在上一篇文章《分布式系统的构建原则》中总结了分布式系统的几个原则,扩展性是其中非常重要的一个原则,而对于扩展性则是我们工程团队多年以来不懈的追求,所以,我们单独展开,写一写有关扩展性的内容。
在各种不同的领域中,深耕的组织和团队都不约而同的尝试、发现和总结软件架构模式,最后都相似的得出共同的软件架构特征,大家都希望系统更健壮、具有适应能力、更好的满足现代化的需求。
而这些特征其实背后无疑都指向一个共同的非常重要的实现原则,扩展性!
扩展性从不同的角度大致可以分为 功能扩展性 和 性能扩展性 ,
功能扩展,
- 系统是否能方便灵活的增加新功能,或者新的实现,能让你的系统更快的响应需求的变化,大神们在实践中总结出来的各种设计模式基本上都是为了解决这个问题,响应变化;
- 功能之间松耦合,非强依赖,有一定的容错和降级能力,组件相互隔离,失败的扩散控制的组件内部,能够独立恢复,保证部分失败,不会阻断系统的可用性。
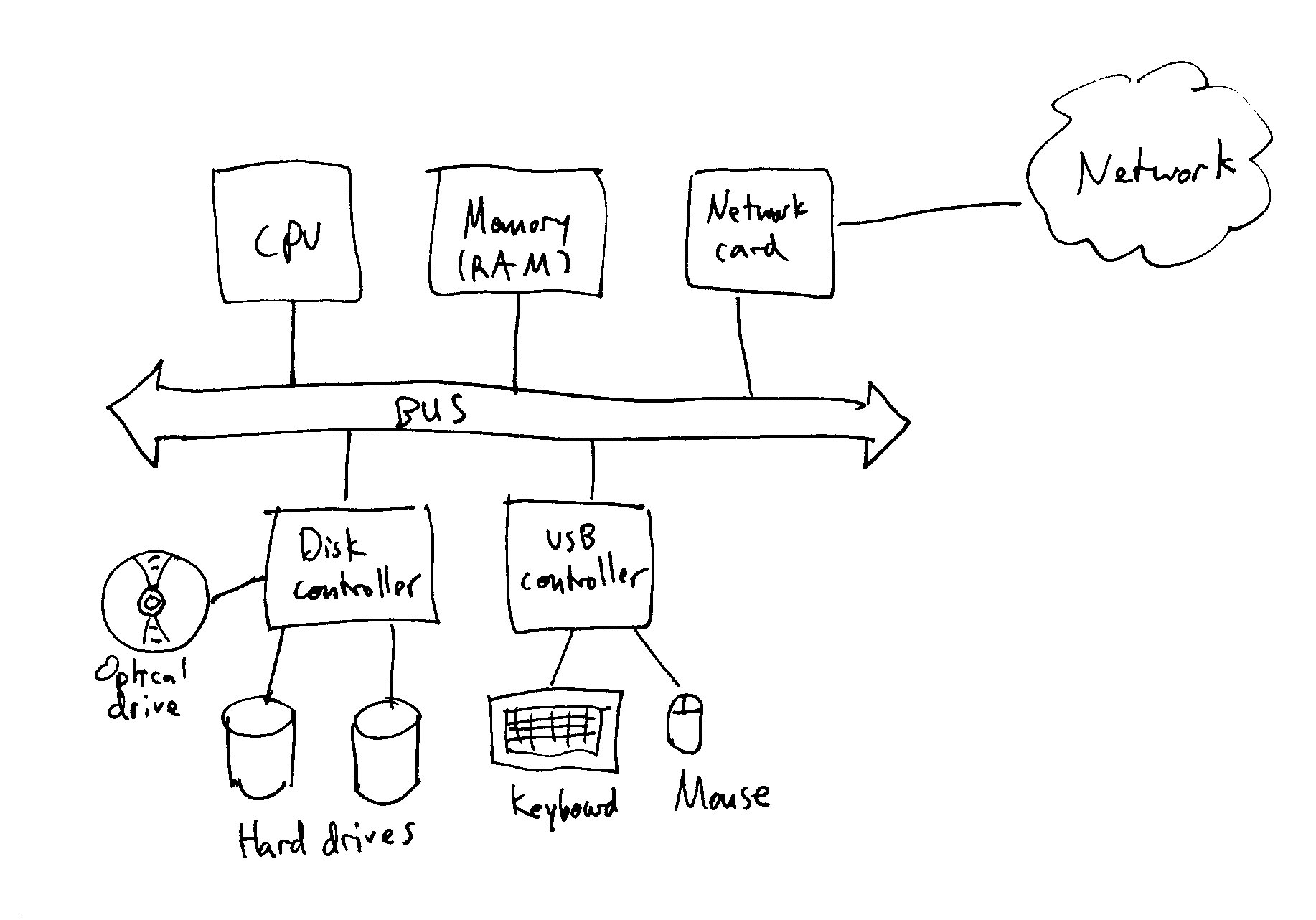
其实回头想想,计算机,操作系统在这方面设计和抽象的非常有远见,冯诺依曼对计算机抽象的5个部分,相对都能做到独立工作、独立扩展、独立恢复,例如现代化的Internet、USB、Type-C等都是被兼容的设备,大家都属于input/output,而在大部分情况下,一些扩展的设备发生故障,整个计算机还是可以继续工作。
冯诺依曼1945年的论文《First Draft of a Report on the EDVAC》提出的计算机架构,能够适应上百年甚至更久,不得不说这是一种伟大的设计!
假如你可能要问,如果CPU坏了呢,计算机还能工作吗?
你可以试想一下,想象一台更大的计算机,某个CPU组成的计算机可能是整个大型计算机的一个input或者output呢?
性能扩展,
当今,流量红利爆发,特别是To C的系统,上线后,性能往往会成为公司和开发团队关注的焦点。
功能方面能不能方便扩展,追的上需求的发展,是工程团队首要考虑的,而上线以后能不能扛得住流量的考验则是老板和投资人比较关注的,
那我们来讨论一下如何提升系统的吞吐量,保证SLA。
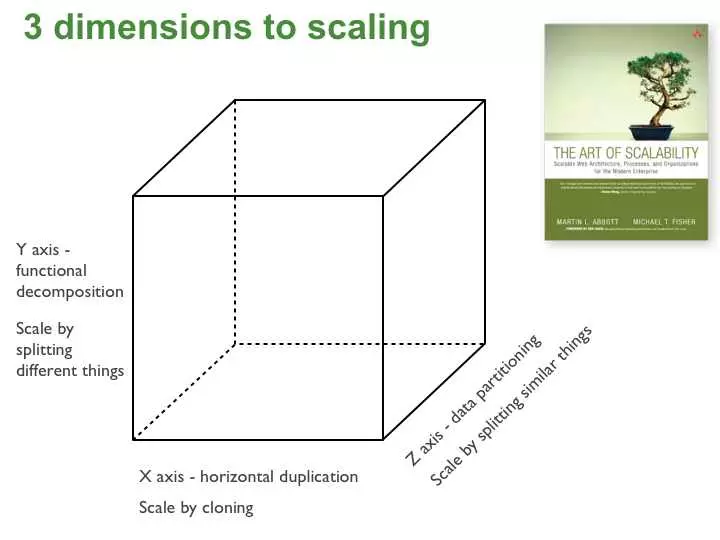
在负载均衡下部署多个系统实例,运行多个程序副本,是扩展性能最直接的办法,《The Art of Scalability》中文名《架构即未来》一书中谈到扩展模型,包括X-axis、Y-axis、Z-axis三个纬度进行扩展,提升系统的吞吐量,而多实例这个方法被称为是横向扩展,即:X-axis。
这个模型叫做扩展立方体(Scale Cube),比较符合微服务盛行的当下,让扩展更具有针对性。
X-axis scaling
由多个程序副本同时运行,组成一个集群,由负载均衡统一调度分配流量,例如,一个系统由N个副本同时工作,那每个副本处理的流量为 1/N,在扩展性方面,这是一个简单,有效的方案,我们通常称为横向扩展,或者水平扩展。
简单的办法,往往会损失一些细节和灵活性,总结下来有三个缺点,
- 无法局部扩展,每个系统副本有相同的要求,这就需要我们投入更多的资源,每个系统需要配比相同的配置,包括服务器和数据库等;
- 无法局部恢复、问题修复代价比较大,需要更新所有系统副本,会造成一定几率的服务不可用;
- 系统的复杂性没有解决,其实就是康威定律,随着系统不断的开发,系统的复杂性也会不断的升高,增加CICD的难度,和部署周期。
Y-axis scaling
水平扩展是整个系统多副本运行,平分流量从而提升整体性能,而Y-axis扩展是对这个服务进行拆分,让一个大的系统裂变为多个小服务,独立部署,让扩展更具针对性。
拆分的指导思想是把职责相关的功能拆分为一个服务,类似单一职责原则,一般有基于动词和基于名词俩种拆分方法,例如上传文件服务是基于动词拆分出来的服务,用户管理则是基于名词的拆分。
这样一来,水平扩展的几个问题都被解决了,结合X-axis,可以局部扩展,局部更新。
其实,这就是微服务。
Z-axis scaling
上面俩个都是基于服务级别的扩展,它们可能面临同一个问题,却无法通过以上俩种扩展方案去解决,是服务所依赖的数据库的性能问题。
所以,Z-axis就派上用场了,数据分区。
如果说Y-axis是对服务的职责单一化,那Z-axis是对数据库的职责单一化,部署多个数据库服务,在业务层,也就是服务层,对这些数据库进行逻辑分类使用,例如,VIP用户和普通用户使用不同的数据库,不同地区的用户数据存储在不同的数据库等等,分散存储,以减轻数据库的压力。
如果需要查询或者排序的话,就需要访问所有数据库,得到聚合结果,然后在服务层做合并处理。
注意,数据拆分会增加系统的复杂度,事务和数据迁移或从新分配都是比较棘手的问题,当然,我们可以借助一些成熟的方案甚至数据库系统来化解,但要求我们深谙数据拆分之道。
其实,这就是分库分表,或者分布式数据库的应用场景。
小结
扩展立方体,给我们扩展系统提供了思路,需要我们根据自己系统的实际架构和压力情况来衡量并制定合适的扩展方案,并不是X、Y、Z都要用上。
再者,这个模型也是宏观指导,影响一个系统的性能包括CPU、内存、IO(网络、磁盘)等诸多因素,需要我们像个老中医一样,通过望闻问切等多种手段,定位系统性能瓶颈,然后采取有效的扩展措施,例如,如果一个系统是网络IO密集型,瓶颈在于基础设施网络,这种情况下,你如何扩展也起不到效果,可能需要
的是升级硬件、提高网络利用率、压缩input、output、采用异步流传输、缩短调用链、改变交互方式(响应式、异步、非阻塞)等措施,才能真正解决痛点。
但如果是一个大型系统,面临性能问题,按照Scale Cube模型,整体扩展思路总结一下大概是,先垂直拆分、后水平扩展,包括服务拆分,数据库拆分,拆分原则是职责单一,用动词或名词拆分法,然后对服务和数据库根据压力情况,适当的水平扩展。