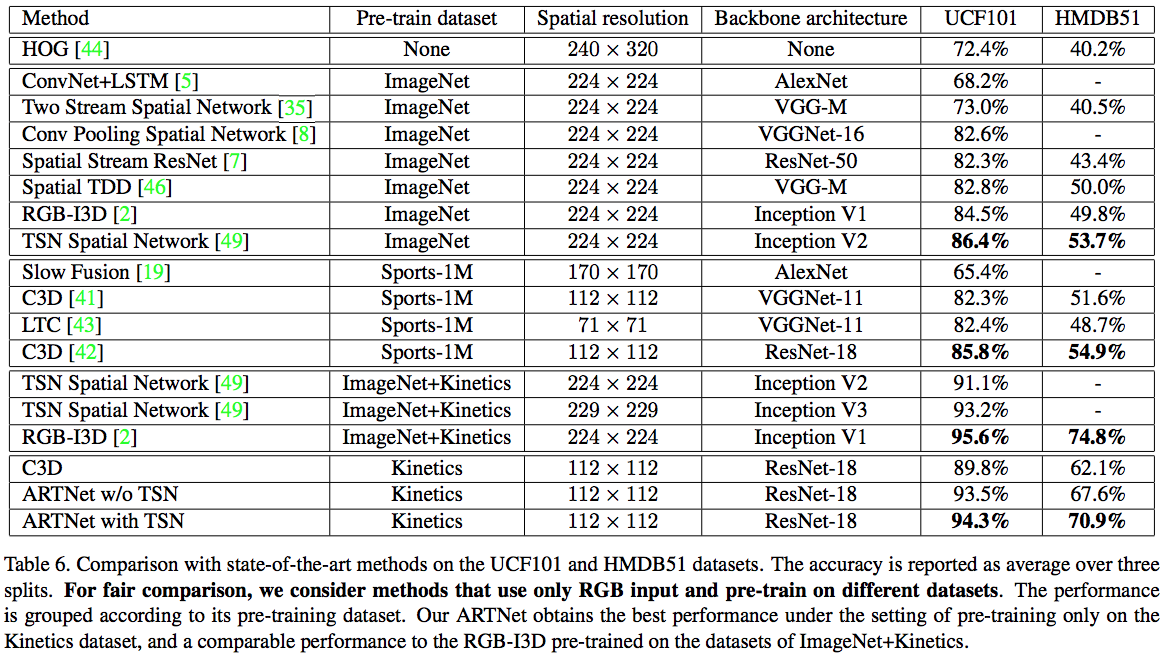
4.4 UCF101 和 HMDB51 上对比,可以看到接近RGB-I3D的结果
4.5 结论和展望
和C3D相比已经有了显著的提升,但是相比于two-stream仍然有差距,为了缩小这种差距,未来尝试更深的网络和更大的分辨率
部分转自:知乎-思考中的哈士奇
公式解读转自 Elaine-Bao