Mysql数据库优化是多方面的,原则是减少系统的瓶颈,减少资源的占用,增加系统的反应速度。例如,通过优化文件系统,提高磁盘I�的读写速度;通过优化操作系统调度策略,提高MySQL在高负荷情况下的负载能力;优化表结构,索引、查询语句等使查询响应更快。
在MySQL中,可以使用SHOW STATUS 语句查询一些MySQL的性能参数
1 SHOW STATUS LIKE 'value'; 2 常用性能的参数如下: 3 Connections:连接mysql服务器的次数 4 Uptime:MySQL服务器上线的时间 5 SLow_queries:慢查询的次数 6 Com_selet:查询操作的次数 7 Com_insert:插入操作的次数 8 Com_update:修改操作的次数 9 Com_delete:删除操作的次数
利用EXPLAGIN分析查询语句/h2>
EXPLAGIN语句的基本语法
explain select * from tbl_order_goodsG
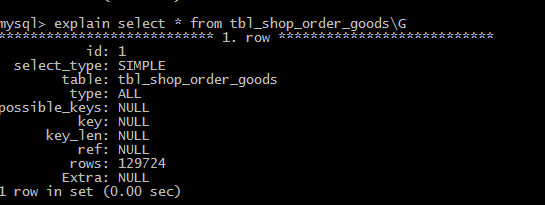
1、id:select的查询序列号,值越大优先级越高,越先被执行
2、select_type:select语句的类型。有几种取值
(1)SIMPLE 简单查询,不包括连接查询和子查询
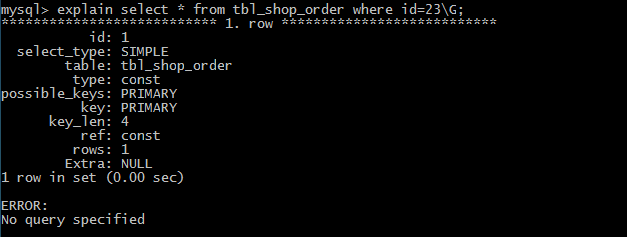
(2)PRIMARY 主查询或者是最外层查语句询,不包括连接查询和子查询
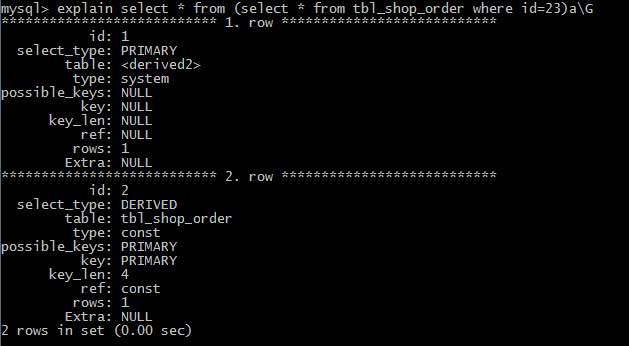
(3)UNION和UNION RESULT UNION 表示连接查询的第二个或后面的查询语句,不依赖于外部查询的结果集。UNION RESULT表示UNION查询的结果集
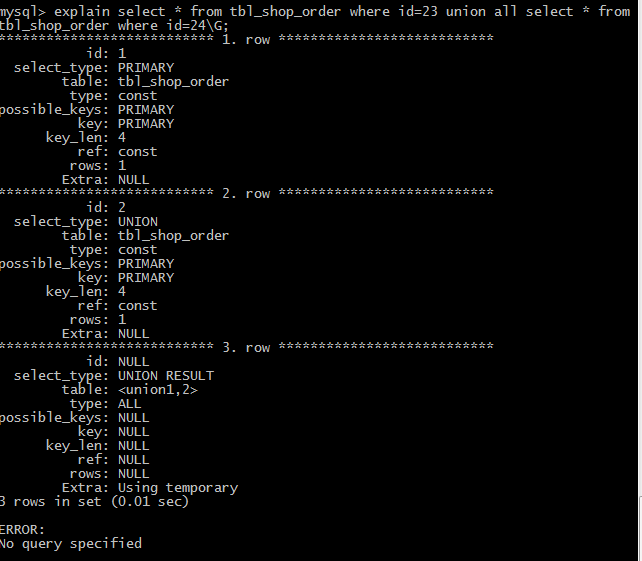
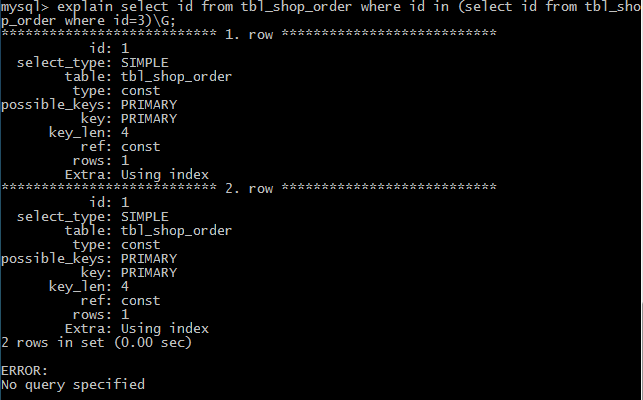
(4)dependent union 表示连接查询的第二个或后面的select语句,取决于外面的查询
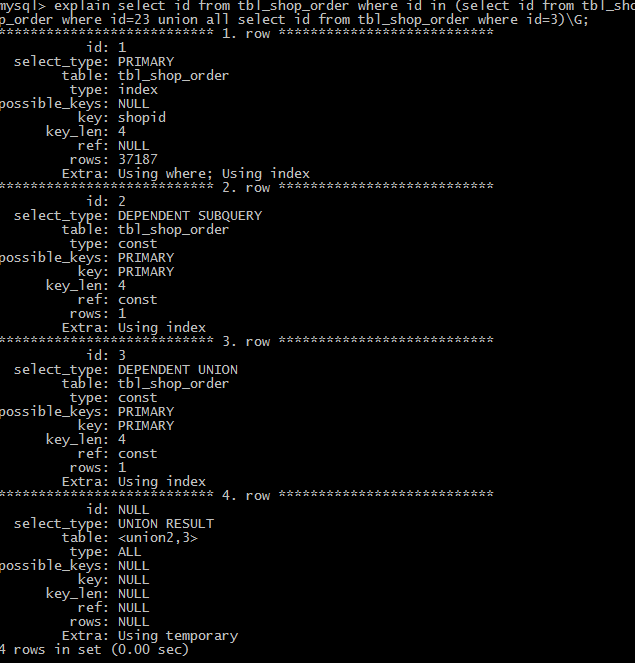
(5)subquery 表示子查询中的第一个select语句,不依赖于外部查询的结果集
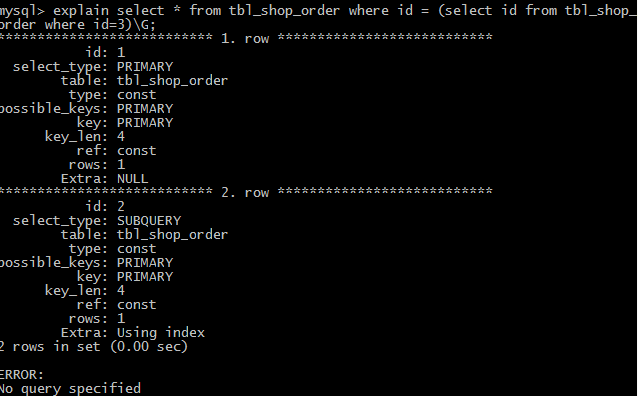
(6)dependent subquery 表示子查询中的第一个select语句,取决于外面查询的
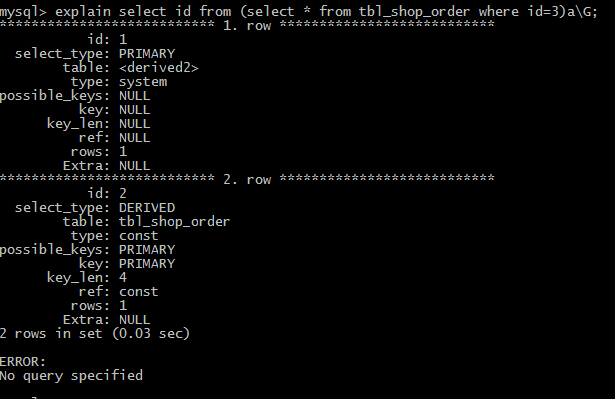
(7)derived 查询类型用于from字句里有子查询的情况。MySQL会递归执行这些子查询,把结果放在临时表里。
4、type 表示表的连接类型
3 system 表只有一行 4 const 表最多只有一行匹配,通用用于主键或者唯一索引比较时 5 eq_ref 每次与之前的表合并行都只在该表读取一行,这是除了system,const之外最好的一种, 6 特点是使用=,而且索引的所有部分都参与join且索引是主键或非空唯一键的索引 7 ref 如果每次只匹配少数行,那就是比较好的一种,使用=或<=>,可以是左覆盖索引或非主键或非唯一键 8 fulltext 全文搜索 9 ref_or_null 与ref类似,但包括NULL 10 index_merge 表示出现了索引合并优化(包括交集,并集以及交集之间的并集),但不包括跨表和全文索引。 11 这个比较复杂,目前的理解是合并单表的范围索引扫描(如果成本估算比普通的range要更优的话) 12 unique_subquery 在in子查询中,就是value in (select...)把形如“select unique_key_column”的子查询替换。 13 PS:所以不一定in子句中使用子查询就是低效的! 14 index_subquery 同上,但把形如”select non_unique_key_column“的子查询替换 15 range 常数值的范围 16 index a.当查询是索引覆盖的,即所有数据均可从索引树获取的时候(Extra中有Using Index); 17 b.以索引顺序从索引中查找数据行的全表扫描(无 Using Index); 18 c.如果Extra中Using Index与Using Where同时出现的话,则是利用索引查找键值的意思; 19 d.如单独出现,则是用读索引来代替读行,但不用于查找 20 all 全表扫描
5、possible_keys:可能使用到的索引,如果是NULL,则没有相关的索引
6、key:经过优化器评估最终使用的索引
7、key_length:使用到的索引长度
8、ref:引用到的上一个表的列
9、rows:rows_examined,要得到最终记录索要扫描经过的记录数
10、Extra:额外的信息说明
10.1、Using index
mysql使用了覆盖索引,避免访问了镖的数据行,效率不错
10.2、Using where
表示服务器在存储引擎收到行后将进行过滤。
10.3、Using temporary
Mysql对查询结果进行排序的时候使用了一张临时表。
10.3、
Using filesort mysql会对数据使用一个外部的索引排序
当出现Using temporary 和Using filesort时,需要对查询语句进行优化操作。
如何使用索引查询
1、使用like关键字查询语句
在使用like关键字进行查询的查询语句中,如果匹配字符串的第一个字符为"%",索引不会起作用。只有"%"不再第一个位置,索引才会起作用
2、使用多列索引查询语句
一个索引可以包括16个字段。对于多列索引,只有查询条件中使用了这些字段中第一个字段时,索引才会被使用
3、使用or关键字的查询语句
查询条件中只有or关键字,且or前后的两个条件中的列都是索引时,查询中才使用索引。否则,查询将不使用索引。
优化insert语句
第一种:
insert into tbl_shop_order (id,name)values(1,'小鸡炖蘑菇')要比insert into tbl_shop_order (id,name)value(1,'小鸡炖蘑菇')速度快。
当一个文本文件载入一个表时,使用load data infile加载数据往往比使用很多insert语句效率至少提高20倍。
例:数据库结构
1 CREATE TABLE `t0` ( 2 `id` bigint(20) unsigned NOT NULL auto_increment, 3 `name` char(20) NOT NULL, 4 `age` tinyint(3) unsigned NOT NULL, 5 `description` text NOT NULL, 6 PRIMARY KEY (`id`), 7 UNIQUE KEY `idx_name` (`name`),
8 update_time timestamp not null 9 ) ENGINE=MyISAM DEFAULT CHARSET=utf8
s.txt文件内容


1 "我爱你","20","相貌平常,经常耍流氓!哈哈" 2 "李奎","21","相貌平常,经常耍流氓!哈哈" 3 "王二米","20","相貌平常,经常耍流氓!哈哈" 4 "老三","24","很强" 5 "老四","34","XXXXX" 6 "老五","52","***%*¥*¥*¥*¥" 7 "小猫","45","中间省略。。。" 8 "小狗","12","就会叫" 9 "小妹","21","PP的很" 10 "小坏蛋","52","表里不一" 11 "上帝他爷","96","非常英俊" 12 "MM来了","10","。。。" 13 "歌颂党","20","社会主义好" 14 "人民好","20","的确是好" 15 "老高","10","学习很好" 16 "斜三","60","眼睛斜了" 17 "中华之子","100","威武的不行了" 18 "大米","63","我爱吃" 19 "苹果","15","好吃"
执行sql语句
load data infile 'G:/s.txt' ignore into table t0 character set gbk fields terminated by ',' enclosed by '"' lines terminated by ' '(`name`,`age`,`description`)set update_time=current_timestamp;
第二种:对于myisam类型的表,可以通过insert into delayed语句提升执行速度。insert delayed into是客户端提交数据给mysql服务器,mysql服务器返回OK状态码给客户端,实际上,数据还没有被插入到表,而是存储在内存里面等待排队,当mysql服务器空闲时在执行插入。优点是速度快,缺点是,系统崩溃,数据会丢失
第三种:锁表,加快插入数据速度
1 lock tables tbl_shop_order write; 2 insert into tbl_shop_order (id,name)values(1,'小鸡炖蘑菇'); 3 unlock tables;
如果不加锁定表,每一次insert完成之后,索引缓冲区都会被写到磁盘上,加入锁定后索引缓冲区仅被写到磁盘上1次
优化order by语句
1、order by id/order by id索引优化(这应该是常识,大家都懂,id加索引)
select * from tbl_shop_order where id=10
select * from tbl_shop_order order by id
2、order by id +limit 组合的索引优化
select * from tbl_shop_order where name='天王盖地虎' order by id
只对id添加索引,效率不是很高,更加高效的方法就是建一个联合索引(name,id)
3、不要对where和order by 的选项使用表达式或者函数
4、order by 的字段混合使用asc和desc(估计没人这么干过)
select * from tbl_shop_order order by id desc,name asc;此方法不应该使用索引
5、where字句使用的字段和order by的字段不一致
select * from tbl_shop_orde where id=1 order by name;此方法不应该使用索引
6、对不同的关键字使用order by 排序
select * from tbl_shop_orde order by id,name;此方法不应该使用索引
优化group by语句
使用grouo by语句时,默认情况,mysql会对符合的结果自动排序。通过扫描整个表并创建一个新的临时表,表中美工组的所有行应为连续,然后使用该临时表来找到组并应用累计行数。
group by 优先于order by
group by是分组查询,一般与聚会函数配合使用
通过使用 order by null禁止排序,从而可以节省耗损
explain select wm_order_platform,count(*) as c from tbl_shop_order group by wm_order_id order by null;
优化嵌套查询
1、使用用join代替子查询(避免了创建临时表)
2、两张表关联时,大表关联小表,这样速度更快
优化or 条件
使用or条件语句,如果要使用索引,则or直接的每个条件都必须使用到索引,如果没有,考虑添加索引。
explain select * from tbl_shop_order where id=1 or wm_order_id=2;
优化插入记录的速度
插入记录时,影响插入速度的主要是索引,唯一性教研,一次插入记录条数等。
1、禁用索引
对于非空表,插入记录时,mysql会根据表的索引队插入的记录建立索引,如果要插入大力的数据,建立索引会降低插入记录的速度。可以在插入记录之前禁用索引,插入完成之后在开启索引
alter table tbl_shop_order DISABLE KEYS;(tbl_shop_order 表名)
开启索引
alter table tbl_shop_order ENABLE KEYS;
2、禁用唯一性检查
SET UNIQUE_CHECK=0;(禁用)
load ...
SET UNIQUE_CHECK=1;(开启)
3、批量插入
insert into tbl_shop_order (id,name)values(1,'小鸡炖蘑菇'),values(1,'小鸡炖蘑菇'),values(1,'小鸡炖蘑菇'),values(1,'小鸡炖蘑菇');
4、使用load命令批量导入
以下是针对myisam存储引擎的表
alter table t0 disable keys; load .... alter table t0 enablekeys;
以下是针对innoDB存储引擎的表
1、禁用唯一性检查
set unique_checks=0 load .... set unique_checks=1
2、禁用外键检查
set foreign_key_checks=0 load .... set foreign_key_checks=1
3、禁止自动提交
set autocommit=0 load .... set autocommit=1
优化数据库结构
1、将字段很多的表分解成多个表
2、增加中间表(对于经常联合查询的表,可以建立中间表以提高查询效率)
3、增加冗余字段(设计数据库时应尽量遵循范式理论的规约,尽可能减少冗余字段。但是适当的增加冗余字段,可以提高查询速度)
分析表
分析表主要是分析关键字的分布
analyze table t0;
table:表名
op:执行的操作 .analyze表示进行分析操作
msg_type:信息类型。通常为状态(status),信息(info),注意(note),警告(warning)和错误(error)
msg_text:显示信息
analyz table分析表的过程中,数据库系统会自动对表加一个只读锁。分析期间只能读,不能改、增加。analyz table可以分析mysiam和innoDB
检查表
检查表主要是检查表是否存在错误
check table 可以坚持mysiam和innodb类型的表是否存在错误。对与myisam类型的表check table语句会更新关键字统计数据。而且check table可以坚持师徒是否有错误
check table t0
优化表
优化表主要是消除删除或者更新造成的空间浪费
optilmize table语句来优化表
optilmize table只能优化表中的varchar,blob或text类型的字段
optilmize table语句可以消除删除和更新造成的文件碎片。optilmize table在执行过程中也会给表加上只读锁
本文乃《MySQL技术精粹->架构、高级特性、性能优化与集群实战》读书笔记!