

1.基本数据类型和数组都是值传递
变量
声明一个变量
第一种,指定变量类型,声明后若不赋值,使用默认值
var name type name = value
第二种,根据值自行判定变量类型(类型推断Type inference)
如果一个变量有一个初始值,Go将自动能够使用初始值来推断该变量的类型。因此,如果变量具有初始值,则可以省略变量声明中的类型。
var name = value
第三种,省略var, 注意 :=左侧的变量不应该是已经声明过的(多个变量同时声明时,至少保证一个是新变量),否则会导致编译错误(简短声明)
name := value // 例如 var a int = 10 var b = 10 c : = 10
这种方式它只能被用在函数体内,而不可以用于全局变量的声明与赋值
多变量声明
第一种,以逗号分隔,声明与赋值分开,若不赋值,存在默认值
var name1, name2, name3 type name1, name2, name3 = v1, v2, v3
第二种,直接赋值,下面的变量类型可以是不同的类型
var name1, name2, name3 = v1, v2, v3
第三种,集合类型
var ( name1 type1 name2 type2 )
1.1 布尔型bool
布尔型的值只可以是常量 true 或者 false。一个简单的例子:var b bool = true 占用一个字节 不能 用0表示false 1表示true
1.2 数值型
1、整数型
-
int8 有符号 8 位整型 (-128 到 127) 长度:8bit 有符号 -2^7 ~ 2^7-1 一个字节8位,第一位表示符号正或负
-
int16 有符号 16 位整型 (-32768 到 32767) -2^15 ~ 2^15-1
-
int32 有符号 32 位整型 (-2147483648 到 2147483647) -2^31 ~ 2^31-1
-
int64 有符号 64 位整型 (-9223372036854775808 到 9223372036854775807) -2^63 ~ 2^63-1
-
uint8 无符号 8 位整型 (0 到 255) 8位都用于表示数值: 无符号 0 ~ 2^7-1 一个字节8位,第一位也表示数字
-
uint16 无符号 16 位整型 (0 到 65535) 0 ~ 2^16-1
-
uint32 无符号 32 位整型 (0 到 4294967295) 0 ~ 2^32-1
-
uint64 无符号 64 位整型 (0 到 18446744073709551615) 0 ~ 2^64-1
int和uint:根据底层平台,表示32或64位整数。除非需要使用特定大小的整数,否则通常应该使用int来表示整数。 大小:32位系统32位,64位系统64位。 范围:-2147483648到2147483647的32位系统和-9223372036854775808到9223372036854775807的64位系统。
数据类型转换
var i int32 = 100 var n1 float32 = float32(i)
上面只是把 i 的值转换为 float32 赋值给 n1 但 i 本身类型没有变化
int64很大的数 转换为 int8 会做溢出处理
2、浮点型
-
float32
IEEE-754 32位浮点型数
-
float64 (推荐使用)
IEEE-754 64位浮点型数
-
complex64
32 位实数和虚数
-
complex128
64 位实数和虚数
3、其他
-
byte
类似 uint8
-
rune
类似 int32
-
uint
32 或 64 位
-
int
与 uint 一样大小
-
uintptr
无符号整型,用于存放一个指针

1.3 字符串型
字符串就是一串固定长度的字符连接起来的字符序列。Go的字符串是由单个字节连接起来的。Go语言的字符串的字节使用UTF-8编码标识Unicode文本
var str string str = "Hello World"
字符串是由字节组成,单个字符可以用byte存储
单引号一个字符/汉字 是对应的 ASCII码值1.字符串类型为 string,使用双引号或者反引号包起来
2.字符串拼接 "hello" + "world" 多个链接 + 后面换行
1.4 数据类型转换:Type Convert
语法格式:Type(Value)
常数:在有需要的时候,会自动转型
变量:需要手动转型 T(V)
注意点:兼容类型可以转换
二、 复合类型(派生类型)
1、指针类型(Pointer) 2、数组类型 3、结构化类型(struct) 4、Channel 类型 5、函数类型 6、切片类型 7、接口类型(interface) 8、Map 类型
package main import ( "fmt" "unsafe" ) func main() { var n2 int64 = 10 fmt.Printf("n2 的类型:%T,n2 的占用字节数%d",n2,unsafe.Sizeof(n2)) }
结果
n2 的类型:int64,n2 的占用字节数8
常量(const)
常量是一个简单值的标识符,在程序运行时,不会被修改的量。
显式类型定义: const b string = "abc"
隐式类型定义: const b = "abc"
package main import "fmt" func main() { const LENGTH int = 10 const WIDTH int = 5 var area int const a, b, c = 1, false, "str" //多重赋值
const d = 9/3 //OK
area = LENGTH * WIDTH fmt.Printf("面积为 : %d", area) println() println(a, b, c) }
常量可以作为枚举,常量组
const ( Unknown = 0 Female = 1 Male = 2 )
常量组中如不指定类型和初始化值,则与上一行非空常量右值相同
package main import ( "fmt" ) func main() { const ( x uint16 = 16 y s = "abc" z ) fmt.Printf("%T,%v\n", y, y) //uint16,16 fmt.Printf("%T,%v\n", z, z) //string,abc }
常量的注意事项:
1)常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型
2)不曾使用的常量,在编译的时候,是不会报错的
3)显示指定类型的时候,必须确保常量左右值类型一致,需要时可做显示类型转换。这与变量就不一样了,变量是可以是不同的类型值
iota
iota,特殊常量,可以认为是一个可以被编译器修改的常量
iota 可以被用作枚举值:
const ( a = iota b = iota c = iota )
第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1;所以 a=0, b=1, c=2 可以简写为如下形式:
const ( a = iota //0 b //1 c //2 ) //新的一个则重新开始算 const ( d = iota //0 e = iota //1 f,g = iota,iota //2,2 //所以需要新的一行才会加1 )
iota 用法
package main import "fmt" func main() { const ( a = iota //0 b //1 c //2 d = "ha" //独立值,iota += 1 e //"ha" iota += 1 f = 100 //iota +=1 g //100 iota +=1 h = iota //7,恢复计数 i //8 ) fmt.Println(a,b,c,d,e,f,g,h,i) //0 1 2 ha ha 100 100 7 8 }
如果中断iota自增,则必须显式恢复。且后续自增值按行序递增
自增默认是int类型,可以自行进行显示指定类型
数字常量不会分配存储空间,无须像变量那样通过内存寻址来取值,因此无法获取地址
三、类型转换
其他类型转换为字符串类型
var num int = 99 var num1 float64 = 56.32 var b bool = true var str string str = fmt.Sprintf("%d",num) str = fmt.Sprint(num) str = strconv.Itoa(num) str = strconv.FormatInt(int64(num),10) str = strconv.FormatFloat(num1,'f',10,64) str = strconv.FormatBool(b) fmt.Printf("str type %T str=%q\n",str,str)
string类型转换为其他类型 用的 strconv包
var str string = "true" var str1 string = "12" var str2 string = "56.24" var b bool var n1 int64 var n2 int var f1 float64 b,_ = strconv.ParseBool(str) fmt.Printf("str type %T str=%v\n",b,b) n1,_= strconv.ParseInt(str1,10,64) n2 = int(n1) fmt.Printf("str type %T str=%v\n",n1,n1) fmt.Printf("str type %T str=%v\n",n2,n2) f1,_ = strconv.ParseFloat(str2,64) fmt.Printf("str type %T str=%v\n",f1,f1)
如果 一个 str ="hello" 转换为int 会转换为默认值 0 如果转换为 bool 也会是默认值 flase
值类型:
基本数据类型 int 系列, float 系列, bool, string 、数组和结构体 struct
引用类型:
指针、slice 切片、map、管道 chan、interface 等都是引用类型
四、算数运算
1. 除法整除整 取整 要得到小数部分 必须有浮点数据参与运算
fmt.Println(10 /4) //2 只会取整数部分 fmt.Println(10.0 /4) //2.5 有浮点数参加 才会有小数部分 fmt.Println(10%-3) //1 取余(取莫) 按照公式 a % b = a - a / b * b GO 只有 num++ num-- 没有 ++num --num 也不允许 a := b++ a:=b-- 只能当作一个独立的使用
不使用第三个变量来交换两个变量的值
//常规做法 var a int = 9 var b int = 5 a = a + b // 9 + 5 b = a - b // a + b - b a = a - b // a + b - a fmt.Println(a,b) //go的做法 a,b = b,a
运算符优先级

键盘输入语句:
fmt.包的 func Scan fmt.Scanln fmt.Scanf 例如 :
var x,y int fmt.Scanln(&x,&y)
其他进制转十进制
二进制 1101 = 1*2^0 + 0*2^1 + 1*2^2 + 1*2^3 = 1+0+4+8 = 13
八进制 1111 = 1*8^0 + 1*8^1+1*8^2 + 1*8^3 = 1+8+64+512 = 585
十六进制 0x111 = 1*16^0 + 1*16^1+1*16^2 = 1+16+256 = 273
十进制转其他进制
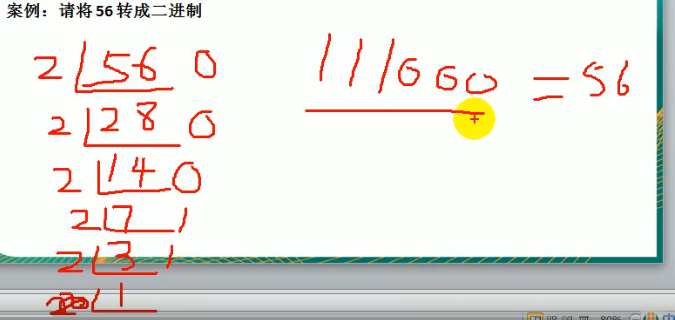
十进制转二进制 规则:将该数不断除以2,直到商为0为止,然后将每步得到的余数倒过来,就是对应的二进制
转二进制 56
十进制转八进制 规则:将该数不断除以8,直到商为0为止,然后将每步得到的余数倒过来,就是对应的二进制

十进制转十六进制 规则:将该数不断除以16,直到商为0为止,然后将每步得到的余数倒过来,就是对应的二进制
二进制转八进制 规则:将二进制数每三位一组(从低位开始组合),转换对应的八进制数即可 11 010 101 = 0325
二进制转十六进制 规则:将二进制数每四位一组(从低位开始组合),转换对应的十六进制数即可 1101 0101 = 0xD5
八进制转二进制 规则:将八进制数每一位,转换成对应的一个3位的二进制即可 0237 = 10011111
十六进制转二进制 规则:将十六进制数每一位,转换成对应的一个4位的二进制即可 0237 = 1000110111


原码、反码、补码
网上对源码,反码,补码的解释过于复杂,我这里精简6局话:
对于有符号的而言:
1)二进制的最高位是符号位:0表示整数,1表示负数
1====>[0000 0001] -1====>[1000 0001]
2)正数的源码,反码,补码都一样
3)负数的反码 = 它的原码符号位不变,其他位取反(0->1 1->0)
1===>原码[0000 0001] 反码[0000 0001] 补码[0000 0001]
-1===>原码[1000 0001] 反码[1111 1110] 补码[1111 1111]
4)负数的补码 = 他的反码+1
5)0的反码 补码都是0
6)在计算机运算的时候,都是以补码的方式来运算的
1+1 1-1 = 1+(-1)


一.switch分支结构
switch 细节讨论
1) case后是一个表达式(即:常量值、变量、一个有返回值的函数等都可以)
2) case后的各个表达式的值的数据类型,必须和switch的表达式数据类型一致
3) case后面可以带多个表达式,使用逗号间隔.比如case 表达式1,表达式2 ...
4) case后面的表达式如果是常量值(字面量),则要求不能重复
5) case后面不需要带brear,程序匹配到一个case后就会执行对应的代码块,然后退出switch,如果一个都匹配不到,则执行default
6) default语句不是必须的
7) switch后也可以不带表达式,类似多个if--else分支来使用
8) switch后也可以直接声明/定义一个变量,分号结束,不推荐
9) switch 穿透-fallthrough,如果在case语句块后增加fallthrough,则会继续执行下一个case,也叫switch穿透
10) Type Switch: switch语句还可以被用于type-switch来判断某个 interface 变量中实际指向的变量类型
var score int = 30 switch { case score >90 : fmt.Println("成绩及格...") case score >70: fmt.Println("成绩优良...") case score >60 && score<70: fmt.Println("成绩及格...") default: fmt.Println("成绩不及格") }
//编写一个函数,可以判断输入的参数是什么类型 type Student struct { } //编写一个函数,可以判断输入的参数是什么类型 func TypeJudge(items... interface{}) { for index,v :=range items{ index++ switch v.(type) { case bool: fmt.Printf("第%v个参数是 bool 类型,值是%v\n",index,v) case int32: fmt.Printf("第%v个参数是 int32 类型,值是%v\n",index,v) case int64: fmt.Printf("第%v个参数是 int64 类型,值是%v\n",index,v) case float32: fmt.Printf("第%v个参数是 float32 类型,值是%v\n",index,v) case float64: fmt.Printf("第%v个参数是 float64 类型,值是%v\n",index,v) case string: fmt.Printf("第%v个参数是 string 类型,值是%v\n",index,v) case Student: fmt.Printf("第%v个参数是 Student 类型,值是%v\n",index,v) case *Student: fmt.Printf("第%v个参数是 *Student 类型,值是%v\n",index,v) default: fmt.Printf("第%v个参数是 不确定 类型,值是%v\n",index,v) } } } func main() { var n1 float32 = 1.1 var n2 float64 = 5.69 var n3 bool = true var n4 int32 = 5 var n5 int64 = 9 var n6 string = "hello" stu1 :=Student{} stu2 :=&Student{} TypeJudge(n1,n2,n3,n4,n5,n6,stu1,stu2) }
二.for循环
//1.第一种 for i:=1;i<=10;i++{ fmt.Println("输出",i) } //2.第二种 j:=1 for j<=10{ fmt.Println("shuchu",j) j++ } //3.第三种 i:=1 for ; ; { //也等价于 for{ fmt.Println(i) if i>10{ break } i++ }
//遍历字符串 var str string ="hello,world" 1.第一种 for i:=0;i<len(str);i++{ fmt.Printf("%c\n",str[i]) } 2.第二种 for index,val := range str{ fmt.Printf("index=%d,val=%c\n",index,val) } //如果字符串里面有中文,遍历是取的每一个字节,汉字在utf-8里面占三个字节 var str string ="hello,world北京" str1 := []rune(str) for i:=0;i<len(str1);i++{ fmt.Printf("%c\n",str1[i]) } //这种方式比较智能,按照字符的方式遍历 有中文也是没问题的 for i,v :=range str{ fmt.Printf("index=%d,var=%c\n",i,v) }
//产生一个0-100的随机数,当这个数等于99时 退出 rand.Seed(time.Now().Unix())//随机种子 也可以用 UnixNano() 纳秒 for{ see := rand.Intn(100)+1 // [1,100)+1 fmt.Println(see) if(see==99){ break } }
//break 跳出多层循环,指定标签 lable2: for i:=1;i<4;i++{ for j:=1;j<10;j++{ if j==2{ break lable2 } fmt.Println(j) } }
//continue跳过本次循环 lable2: for i:=1;i<4;i++{ for j:=1;j<10;j++{ if j==2{ continue lable2 //跳出本次循环 } fmt.Println("i=",i,"j=",j) } } //结果 i= 1 j= 1 i= 2 j= 1 i= 3 j= 1
go build -o bin/my.exe 目录
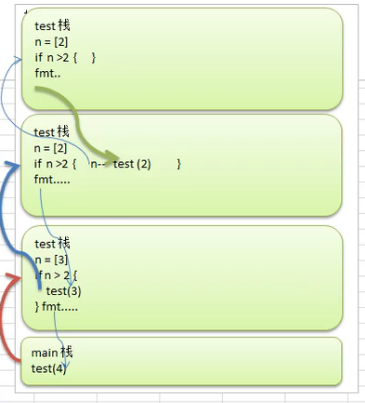
三.递归函数
package main import "fmt" func test(n int){ if n>2{ n-- test(n) } fmt.Println("n=",n) } func main() { test(4) } //结果 n = 2 n = 2 n = 3
//求出第n个斐波拉契数 func fbn(n int)int{ if n==1 || n==2{ return 1 }else { return fbn(n-1)+fbn(n-2) } } func main() { res :=fbn(10) fmt.Println(res) }
已知 f(1)=3 ;f(n) = 2*f(n-1)+1 func fbn(n int)int{ if n==1{ return 3 }else { return 2*fbn(n-1)+1 } } func main() { res :=fbn(10) fmt.Println(res) }
//一堆桃子,猴子第一天吃了其中的一半,并再多吃一个,以后每天都吃其中的一半再多吃一个,第十天想吃时,发现只一个了 问:最初共多少个桃子 1.第十天只有一个 2.第九天 (第十天的桃子+1)*2 //第九天吃完就只一个 第九天N个 n/2-1 = 第十天的桃子 那么 n= (第十天的桃子+1)*2 3.规律 第N天的桃子 peach(n) = (peach(n+1)+1)*2 func peach(n int)int{ if n>10 || n<1{ fmt.Println("输入的天数不对") return 0 } if n==10{ return 1 }else { return (peach(n+1)+1)*2 } } func main() { res :=peach(1) fmt.Println(res) //1534 }
四.函数
1.在go中,函数也是一种数据类型,可以赋值给一个变量,则该变量就是一个函数类型的变量了,通过该变量可以函数调用
2.函数既然是一种数据类型,因此在GO中,函数可以作为形参,并调用
3.为了简化数据类型定义,GO支持自定义数据类型
基本语法:type 自定义数据类型 数据类型 //理解:相当于一个别名
案例 type myInt int //这时myInt 就等价 int 来使用了 //但是 myInt 和 int 是两种不同的数据类型
案例 type mySum func(int,int)int //这时mySum就等价 一个函数类型 func(int,int)int
type myFunType func(int,int)int //定义函数类型 func getSum(n1,n2 int)int{ return n1+n2 } func myFun(funcvar myFunType,num1 int,num2 int)int { return funcvar(num1,num2) } func main() { a := getSum fmt.Printf("a的类型%T,getSum类型是%T\n",a,getSum) res :=a(10,100) fmt.Println("res= ",res) res1 := myFun(getSum,50,39) fmt.Println("res1=",res1) type myInt int var num1 myInt var num2 int num1 = 10 num2 = int(num1)//需要转换 fmt.Println(num1,num2) }
4.支持对函数返回值命名
func getSum(n1 int,n2 int)(sum int,sub int) { sum = n1+n2 sub = n1-n2 return } func main() { res,res1 := getSum(100,23) fmt.Println(res,res1) }
5.GO支持可变参数 可变参数必须放到形参的最后面
func getSum(args ...int)int { sum :=0 for i:=0;i<len(args);i++{ sum+=args[i] } return sum } func main() { res := getSum(1,2,3,4,5,6) fmt.Println(res) }
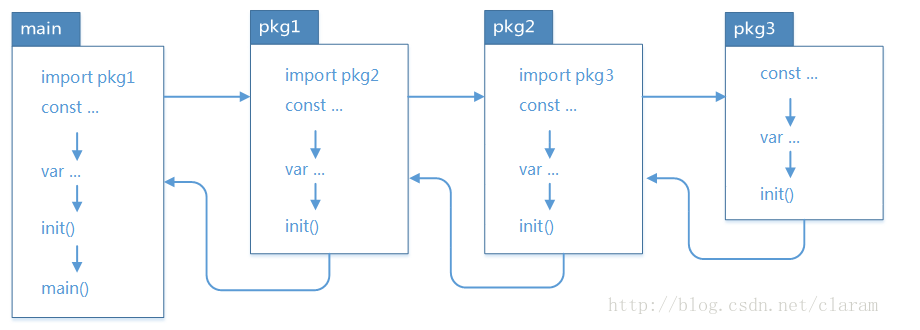
6.每一个源文件都可以包含一个init函数 该函数会在mian函数执行前,被GO运行框架调用,也就是说 init会在main函数前被调用 通常完成初始化工作
如果一个文件同时包含全局变量,init函数 main函数 ,执行的顺序 全局变量定义 》init > mian
var age = test() func test()int { fmt.Println("test()...") return 90 } func init() { fmt.Println("init()...") } func main() { fmt.Println("mian()...age=",age) } 结果: test()... init()... main()...
对于init 函数
如果 package 存在依赖,调用顺序为最后被依赖的最先被初始化,例如:导入顺序 main –> A –> B –> C,则初始化顺序为 C –> B –> A –> main,一次执行对应的 init 方法。main 包总是被最后一个初始化,因为它总是依赖别的包
五.若冥函数(闭包)
匿名函数
var( fun1 = func(n1 int,n2 int)int {//全局匿名函数 return n1*n2 } ) func main() { res := func(n1 int,n2 int)int { //匿名函数 return n1+n2 }(10,20) fmt.Println(res) a := func(n1 int,n2 int)int { //匿名函数赋值给变量 return n1 - n2 } re1 := a(10,3) fmt.Println(re1) re2 :=fun1(2,3) fmt.Println(re2) }
闭包:就是一个函数和与其相关的引用环境组合的一个整体
func addUpper() func(int)int { var n int = 10 return func(x int) int { n = n+x return n } } func main() { f := addUpper() fmt.Println(f(1)) //11 fmt.Println(f(2)) //13 fmt.Println(f(3)) //16 } //上述 n 只初始化一次,多次调用 就在累加 返回的匿名函数和 n 构成了闭包
func makeSuffix(suffix string) func(string)string { return func(name string) string { if !strings.HasSuffix(name,suffix){ //是否存在指定后缀 return name + suffix } return name } } func main() { f := makeSuffix(".jpg") fmt.Println("文件名处理后:",f("winter")) }
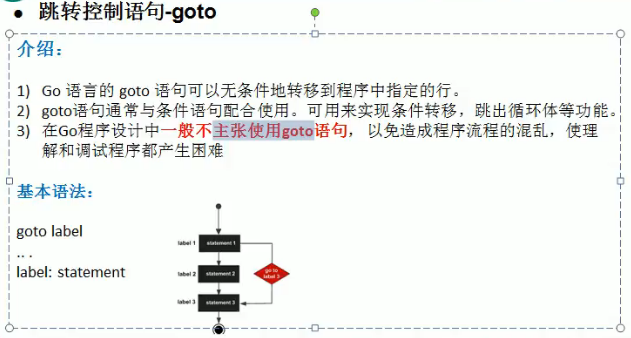
六.defer的使用 (延时机制)
压入栈,先进后出的原则,如果涉及到相关的值,也会拷贝同时入栈
func sum(n1 int,n2 int)int { defer fmt.Println("ok1 n1=",n1) //压入栈 先进后出 defer fmt.Println("ok2 n2=",n2) //压入栈 先进后出 n1++ n2++ res :=n1+n2 fmt.Println("ok3 res=",res) return res } func main() { res := sum(10,20) fmt.Println(res) } // ok3 res= 32 ok2 n2= 20 ok1 n1= 10 32
全局变量 只能用 var a int 不能用 a : = 10 相当于 var a int 和 a = 10 . a = 10 赋值必须放在函数体里面
1.查找子串是否在指定的字符串中 :strings.Contains("seafood","food") //true
2.10进制转换 2 ,8 ,16 :str = strconv.FromatInt(123,2) // 2->8->16
3.统计一个字符串有几个指定的字串: strings.Count("ceheese","e") //4
4.不区分大小写字符串比较(==是区分字母大小写的):strings.EqualFold("abc","Abc") //true
5.返回子字符串第一次出现的位置 :strings.Index("NLT_abc","abc") //4
6.返回子串在字符串最后一次出现的位置 如果没用返回-1 :strings.LastIndex("go golang","go")
7.将指定的字符串替换成,另外一个字串:strings.Replace("go go hello ","go","go 语言",n) //n 可以指定你希望替换几个,如果n=-1 表示全部替换
8.按照制度的木个字符,为分割标识,将一个字符串拆分为字符串数组 : strings.Split("hello,world,ok",",")
9.j将字符串的字母进行大小写转换 :strings.ToLower("GO")// go strings.ToUpper("go") // GO
10.将字符串左右两边的空格去掉: strings.TrimSpace(" tn a lone gopher ntm ")
11.将字符串左右两边指定的字符去掉:strings.Trim("!hello!","!") 可以去掉多个 strings.Trim("!hello!"," !") //将左右两边的空格和! 去掉
12.将字符串左边指定的字符串去掉:strings.TrimLeft("!hello!","!")
13.将字符串右边指定的字符串去掉:strings.TrimReft("!hello!","!")
14.判断字符串是否以指定的字符串开头:strings.HasPrefix("ftp://192.168.10.1","ftp")//true
15.判断字符串是否以指定的字符串结束:strings.HasSuffix("NLT_abc.jpg","abc")// false
七.时间日期函数
1.获取当前时间:time.Now() //类型 time.Time
2.获取日期
now :=time.Now() 年:now.Year() 月:int(now.Month()) 日:now.Day() 时:now.Hour() 分:now.Minute() 秒:now.Second()
3.格式化日期
now :=time.Now() //第一种 fmt.Printf("当前日期: %d-%d-%d %d:%d:%d\n",now.Year(),now.Month(),now.Day(),now.Hour(),now.Minute(),now.Second()) //当前日期: 2022-2-9 16:30:58 dateStr := fmt.Sprintf("当前日期: %d-%d-%d %d:%d:%d\n",now.Year(),now.Month(),now.Day(),now.Hour(),now.Minute(),now.Second()) fmt.Println(dateStr) //当前日期: 2022-2-9 16:32:41 //第二种 //2006/01/02 15:04:05 日期数字是固定的 fmt.Printf(now.Format("2006/01/02 15:04:05")) //2022/02/09 16:34:15
1天=24小时 = 24*60 分钟 = 24*60*60秒 = 24*60*60*1000毫秒 = 24*60*60*1000*1000 微秒 = 24*60*60*1000*1000*1000 纳秒
second 秒 Millisecond 毫秒 Microsecond 微秒 Nanosecond 纳秒 unix时间戳 unixnano 纳秒时间戳 time.Sleep(time.Second) //睡眠一秒 time.Sleep(time.Millisecond*100) // 毫秒*100 每隔0.1秒 now.Unix() //时间戳 now.UnixNano() //纳秒时间戳
//测试程序执行时间 func test(){ str := "" for i:=0;i<100000;i++ { str +="hello"+strconv.Itoa(i) } } func main() { statr := time.Now().Unix() test() end := time.Now().Unix() fmt.Printf("执行时间为:%v",end-statr) }
八.内置函数 buildin
len() 用来求长度,比如 string,arry,slice,map,channel cap() 用来求容量 比如 slice new() 用来分配内存,主要用来分配值类型,比如int,float32,struce ...返回的是指针 make() 用来分配内存的,主要用来分配引用类型,比如 chan,map,slice. num2 := new(int) fmt.Printf("num2的类型%T,num2的值=%v,num2的地址%v,num2这个指针,指向的值=%v",num2,num2,&num2,*num2) //结果 num2的类型*int,num2的值=0xc00000a0a0,num2的地址0xc000006028,num2这个指针,指向的值=0
九.错误机制
1.在默认情况下,当发生错误后(panic),程序就会退出(崩溃)
2.GO中引入的处理方式为:defer,panic,recover
3.这几个异常的使用场景可以这么简述:GO中可以抛出一个panic 的异常,然后在defer中通过recover捕获这个异常,然后正常处理
func test() { defer func() { err := recover() //recover 内置函数,可以捕获到异常 if err !=nil{ //说明捕获到错误 fmt.Println("err=",err) } }() num1 := 10 num2 := 0 res := num1/num2 //此处发生错误 引发panic fmt.Println("res=",res) } func main() { test() fmt.Println("main()下面代码继续执行") }
4.自定义错误
1.GO中也支持自定义错误,使用errors.New 和 panic内置函数
1)errors.New(”错误说明“),会返回一个error类型的值,表示一个错误
2)panic内置函数,接收一个interface{} 类型的值(空接口可以接受任何值)作为参数,可以接受error类型的变量 输出错误信息,并退出程序
func readconf(name string) error { if name=="config.ini"{ //正确的 return nil }else { //返回一个自定义错误 return errors.New("读取文件错误") } } func test() { err :=readconf("config.ini") if err !=nil{ panic(err) } fmt.Println("test()继续执行") } func main() { test() fmt.Println("main()下面代码继续执行") }
十.数组
1.数组可以存放多个同一类型的数据,数组也是一种数据类型,在GO中数组是值类型
数组的定义 var 数组名 [数组的大小]数据类型 var a [5]int 赋值 a[0] =1 a[1]=2 数组的四种定义方式 var arr1 [3]int = [3]int{1,2,3} //[1 2 3] var arr2 = [3]int{3,4,5} //[3 4 5] var arr3 = [...]int{7,8,9} //[7 8 9] var arr4 = [...]int{1:200,2:400,4:500} //[0 200 400 0 500] 1.数组的地址,也就是数组的第一个元素的地址 (数组是连续分配内存的) var arr [3]int fmt.Printf("数组的地址%p,数组的第一个地址%p",&arr,&arr[0]) //结果 数组的地址0xc000010360,数组的第一个地址0xc000010360 2.数组地址大小间隔 由数组的类型决定 int 间隔8
数组循环
var arr = [5]string{"张三","李四","王五","张二麻子","田小雨"} for i:=0; i<len(arr);i++ { fmt.Println(arr[i]) } for index , value := range arr{ fmt.Printf("下标是:%v,值是:%v\n",index,value) }
1.数组是多个相同类型数据的组合,一个数组一旦声明/定义了,其长度是固定的,不能动态变化
2.var arr []int 这时arr是一个slice切片
3.数组中的元素可以是任何数据类型,包括值类型,和引用类型 但不能混用
4.数组创建后如果没用赋值,有默认值,数值类型为0 字符串类型为”“ bool类型为 false
5.使用数组的步骤:1声明数组并开辟孔明,2 给数组各个元素赋值 3 使用数组
6.数组下标必须在指定范围内使用,否则报panic 比如 var arr [5]int 有效的下标 0-4
7.数组默认情况值传递,会进行值拷贝
8.如果想在其他函数修改数组中的值 ,可以使用引用传递(指针方式)
//生成五个随机数,将其反转 rand.Seed(time.Now().UnixNano()) var intArr [5]int var arrlen int = len(intArr) for i:=0;i<arrlen;i++{ intArr[i] = rand.Intn(100) } fmt.Println(intArr) tem :=0 for i:=0;i<arrlen/2;i++{ tem = intArr[arrlen-1-i] intArr[arrlen-1-i] = intArr[i] intArr[i] = tem } fmt.Println(intArr)
十一.切片
1.切片是数组的引用,是一个引用类型
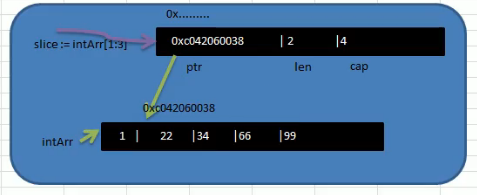
a := [5]int{76, 77, 78, 79, 80} var b []int = a[1:4] //creates a slice from a[1] to a[3] fmt.Println(b) //[77 78 79] 长度len(b) //3 容量cap(b) //4
修改切片:slice没有自己的任何数据。它只是底层数组的一个表示。对slice所做的任何修改都将反映在底层数组中。
slice 从底层来说 其实就是一个数据结构(struct 结构体)
type slice struct{ ptr *[2]int len int cap int }
切片的使用
方式1.定义一个切片,然后让切片去引用一个已经创建好的数组,比如上面的案例
var arr = [5]int{1,2,3,4,5} var slice = arr[1:] //[2 3 4 5] var slice1 = arr[:3] //[1 2 3] var slice2 = arr[:] //[1,2,3,4,5] //切片可以继续切片 var newslice = slice2[1:4] //[2 3 4]
方式2.通过make来创建切片,var 切片名 []type = make([]int,len,cap) 参数说明:type 就是数据类型 len 大小 cap 容量
var slice []int = make([]int,4,10) fmt.Println(slice) //[0 0 0 0] fmt.Println("slice len=",len(slice),"slice cap=",cap(slice)) //slice len= 4 slice cap= 10 slice[1] = 10 slice[3] = 20 fmt.Println(slice) //[0 10 0 20]
make创建的切片 操作的数组对外部不可见

方式3.定义一个切片,直接就指定具体数组,使用原理类似make的方式
var slice []string = []string{"tom","jack","mary"} fmt.Println(slice)
append 动态增加切片
var slice []int = []int{100,200,300} slice = append(slice,400,500,600) fmt.Println(slice) //[100 200 300 400 500 600] slice = append(slice,slice...) //将后面的slice的元素被打散一个个append进strss fmt.Println(slice) // [100 200 300 400 500 600 100 200 300 400 500 600
切片拷贝 copy
1.拷贝数据是相互独立的
2.必须都是切片类型
3.如果拷贝容量不够,则只会拷贝相应容量大小的
var slice []int = []int{1,2,3,4,5} var slice1 = make([]int,10) //如果此处的容量不够 则只会拷贝当前容量的值 make([]int,2) //[1 2] 会被拷贝进来 copy(slice1,slice) fmt.Println(slice) // [1 2 3 4 5] fmt.Println(slice1) // [1 2 3 4 5 0 0 0 0 0]
string 和 slice
1.string底层是一个byte数组,因此string也可以进行切片处理
str :="hello@world" slice :=str[6:] fmt.Println(slice) //world
2.string 是不可变的,也就是说不能通过 str[0] = 'z' 方式来修改字符串
3.如果需要修改字符串,可以先将string ->[]byte 或者 []rune ->修改->重写转成 string.
str :="hello@world" str1 := []byte(str) str1[0] = 'z' str = string(str1) fmt.Println(str) //如果有中文则 转换成 []rune rune按字符处理的 兼容中文 str1 := []rune(str) str1[0] = '倍' str = string(str1) fmt.Println(str) //倍ello@world
将一个斐波拉契放到一个切片
func fbn(n int)[]uint64 { fbnslice := make([]uint64,n) fbnslice[0] = 1 fbnslice[1] = 1 for i := 2;i<n;i++ { fbnslice[i] = fbnslice[i-1]+fbnslice[i-2] } return fbnslice } func main() { res :=fbn(10) fmt.Println(res) // [1 1 2 3 5 8 13 21 34 55] }
十二.排序查找
//冒泡排序 【24 69 80 57 13】 1.一共会经过arr.length-1次的轮数比较,每一轮将会确定一个数的位置 2.每一轮的比较次数在逐渐减少 3.当发现前面的一个数比后面的一个数大的时候,就进行交换 //冒泡排序 func bubbleSort(arr *[10]int) { fmt.Println("排序前的数组:",*arr) for i:=0;i<len(*arr)-1;i++{ for j:=0;j<len(*arr)-1-i;j++{ if((*arr)[j]>(*arr)[j+1]){ (*arr)[j],(*arr)[j+1] = (*arr)[j+1],(*arr)[j] } } } fmt.Println("排序后的数组:",*arr) } func main() { arr :=[10]int{3,1,4,5,6,7,8,9,10,11} bubbleSort(&arr) }
//冒泡排序优化1 假设我们现在排序ar[]={1,2,3,4,5,6,7,8,10,9}这组数据,按照上面的排序方式,第一趟排序后将10和9交换已经有序,接下来的8趟排序就是多余的,什么也没做。所以我们可以在交换的地方加一个标记,如果那一趟排序没有交换元素,说明这组数据已经有序,不用再继续下去。 func bubbleSort1(arr *[10]int) { fmt.Println("排序前的数组:",*arr) for i:=0;i<len(*arr)-1;i++{ flag := true //定义标识 for j:=0;j<len(*arr)-1-i;j++{ if((*arr)[j]>(*arr)[j+1]){ (*arr)[j],(*arr)[j+1] = (*arr)[j+1],(*arr)[j] flag = false //说明还在发生数据交换 } } if flag{ //当内循环没有发生了数据交换 说明已经排好了 break } } fmt.Println("排序后的数组:",*arr) } func main() { arr :=[10]int{1,2,3,4,5,6,7,8,10,9} bubbleSort1(&arr) }
//冒泡排序优化2 我们可以继续优化。既我们可以记下最后一次交换的位置,后边没有交换,必然是有序的,然后下一次排序从第一个比较到上次记录的位置结束即可。 func bubbleSort2(arr *[10]int) {//优化 fmt.Println("排序前的数组:",*arr) last_pos :=len(*arr)-1 //记录每一次外部循环过程中,最后进行数据交换的位置 next_pos :=len(*arr) //记录每一次数据交换的位置 for i:=0;i<len(*arr)-1;i++{ flag := true for j:=0;j<last_pos;j++{ if((*arr)[j]>(*arr)[j+1]){ (*arr)[j],(*arr)[j+1] = (*arr)[j+1],(*arr)[j] flag = false next_pos = j //交换元素,记录最后一次交换的位置 } } if flag{ break } last_pos = next_pos } fmt.Println("排序后的数组:",*arr) } func main(){ arr1 :=[10]int{1,2,5,7,4,3,6,8,9,10} bubbleSort2(&arr1) }
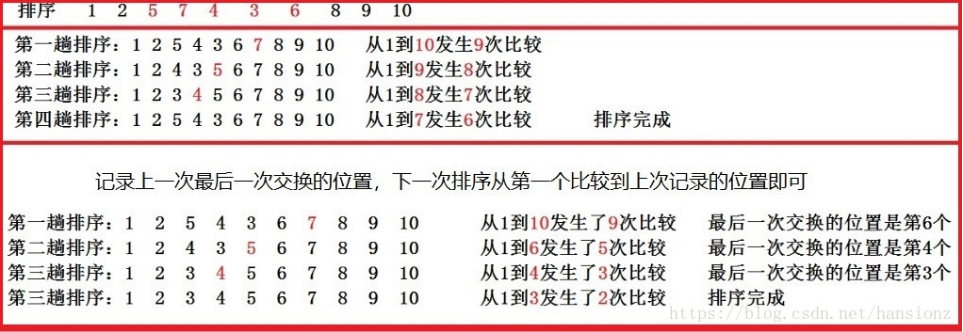
//冒泡排序优化3
优化二的效率有很大的提升,还有一种优化方法可以继续提高效率。大致思想就是一次排序可以确定两个值,正向扫描找到最大值交换到最后,反向扫描找到最小值交换到最前面。例如:排序数据1,2,3,4,5,6,0

func bubbleSort3(arr *[10]int){ fmt.Println("排序前的数组:",*arr) last_pos :=len(*arr)-1 //记录每一次外部循环过程中,最后进行数据交换的位置 next_pos :=len(*arr) //记录每一次数据交换的位置 n := 0 //同时找最大值的最小需要两个下标遍历 for i:=0;i<len(*arr)-1;i++{ flag := true //正向寻找最大值 for j:=n;j<last_pos;j++{ if((*arr)[j]>(*arr)[j+1]){ (*arr)[j],(*arr)[j+1] = (*arr)[j+1],(*arr)[j] flag = false //加入标记 next_pos = j //交换元素,记录最后一次交换的位置 } } if flag{ break } last_pos = next_pos for j:=last_pos;j>n;j--{ if (*arr)[j] < (*arr)[j - 1]{ (*arr)[j],(*arr)[j - 1] = (*arr)[j-1],(*arr)[j] flag = false //加入标记 } } n++ //n++是在之后的循环中从第n+1个数开始。比如你第一次循环找出了最大数和最小数,那么第二次循环的时候,你就只要从第2个数和第n-1个数之间去查找最大数和最小数了 if flag{ break } } fmt.Println("排序后的数组:",*arr) } func main() { arr1 :=[10]int{1,2,5,7,4,3,6,8,9,10} bubbleSort3(&arr1) }
查找
1.顺序查找
func main() { names :=[4]string{"张三","李四","王五","朱六"} var heroName = "" fmt.Println("请输入要查找的人名:") fmt.Scanln(&heroName) index :=-1 for i:=0;i<len(names);i++{ if names[i] == heroName{ index = i break } } if index!=-1{ fmt.Printf("找到%v,下标是%v\n",heroName,index) } }
二分查找 (必须有序)
func BinaryFind(arr *[10]int,leftIndex int,rightIndex int,findVal int){ if leftIndex>rightIndex{ fmt.Println("找不到") return } //先找到中间的下标 middle := (leftIndex + rightIndex) / 2 if(*arr)[middle] >findVal{ BinaryFind(arr,leftIndex,middle-1,findVal) }else if (*arr)[middle]<findVal{ BinaryFind(arr,middle+1,rightIndex,findVal) }else { fmt.Println("找到了,下标为",middle) } } func main() { arr :=[10]int{1,2,3,4,5,6,7,8,9,10} BinaryFind(&arr,0,len(arr)-1,5) }
十三.二维数组
func main() { var arr [4][6]int //arr :=[4][6]int{{1,2,3,4,5,6},{7,8,9,10,11,12},{13,14,15,16,17,18},{19,20,21,22,23,24}} arr[1][2] = 1 arr[2][1] = 2 arr[2][3] = 3 for i:=0;i<len(arr);i++{ for j:=0;j<len(arr[i]);j++{ fmt.Print(arr[i][j]," ") } fmt.Println() } } for _,v :=range arr{ for _,v1 :=range v{ fmt.Print(v1," ") } fmt.Println() }
var arr [2][3]int // var arr [...][3]int fmt.Println(arr) fmt.Printf("第一个地址:%p\n",&arr[0]) //0xc0000b6060 fmt.Printf("第二个地址:%p\n",&arr[1]) //0xc0000b6078 //这个是16进制 比第一个相差24 因为每个里面都有3个元素int(8) 3*8=24 这个二维数组 是 两个指针分别指向一个3位的一维数组

//求出三个班,每个班的五个学生的,每个班级的平均分和所有班级的平均分 func main() { rand.Seed(time.Now().UnixNano()) var scores [3][5]float64 for i:=0;i<len(scores);i++{ for j:=0;j<len(scores[i]);j++{ scores[i][j] = float64(rand.Intn(100)+1) } } totalSum := 0.0 num := 0 for i:=0;i<len(scores);i++{ sum :=0.0 for j:=0;j<len(scores[i]);j++{ sum += scores[i][j] num++ } totalSum +=sum fmt.Printf("第%v个班的总分为%v,平均分为:%v\n",i+1,sum,sum/float64(len(scores[i]))) } fmt.Printf("总分为%v,总平均分为:%.2f\n",totalSum,totalSum/float64(num)) }
十四.map
var 变量名 map[keytype][valtype] map是无序的
key 可以是 bool,数字,string ,指针,channel 还可以是只包含前面几个类型 接口,结构体,数组 通常的为 int ,string
注意:slice,map,还有function 不可以,因为这几个没办法用 == 来判断
value 通常为 整型 浮点型,string , map struct
声明不会分配内存,只有make才会分配内存
func main() { //方式一 var a map[string]string a =make(map[string]string,10) a["a"] = "张三" a["b"] = "李四" a["c"] = "王五" fmt.Println(a) //方式二 var b = make(map[string]string) b["no1"] = "天津" b["no2"] = "bejing" fmt.Println(b) //方式三 var heroes map[string]string = map[string]string{ "her01":"松江", "her02":"张飞", } fmt.Println(heroes) heroes1 := map[string]string{ "her01":"松江", "her02":"张飞", } heroes1["her03"] = "飞刀" fmt.Println(heroes) fmt.Println(heroes1) }
//存放三个学生的name和sex arr1 :=make(map[string]map[string]string) arr1["stu01"] = make(map[string]string) arr1["stu01"]["name"] = "tom" arr1["stu01"]["sex"] = "男" arr1["stu02"] = make(map[string]string) arr1["stu02"]["name"] = "tom1" arr1["stu02"]["sex"] = "男" arr1["stu03"] = make(map[string]string) arr1["stu03"]["name"] = "tom2" arr1["stu03"]["sex"] = "男" fmt.Println(len(arr1)) //获取map的长度 fmt.Println(arr1) //map的遍历一般使用for-range for key,val:=range arr1{ fmt.Println(key) for k,v :=range val{ fmt.Printf("\tk=:%v,v=:%v\n",k,v) } }
map的删除操作:delete(map,"key") delete 是一个内置函数,如果key存在,就删除该key-value, 如果不存在,不操作,也是不会报错
arr := make(map[string]string) arr["nan1"] = "张三" arr["nan2"] = "李四" //删除 delete(arr,"nan1") //直接删除 delete(arr,"nan4") //不会报错 fmt.Println(arr) //查找 val,ok :=arr["nan2"] if ok{ //true false fmt.Println("nan2存在,他的值为%v",val) } fmt.Println("没有找到nan2这个key") //遍历 for key,val:=range arr{ fmt.Printf("key=:%v,val=:%v\n",key,val) }
删除map所有key
1.遍历一下key,逐个删除 2.map=make(...),make一个新的,让原来的成为垃圾,被GC回收
map切片 :切片里面放的是map类型
切片的数据类型如果是map,则我们称为 slice of map ,map切片,这样使用则map个数就可以动态变化了
func main() { monsters :=make([]map[string]string,2) //这是一个切片,里面放的map 切片需要make if monsters[0] == nil{ monsters[0] = make(map[string]string,2) //map 也需要make monsters[0]["name"] ="小老鼠" monsters[0]["age"] = "400" } if monsters[1] == nil{ monsters[1] = make(map[string]string,2) //map 也需要make monsters[1]["name"] ="牛魔王" monsters[1]["age"] = "500" } //下面代码错误 切片长度为2 不能赋值第三个会报错 的用切片的append /*if monsters[2] == nil{ monsters[2] = make(map[string]string,2) //map 也需要make monsters[2]["name"] ="蜈蚣精" monsters[2]["age"] = "200" }*/ newMonsters := map[string]string{ //先创建一个map "name":"玉兔精", "age": "230", } monsters = append(monsters,newMonsters)//切片添加 fmt.Println(monsters) }
map是无序的,如果需要排序,可以进行key排序,再根据key输出 map排序
func main() { map1 :=make(map[int]string,10) map1[10] = "张三" map1[1] = "李四" map1[4] = "王五" map1[8] = "王二麻子" fmt.Println(map1) var keys []int for k,_ :=range map1{ keys = append(keys,k) } sort.Ints(keys) //字符串排序 sort.Strings(keys) fmt.Println(keys) for _,v :=range keys{ fmt.Printf("map[%v]=%v\n",v,map1[v]) } }
1.map是引用类型,遵守引用类型传递的机制,在一个函数接受map,修改后,会直接修改原来的map
func modify(map1 map[int]int) { map1[10] = 900 } func main() { map1 :=make(map[int]int) map1[0] = 3 map1[5] = 4 map1[10] = 10 modify(map1) fmt.Println(map1) }
2.map的容量达到后,再想map增加元素,会自动扩容,并不会发生panic,也就是说map 能动态的增长键值对
3.map的value 也经常使用struct类型,更适合管理复杂的数据(比value是一个map更好)比如value为student结构体
type stu struct { Name string Age int Address string } func main() { students :=make(map[string]stu,10) stu1 := stu{"张三",18,"北京"} stu2 := stu{"李四",30,"上海"} students["students1"] = stu1 students["students2"] = stu2 fmt.Println(students) for i,v:=range students{ fmt.Printf("学生的编号%v,学生的姓名:%v,学生的年龄:%v,学生的地址:%v\n",i,v.Name,v.Age,v.Address) } }
十五.结构体,struct
type Cat struct { Name string Age int Color string Hobby string } func main() { cat1 := Cat{"小白",18,"白色","吃鱼"} cat1.Name ="小白白" cat1.Age = 19 fmt.Printf("名称:%v,年龄:%v,颜色:%v",cat1.Name,cat1.Age,cat1.Color) }

type Person struct { Name string Age int Scores [5]float64 ptr *int slice []int map1 map[int]int } func main() { var p1 Person fmt.Println(p1) p1.slice = make([]int,10) p1.map1 = make(map[int]int) fmt.Println(p1) }
创建结构体的四种类型
type Person struct { Name string Age int } func main() { //第一种 var p1 Person p1.Name = "张三" p1.Age = 20 //第二种 p2 := Person{"李四",13} fmt.Print(p2) //第三中 var p3 *Person = new(Person) (*p3).Name = "王五" //等价与 p3.Name = "王五" (*p3).Age = 30 //等价与 p3.Age = 30 p3.Name = "和三" p3.Age = 50 //第四种 var p4 *Person = &Person{"mary",33} //等价于 var p4 = &Person{"mary",33} //类型推导 p4 := &Person{"mary",33} (*p4).Name = "李飞" //等价于 p4.Name = "李飞" p4.Age = 40 fmt.Println(p4) }
1.结构体在内存中的字段是连续的
type Point struct { x int y int } type Rect struct { leftUp,rightDown Point } type Rect2 struct { leftUp,rightDown *Point } func main() { r1 := Rect{Point{1,2},Point{3,4}} fmt.Printf("r1.leftUp.x 地址=%p r1.leftUp.y 地址=%p r1.rightDown.x 地址=%p r1.rightDown.y 地址=%p \n", &r1.leftUp.x,&r1.leftUp.y,&r1.rightDown.x,&r1.rightDown.y)//16进制每个都相差8 //r2 有两个 *Point类型,这两个*Poin类型的本身地址也是连续的, //但他们指向的地址不一定是连续的 r2 := Rect2{&Point{10,20},&Point{30,40}} fmt.Printf("r2.leftUp.x 地址=%p r2.leftUp.y 地址=%p r2.rightDown.x 地址=%p r2.rightDown.y 地址=%p \n", &r2.leftUp.x,&r2.leftUp.y,&r2.rightDown.x,&r2.rightDown.y)//16进制每个都相差8 fmt.Printf("r2.leftUp 指向地址=%p ,r2.rightDown 指向地址=%p \n",r2.leftUp,r2.rightDown) }
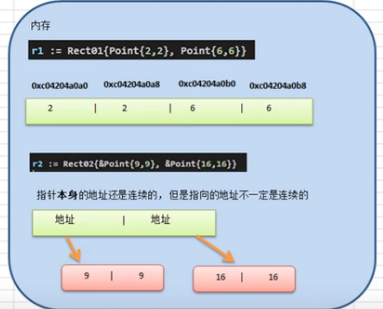
2.结构体是用户单独定义的类型,和其他类型进行转换时需要有完全相同的字段(名称,个数,类型)
3.结构体进行type重新定义(相当于取别名)golang认为是新的数据类型,但是相互间可以强转
4.struct 的每个字段上,可以写一个tag,该tag可以通过反射机制获取,常见的使用场景就是序列化和反序列化 //用户接口请求返回参数
返回结构体,结构体一般大写开头,(也不能改成小写,别的包 要用)很多不适应,我们就用tag 反射机制改成小写
type Monster struct { Name string `json:"name"` Age int `json:"age"` Skill string `json:"skill"` } func main() { moster :=Monster{"张三",46,"打人"} //将moster序列号 jsonMoster,err :=json.Marshal(moster) if err!=nil { fmt.Println("json 处理错误:",err) } fmt.Println(string(jsonMoster))//{"name":"张三","age":46,"skill":"打人"} }
十六.结构体,方法
1.方法是作用在指定的数据类型上的,和指定的数据类型绑定,因此自定义类型,都可以有方法,而不仅仅是struct
type Person struct { Name string } func (p Person) test() { p.Name = "jack" fmt.Println("test()...",a.Name) } func main() { var p Person p.Name = "tom" p.test() fmt.Println("main() p.name=",p.Name) //输出 tom 作用域不同,结构体是值类型 } //1.test方法和Person类型绑定 //2.test方法只能通过 Person类型的变量来调用,而不能直接调用,也不能通过其他类型的变量来调用 //3.func (p Person)test(){....} p表示哪个Person 变量调用
type integer int func (i integer) print() { fmt.Println("i = ",i) } func (i *integer) change(){ *i = *i + 1 } func main() { var i integer = 10 i.print() i.change() fmt.Println("i = ",i) //11 }
//求圆的面积
type Circle struct { Radius float64 } func (c Circle) area() float64 { return 3.14 * c.Radius * c.Radius } func (c *Circle) area2() float64 { c.Radius = 10 return 3.14 * c.Radius * c.Radius } func main() { var c Circle c.Radius = 4.0 res := c.area() //这里的C 传的是指针,结构体的指针 fmt.Println("面积为:",res) res2 :=c.area2() fmt.Println("面积=",res2) fmt.Println("c.radius = ",c.Radius) //10 因为是引用传递 }
如果一个类型实现了 String()这个方法,那么fmt.Println fmt.Print 默认会调用这个变量的 String()进行输出
type student struct { Name string Age int } func (stu *student) String() string { str := fmt.Sprintf("Name=[%v],Age=[%v]\n",stu.Name,stu.Age) return str } func main() { stu := student{ Name: "张三", Age: 90, } fmt.Println(&stu) }
//写一个加减乘除
type Calcuator struct { Num1 float64 Num2 float64 op byte } func (ca *Calcuator) Getnum()float64 { res :=0.0 switch ca.op { case '+': res = ca.Num1+ca.Num2 case '-': res = ca.Num1-ca.Num2 case '*': res = ca.Num1*ca.Num2 case '/': res = ca.Num1/ca.Num2 default: fmt.Println("输入的操作符有误") } return res } func main() { var mn Calcuator mn.Num1 = 3.45 mn.Num2 = 5.89 mn.op = '/' res := mn.Getnum() fmt.Printf("结果为:%.2f",res) }
//函数和方法的区别
1.调用方式不一样
函数的调用方式 :函数名(实参列表)
变量.方法名(实参列表)
2.对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然
3.对于方法(如struct 的方法),接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样可以 //因为方法底层做了处理
方法的绑定是值类型, 即使用地址调用 也是值拷贝 例如:(&p).test()
1.不管调用形式如何,真正决定是值拷贝还是地址拷贝,看这个方法是和那个类型绑定
2.如果是和值类型 比如 (p Person)则是值拷贝,如果是和指针类型,比如是(p *Person) 则是地址拷贝
type Person struct { Name string } func (p Person) test() { p.Name = "jack" fmt.Println("test() = ",p.Name) } func (p *Person) test1() { p.Name = "make" fmt.Println("test() = ",p.Name) } func main() { p := Person{Name:"tom"} p.test() //test() = jack (&p).test() //test()=jack //这里仍然是值拷贝 fmt.Println("man() p.name=",p.Name) //man() p.name= tom (p).test1()//test() = make 等价于 p.test() }
十七.工厂模式
golang的结构体没有构造函数,通常可以使用工厂模式来解决这个问题
//一个结构体的声明是这样的: package model type Student struct{ Name string } 因为这里的Student的 首字母S是大写的,如果我们想在其他包创建Student的实例(比如main包) 引入model包后,就可以直接创建Student结构体的变量(实例) 但问题来了,如果首字母是小写的,比如 type student struct{} 就不行了,怎么解决。。。。。。。工厂模式解决
正常大写情况引入包
//packgo/model/student.go package model type Student struct { Name string Score float64 } //packgo/main/mian.go package main import ( "fmt" "packago/model" ) func main() { var stu = model.Student{Name:"张三",Score:58.5} fmt.Println(stu) //{张三 58.5} }
工厂模式
//packgo/model/student.go package model type student struct { Name string score float64 } //因为student首字母s是小写,只能在model 包用 func NewStudent(n string,s float64) *student { return &student{ Name: n, score: s, } } //如果score的首字母小写 func (s *student) GetScore()float64 { return s.score } //packgo/main/mian.go package main package main import ( "fmt" "packago/model" ) func main() { var stu = model.NewStudent("tom",88.8) fmt.Println(*stu)//{tom 88.8} 因为score的首字母小写 外部包 不可访问 fmt.Println("name=",stu.Name,"score=",stu.GetScore()) //name = tom score= 88.8 }
十八.封装,继承,多重继承
1.将结构体,字段的首字母小写,其他包不能使用,类似private
2.给结构体所在包提供一个工厂模式的函数,首字母大写,类似一个构造函数
3.提供一个首字母大写的Set方法,类似其他语言的public 用于对属性判断并赋值
4.提供一个首字母大写的Get方法,类似其他语言的public 用于获取属性的值
//package\model\preson.go package model import "fmt" type person struct { Name string age int //其他包不能访问 sal float64 //其他包不能访问 } func NewPerson(name string) *person { return &person{ Name: name, } } func (p *person) SetAge(age int) { if age>0 && age <150{ p.age = age }else { fmt.Println("年龄范围不正确") } } func (p *person) GetAge()int { return p.age } func (p *person) SetSal(sal float64) { if sal>=3000 && sal<30000{ p.sal = sal }else { fmt.Println("薪水范围不正确") } } func (p *person) GetSal() float64 { return p.sal } //package\mian\mian.go package main import ( "fmt" "packago/model" ) func main() { p := model.NewPerson("smith") p.SetAge(18) p.SetSal(5000) fmt.Println(p) //&{smith 18 5000} fmt.Println(p.Name) //smith fmt.Println("age=",p.GetAge(),"sal=",p.GetSal()) //age= 18 sal= 5000 }
//继承 解决代码复用
1.当多个结构体存在相同的属性,和方法时,可以从这些结构体中抽象出结构体,在该结构体中定义这些相同的属性和方法
其他结构体不需要重新定义这些属性和方法,只需要嵌套一个匿名结构体即可,
golang中,如果一个struct嵌套了另一个匿名结构体,那么这个结构体可以直接访问匿名结构体的字段和方法,从而实现了继承的特性
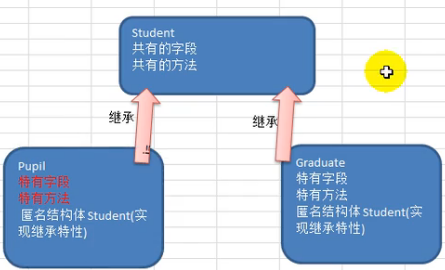
type Strudent struct { //同有特性 Name string //学生姓名 Age int //学生年龄 Score int //学生成绩 } func (stu *Strudent) ShowInfo() { //显示学生成绩 同有特性 fmt.Printf("学生姓名:%v,学生年龄:%v,学生成绩:%v\n",stu.Name,stu.Age,stu.Score) } func (stu *Strudent) SetScore(score int){//设置学生成绩 同有特性 stu.Score = score } func (stu *Strudent) GetSum(n1 int,n2 int)int { return n1+n2 } //小学生 type Pupil struct { Strudent //嵌入了匿名结构体 } func (p *Pupil) testing() { //特有的 fmt.Println("小学生正在考试.......") } //大学生 type Graduate struct { Strudent //嵌入了匿名结构体 } func (p *Graduate)testing() {//特有的 fmt.Println("大学生正在考试.......") } func main() { pupil := &Pupil{} pupil.Strudent.Name = "tom.." pupil.Strudent.Age = 8 pupil.testing() pupil.Strudent.SetScore(78) pupil.Strudent.ShowInfo() fmt.Println("小学生做加法:",pupil.Strudent.GetSum(8,5)) graduate := &Graduate{} graduate.Strudent.Name = "may.." graduate.Strudent.Age = 20 graduate.testing() graduate.Strudent.SetScore(99) graduate.Strudent.ShowInfo() fmt.Println("大学生做加法:",graduate.Strudent.GetSum(80,50)) }
1.结构体可以使用嵌套匿名结构体的所有字段和方法,即:首字母大写或者小写的字段和方法都可以使用
2.匿名结构体字段访问可以简化
3.当结构体和匿名结构体有相同的字段或者方法时,编辑器采用 就近访问原则,如希望访问匿名结构体的字段和方法,可以通过匿名结构体来区分
type A struct { Name string age int } func (a *A)SayOK() { fmt.Println("A SayOk",a.Name) } func (a *A)hello() { fmt.Println("A hello",a.Name) } type B struct { A Name string } func main() { var b B b.Name = "may" b.A.Name = "tome" b.A.age = 19 //等价于 b.age = 19 b.A.hello() //等价于 b.hello() b.A.SayOK() //等价于 b.SayOK() }
(1)当我们直接通过b 访问字段或者方法时,其执行流程如下,比如b.Name
(2)编辑器会先看b 对应的类型有没有Name,如果有,则直接调用B类型的Name字段
(3)如果没用就去看B中嵌套的结构A 有没有这个Name 字段 如果有就调用,如果没用 继续找A结构体里面的嵌套
4.结构体嵌入两个或者多个匿名结构体,如两个匿名结构体有相同的字段和方法(同事结构体本身没用同名的字段和方法)
在访问时,就必须明确指定匿名结构体名字,否则编辑报错
type A struct { Name string Age int } func (a *A)Show(){ fmt.Println("A 的Name=",a.Name,"A 的Age=",a.Age) } type B struct { Name string Age int } type C struct { A B } func main() { var c C c.A.Name = "tom" c.B.Name = "msy" c.A.Age = 59 c.B.Age = 10 c.Show() }
5.如果一个struct 嵌套了一个有名的结构体,这种模式就是组合,如果是组合关系,那么在访问组合的结构体的字段或方法时,必须带上结构体的名字
type D struct{ a A } //调用 var d D d.a.Name = "jack"
6.嵌套匿名结构体后,也可以在创建结构体变量时,直接指定各个匿名结构体的字段值。下面是多重继承,尽量不用使用多重继承
type Goods struct { Name string Price float64 } type Brand struct { Name string Address string } type Tv struct { Goods Brand } type Tv1 struct { *Goods *Brand } func main() { var tv =Tv{ Goods{Name:"电视机",Price:5999}, Brand{"华为","山东"}, } fmt.Println(tv) var tv1 =&Tv1{ &Goods{Name:"电视机",Price:5999}, &Brand{"华为","山东"}, } fmt.Println(*tv1.Goods,*tv1.Brand) }
7.结构体里面也可以匿名基本数据类型
type A struct { Name string Age int } type B struct { A int } func main() { var b B b.int = 9 b.Name = "tom" b.Age = 85 fmt.Println(b) }
十九.接口 interface
interface 类型可以定义一组方法,但是这些方法不需要实现,并且interface不能包含任何变量,到莫个自定义类型,比如结构体,要使用的时候,在根据具体情况把这些方法写出来
1.接口里面所有方法都没有方法体,即接口的方法都是没用实现的方法。接口体现了程序设计的多态和高内聚低耦合的思想
2.GOlang中接口,不需要显式的实现,只要一个变量,含有接口类型中的所有方法,那么这个变量九实现了这个接口,作为的鸭子类型,长的像鸭子,会下蛋,会鸭叫,会游泳的 就鸭子
type Usb interface { Start() Stop() } type Phone struct { } //让Phone 实现 Usb接口的方法 func (p Phone)Start() { fmt.Println("手机开始工作....") } func (p Phone)Stop() { fmt.Println("手机停止工作") } type Camera struct { } func (p Camera)Start() { fmt.Println("相机开始工作....") } func (p Camera)Stop() { fmt.Println("相机停止工作") } //计算机 type Computer struct { } //只要是USB接口 都可以可以用 需要实现USB接口的所有方法 func (c Computer)Working(usb Usb) { //这里体现了多态 usb变量会根据传入的实参,来判断到底是Phone 还是Camera usb.Start() usb.Stop() } func main() { computer :=Computer{}//电脑 phone :=Phone{}//手机 camera :=Camera{}//相机 computer.Working(phone) computer.Working(camera) }
1.接口本身不能创建实例,但可以指向一个实现了该接口的自定义类型的变量(实例)
type Ainterface interface { Say() } type Binterface interface { Hello() } type Stu struct { Name string } func (stu Stu)Say() { fmt.Println("stu Say()....") } type integer int //普通类型实现接口 func (i integer)Say() { fmt.Println("integer Say().......") } type Monster struct { } //Monster 实现 B接口 func (m Monster)Hello() { fmt.Println("Monster Hello()....") } //Monster 实现A接口 func (m Monster)Say() { fmt.Println("Monster Say()......") } func main() { var stu Stu var a Ainterface= stu a.Say() //普通类型实现接口 var i integer = 10 var b Ainterface = i b.Say() //Monster 实现了 A 和 B 两个接口 var monster Monster var a1 Ainterface = monster var a2 Binterface = monster a1.Say() a2.Hello() }
2.接口中所有方法都没用方法体,即都没有实现的方法
3.在golang中 一个自定义类型需要将木个接口所有的方法都实现,我们说这个自定义类型实现了该接口
4.一个自定义类型只有实现了木个接口,才能将该自定义类型的实例(变量)赋值给接口类型
5.只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型
6.一个自定义类型可以实现多个接口
7.一个接口(比如A),可以继承多个别的接口(比如B,C)这时如果要实现A接口,也必须将B,C接口的方法也全部实现,但B和C 不能有相同的方法名
type Binterface interface { test01() } type Cinterface interface { test02() } type Ainterface interface { Binterface Cinterface test03() } type Stu struct { } func (stu Stu)test01() { fmt.Println("Binterface test01()......") } func (stu Stu)test02() { fmt.Println("Cinterface test02()......") } func (stu Stu)test03() { fmt.Println("Ainterface test03()......") } func main() { var stu Stu var a Ainterface = stu a.test02() }
8. interface类型默认是一个指针,(引用类型),如果没用对interface初始化就使用,那么会输出nil
9.空接口interface{}没有任何方法,所以所有类型都实现了空接口,可以把任何类型的变量赋值给空接口
//实现对Hero结构体切片的排序:sort.Sort(data Interface) sort.Ints() 对一个int切片进行排序 (实用对学生成绩排序)
func main() { slice := []int{1,5,7,3,4,6,88,22,55} sort.Ints(slice)//对int类型的切片进行排序 fmt.Println(slice) }
package main import ( "fmt" "math/rand" "sort" ) type Hero struct { Name string Age int Score float64 } //声明一个Hero结构体切片类型 type HeroSlice []Hero //切片里面的val 是Hero结构体 //实现Interface接口 func (hs HeroSlice) Len() int{ return len(hs) } //less方法就是决定你使用什么标准进行排序 //1.按hero的年龄从小到大排序 func (hs HeroSlice) Less(i,j int) bool{ //return hs[i].Age > hs[j].Age //对Age排序 //return hs[i].Name > hs[j].Name //对Name排序 return hs[i].Score > hs[j].Score //对Name排序 } func (hs HeroSlice)Swap(i,j int) { hs[i],hs[j] = hs[j],hs[i] } func main() { var heroes HeroSlice for i:=0;i<=10;i++ { hero :=Hero{ Name: fmt.Sprintf("硬汉~%d",rand.Intn(100)), Age: rand.Intn(100), Score: float64(rand.Intn(100)), } heroes = append(heroes,hero) } fmt.Println("排序前:",heroes) //调用sort.Sort sort.Sort(heroes) //用这个排序必须实现接口,实现接口里面的三个方法,Len(),Less(),Swap(), fmt.Println("排序后:",heroes) }
//对学生成绩排序
package main import ( "fmt" "math/rand" "sort" ) type Student struct { Name string //学生姓名 Age int //学生年龄 Score float64 //学生分数 } type Stuslice []Student //结构体切片->切片里面放的结构体 func (stu Stuslice)Len()int { return len(stu) } func (stu Stuslice)Less(i,j int)bool { return stu[i].Score>stu[j].Score } func (stu Stuslice)Swap(i,j int) { stu[i],stu[j] = stu[j],stu[i] } func main() { //结构体切片排序 var stuslic Stuslice for i:=0;i<=10;i++ { hero :=Student{ Name: fmt.Sprintf("张三~%d",rand.Intn(100)), Age: rand.Intn(100), Score: float64(rand.Intn(100)), } stuslic = append(stuslic,hero) } fmt.Println("排序前",stuslic) sort.Sort(stuslic) fmt.Println("排序后",stuslic) //整型切片排序 var slic []int for i:=0;i<=10;i++{ s :=rand.Intn(100) slic = append(slic,s) } fmt.Println(slic) sort.Ints(slic) fmt.Println(slic) }
//一个小猴子,继承老猴子的爬树,又要有鸟的飞行能力,又要有鱼的游泳能力
package main import "fmt" //定义一个猴子的结构体 type Monkey struct { Name string //猴子名称 } func (mon *Monkey)Climbing() { fmt.Println(mon.Name,"生来会爬树....") } //小猴子结构体 type LittleMonkey struct { Monkey //小猴子继承了猴子的结构体 } //鸟的飞行接口 type BridAble interface { Flying() //飞行能力 } //小猴子实现飞行接口 func (mon *LittleMonkey)Flying() { fmt.Println(mon.Name,"通过学习会飞行....") } //鱼游泳的接口 type FishAble interface { Swimming() } //小猴子实现游泳接口 func (mon *LittleMonkey)Swimming() { fmt.Println(mon.Name,"通过学习会游泳....") } func main(){ mokey := LittleMonkey{ Monkey{ Name:"悟空", }, } fmt.Printf("mokey的类型是:%T\n",mokey) mokey.Climbing() mokey.Flying() mokey.Swimming() }
1)当A结构体继承了B结构体,那么A结构体就自动继承了B结构体的字段和方法,并且可以直接使用
2)当A结构体需要扩展功能,同时又不希望去破坏继承关系,则可以去实现木个接口即可,因此我们可以认为:实现接口是对继承机制的补充

1.接口和继承解决的问题不同
继承的价值在于:解决代码的复用性和可维护性
接口的价值在于:设计,设计好各种规范(方法),让其他自定义类型去实现这些方法
2.接口比继承更加灵活
接口比继承更加灵活,继承是满足is-a的关系,而接口是满足like-a的关系
3.接口在一定程度上实现代码解耦
二十.多态
1.变量(实例)具有多种形态,面向对象的第三大特征,在GO语言,多态的特征是通过接口实现的,可以按照统一的接口来调用不同的实现,这时接口变量就呈现不同的形态
2.前面的Usb接口案例,Usb usb既可以接受手机变量,又可以接受相机变量,就体现了Usb接口的多态特性
1)多态参数
在前面的Usb接口案例,Usb usb 既可以接受手机变量,又可以接受相机变量,就体现了Usb接口多态
2)多态数组
演示一个案例:给Usb数组中,存放Phone结构体,和 Camera结构体变量,Phone还有一个特有的方法call() 请遍历Usb数组,如果是Phone变量,除了调用Usb接口声明的方法外,还需要调用Phone 特有方法Call
type Usb interface { Start() Stop() } type Phone struct { Name string } //让Phone 实现 Usb接口的方法 func (p Phone)Start() { fmt.Println("手机开始工作....") } func (p Phone)Stop() { fmt.Println("手机停止工作") } type Camera struct { Name string } func (p Camera)Start() { fmt.Println("相机开始工作....") } func (p Camera)Stop() { fmt.Println("相机停止工作") } //计算机 type Computer struct { } //只要是USB接口 都可以可以用 需要实现USB接口的所有方法 func (c Computer)Working(usb Usb) { //这里体现了多态 usb变量会根据传入的实参,来判断到底是Phone 还是Camera usb.Start() usb.Stop() } func main() { //定义一个Usb接口数组,可以存放Phone 和 Camear 的结构体变量 //这里就体现出了多态数组 var usbArr [3]Usb usbArr[0] = Phone{Name:"华为"} usbArr[1] = Phone{Name:"小米"} usbArr[2] = Camera{Name:"佳能"} fmt.Println(usbArr) //[{华为} {小米} {佳能}] }
二十一.类型断言
type Point struct { x int y int } func main() { var a interface{} var point Point = Point{1,2} a = point // 空接口可以接受任何类型的数据 var b Point //b = a 错误的 空接口赋值给结构体 b = a.(Point) //类型断言 fmt.Println(b) //{1 2} }
类型断言,由于接口是一般类型,不知道具体类型,如果要转成具体类型,就需要使用类型断言。
func main() { var t float64 = 2.25 var x interface{} x = t //接口指向了 float64 y := x.(float64) fmt.Printf("y 的类型是 %T 值是=%v",y,y) }
对于上面代码
在进行类型断言时,如果类型不匹配,就会报panic 因此进行类型断言时,要确保原来的空接口指向的就是断言的类型
如果在断言时,带上了检测机制,如果成功就OK,否则也不要报panic
//第一个 func main() { var t float64 = 2.25 var x interface{} x = t //接口指向了 float64 y,ok := x.(float64) if ok{ fmt.Println("断言成功") }else { fmt.Println("断言类型不对") } fmt.Printf("y 的类型是 %T 值是=%v",y,y) }
//第二个 type Stu struct { Name string Age int } func main() { stu := Stu{Name:"tom",Age:59} var a interface{} a = stu var stu1 Stu stu1 = a.(Stu) fmt.Println(stu1) }
给Phone结构体增加一个特有的方法call() 当Usb接口接受的是Phone 变量时,还需要调用call方法
type Usb interface { Start() Stop() } type Phone struct { Name string } //让Phone 实现 Usb接口的方法 func (p Phone)Start() { fmt.Println(p.Name,"手机开始工作....") } func (p Phone)Stop() { fmt.Println(p.Name,"手机停止工作") } func (p Phone)Call() { fmt.Println(p.Name,"手机在打电话") } type Camera struct { Name string } func (p Camera)Start() { fmt.Println(p.Name,"相机开始工作....") } func (p Camera)Stop() { fmt.Println(p.Name,"相机停止工作") } //计算机 type Computer struct { } //只要是USB接口 都可以可以用 需要实现USB接口的所有方法 func (c Computer)Working(usb Usb) { //这里体现了多态 usb变量会根据传入的实参,来判断到底是Phone 还是Camera usb.Start() //类型断言 if phone,ok := usb.(Phone);ok{ phone.Call() } usb.Stop() } func main() { //定义一个Usb接口数组,可以存放Phone 和 Camear 的结构体变量 //这里就体现出了多态数组 var usbArr [3]Usb usbArr[0] = Phone{Name:"华为"} usbArr[1] = Phone{Name:"小米"} usbArr[2] = Camera{Name:"佳能"} //遍历数组 var computer Computer for _,v := range usbArr{ computer.Working(v) fmt.Println() } fmt.Println(usbArr) //[{华为} {小米} {佳能}] }
//编写一个函数,可以判断输入的参数是什么类型 type Student struct { } //编写一个函数,可以判断输入的参数是什么类型 func TypeJudge(items... interface{}) { for index,v :=range items{ index++ switch v.(type) { case bool: fmt.Printf("第%v个参数是 bool 类型,值是%v\n",index,v) case int32: fmt.Printf("第%v个参数是 int32 类型,值是%v\n",index,v) case int64: fmt.Printf("第%v个参数是 int64 类型,值是%v\n",index,v) case float32: fmt.Printf("第%v个参数是 float32 类型,值是%v\n",index,v) case float64: fmt.Printf("第%v个参数是 float64 类型,值是%v\n",index,v) case string: fmt.Printf("第%v个参数是 string 类型,值是%v\n",index,v) case Student: fmt.Printf("第%v个参数是 Student 类型,值是%v\n",index,v) case *Student: fmt.Printf("第%v个参数是 *Student 类型,值是%v\n",index,v) default: fmt.Printf("第%v个参数是 不确定 类型,值是%v\n",index,v) } } } func main() { var n1 float32 = 1.1 var n2 float64 = 5.69 var n3 bool = true var n4 int32 = 5 var n5 int64 = 9 var n6 string = "hello" stu1 :=Student{} stu2 :=&Student{} TypeJudge(n1,n2,n3,n4,n5,n6,stu1,stu2) }
二十二.文件操作

流:数据在数据源(文件)和程序(内存)之间经历的路径
输入流:数据从数据源(文件)到程序(内存)的路径
输出流:数据从程序(内存)到数据源(文件)的路径
os.File 封装了所有文件相关操作,File是一个结构体
func main() { //打开文件 file,err := os.Open("c:/ebay.txt") if err != nil{ fmt.Println("打开文件失败 err=",err) } fmt.Printf("file=%v",*file) //关闭文件 err = file.Close() if err != nil{ fmt.Println("关闭文件失败 err=",err) } }
1)读取文件的内容并显示在终端(带缓冲区的方式),使用 os.Open file.Close, bufio.NewReader(), reader.ReadString
func main() { //打开文件 file,err := os.Open("c:/go/golang.txt") if err != nil{ fmt.Println("打开文件失败 err=",err) } defer file.Close() ////关闭文件 否则会有内存泄漏 reader := bufio.NewReader(file) //缓冲读取 默认大小 4096 //循环读取文件内容 for{ str,err := reader.ReadString('\n') if err == io.EOF{ //io.EOF 表示文件的末尾 break } fmt.Print(str) } fmt.Println("文件读取结束") }
2)读取文件的内容并显示在终端,(使用ioutil一次将整个文件读入到内存中),这种方式适用于文件不大的情况,相关方法和函数(ioutil.ReadFile)
func main() { file :="c:/go/golang.txt" content,err :=ioutil.ReadFile(file)//返回的是一个byte切片 if err != nil{ fmt.Println("读取文件失败,err=",err) } fmt.Printf("%v",string(content)) }
打开文件的模式
const ( O_RDONLY int = syscall.O_RDONLY // 只读模式打开文件 O_WRONLY int = syscall.O_WRONLY // 只写模式打开文件 O_RDWR int = syscall.O_RDWR // 读写模式打开文件 O_APPEND int = syscall.O_APPEND // 写操作时将数据附加到文件尾部 O_CREATE int = syscall.O_CREAT // 如果不存在将创建一个新文件 O_EXCL int = syscall.O_EXCL // 和O_CREATE配合使用,文件必须不存在 O_SYNC int = syscall.O_SYNC // 打开文件用于同步I/O O_TRUNC int = syscall.O_TRUNC // 如果可能,打开时清空文件 )
func OpenFile(name string, flag int, perm FileMode) (file *File, err error)
OpenFile是一个更一般性的文件打开函数,大多数调用者都应用Open或Create代替本函数。它会使用指定的选项(如O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件。如果操作成功,返回的文件对象可用于I/O。如果出错,错误底层类型是*PathError。
name:文件路径 fiag: 上述模式 perm:权限 FileMode 在WINDS下面无效,是用户Linux下面的
const ( // 单字符是被String方法用于格式化的属性缩写。 ModeDir FileMode = 1 << (32 - 1 - iota) // d: 目录 ModeAppend // a: 只能写入,且只能写入到末尾 ModeExclusive // l: 用于执行 ModeTemporary // T: 临时文件(非备份文件) ModeSymlink // L: 符号链接(不是快捷方式文件) ModeDevice // D: 设备 ModeNamedPipe // p: 命名管道(FIFO) ModeSocket // S: Unix域socket ModeSetuid // u: 表示文件具有其创建者用户id权限 ModeSetgid // g: 表示文件具有其创建者组id的权限 ModeCharDevice // c: 字符设备,需已设置ModeDevice ModeSticky // t: 只有root/创建者能删除/移动文件 // 覆盖所有类型位(用于通过&获取类型位),对普通文件,所有这些位都不应被设置 ModeType = ModeDir | ModeSymlink | ModeNamedPipe | ModeSocket | ModeDevice ModePerm FileMode = 0777 // 覆盖所有Unix权限位(用于通过&获取类型位) )
1.创建一个新文件,写入内容 5句"hello,Gardon"
2.打开一个存在的文件中,将来源的内容覆盖成新的内容10句"你好,牛魔王"
3.打开一个存在文件,在原来的内容追加内容"ABC!ENGLIST!"
4.打开一个文件,读出里面的内容,并追加十句"你好,北京"
func main() { filepath :="c:/go/golang1.txt" //file,err :=os.OpenFile(filepath,os.O_WRONLY|os.O_CREATE,0666) //1.写 和 创建 的模式 //file,err :=os.OpenFile(filepath,os.O_WRONLY|os.O_TRUNC,0666) //2.写 和 清空 的模式 //file,err :=os.OpenFile(filepath,os.O_WRONLY|os.O_APPEND,0666) //3.写 和 追加 的模式 file,err :=os.OpenFile(filepath,os.O_RDWR|os.O_APPEND,0666) //.读写 和 追加 的模式 if err != nil{ fmt.Printf("打开文件错误,err=",err) } //及时关闭file句柄 defer file.Close() reader :=bufio.NewReader(file) for { str,err := reader.ReadString('\n') if err == io.EOF{ break } fmt.Print(str) } //str :="hello,Gardon\r\n" //str :="你好,牛魔王\r\n" //str :="ABC!ENGLIST!" str :="你好,北京\r\n" //写入时,使用带缓存的 *Writer writer := bufio.NewWriter(file) for i:=0;i<5;i++{ writer.WriteString(str) } //因为writer是带缓存,因此在调用writerString方法时,其实内容是写入了缓存 writer.Flush() //将缓存的内容写入到文件 }
将一个文件内容写入到另一个文件中(文件都已经存在)
func main() { filepath1 :="c:/go/golang1.txt" filepath2 :="c:/go/golang2.txt" data,err := ioutil.ReadFile(filepath1) //读出一个文件的所有内容,只适合小文件内容的 if err != nil{ fmt.Println("读取文件失败 err=",err) return } err = ioutil.WriteFile(filepath2,data,0666) if err != nil{ fmt.Println("写入错误 err=",err) } }
golang判断文件或文件夹是否存在的方法为:os.Stat() 函数返回的错误值进行判断:
1)如果返回的错误为nil说明文件或文件夹存在
2)如果返回的错误类型使用os.IsNoExist()判断为true 说明文件或文件夹不存在
3)如果返回的错误为其他类型,则不确定是否存在
func PathExists(paths string)(bool,error) { _,err := os.Stat(paths) if err == nil{ return true,nil } if os.IsNotExist(err){//判断错误是不是不存在的错误 return false,nil } return false,nil } func main() { //filepath1 :="c:/go/golang1.txt" filepath2 :="c:/go/golang3.txt" bos,err :=PathExists(filepath2) fmt.Println(bos,err) }
将一个图片/电影/视频 拷贝到另一个目录下
func Copy(dst Writer, src Reader) (written int64, err error)
package main import ( "bufio" "fmt" "io" "os" ) func CopyFile(dstFileName string,srcFileName string)(writtern int64,err error) { srcfile,err := os.Open(srcFileName) if err !=nil{ fmt.Println("打开文件错误,err=",err) } defer srcfile.Close() reader := bufio.NewReader(srcfile) dstFile,err :=os.OpenFile(dstFileName,os.O_WRONLY|os.O_CREATE,0666) if err != nil{ fmt.Println("打开文件失败err=",err) } defer dstFile.Close() writer :=bufio.NewWriter(dstFile) return io.Copy(writer,reader) } func main() { srcFile :="1.jpg" dstFile :="./model/2.jpg" _,err :=CopyFile(dstFile,srcFile) if err != nil{ fmt.Println("拷贝失败err=",err) } }
统计英文,数字,空格,和其他字符的数量
说明:统计一个文件中含有的英文,数字,空格及其它的字符数量
//定义一个结构体用户保存统计结构 type CharCount struct { ChCount int //记录英文个数 NumCount int //记录数字个数 SpaceCount int //记录空格个数 OtherCount int //记录其他字符个数 } func main() { filepath :="abc.txt" file,err :=os.Open(filepath) if err != nil{ fmt.Println("打开文件错误") return } defer file.Close() var count CharCount //记录结果的结构体 reader :=bufio.NewReader(file) for{ str,err := reader.ReadString('\n') if err == io.EOF{ break } //遍历str 进行统计 for _,v := range str{ switch { case v>'a' && v<'z': fallthrough //穿透 case v>'A' && v<'Z': count.ChCount++ case v == ' ' || v == '\t': count.SpaceCount++ case v >='0' && v<=9: count.NumCount++ default: count.OtherCount++ } } } fmt.Printf("数字的字符个数:%v,字符的个数为:%v,空格的字符为:%v,其他字符的个数:%v",count.NumCount,count.ChCount,count.SpaceCount,count.OtherCount) }
二十三.命令行参数
基本介绍
os.Args 是一个string的切片,用来存储所有的命令行参数
请编写一段代码,可以获取命令行各个参数
func main() { fmt.Println("命令行的参数有:",len(os.Args)) for i,v:=range os.Args{ fmt.Printf("args[%v]=%v\n",i,v) } }

flag包用来解析命令行参数
说明:前面的方式是比较原生的方式,对解析参数不是特别的方便,特别是带有指定参数形式的命令行。
比如:cmd>main.ext -f c:/aaa.txt -p 200 -u root 这样的形式命令行,go设计者给我们提供了 flag 包,可以方便的解析命令行参数,而且参数顺序可以随意
请编写一段代码获取各个输入参数
func main() { //定义几个变量,用于接受命令行参数 var user string var pwd string var host string var port int //&user 就是接受用户命令行中输入的 -u 后面的参数值 //"u",就是 -u 指定参数 //"",默认值 //"用户名,默认为空" 说明 flag.StringVar(&user,"u","","用户名,默认为空") flag.StringVar(&pwd,"p","","密码,默认为空") flag.StringVar(&host,"h","localhost","主机名,默认为localhost") flag.IntVar(&port,"port",3306,"端口号,默认为3306") //这里有一个非常终于的操作,转换,必须调用该方法 flag.Parse() //输入结果 fmt.Printf("user=%v pwd=%v host=%v port=%v",user,pwd,host,port) }

二十四.json数据格式 和 tag的使用(指定标签)
结构体序列化
package main
import (
"encoding/json"
"fmt"
)
type Monster struct {
Name string `json:"name"` //首字母大写才能挎包使用,不然 下面的 json.Marshal 会丢失 Name
Age int `json:"age"`
Birthday string `json:"birthday"`
Sal float64 `json:"sal"`
Skill string `json:"skill"`
}
//结构体的序列化
func testStruct() {
monster := Monster{
Name: "牛魔王",
Age: 500,
Birthday: "2022-01-05",
Sal: 8000.0,
Skill: "牛魔权",
}
data, err := json.Marshal(&monster) //返回一个byte切片
if err != nil {
fmt.Println("序列化错误 err=", err)
}
fmt.Printf("结构体序列化的结果:%v\n", string(data))
}
//切片的序列化
func testSlice() {
var slice []map[string]interface{}
var m1 map[string]interface{}
m1 = make(map[string]interface{})
m1["name"] = "job"
m1["age"] = 45
m1["address"] = "深圳龙岗区"
slice = append(slice,m1)
m2 := make(map[string]interface{})
m2["name"] = "top"
m2["age"] = 5
m2["address"] = [2]string{"深圳宝安","深圳福田"}
slice = append(slice,m2)
data, err := json.Marshal(&slice) //返回一个byte切片
if err != nil {
fmt.Println("序列化错误 err=", err)
}
fmt.Printf("切片序列化的结果:%v\n", string(data))
}
//基本类型的序列化
func testFloat64() {
var num1 float64 = 2354.54
data, err := json.Marshal(&num1) //返回一个byte切片
if err != nil {
fmt.Println("序列化错误 err=", err)
}
fmt.Printf("基本类型序列化的结果:%v\n", string(data))
}
func main() {
testStruct()
testSlice()
testFloat64()
}
结果:
结构体序列化的结果:{"name":"牛魔王","age":500,"birthday":"2022-01-05","sal":8000,"skill":"牛魔权"}
切片序列化的结果:[{"address":"深圳龙岗区","age":45,"name":"job"},{"address":["深圳宝安","深圳福田"],"age":5,"name":"top"}]
基本类型序列化的结果:2354.54
将json字符串反序列化为结构体
package main import ( "encoding/json" "fmt" ) type Monster struct { Name string Age int Birthday string Sal float64 Skill string } //将json反序列化成结构体 func unmarshalStruct() { str :=`{"name":"牛魔王","age":500,"birthday":"2022-01-05","sal":8000,"skill":"牛魔权"}`; //定义一个Monster实例 var monster Monster err :=json.Unmarshal([]byte(str),&monster) if err != nil{ fmt.Printf("Unmarshal err=%v\n",err) } fmt.Printf("反序列化后 monster=%v\n monster.Name=%v\n",monster,monster.Name) } //将json字符串反序列化为map func unmarshalMap() { str :=`{"address":"深圳龙岗区","age":45,"name":"job"}` //定义一个map var a map[string]interface{} //反序列化 //注意:反序列化map 不需要make,因为make操作被封装到了 Unmarshal函数 err :=json.Unmarshal([]byte(str),&a) if err != nil{ fmt.Printf("Unmarshal err=%v\n",err) } fmt.Printf("反序列化后map=%v\n",a) } //将json字符串反序列化为slice func unmarshalSlice() { str :=`[{"address":"深圳龙岗区","age":45,"name":"job"},{"address":["深圳宝安","深圳福田"],"age":5,"name":"top"}]` var b []map[string]interface{} //注意:反序列化map 不需要make,因为make操作被封装到了 Unmarshal函数 err :=json.Unmarshal([]byte(str),&b) if err != nil{ fmt.Printf("Unmarshal err=%v\n",err) } fmt.Printf("反序列化后的切片=%v\n",b) } func main() { unmarshalStruct() unmarshalMap() unmarshalSlice() }
结果:
1)在反序列化一个json字符串时,要确保反序列化后的数据类型和原来的序列化前的数据类型一致
反序列化后 monster={牛魔王 500 2022-01-05 8000 牛魔权}
monster.Name=牛魔王
反序列化后map=map[address:深圳龙岗区 age:45 name:job]
反序列化后的切片=[map[address:深圳龙岗区 age:45 name:job] map[address:[深圳宝安 深圳福田] age:5 name:top]]
二十四.单元测试
GO语言中自带有一个轻量级的测试框架testing和自带的go test 命令来实现单元测试和性能测试,testing框架和其他语言中的测试框架类似,可以基于这个框架写针对相应的测试用例,也可以基于该框架写相应的压力测试用例.通过单元测试,可以解决如下问题:
1)确保每个函数是可运行,并且运行结果是正确的
2)确保写处理的代码性能是好的
3)单元测试能及时发现程序设计或实现的逻辑错误,使问题及早暴露,便于问题的定位解决,而性能测试的重点在于发现程序设计上的一些问题,让程序能够在高并发的情况下还能保持稳定
packago/myAccount/cal.go
package main
func addUpper(n int)(int) {
var sum = 0
for i:=1;i<=n;i++{
sum +=i
}
return sum
}
func getsub(x,y int)int {
return x-y
}
packago/myAccount/cal_test.go
package cal
import (
"testing"
)
func TestAddUpper(t *testing.T) {
res :=addUpper(10)
if res != 55{
t.Fatalf("AddUpper(10) 执行错误,期望值=%v 实际值=%v\n",55,res)
}
t.Logf("AddUpper(10) 执行正确,期望值=%v 实际值=%v\n",55,res)
}
packago/myAccount/sub_test.go
package cal import "testing" func TestSub(t *testing.T) { res :=getsub(10,5) if res != 5{ t.Fatalf("getsub(10,5) 执行错误,期望值=%v 实际值=%v\n",5,res) } t.Logf("getsub(10,5) 执行正确,期望值=%v 实际值=%v\n",5,res) }
测试结果:go test -v 会扫描所有的_test.go 测试用例执行
=== RUN TestAddUpper
cal_test.go:11: AddUpper(10) 执行正确,期望值=55 实际值=55
--- PASS: TestAddUpper (0.00s)
=== RUN TestSub
sub_test.go:10: getsub(10,5) 执行正确,期望值=5 实际值=5
--- PASS: TestSub (0.00s)
PASS
ok packago/myAccount 0.402s
1) 测试用例文件名必须以 _test.go 结尾。比如 cal_test.go , cal 不是固定的
2) 测试用例函数必须以 Test开头,一般来说就是 Test+被测试的函数名,比如 TestAddUpper.
官方说明:func TestXxx(*testing.T) 其中 Xxx 可以是任何字母数字字符串(但第一个字母不能是 [a-z]小写的),用于识别测试例程。
3) TestAddUpper(T *testing.T)的形参类型必须是 *testing.T
4) 一个测试用例文件中,可以有多个测试用例函数,比如 TestAddUpper,TestSub
5) 运行测试用例指令
(1) cmd>go test[如果运行正确,无日志,错误时,会输出日志]
(2) cmd>go test -v [运行正确或错误,都会输出日志]
6) 当出现错误时,可以使用t.Fatalf来格式化输出错误信息,并退出程序
7) t.Logf方法可以输出相应的日志
8) 测试用例函数,并没有放到main函数中,也执行了,这就是测试用例的方便之处
9) PASS 表示测试用例运行成功,FALL表示测试用例运行失败
10) 测试单个文件,一定要带上被测试的源文件 go test -v cal_test.go cal.go
C:\goprojects\src\packago\myAccount>go test -v sub_test.go cal.go === RUN TestSub sub_test.go:10: getsub(10,5) 执行正确,期望值=5 实际值=5 --- PASS: TestSub (0.00s) PASS ok command-line-arguments (cached)
11) 测试单个方法 go test -v -test.run TestAddUpper
=== RUN TestAddUpper cal_test.go:11: AddUpper(10) 执行正确,期望值=55 实际值=55 --- PASS: TestAddUpper (0.00s) PASS ok packago/myAccount 0.409s
1) 编写一个Monster结构体,字段Name,Age,Skill
2) 给Monster绑定方法Store,可以将一个Monster变量,序列化后保存到文件中
3) 给Monster绑定方法ReStore,可以将一个序列化的Monster,从文件中读取,并反序列化为Monster对象
4) 编程测试用例文件 store_test.go,编写测试用例函数TestStore和TestRestore进行测试
monster.go
package model
import (
"encoding/json"
"fmt"
"io/ioutil"
)
type Monster struct {
Name string
Age int
Skill string
}
func (this *Monster)Store() bool {
data,err := json.Marshal(this)
fmt.Println(data)
if err !=nil{
fmt.Println("序列化错误 err=", err)
return false
}
filepath :="c:/go/golang.txt"
err = ioutil.WriteFile(filepath,data,0666)
if err != nil{
fmt.Println("打开文件错误,err=",err)
return false
}
return true
}
func (this *Monster)ReStore() bool {
filepath :="c:/go/golang.txt"
data,err :=ioutil.ReadFile(filepath)
if err !=nil{
fmt.Println("读取文件错误 err=", err)
return false
}
err = json.Unmarshal(data,this)
if err !=nil{
fmt.Println("反序列化失败 err=", err)
return false
}
return true
}
monster_test.go
package model import "testing" func TestStore(t *testing.T) { monster := Monster{ Name: "红孩儿", Age: 900, Skill: "三头六臂", } res :=monster.Store() if !res{ t.Fatalf("monster.Store() 错误,希望为:%v 实际为%v",true,res) } t.Logf("monster.Store() 测试成功") } func TestReStore(t *testing.T) { var monster Monster res :=monster.ReStore() if !res{ t.Fatalf("monster.ReStore() 错误,希望为:%v 实际为%v",true,res) } if monster.Name != "红孩儿"{ t.Fatalf("monster.ReStore() 错误,希望为:%v 实际为%v",true,res) } t.Logf("monster.ReStore() 测试成功") }
二十五.Goroutine(协程)
25.1基本介绍
进程和线程
1) 进程就是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位
2) 线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单位
3) 一个进程可以创建核销多个线程,同一个进程中的多个线程可以并发执行
4) 一个程序至少有一个进程,一个进程至少有一个线程
并发和并行
1) 多线程程序在一个核的cpu上运行,就是并发。
解释:因为是在一个CPU上,比如有10个线程,每个线程执行10毫秒(进行轮询操作),从人的角度看,好像这10个线程都在运行,但是从微观上看,
在某一个时间点看,其实只有一个线程在执行,这就是并发。

2) 多线程程序在多个核的cpu上运行,就是并行。
解释:因为是多个CPU上(比如有10个CPU),比如有10个线程,每个线程执行10毫秒(各自在不同CPU上执行),从人的角度看,这10个线程都在运行,
但从微观上看,在某一个时间点看,也同时有10个线程在执行,这就是并行

协程和线程
协程:独立的栈空间,共享堆空间,调度由用户自己控制,本质上有点类似于用户级线程,这些用户级线程的调度也是自己实现的。
线程:一个线程上可以跑多个协程,协程是轻量级的线程。
25.2 go协程和go的主线程
1) go主线程(有程序员直接称为线程/也可以理解成进程):一个GO线程上,可以起多个协程,你可以这样理解,协程是轻量级的线程。
2) go协程的特点 1.有独立的栈空间 2.共享程序堆空间 3.调度由用户控制 4.协程是轻量级的线程
小知识:
堆和栈的区别主要有五大点,分别是:
1、申请方式的不同。栈由系统自动分配,而堆是人为申请开辟;
2、申请大小的不同。栈获得的空间较小,而堆获得的空间较大;
3、申请效率的不同。栈由系统自动分配,速度较快,而堆一般速度比较慢;
4、存储内容的不同。栈在函数调用时,函数调用语句的下一条可执行语句的地址第一个进栈,
然后函数的各个参数进栈,其中静态变量是不入栈的。而堆一般是在头部用一个字节存放堆的大小,堆中的具体内容是人为安排;
5、底层不同。栈是连续的空间,而堆是不连续的空间。
package main import ( "fmt" "strconv" "time" ) func test(){ for i:=0;i<=10;i++{ fmt.Println("test() hello,world "+strconv.Itoa(i)) time.Sleep(time.Second) } } func main() { go test()//开启一个协程 for i:=0;i<=10;i++{ fmt.Println("main() hello,golang "+strconv.Itoa(i)) time.Sleep(time.Second) } }
结果:main主线程和test协程在同时执行
main() hello,golang 0 test() hello,world 0 main() hello,golang 1 test() hello,world 1 test() hello,world 2 main() hello,golang 2 test() hello,world 3 main() hello,golang 3
...
示意图:

1) 主线程是一个物理线程,直接作用在cpu上的。是重量级的,非常耗费cpu资源。
2) 协程从主线程开启的,是轻量级的线程,是逻辑态。对资源消耗相对小。
3) golang的协程机制是重要的特点,可以轻松的开启上万个协程。其他编程语言的并发机制是一般基于线程的,开启过多的线程,资源耗费大,这里就是突显golang在并发上的优势了
25.3 MPG基本模式介绍

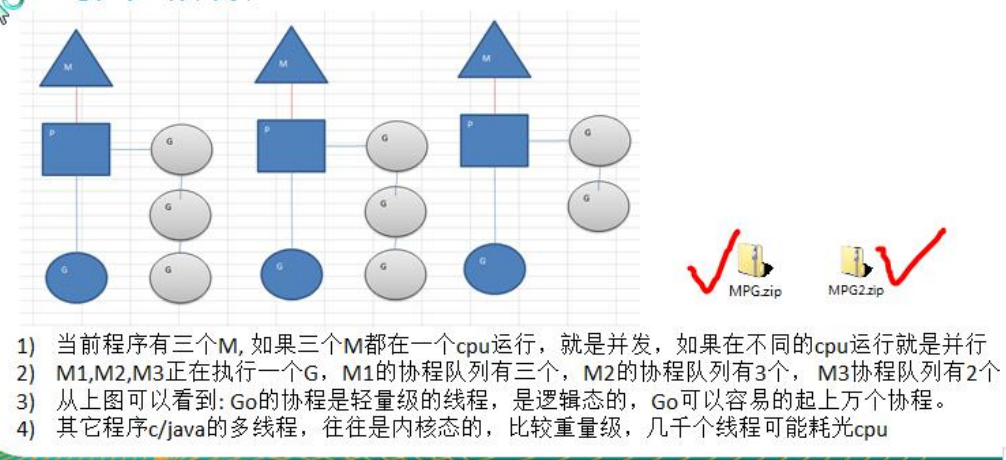

25.4 设置golang使用CPU的个数
package main import ( "fmt" "runtime" ) func main() { //获取当前系统CPU的数量 num:=runtime.NumCPU() //设置使用多少个CPU runtime.GOMAXPROCS(num-1)//留一个CPU给其他程序使用 fmt.Println(num) }
1) go1.8后,默认让程序运行在多个核上,可以不用设置了
2) go1.8前,还是要设置一下,可以更高效的利用CPU
Gosched:让当前线程让出 cpu 以让其它线程运行,它不会挂起当前线程,因此当前线程未来会继续执行
这个函数的作用是让当前 goroutine 让出 CPU,当一个 goroutine 发生阻塞,Go 会自动地把与该 goroutine 处于同一系统线程的其他 goroutine 转移到另一个系统线程上去,以使这些 goroutine 不阻塞。
func main() { go func() { for i := 0; i < 5; i++ { fmt.Println("goroutine。。。") } }() for i := 0; i < 4; i++ { //让出时间片,先让别的协议执行,它执行完,再回来执行此协程 runtime.Gosched() fmt.Println("main。。") } }
Goexit:退出当前 goroutine(但是defer语句会照常执行)
func main() { //创建新建的协程 go func() { fmt.Println("goroutine开始。。。") //调用了别的函数 fun() fmt.Println("goroutine结束。。") }() //别忘了() //睡一会儿,不让主协程结束 time.Sleep(3*time.Second) } func fun() { defer fmt.Println("defer。。。") //return //终止此函数 runtime.Goexit() //终止所在的协程 fmt.Println("fun函数。。。") }
NumGoroutine:返回正在执行和排队的任务总数
runtime.NumGoroutine函数在被调用后,会返回系统中的处于特定状态的Goroutine的数量。这里的特指是指Grunnable\Gruning\Gsyscall\Gwaition。处于这些状态的Groutine即被看做是活跃的或者说正在被调度。
注意:垃圾回收所在Groutine的状态也处于这个范围内的话,也会被纳入该计数器。
GOOS:目标操作系统
runtime.GC:会让运行时系统进行一次强制性的垃圾收集
强制的垃圾回收:不管怎样,都要进行的垃圾回收。
非强制的垃圾回收:只会在一定条件下进行的垃圾回收(即运行时,系统自上次垃圾回收之后新申请的堆内存的单元(也成为单元增量)达到指定的数值)。
GOROOT :获取goroot目录
GOOS : 查看目标操作系统 很多时候,我们会根据平台的不同实现不同的操作,就而已用GOOS了:
//获取goroot目录: fmt.Println("GOROOT-->",runtime.GOROOT()) //获取操作系统 fmt.Println("os/platform-->",runtime.GOOS) // GOOS--> darwin,mac系统
临界资源安全问题
临界资源: 指并发环境中多个进程/线程/协程共享的资源。
但是在并发编程中对临界资源的处理不当, 往往会导致数据不一致的问题。
示例代码:
package main import ( "fmt" "time" ) func main() { a := 1 go func() { a = 2 fmt.Println("子goroutine。。",a) }() a = 3 time.Sleep(1) fmt.Println("main goroutine。。",a) }
结果:

能够发现一处被多个goroutine共享的数据。
并发本身并不复杂,但是因为有了资源竞争的问题,就使得我们开发出好的并发程序变得复杂起来,因为会引起很多莫名其妙的问题。
如果多个goroutine在访问同一个数据资源的时候,其中一个线程修改了数据,那么这个数值就被修改了,对于其他的goroutine来讲,这个数值可能是不对的。
举个例子,我们通过并发来实现火车站售票这个程序。一共有100张票,4个售票口同时出售。
我们先来看一下示例代码:
package main import ( "fmt" "math/rand" "time" ) //全局变量 var ticket = 10 // 100张票 func main() { /* 4个goroutine,模拟4个售票口,4个子程序操作同一个共享数据。 */ go saleTickets("售票口1") // g1,100 go saleTickets("售票口2") // g2,100 go saleTickets("售票口3") //g3,100 go saleTickets("售票口4") //g4,100 time.Sleep(5*time.Second) } func saleTickets(name string) { rand.Seed(time.Now().UnixNano()) for { //ticket=1 if ticket > 0 { //g1,g3,g2,g4 //睡眠 time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond) // g1 ,g3, g2,g4 fmt.Println(name, "售出:", ticket) // 1 , 0, -1 , -2 ticket-- //0 , -1 ,-2 , -3 } else { fmt.Println(name,"售罄,没有票了。。") break } } }
结果:

我们为了更好的观察临界资源问题,每个goroutine先睡眠一个随机数,然后再售票,我们发现程序的运行结果,还可以卖出编号为负数的票。
分析:
我们的卖票逻辑是先判断票数的编号是否为负数,如果大于0,然后我们就进行卖票,只不过在卖票钱先睡眠,然后再卖,假如说此时已经卖票到只剩最后1张了,某一个goroutine持有了CPU的时间片,那么它再片段是否有票的时候,条件是成立的,所以它可以卖票编号为1的最后一张票。但是因为它在卖之前,先睡眠了,那么其他的goroutine就会持有CPU的时间片,而此时这张票还没有被卖出,那么第二个goroutine再判断是否有票的时候,条件也是成立的,那么它可以卖出这张票,然而它也进入了睡眠。。其他的第三个第四个goroutine都是这样的逻辑,当某个goroutine醒来的时候,不会再判断是否有票,而是直接售出,这样就卖出最后一张票了,然而其他的goroutine醒来的时候,就会陆续卖出了第0张,-1张,-2张。
这就是临界资源的不安全问题。某一个goroutine在访问某个数据资源的时候,按照数值,已经判断好了条件,然后又被其他的goroutine抢占了资源,并修改了数值,等这个goroutine再继续访问这个数据的时候,数值已经不对了。
临界资源安全问题的解决
临界资源安全问题的解决要想解决临界资源安全的问题,很多编程语言的解决方案都是同步。通过上锁的方式,某一时间段,只能允许一个goroutine来访问这个共享数据,当前goroutine访问完毕,解锁后,其他的goroutine才能来访问。
我们可以借助于sync包下的锁操作。
示例代码:
package main import ( "fmt" "math/rand" "sync" "time" ) //全局变量 var ticket = 10 // 100张票 var wg sync.WaitGroup var matex sync.Mutex // 创建锁头 func main() { /* 4个goroutine,模拟4个售票口,4个子程序操作同一个共享数据。 */ wg.Add(4) go saleTickets("售票口1") // g1,100 go saleTickets("售票口2") // g2,100 go saleTickets("售票口3") //g3,100 go saleTickets("售票口4") //g4,100 wg.Wait() // main要等待。。。 //time.Sleep(5*time.Second) } func saleTickets(name string) { rand.Seed(time.Now().UnixNano()) defer wg.Done() for { //ticket=1 matex.Lock() if ticket > 0 { //g1,g3,g2,g4 //睡眠 time.Sleep(time.Duration(rand.Intn(1000)) * time.Millisecond) // g1 ,g3, g2,g4 fmt.Println(name, "售出:", ticket) // 1 , 0, -1 , -2 ticket-- //0 , -1 ,-2 , -3 } else { matex.Unlock() //解锁 fmt.Println(name, "售罄,没有票了。。") break } matex.Unlock() //解锁 } }
在Go的并发编程中有一句很经典的话:不要以共享内存的方式去通信,而要以通信的方式去共享内存。
在Go语言中并不鼓励用锁保护共享状态的方式在不同的Goroutine中分享信息(以共享内存的方式去通信)。而是鼓励通过channel将共享状态或共享状态的变化在各个Goroutine之间传递(以通信的方式去共享内存),这样同样能像用锁一样保证在同一的时间只有一个Goroutine访问共享状态。
当然,在主流的编程语言中为了保证多线程之间共享数据安全性和一致性,都会提供一套基本的同步工具集,如锁,条件变量,原子操作等等。Go语言标准库也毫不意外的提供了这些同步机制,使用方式也和其他语言也差不多。
sync包
sync是synchronization同步这个词的缩写,所以也会叫做同步包。这里提供了基本同步的操作,比如互斥锁等等。这里除了Once和WaitGroup类型之外,大多数类型都是供低级库例程使用的。更高级别的同步最好通过channel通道和communication通信来完成
WaitGroup
WaitGroup,同步等待组。
在类型上,它是一个结构体。一个WaitGroup的用途是等待一个goroutine的集合执行完成。主goroutine调用了Add()方法来设置要等待的goroutine的数量。然后,每个goroutine都会执行并且执行完成后调用Done()这个方法。与此同时,可以使用Wait()方法来阻塞,直到所有的goroutine都执行完成。
Add()方法:
Add这个方法,用来设置到WaitGroup的计数器的值。我们可以理解为每个waitgroup中都有一个计数器 用来表示这个同步等待组中要执行的goroutin的数量。
如果计数器的数值变为0,那么就表示等待时被阻塞的goroutine都被释放,如果计数器的数值为负数,那么就会引发恐慌,程序就报错了。
Done()方法
Done()方法,就是当WaitGroup同步等待组中的某个goroutine执行完毕后,设置这个WaitGroup的counter数值减1。
Wait()方法
Wait()方法,表示让当前的goroutine等待,进入阻塞状态。一直到WaitGroup的计数器为零。才能解除阻塞, 这个goroutine才能继续执行。
我们创建并启动两个goroutine,来打印数字和字母,并在main goroutine中,将这两个子goroutine加入到一个WaitGroup中,同时让main goroutine进入Wait(),让两个子goroutine先执行。当每个子goroutine执行完毕后,调用Done()方法,设置WaitGroup的counter减1。当两条子goroutine都执行完毕后,WaitGroup中的counter的数值为零,解除main goroutine的阻塞。
示例代码:
package main import ( "fmt" "sync" ) var wg sync.WaitGroup // 创建同步等待组对象 func main() { /* WaitGroup:同步等待组 可以使用Add(),设置等待组中要 执行的子goroutine的数量, 在main 函数中,使用wait(),让主程序处于等待状态。直到等待组中子程序执行完毕。解除阻塞 子gorotuine对应的函数中。wg.Done(),用于让等待组中的子程序的数量减1 */ //设置等待组中,要执行的goroutine的数量 wg.Add(2) go fun1() go fun2() fmt.Println("main进入阻塞状态。。。等待wg中的子goroutine结束。。") wg.Wait() //表示main goroutine进入等待,意味着阻塞 fmt.Println("main,解除阻塞。。") } func fun1() { for i:=1;i<=10;i++{ fmt.Println("fun1.。。i:",i) } wg.Done() //给wg等待中的执行的goroutine数量减1.同Add(-1) } func fun2() { defer wg.Done() for j:=1;j<=10;j++{ fmt.Println("\tfun2..j,",j) } }
结果:

Mutex(互斥锁)
通过上一小节,我们知道了在并发程序中,会存在临界资源问题。就是当多个协程来访问共享的数据资源,那么这个共享资源是不安全的。为了解决协程同步的问题我们使用了channel,但是Go语言也提供了传统的同步工具。
什么是锁呢?就是某个协程(线程)在访问某个资源时先锁住,防止其它协程的访问,等访问完毕解锁后其他协程再来加锁进行访问。一般用于处理并发中的临界资源问题。
Go语言包中的 sync 包提供了两种锁类型:sync.Mutex 和 sync.RWMutex。
Mutex 是最简单的一种锁类型,互斥锁,同时也比较暴力,当一个 goroutine 获得了 Mutex 后,其他 goroutine 就只能乖乖等到这个 goroutine 释放该 Mutex。
每个资源都对应于一个可称为 “互斥锁” 的标记,这个标记用来保证在任意时刻,只能有一个协程(线程)访问该资源。其它的协程只能等待。
互斥锁是传统并发编程对共享资源进行访问控制的主要手段,它由标准库sync中的Mutex结构体类型表示。sync.Mutex类型只有两个公开的指针方法,Lock和Unlock。Lock锁定当前的共享资源,Unlock进行解锁。
在使用互斥锁时,一定要注意:对资源操作完成后,一定要解锁,否则会出现流程执行异常,死锁等问题。通常借助defer。锁定后,立即使用defer语句保证互斥锁及时解锁。
Lock()方法:
Lock()这个方法,锁定m。如果该锁已在使用中,则调用goroutine将阻塞,直到互斥体可用。
Unlock()方法
Unlock()方法,解锁解锁m。如果m未在要解锁的条目上锁定,则为运行时错误。
锁定的互斥体不与特定的goroutine关联。允许一个goroutine锁定互斥体,然后安排另一个goroutine解锁互斥体。
我们针对于上次课程汇总,使用goroutine,模拟4个售票口出售火车票的案例。4个售票口同时卖票,会发生临界资源数据安全问题。我们使用互斥锁解决一下。(Go语言推崇的是使用Channel来实现数据共享,但是也还是提供了传统的同步处理方式)
package main import ( "fmt" "time" "math/rand" "sync" ) //全局变量,表示票 var ticket = 10 //100张票 var mutex sync.Mutex //创建锁头 var wg sync.WaitGroup //同步等待组对象 func main() { /* 4个goroutine,模拟4个售票口, 在使用互斥锁的时候,对资源操作完,一定要解锁。否则会出现程序异常,死锁等问题。 defer语句 */ wg.Add(4) go saleTickets("售票口1") go saleTickets("售票口2") go saleTickets("售票口3") go saleTickets("售票口4") wg.Wait() //main要等待 fmt.Println("程序结束了。。。") //time.Sleep(5*time.Second) } func saleTickets(name string){ rand.Seed(time.Now().UnixNano()) defer wg.Done() for{ //上锁 mutex.Lock() //g2 if ticket > 0{ //ticket 1 g1 time.Sleep(time.Duration(rand.Intn(1000))*time.Millisecond) fmt.Println(name,"售出:",ticket) // 1 ticket-- // 0 }else{ mutex.Unlock() //条件不满足,也要解锁 fmt.Println(name,"售罄,没有票了。。") break } mutex.Unlock() //解锁 } }

RWMutex(读写锁)
通过对互斥锁的学习,我们已经知道了锁的概念以及用途。主要是用于处理并发中的临界资源问题。
Go语言包中的 sync 包提供了两种锁类型:sync.Mutex 和 sync.RWMutex。其中RWMutex是基于Mutex实现的,只读锁的实现使用类似引用计数器的功能。
RWMutex是读/写互斥锁。锁可以由任意数量的读取器或单个编写器持有。RWMutex的零值是未锁定的mutex。
如果一个goroutine持有一个rRWMutex进行读取,而另一个goroutine可能调用lock,那么在释放初始读取锁之前,任何goroutine都不应该期望能够获取读取锁。特别是,这禁止递归读取锁定。这是为了确保锁最终可用;被阻止的锁调用会将新的读卡器排除在获取锁之外。
我们怎么理解读写锁呢?当有一个 goroutine 获得写锁定,其它无论是读锁定还是写锁定都将阻塞直到写解锁;当有一个 goroutine 获得读锁定,其它读锁定仍然可以继续;当有一个或任意多个读锁定,写锁定将等待所有读锁定解锁之后才能够进行写锁定。所以说这里的读锁定(RLock)目的其实是告诉写锁定:有很多人正在读取数据,你给我站一边去,等它们读(读解锁)完你再来写(写锁定)。我们可以将其总结为如下三条:
同时只能有一个 goroutine 能够获得写锁定。
同时可以有任意多个 gorouinte 获得读锁定。
同时只能存在写锁定或读锁定(读和写互斥)。
所以,RWMutex这个读写锁,该锁可以加多个读锁或者一个写锁,其经常用于读次数远远多于写次数的场景。
读写锁的写锁只能锁定一次,解锁前不能多次锁定,读锁可以多次,但读解锁次数最多只能比读锁次数多一次,一般情况下我们不建议读解锁次数多余读锁次数。
基本遵循两大原则:
1、可以随便读,多个goroutine同时读。
2、写的时候,啥也不能干。不能读也不能写。
读写锁即是针对于读写操作的互斥锁。它与普通的互斥锁最大的不同就是,它可以分别针对读操作和写操作进行锁定和解锁操作。读写锁遵循的访问控制规则与互斥锁有所不同。在读写锁管辖的范围内,它允许任意个读操作的同时进行。但是在同一时刻,它只允许有一个写操作在进行。
并且在某一个写操作被进行的过程中,读操作的进行也是不被允许的。也就是说读写锁控制下的多个写操作之间都是互斥的,并且写操作与读操作之间也都是互斥的。但是,多个读操作之间却不存在互斥关系。
二十六.channel(管道)
需求:现在要计算 1-200 的各个数的阶乘,并把各个数的阶乘放入到map中。最后显示出来。要求用goroutine完成
分析思路:
1) 使用goroutine来完成,效率高,但是会出现并发/并行安全问题
2) 这里就提出了不同goroutine如何通信的问题
代码实现
1) 使用 goroutine 来完成 (看看使用 goroutine 并发完成会出现什么问题?然后我们如何去解决)
2) 在运行某个程序时,如何指定是否存在资源竞争问题。在编译该程序时,增加一个参数 -race 即可
package main import ( "fmt" "time" ) var myMap = make(map[int]int,10) func test(n int) { res :=1 for i:=1;i<=n;i++ { res *=i } myMap[n] = res; } func main() { for i:=1; i<=200;i++ { go test(i)//开启200个协程 } time.Sleep(time.Second * 10) for i,v :=range myMap{ fmt.Printf("map[%d]=%d\n",i,v) } }
结果:fatal error: concurrent map writes
同时两百个协程同时操作了mymap 资源竞争

不同goroutine 之间如何通讯
1) 全局变量加锁同步
2) channel
使用全局变量加锁同步改进程序
1) 因为没有对全局变量m加锁,因此会出现资源争夺问题,代码会出现错误,提示concurrent map writes
2) 解决方案:加入互斥锁
3) 我们的数的阶乘很大,结果会越界,可以将求阶乘改成 sum += uint64(i)
package main import ( "fmt" "sync" "time" ) var myMap = make(map[int]float64,10) var lock sync.Mutex //互斥锁 func test(n int) { var res float64 = 1 for i:=1;i<=n;i++ { res *=float64(i) } lock.Lock()//加锁 myMap[n] = res; lock.Unlock()//解锁 } func main() { for i:=1; i<=200;i++ { go test(i) } time.Sleep(time.Second * 2) lock.Lock() for i,v:=range myMap{ fmt.Printf("map[%d]=%f\n",i,v) } lock.Unlock() } /*读为什么需要加互斥锁,按理说10秒数上面的协程都应该执行完,后面就不应该出现资源竞争的问题了,但是在实际运行中,还是可能 出现资源竞争,因为我们程序从设计上可以知道10秒就执行完所有协程,但是主线程并不知道,因此底层可能仍然出现资源真多,因此 加入互斥锁即可解决问题。*/
结果:
map[10]=3628800.000000 map[35]=10333147966386144222209170348167175077888.000000 map[34]=295232799039604119555149671006000381952.000000 map[49]=608281864034267522488601608116731623168777542102418391010639872.000000 map[80]=71569457046263778832073404098641551692451427821500630228331524401978643519022131505852398484420816675798776564959674368.000000 map[124]=150614174151114036108297093562510697..... map[6]=720.000000
为什么需要channel
1) 前面使用了全局变量加锁同步来解决goroutine的通讯,但不完美
2) 主线程在等待所有 goroutine 全部完成的时间很难确定,我们这里设置了10秒,仅仅是估算
3) 如果主线程休眠时间长了,会加长等待时间,如果等待时间短了,可能还有 goroutine 处于工作状态,这时也会随主线程的退出而销毁
4) 通过全局变量加锁同步来实现通讯,也并不利于多个协程对全部变量的读写操作。
5) 上面种种分析都在呼唤一个新的通讯机制 - channel
channel 的基本介绍
1) channel 本质就是一个数据结构-队列
2) 数据是先进先出【FIFO:first in first out】
3) 线程安全,多 goroutine 访问时,不需要加锁,就是说channel 本身就是线程安全的
4) channel 有类型的,一个 string 的 channel 只能存放 string 类型的数据
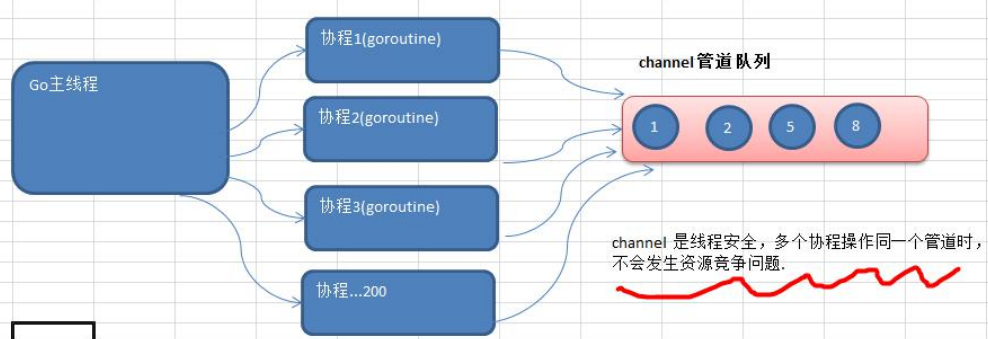
var 变量名 chan 数据类型
举例:
var intChan chan int (intChan 用于存放 int 数据)
var mapChan chan map[int]string (mapChan 用于存放 map[int]string类型)
var perChan chan Person
var perChan2 chan *Person
说明:
channel 是引用类型
channel 必须初始化才能写入数据,即 make后才能使用
package main
import "fmt"
func main() {
var intChan chan int
intChan = make(chan int,3)
fmt.Printf("intChan的值 %v, intChan本身的地址 %p\n",intChan,&intChan)
//向管道写入数据,写入的数据不能超过管道的容量
intChan<- 10
num :=20
intChan<- num
intChan<- 50
fmt.Printf("channel len=%v cap=%v \n",len(intChan),cap(intChan))
//向管道中读取数据,在没有使用协程的情况下,如果我们的管道数据已经全部取出,再取就会报告 deadlock
num2 := <-intChan
fmt.Printf("num2=%v\n",num2)
fmt.Printf("channel len=%v cap=%v \n",len(intChan),cap(intChan))
num3 :=<-intChan
num4 :=<-intChan
fmt.Println("num3=",num3,"num4=",num4)
}
结果:
intChan的值 0xc000104000, intChan本身的地址 0xc000006028 channel len=3 cap=3 num2=10 channel len=2 cap=3 num3= 20 num4= 50
channel(管道)-使用注意事项
1.channel中只能存放指定的数据类型
2.channel的数据放满后,就不能再放入了
3.如果从channel取出数据后,可以继续放入
4.在没有使用协程的情况下,如果channel数据取完了,再取,就会报 dead lock
创建一个mapChan,最多可以存放10个map[string]string的key-val
package main import "fmt" func main() { var mapChan chan map[string]string mapChan = make(chan map[string]string,10) m1 :=make(map[string]string,20) m1["city1"] = "北京" m1["city2"] = "天津" m2 :=make(map[string]string,20) m2["hero1"] = "宋江" m2["hero2"] = "武松" mapChan<-m1 mapChan<-m2 fmt.Printf("mapChan len=%v , cap=%v",len(mapChan),cap(mapChan)) //mapChan len=2 , cap=10 }
创建一个catChan,最多可以存放10个cat结构体变量
package main import "fmt" type cat struct { Name string Age int } func main() { var catChan chan cat catChan = make(chan cat,10) cat1 := cat{"tome~",18} cat2 := cat{"many",30} //放入到管道 catChan<- cat1 catChan<- cat2 //从管道取出 qcat1 :=<-catChan qcat2 :=<-catChan fmt.Println(qcat1,qcat2) }
创建一个catChan2,最多可以存放10个*cat结构体变量
package main import "fmt" type cat struct { Name string Age int } func main() { var catChan2 chan *cat catChan2 = make(chan *cat,10) cat1 := cat{"tome~",18} cat2 := cat{"many",30} //放入到管道 catChan2<- &cat1 catChan2<- &cat2 //从管道取出 qcat1 :=<-catChan2 qcat2 :=<-catChan2 fmt.Println(qcat1,qcat2) }
创建一个allChan,最多可以存放10个 任意数据类型变量
package main import "fmt" type cat struct { Name string Age int } func main() { var allChan chan interface{} allChan = make(chan interface{},10) cat1 := cat{"tom",20} cat2 := cat{"tix",30} allChan<- cat1 allChan<- cat2 allChan<- "jack" allChan<- 30 qcat1 :=<-allChan qcat2 :=<-allChan v1:=<-allChan v2:=<-allChan fmt.Println(qcat1,qcat2,v1,v2) //{tom 20} {tix 30} jack 30 }
空接口类型的数据必须使用类型断言
package main import "fmt" type Cat struct { Name string Age int } func main() { allChan := make(chan interface{},10) allChan<- 10 allChan<- "tome jack" cat :=Cat{"小花猫",4} allChan<-cat //取第三个,丢弃前两个 <-allChan <-allChan vcat := <-allChan fmt.Printf("vcat=%T,vcat=%v\n",vcat,vcat) //vcat=main.Cat,vcat={小花猫 4} //fmt.Printf("vcat.name=%v",vcat.Name) 错误的 空接口类型必须使用类型断言 a:=vcat.(Cat) fmt.Printf("vcat.name=%v",a.Name)//vcat.name=小花猫 }
channel 的关闭
使用内置函数close可以关闭channel,当channel关闭后,就不能再向channel写数据了,但是仍然可以从该channel读数据
channel 的遍历
channel支持for-range的方式进行遍历,请注意两个细节
1) 在遍历时,如果channel没有关闭,则回出现deadlock的错误
package main import "fmt" func main() { allChan := make(chan int,3) allChan<- 10 allChan<-20 close(allChan) //allChan<-30 //报错,不能向关闭的通道写入数据 n1 :=<-allChan //读取关闭的通道数据是没问题的 fmt.Println(n1) }
2) 在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历
package main
import "fmt"
func main() {
intChan := make(chan int,100)
for i:=1;i<=100;i++{
intChan<- i*2 //放入100个数据
}
//遍历管道不能使用普通的 for 循环
//for i:=0;i<=len(intChan);i++{
//}
close(intChan) //不关闭管道会报 deadlock 错误
for v:=range intChan{
fmt.Println(v)
}
fmt.Printf("intChan len=%v,cap=%v",len(intChan),cap(intChan))//intChan len=0,cap=100 遍历也就取出了管道里面的数据
}
1.开启一个writeData协程,向管道intChan中写入50个整数
2.开启一个readData协程,从管道intChan中读取writeData写入的数据
3.注意:writeData和readData操作的是同一个管道
4.主线程需要等待writeData和readData协程都完成工作才能退出
package main import ( "fmt" "time" ) //writeData func writeData(intChan chan int) { for i:=1;i<=50;i++{ intChan<-i fmt.Println("writeData 写入数据",i) time.Sleep(time.Second) } close(intChan) //x, ok := <-c 还会将ok置为false。 } //readData func readData(intChan chan int,exitChan chan bool) { for{ v,ok:=<-intChan //会阻塞 if !ok{ //intChan 管道被close 才会退出 break } fmt.Printf("readData 读到数据=%v\n",v) } //readDate 读取完数据后,即任务完成 exitChan<-true close(exitChan) } func main() { intChan :=make(chan int,50) exitChan :=make(chan bool,1) go writeData(intChan) go readData(intChan,exitChan) for{ _,ok :=<-exitChan if !ok{ break } } fmt.Println("main 线程结束") }
channel 阻塞
1.协程写入管道,超过了容量,如果发现有协程在读,会阻塞,如果没有发现协程在读,会死锁deadlock,读写频率不一致没关系。
要求统计1-80000的数字中,那些是素数?
分析:
1.传统方法,就是使用一个循环,循环的判断各个数是不是素数
2.使用并发/并行的方式,将统计的素数任务分配给多个goroutine去完成,完成任务时间短
package main import ( "fmt" "time" ) //向intChan放入1-8000个数 func putNum(intChan chan int) { for i:=1;i<=8000;i++{ intChan<-i } close(intChan) } //放入素数 func prineNum(intChan chan int,prineChan chan int,exitChan chan bool) { var flag bool for{ //time.Sleep(time.Millisecond*10) num,ok:= <-intChan if !ok{//取到了结束标识符 break } flag = true //假设是素数 for i:=2;i<num;i++{ if num % i == 0{//说明不是素数 flag = false } } if flag{ prineChan <- num } } fmt.Println("有一个prineNum结束") //自己结束,写入结束标志 exitChan<- true } func main() { intChan :=make(chan int,1000) prineChan :=make(chan int,2000)//放入结果 exitChan :=make(chan bool,4)//协程完成的标识 start :=time.Now().Unix() go putNum(intChan) for i:=1;i<=4;i++ { go prineNum(intChan,prineChan,exitChan) } go func() { for i:=1;i<=4;i++{ <-exitChan //取不到会阻塞 } end :=time.Now().Unix() fmt.Println("使用协程所用的时间",end-start) //当我们从 exitChan取出了4个值 就可以关闭prineChan了 close(prineChan) }() for{ res,ok := <-prineChan if !ok{ break } fmt.Printf("素数为=%d\n",res) } /*for v:=range prineChan{ fmt.Printf("素数为=%d\n",v) }*/ fmt.Println("主线程退出") }
1) channel 可以声明为只读,或者只写性质 (默认情况下,管道为双向管道,可读也可写)
package main import "fmt" func main() { //1.声明为只写 var chan1 chan<- int chan1 = make(chan int,3) chan1<- 20 //写 fmt.Println("chan1 = ",chan1) //2.声明为只读 var chan2 <-chan int chan2 = make(chan int,3) num2 :=<-chan2 //读 fmt.Println("num2 = ",num2) }
如果把双向通道传值给形参(只读通道),相当于把双向通道的读,封闭了
time包中的通道相关函数
主要就是定时器,标准库中的Timer让用户可以定义自己的超时逻辑,尤其是在应对select处理多个channel的超时、单channel读写的超时等情形时尤为方便。
Timer是一次性的时间触发事件,这点与Ticker不同,Ticker是按一定时间间隔持续触发时间事件。
Timer常见的创建方式:
t:= time.NewTimer(d) t:= time.AfterFunc(d, f) c:= time.After(d)
虽然说创建方式不同,但是原理是相同的。
Timer有3个要素:
定时时间:就是那个d
触发动作:就是那个f
时间channel: 也就是t.C
time.NewTimer()
NewTimer()创建一个新的计时器,该计时器将在其通道上至少持续d之后发送当前时间。它的返回值是一个Timer。
通过源代码我们可以看出,首先创建一个channel,关联的类型为Time,然后创建了一个Timer并返回。
- 用于在指定的Duration类型时间后调用函数或计算表达式。
- 如果只是想指定时间之后执行,使用time.Sleep()
- 使用NewTimer(),可以返回的Timer类型在计时器到期之前,取消该计时器
- 直到使用<-timer.C发送一个值,该计时器才会过期
package main import ( "fmt" "time" ) func main() { /* 1.func NewTimer(d Duration) *Timer 创建一个计时器:d时间以后触发,go触发计时器的方法比较特别,就是在计时器的channel中发送值 */ //新建一个计时器:timer timer := time.NewTimer(3 * time.Second) fmt.Printf("%T\n", timer) //*time.Timer fmt.Println(time.Now()) //2019-08-15 10:41:21.800768 +0800 CST m=+0.000461190 //此处在等待channel中的信号,执行此段代码时会阻塞3秒 ch2 := timer.C //<-chan time.Time fmt.Println(<-ch2) //2019-08-15 10:41:24.803471 +0800 CST m=+3.003225965 }
结果:
*time.Timer 2022-04-01 10:02:28.9274932 +0800 CST m=+0.000996601 2022-04-01 10:02:31.9275217 +0800 CST m=+3.001025101
timer.Stop (计时器停止)
示例代码:
package main import ( "fmt" "time" ) func main() { //新建计时器,一秒后触发 timer2 := time.NewTimer(5 * time.Second) //新开启一个线程来处理触发后的事件 go func() { //等触发时的信号 <-timer2.C fmt.Println("Timer 2 结束。。") }() //由于上面的等待信号是在新线程中,所以代码会继续往下执行,停掉计时器 time.Sleep(3*time.Second) stop := timer2.Stop() if stop { fmt.Println("Timer 2 停止。。") } }
结果:Timer 2 停止。。
time.After()
在等待持续时间之后,然后在返回的通道上发送当前时间。它相当于NewTimer(d).C。在计时器触发之前,垃圾收集器不会恢复底层计时器。如果效率有问题,使用NewTimer代替,并调用Timer。如果不再需要计时器,请停止。
示例代码:
package main import ( "fmt" "time" ) func main() { /* func After(d Duration) <-chan Time 返回一个通道:chan,存储的是d时间间隔后的当前时间。 */ ch1 := time.After(3 * time.Second) //3s后 fmt.Printf("%T\n", ch1) // <-chan time.Time fmt.Println(time.Now()) //2019-08-15 09:56:41.529883 +0800 CST m=+0.000465158 time2 := <-ch1 fmt.Println(time2) //2019-08-15 09:56:44.532047 +0800 CST m=+3.002662179 }
select语句
select 是 Go 中的一个控制结构。select 语句类似于 switch 语句,但是select会随机执行一个可运行的case。如果没有case可运行,它将阻塞,直到有case可运行。
select语句的语法结构和switch语句很相似,也有case语句和default语句:
select { case communication clause : statement(s); case communication clause : statement(s); /* 你可以定义任意数量的 case */ default : /* 可选 */ statement(s); }
说明:
- 每个case都必须是一个通信
- 所有channel表达式都会被求值
- 所有被发送的表达式都会被求值
- 如果有多个case都可以运行,select会随机公平地选出一个执行。其他不会执行。
- 否则:
如果有default子句,则执行该语句。
如果没有default字句,select将阻塞,直到某个通信可以运行;Go不会重新对channel或值进行求值。
示例代码:
package main import ( "fmt" "time" ) func main() { /* 分支语句:if,switch,select select 语句类似于 switch 语句, 但是select会随机执行一个可运行的case。 如果没有case可运行,它将阻塞,直到有case可运行。 */ ch1 := make(chan int) ch2 := make(chan int) go func() { time.Sleep(2 * time.Second) ch2 <- 200 }() go func() { time.Sleep(2 * time.Second) ch1 <- 100 }() select { case num1 := <-ch1: fmt.Println("ch1中取数据。。", num1) case num2, ok := <-ch2: if ok { fmt.Println("ch2中取数据。。", num2) }else{ fmt.Println("ch2通道已经关闭。。") } } }
运行结果:可能执行第一个case,打印100,也可能执行第二个case,打印200。(多运行几次,结果就不同了)
2) 使用 select 可以解决从管道取数据的阻塞问题
package main import ( "fmt" "time" ) func main() { intChan :=make(chan int,10) for i:=1;i<=10;i++{ intChan<-i } strChan :=make(chan string,5) for i:=1;i<=5;i++{ strChan<-"hello"+fmt.Sprintf("%d",i) } //传统的方法在遍历管道时,如果不关闭会阻塞而导致 deadlock //在实际开发中,可能我们不好确定什么时候关闭该管道 for{ select { //注意:这里,如果intChan一直没有关闭,不会一直阻塞而deadlock //会自动到下一个case匹配 case v:=<-intChan : fmt.Printf("从intChan读取数据%d\n",v) time.Sleep(time.Second) case v:=<-strChan: fmt.Printf("从strChan读取数据%s\n",v) time.Sleep(time.Second) default: fmt.Printf("都取不到了,程序员可以加入自己的逻辑\n") return } } }
3) goroutine中使用recover,解决协程中出现panic,导致程序崩溃问题
说明:如果我们起了一个协程,但是这个协程出现了panic 如果我们没有
捕获这个panic,就会造成整个程序崩溃,这时我们可以在goroutine中使用
recover来捕获panic 进行处理,这样即使这个协程发生了问题,但是主线程
仍然不受影响,可以继续执行。
package main import ( "fmt" "time" ) func sayHello() { for i:=0;i<10;i++{ time.Sleep(time.Second) fmt.Println("hello,world") } } func test() { //错误处理 defer func() { if err:=recover();err !=nil{ fmt.Println("test 发生了错误=",err) } }() var myMap map[int]string myMap[0] = "golang" //错误的没有make } func main() { go sayHello() go test() for i:=0;i<10;i++{ time.Sleep(time.Second) fmt.Println("main() ok~") } }
二十七.反射
基本介绍
1) 反射可以在运行时动态获取变量的各种信息,比如变量的类型(type),类别(kind)
2) 如果是结构体变量,还可以获取到结构体本身的信息(包括结构体的字段,方法)
3) 通过反射,可以修改变量的值,可以调用关联的方法
4) 使用反射,需要import("reflect")
package reflect
reflect包实现了运行时反射,允许程序操作任意类型的对象。典型用法是用静态类型interface{}保存一个值,通过调用TypeOf获取其动态类型信息,该函数返回一个Type类型值。
调用ValueOf函数返回一个Value类型值,该值代表运行时的数据。Zero接受一个Type类型参数并返回一个代表该类型零值的Value类型值。
1) reflect.TypeOf(变量名),获取变量的类型,返回reflect.Type类型
2) reflect.ValueOf(变量名),获取变量的值,返回reflect.Value类型reflect.Value 是一个结构体类型[文档],通过reflect.Value 可以获取到
关于该变量的很多信息。
3) 变量,interface{}和 reflect.Value 是可以相互转换的,这点在实际开发中,会经常使用到 (reflect.Value转换为空接口类型用函数:func (v Value) Interface() (i interface{}) 再转换为具体类型用 类型断言)

基本数据类型 interface{} reflect.Value 进行反射的基本操作
package main import ( "fmt" "reflect" ) func reflectTest01(b interface{}) { //通过反射获取传入的变量的 type kind 值 rType := reflect.TypeOf(b) fmt.Printf("rType=%v, type=%T\n",rType,rType) //rType=int, type=*reflect.rtype rVal :=reflect.ValueOf(b) fmt.Printf("rVal=%v, type=%T\n",rVal,rVal) //rVal=100, type=reflect.Value n1 :=10 n2 := n1 + int(rVal.Int())//转换为真正的值,返回的是int64 需要转换一下 fmt.Println("n1+n2的结果:",n2) //n1+n2的结果: 110 //将rVal转换为 interface{} iv := rVal.Interface() num2 :=iv.(int)//类型断言 fmt.Println("num2=",num2) fmt.Println(num2+20)//为int类型可以直接相加 } func main() { //基本类型 var num int = 100 reflectTest01(num) }
结构体类型 interface{} reflect.Value 进行反射的基本操作
package main import ( "fmt" "reflect" ) func reflectTest02(b interface{}) { //1.获取reflect.Type rType := reflect.TypeOf(b) fmt.Printf("rType=%v, type=%T\n",rType,rType) //rType=main.Student, type=*reflect.rtype //2.获取reflect.Value rVal :=reflect.ValueOf(b) fmt.Printf("rVal=%v, type=%T\n",rVal,rVal) //rVal={tom 20}, type=reflect.Value //3.获取 变量对应的kind kind := rVal.Kind()//或者 rType.Kind() fmt.Printf("kind=%v, type=%T\n",kind,kind) //kind=struct, type=reflect.Kind //将rVal转换为 interface{} iv := rVal.Interface() fmt.Printf("iv = %v iv type = %T\n",iv,iv)//iv = {tom 20} iv type = main.Student stu,ok :=iv.(Student)//类型断言 多个可以用 switch if ok{ fmt.Println("stu.Name",stu.Name)//stu.Name tom } } type Student struct { Name string Age int } func main() { //结构体 stu :=Student{"tom",20} reflectTest02(stu) }
1) reflect.Value.Kind,获取变量类别,返回的是一个常量[手册]
Kind代表Type类型值表示的具体分类。零值表示非法分类。

2) Type是类型,Kind是类别,Type和kind可能相同的,也可能是不同的。
比如:var num int = 10 num的Type是int,kind也是int
比如:var stu Student stu的Type是 包名.Student,kind是struct
3) 通过反射可以在让变量在 interface{} 和 Reflect.Value 之间相互转换
4) 使用反射的方式来获取变量的值(并返回对应的类型),要求数据类型匹配,比如x是int,那么就应该使用reflect.Value.Int(),而不能使用其他的,否则panic

5) 通过反射的来修改变量,注意当使用SetXxx 方法来设置需要通过对应的指针类型来完成,这样才能改变传入的变量的值,
同时需要使用到reflect.Value.Elem()方法
package main import ( "fmt" "reflect" ) func reflect01(b interface{}) { //2.获取reflect.Value rVal :=reflect.ValueOf(b) fmt.Println("rVal kind=",rVal.Kind()) //rVal kind= ptr 是一个指针 //Elem返回v持有的接口保管的值的Value封装,或者v持有的指针指向的值的Value封装。 //如果v的Kind不是Interface或Ptr会panic;如果v持有的值为nil,会返回Value零值。 rVal.Elem().SetInt(20) } func main() { num := 10 reflect01(&num) fmt.Println(num) }

该方法Method 方法的排序是按照方法第一个字母的 ASCII码 排序的

1) 使用反射来遍历结构体的字段,调用结构体的方法,并获取结构体标签的值
package main import ( "fmt" "reflect" ) //定义了一个 Monster 结构体 type Monster struct { Name string `json:"name"` Age int `json:"monster_age"` Score float32 `json:"成绩"` Sex string } //方法,返回两个数的和 func (s Monster) GetSum(n1, n2 int) int { return n1 + n2 } //方法, 接收四个值,给 s 赋值 func (s Monster) Set(name string, age int, score float32, sex string) { s.Name = name s.Age = age s.Score = score s.Sex = sex } //方法,显示 s 的值 func (s Monster) Print() { fmt.Println("---start~----") fmt.Println(s) fmt.Println("---end~----") } func TestStruct(a interface{}) { //获取 reflect.Type 类型 typ := reflect.TypeOf(a) //获取 reflect.Value 类型 val := reflect.ValueOf(a) //获取到 a 对应的类别 kd := val.Kind() //如果传入的不是 struct,就退出 if kd != reflect.Struct { fmt.Println("expect struct") return } //获取到该结构体有几个字段 num := val.NumField() fmt.Printf("struct has %d fields\n", num) //4 // 变量结构体的所有字段 for i := 0; i < num; i++ { fmt.Printf("Field %d: 值为=%v\n", i, val.Field(i)) //获取到 struct 标签, 注意需要通过 reflect.Type 来获取 tag 标签的值 tagVal := typ.Field(i).Tag.Get("json") // 如果该字段于 tag 标签就显示,否则就不显示 if tagVal != "" { fmt.Printf("Field %d: tag 为=%v\n", i, tagVal) } } //获取到该结构体有多少个方法 numOfMethod := val.NumMethod() fmt.Printf("struct has %d methods\n", numOfMethod) //方法的排序默认是按照 函数名的排序(ASCII 码) val.Method(1).Call(nil) //获取到第二个方法。调用它 //调用结构体的第 1 个方法 Method(0) var params []reflect.Value //声明了 []reflect.Value params = append(params, reflect.ValueOf(10)) params = append(params, reflect.ValueOf(40)) res := val.Method(0).Call(params) //传入的参数是 []reflect.Value, 返回[]reflect.Value fmt.Println("res=", res[0].Int()) //返回结果, 返回的结果是 []reflect.Value*/ } func main() { //创建了一个 Monster 实例 var a Monster = Monster{Name: "黄鼠狼精", Age: 400, Score: 30.8, Sex: "母的"} //将 Monster 实例传递给 TestStruct 函数 TestStruct(a) }