首先我们找到网站的url = "https://maoyan.com/films/1211270",找到评论区看看网友的吐槽,如下
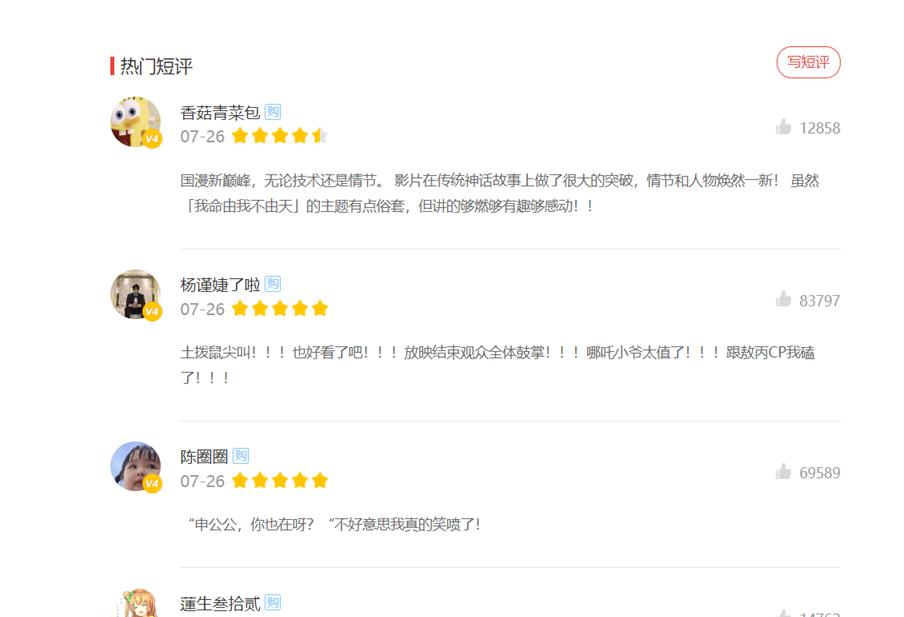
F12打开看看有没有评论信息,我们发现还是有信息的。
但是现在的问题时,我们好像只有这几条评论信息,完全不支持我们的分析呀,我们只能另谋出路了;

f12中由手机测试功能,打开刷新页面,向下滚动看见查看好几十万的评论数据,点击进入后,在network中会看见url = "http://m.maoyan.com/review/v2/comments.json?movieId=1211270&userId=-1&offset=15&limit=15&ts=1568600356382&type=3" api,有这个的时候我们就可以搞事情了。
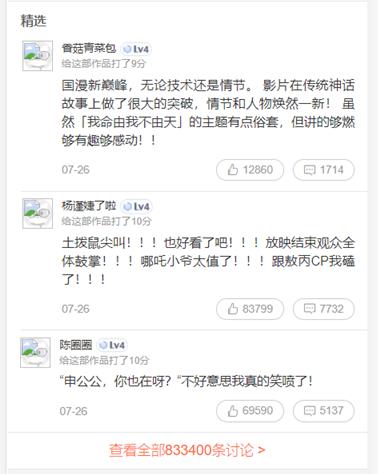

但是随着爬取,还是不能获取完整的信息,百度、谷歌、必应一下,我们通过时间段获取信息,这样我们不会被猫眼给墙掉,所以我们使用该url="http://m.maoyan.com/mmdb/comments/movie/1211270.json?_v_=yes&offset=0&startTime="
效果如下:
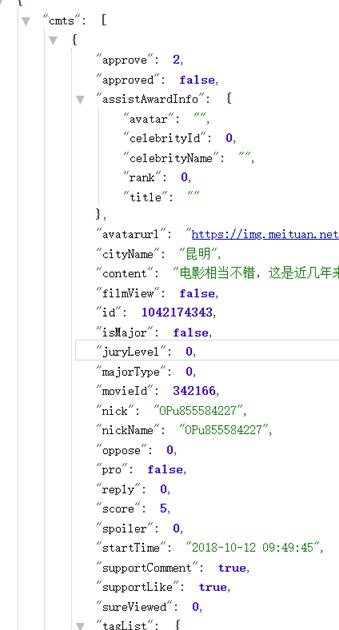
开始构造爬虫代码:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # author:albert time:2019/9/3 4 import requests,json,time,csv 5 from fake_useragent import UserAgent #获取userAgent 6 from datetime import datetime,timedelta 7 8 def get_content(url): 9 '''获取api信息的网页源代码''' 10 ua = UserAgent().random 11 try: 12 data = requests.get(url,headers={'User-Agent':ua},timeout=3 ).text 13 return data 14 except: 15 pass 16 17 def Process_data(html): 18 '''对数据内容的获取''' 19 data_set_list = [] 20 #json格式化 21 data_list = json.loads(html)['cmts'] 22 for data in data_list: 23 data_set = [data['id'],data['nickName'],data['userLevel'],data['cityName'],data['content'],data['score'],data['startTime']] 24 data_set_list.append(data_set) 25 return data_set_list 26 27 if __name__ == '__main__': 28 start_time = start_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 获取当前时间,从当前时间向前获取 29 # print(start_time) 30 end_time = '2019-07-26 08:00:00' 31 32 # print(end_time) 33 while start_time > str(end_time): 34 #构造url 35 url = 'http://m.maoyan.com/mmdb/comments/movie/1211270.json?_v_=yes&offset=0&startTime=' + start_time.replace( 36 ' ', '%20') 37 print('........') 38 try: 39 html = get_content(url) 40 except Exception as e: 41 time.sleep(0.5) 42 html = get_content(url) 43 else: 44 time.sleep(1) 45 comments = Process_data(html) 46 # print(comments[14][-1]) 47 if comments: 48 start_time = comments[14][-1] 49 start_time = datetime.strptime(start_time, '%Y-%m-%d %H:%M:%S') + timedelta(seconds=-1) 50 # print(start_time) 51 start_time = datetime.strftime(start_time,'%Y-%m-%d %H:%M:%S') 52 print(comments) 53 #保存数据为csv 54 with open("comments_1.csv", "a", encoding='utf-8',newline='') as csvfile: 55 writer = csv.writer(csvfile) 56 writer.writerows(comments) 57
-----------------------------------数据分析部分-----------------------------------
我们手里有接近两万的数据后开始进行数据分析阶段:
工具:jupyter、库方法:pyecharts v1.0===> pyecharts 库向下不兼容,所以我们需要使用新的方式(链式结构)实现:
我们先来分析一下哪吒的等级星图,使用pandas 实现分组求和,正对1-5星的数据:
1 from pyecharts import options as opts 2 from pyecharts.globals import SymbolType 3 from pyecharts.charts import Bar,Pie,Page,WordCloud 4 from pyecharts.globals import ThemeType,SymbolType 5 import numpy 6 import pandas as pd 7 8 df = pd.read_csv('comments_1.csv',names=["id","nickName","userLevel","cityName","score","startTime"]) 9 attr = ["一星", "二星", "三星", "四星", "五星"] 10 score = df.groupby("score").size() # 分组求和 11 value = [ 12 score.iloc[0] + score.iloc[1]+score.iloc[1], 13 score.iloc[3] + score.iloc[4], 14 score.iloc[5] + score.iloc[6], 15 score.iloc[7] + score.iloc[8], 16 score.iloc[9] + score.iloc[10], 17 ] 18 # 饼图分析 19 # 暂时处理,不能直接调用value中的数据 20 attr = ["一星", "二星", "三星", "四星", "五星"] 21 value = [286, 43, 175, 764, 10101] 22 23 pie = ( 24 Pie(init_opts=opts.InitOpts(theme=ThemeType.LIGHT)) 25 .add('',[list(z) for z in zip(attr, value)]) 26 .set_global_opts(title_opts=opts.TitleOpts(title='哪吒等级分析')) 27 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}")) 28 ) 29 pie.render_notebook()
实现效果: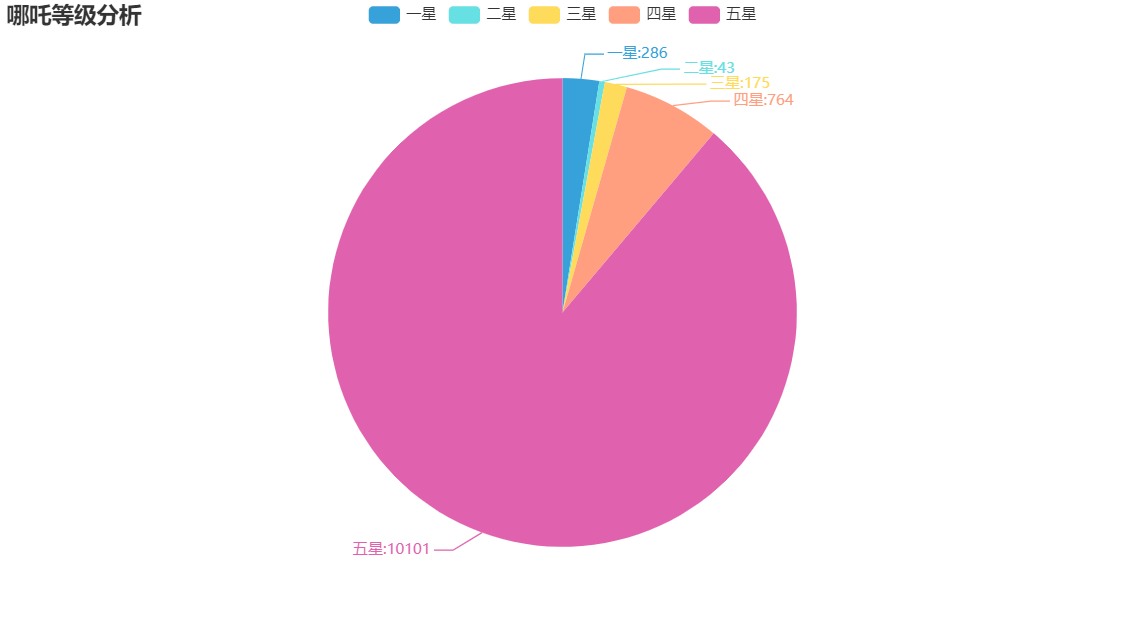
然后进行词云分析:
1 import jieba 2 import matplotlib.pyplot as plt #生成图形 3 from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator 4 5 df = pd.read_csv("comments_1.csv",names =["id","nickName","userLevel","cityName","content","score","startTime"]) 6 7 comments = df["content"].tolist() 8 # comments 9 df 10 11 # 设置分词 12 comment_after_split = jieba.cut(str(comments), cut_all=False) # 非全模式分词,cut_all=false 13 words = " ".join(comment_after_split) # 以空格进行拼接 14 15 stopwords = STOPWORDS.copy() 16 stopwords.update({"电影","最后","就是","不过","这个","一个","感觉","这部","虽然","不是","真的","觉得","还是","但是"}) 17 18 bg_image = plt.imread('bg.jpg') 19 #生成 20 wc=WordCloud( 21 width=1024, 22 height=768, 23 background_color="white", 24 max_words=200, 25 mask=bg_image, #设置图片的背景 26 stopwords=stopwords, 27 max_font_size=200, 28 random_state=50, 29 font_path='C:/Windows/Fonts/simkai.ttf' #中文处理,用系统自带的字体 30 ).generate(words) 31 32 #产生背景图片,基于彩色图像的颜色生成器 33 image_colors=ImageColorGenerator(bg_image) 34 #开始画图 35 plt.imshow(wc.recolor(color_func=image_colors)) 36 #为背景图去掉坐标轴 37 plt.axis("off") 38 #保存云图 39 plt.show() 40 wc.to_file("评价.png")
效果如下:

初学者
分享及成功,你的报应就是我,记得素质三连!