因项目需要,看了下drools规则引擎。写了一个比较简单的drools的drl规则和决策表实现的例子。
规则说明:
网络商城要举办活动(奖励额外积分),
订单原价金额在
100以下, 不加分
100-500 加100分
500-1000 加500分
1000 以上 加1000分
1.建立最基本的Drools项目结构并引入必须的类库。(这里采用junit来执行单元测试)。创建一个Java Project,建立maven形式的源码包。

2.定义实体类Order.java
1 import java.util.Date; 2 3 public class Order { 4 private Date bookingDate;// 下单日期 5 6 private int amout;// 订单原价金额 7 8 private User user;// 下单人 9 10 private int score;//积分 11 12 public Order(Date bookingDate,int amout, User user, int score){ 13 this.bookingDate = bookingDate; 14 this.amout = amout; 15 this.user = user; 16 this.score = score; 17 } 18 19 public Order(){ 20 } 21 22 //省略get、set方法53 54 }
3.定义实体User.java
public class User { private String name;// 姓名 private int level;// 用户级别 public User(){ } public User(String name, int level){ this.name = name; this.level = level; } //省略get、set方法 }
4.编写规则文件point-rules.drl
package drools import com.wang.drools.point.Order import com.wang.drools.point.User rule "zero" no-loop true //只检查一次 lock-on-active true salience 9 //值越大 ,优先级越高 when //购物金额100以下不加分 $s : Order(amout <= 100); then $s.setScore(0); update($s); end rule "add100" no-loop true //只检查一次 lock-on-active true salience 8 //值越大 ,优先级越高 when //购物金额100以上500以下加100积分 $s : Order(amout > 100 && amout <= 500); then $s.setScore(100); update($s); end rule "add500" no-loop true //只检查一次 lock-on-active true salience 6 //值越大 ,优先级越高 when //购物金额500以上1000以下加500积分 $s : Order(amout > 500 && amout <= 1000); then $s.setScore(500); update($s); end rule "add1000" no-loop true //只检查一次 lock-on-active true salience 5 //值越大 ,优先级越高 when //购物金额1000以上加1000积分 $s : Order(amout > 1000); then $s.setScore(1000); update($s); end
说明:rule表示规则的开始,salience表示规则的优先级,当有多条规则同时存在是,优先级越高的越先被匹配执行。lock-on-active表示执行过一次之后就不再执行,防止后续的条件执行过程中改变变量的值导致重新满足该规则之后再次执行对应的操作。When表示匹配的规则,then表示匹配规则之后执行的动作。
5.测试drl规则TestPoint.java
import java.text.DateFormat; import java.text.SimpleDateFormat; import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; import java.util.List; import org.kie.api.io.ResourceType; import org.kie.internal.KnowledgeBase; import org.kie.internal.KnowledgeBaseFactory; import org.kie.internal.builder.KnowledgeBuilder; import org.kie.internal.builder.KnowledgeBuilderErrors; import org.kie.internal.builder.KnowledgeBuilderFactory; import org.kie.internal.definition.KnowledgePackage; import org.kie.internal.io.ResourceFactory; import org.kie.internal.runtime.StatefulKnowledgeSession; @SuppressWarnings("deprecation") public class TestPoint { /** * 计算额外积分金额 规则如下: 订单原价金额 * 100以下, 不加分 * 100-500 加100分 * 500-1000 加500分 * 1000 以上 加1000分 * * @param args * @throws Exception */ public static void main(String[] args) throws Exception { KnowledgeBuilder builder = KnowledgeBuilderFactory.newKnowledgeBuilder(); builder.add(ResourceFactory.newClassPathResource("point/point-rules.drl"), ResourceType.DRL); if (builder.hasErrors()) { System.out.println("规则中存在错误,错误消息如下:"); KnowledgeBuilderErrors kbuidlerErrors = builder.getErrors(); for (Iterator<?> iter = kbuidlerErrors.iterator(); iter.hasNext();) { System.out.println(iter.next()); } return; } Collection<KnowledgePackage> packages = builder.getKnowledgePackages(); KnowledgeBase kbase = KnowledgeBaseFactory.newKnowledgeBase(); kbase.addKnowledgePackages(packages); StatefulKnowledgeSession session = kbase.newStatefulKnowledgeSession(); List<Order> orderList = getInitData(); for (int i = 0; i < orderList.size(); i++) { Order o = orderList.get(i); session.insert(o); session.fireAllRules(); // 执行完规则后, 执行相关的逻辑 addScore(o); } session.dispose(); } private static void addScore(Order o){ System.out.println("用户" + o.getUser().getName() + "享受额外增加积分: " + o.getScore()); } private static List<Order> getInitData() throws Exception { List<Order> orderList = new ArrayList<Order>(); DateFormat df = new SimpleDateFormat("yyyy-MM-dd"); { Order order = new Order(); order.setAmout(80); order.setBookingDate(df.parse("2015-07-01")); User user = new User(); user.setLevel(1); user.setName("Name1"); order.setUser(user); orderList.add(order); } { Order order = new Order(); order.setAmout(200); order.setBookingDate(df.parse("2015-07-02")); User user = new User(); user.setLevel(2); user.setName("Name2"); order.setUser(user); orderList.add(order); } { Order order = new Order(); order.setAmout(800); order.setBookingDate(df.parse("2015-07-03")); User user = new User(); user.setLevel(3); user.setName("Name3"); order.setUser(user); orderList.add(order); } { Order order = new Order(); order.setAmout(1500); order.setBookingDate(df.parse("2015-07-04")); User user = new User(); user.setLevel(4); user.setName("Name4"); order.setUser(user); orderList.add(order); } return orderList; } }
6.建立等同于drl规则文件的xsl文件 point.xsl
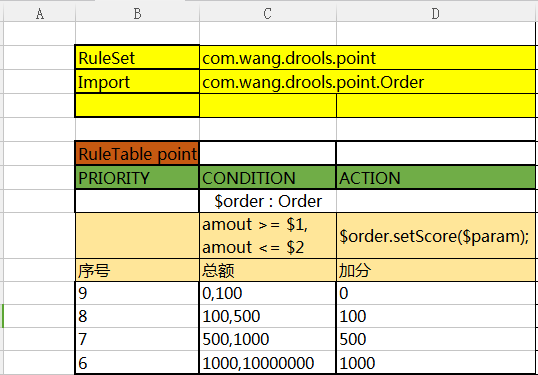
说明:
- RuleSet关键字是必须的,名字是可选的
- Import语句非常像java的import,如果有多个import,用逗号隔开
- RuleTable关键字也是必须的,它指示了后面将会有一批rule,ruletable的名称将会作为以后生成rule的前缀
- 条件如果不写的话默认就是==, 比如上面的contract.get("productLine"),其实就是contract.get("productLine") == $param, 如果有多个参数可以使用$1,$2,比如我们经常用到的一个区间数据,这个占位符就派上用场了
7.在META-INF文件夹下的kmodule.xml文件中配置ksession信息。

说明:1.packages = “xxxx” 配置xsl所在包的名称
2.<ksession name="ksession-calXSL"/> 配置ksession的名称(方便在项目中调用)
8.测试xsl决策表文件正确性 TestPointXML.java
import java.util.Date; import org.kie.api.KieServices; import org.kie.api.runtime.KieContainer; import org.kie.api.runtime.KieSession; /*** * 使用决策表实现规则引擎 * * @author wyx * */ public class TestPointXSL { public static void main(String[] args) { KieServices ks = KieServices.Factory.get(); KieContainer kc = ks.getKieClasspathContainer(); KieSession kSession = kc.newKieSession("ksession-pointXML"); User user = new User(); user.setName("张学友"); user.setLevel(1); Order order = new Order(new Date(),100,user,0); kSession.insert(order); kSession.fireAllRules(); kSession.dispose(); System.out.println(order.getScore()); } }
9.有个很方便的文件解析可以帮助我们很快知道xsl文件是否书写正确 GenerationRules.java
直接能将xsl文件解析成drl规则打印在控制台,方便查看、修改
import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.InputStream; import org.drools.decisiontable.InputType; import org.drools.decisiontable.SpreadsheetCompiler; import org.junit.Test; /*** * * 解析决策树文件 * * @author wyx * */ public class GenerationRules { @Test public void compile() throws FileNotFoundException { File file = new File( "F:\icore\drools\src\main\resources\pointXML\point.xls"); InputStream is = new FileInputStream(file); SpreadsheetCompiler converter = new SpreadsheetCompiler(); String drl = converter.compile(is, InputType.XLS); System.out.println(" " + drl); } }
|
关键字 |
说明 |
是否必须 |
|
RuleSet |
在这个单元的右边单元中包含ruleset的名称 |
必须,只能有一个(如果为空则使用默认值) |
|
Sequential |
右边的单元可以是true或false,如果是true则确保规则按照从表格的上面到下面的顺序执行(规则触发是从上朝下,如果是false就是乱序) |
可选 |
|
Import |
要导入规则库中的类的列表(逗号隔开) |
可选 |
|
Variables |
紧跟在右边的单元格包含global声明。格式是类型跟着变量名(全局变量定义,多个用逗号隔开) |
可选 |
|
Functions |
紧跟在右边的单元格包含可以用在规则代码段中的函数声明。Drools支持在DRL中定义函数,允许逻辑在规则中嵌入 |
可选 |
|
RuleTable |
一个以RuleTable开头的单元格代表一个规则 表定义的开始。实际的规则表从下一行开始。规则表的读取遵循从左到右,从上到下的顺序,知道出现空行 |
至少一个,如果有多个,全部加入到同一个RuleSet中 |
|
CONDITION |
说明该列用于规则的条件表达式 |
每个规则表至少一个 |
|
ACTION |
说明该列用于规则表的推论部分 |
每个规则表至少一个 |
|
PRIORITY |
说明该列值将用来设定改行规则的’salience’值,覆盖‘Sequential’标记 |
可选 |
|
NAME |
说明该列规则的名字将使用该列所指定名字 |
可选 |
|
UNLOOP |
如果单元格这一列上有值,则no-loop属性被设置 |
可选 |
|
Worksheet |
默认只有第一个工作表被认为是决策表 |
N/A |