在介绍这一节之前,需要你对slim模型库有一些基本了解,具体可以参考第二十二节,TensorFlow中的图片分类模型库slim的使用、数据集处理,这一节我们会详细介绍slim模型库下面的一些函数的使用。
一 简介
slim被放在tensorflow.contrib这个库下面,导入的方法如下:
import tensorflow.contrib.slim as slim
这样我们就可以使用slim了,既然说到了,先来了解tensorflow.contrib这个库,tensorflow官方对它的描述是:此目录中的任何代码未经官方支持,可能会随时更改或删除。每个目录下都有指定的所有者。它旨在包含额外功能和贡献,最终会合并到核心TensorFlow中,但其接口可能仍然会发生变化,或者需要进行一些测试,看是否可以获得更广泛的接受。所以slim依然不属于原生tensorflow。
那么什么是slim?slim到底有什么用?
上一节已经讲到slim是一个使构建,训练,评估神经网络变得简单的库。它可以消除原生tensorflow里面很多重复的模板性的代码,让代码更紧凑,更具备可读性。另外slim提供了很多计算机视觉方面的著名模型(VGG, AlexNet等),我们不仅可以直接使用,甚至能以各种方式进行扩展。
slim的子模块及功能介绍:
- arg_scope: provides a new scope named arg_scope that allows a user to define default arguments for specific operations within that scope.
除了基本的name_scope,variabel_scope外,又加了arg_scope,它是用来控制每一层的默认超参数的。(后面会详细说)
- data: contains TF-slim's dataset definition, data providers, parallel_reader, and decoding utilities.
貌似slim里面还有一套自己的数据定义,这个跳过,我们用的不多。
- evaluation: contains routines for evaluating models.
评估模型的一些方法,用的也不多。
- layers: contains high level layers for building models using tensorflow.
这个比较重要,slim的核心和精髓,一些复杂层的定义。
- learning: contains routines for training models.
一些训练规则。
- losses: contains commonly used loss functions.
一些loss。
- metrics: contains popular evaluation metrics.
评估模型的度量标准。
- nets: contains popular network definitions such as VGG and AlexNet models.
包含一些经典网络,VGG等,用的也比较多。
- queues: provides a context manager for easily and safely starting and closing QueueRunners.
文本队列管理,比较有用。
- regularizers: contains weight regularizers.
包含一些正则规则。
- variables: provides convenience wrappers for variable creation and manipulation.
这个比较有用,我很喜欢slim管理变量的机制。
二.slim定义模型
在slim中,组合使用variables, layers和scopes可以简洁的定义模型。
1.variable
定义于模型变量。生成一个weight变量, 用truncated normal初始化它, 并使用l2正则化,并将其放置于CPU上, 只需下面的代码即可:
#定义模型变量
weights = slim.model_variable('weights', shape=[10, 10, 3 , 3],
initializer=tf.truncated_normal_initializer(stddev=0.1),
regularizer=slim.l2_regularizer(0.05),
device='/CPU:0')
model_variables = slim.get_model_variables()
原生tensorflow包含两类变量:普通变量和局部变量。大部分变量都是普通变量,它们一旦生成就可以通过使用saver存入硬盘,局部变量只在session中存在,不会保存。
- slim进一步的区分了变量类型,定义了model_variables(模型变量),这种变量代表了模型的参数。模型变量通过训练或者微调而得到学习,或者在评测或前向传播中可以从ckpt文件中载入。
- 非模型参数在实际前向传播中不需要的参数,比如global_step。同样的,移动平均反应了模型参数,但它本身不是模型参数。如下:
#常规变量
my_var = slim.variable('my_var',shape=[20, 1],
initializer=tf.zeros_initializer())
#get_variables()得到模型参数和常规参数
regular_variables_and_model_variables = slim.get_variables()
当我们通过slim的layers或着直接使用slim.model_variable创建变量时,tf会将此变量加入tf.GraphKeys.MODEL_VARIABLES这个集合中,当你需要构建自己的变量时,可以通过以下代码
将其加入模型参数。
#Letting TF-Slim know about the additional variable.
slim.add_model_variable(my_var)
2.layers
抽象并封装了常用的层,并且提供了repeat和stack操作,使得定义网络更加方便。
首先让我们看看tensorflow怎么实现一个层,例如卷积层:
#在tensorflow下实现一个层
input_x = tf.placeholder(dtype=tf.float32,shape=[None,224,224,3])
with tf.name_scope('conv1_1') as scope:
weight = tf.Variable(tf.truncated_normal([3, 3, 3, 64],
dtype=tf.float32,
stddev=1e-1),
name='weights')
conv = tf.nn.conv2d(input_x, weight, [1, 1, 1, 1], padding='SAME')
bias = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name='biases')
conv1 = tf.nn.relu(tf.nn.bias_add(conv, bias), name=scope)
然后slim的实现:
#在slim实现一层
net = slim.conv2d(input_x, 64, [3, 3], scope='conv1_1')
但这个不是重要的,因为tenorflow目前也有大部分层的简单实现,这里比较吸引人的是slim中的repeat和stack操作:
假设定义三个相同的卷积层:
net = ...
net = slim.conv2d(net, 256, [3, 3], scope='conv2_1')
net = slim.conv2d(net, 256, [3, 3], scope='conv2_2')
net = slim.conv2d(net, 256, [3, 3], scope='conv2_3')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
在slim中的repeat操作可以减少代码量:
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv2')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
repeat不仅只实现了相同操作相同参数的重复,它还将scope进行了展开,例子中的scope被展开为 'conv2/conv2_1', 'conv2/conv2_2' and 'conv2/conv2_3'。
而stack是处理卷积核或者输出不一样的情况,假设定义三层FC:
#stack的使用 stack是处理卷积核或者输出不一样的情况,
x = tf.placeholder(dtype=tf.float32,shape=[None,784])
x = slim.fully_connected(x, 32, scope='fc/fc_1')
x = slim.fully_connected(x, 64, scope='fc/fc_2')
x = slim.fully_connected(x, 128, scope='fc/fc_3')
#使用stack操作:
x = slim.stack(x, slim.fully_connected, [32, 64, 128], scope='fc')
同理卷积层也一样:
# 普通方法:
net = slim.conv2d(input_x, 32, [3, 3], scope='core/core_1')
net = slim.conv2d(net, 32, [1, 1], scope='core/core_2')
net = slim.conv2d(net, 64, [3, 3], scope='core/core_3')
net = slim.conv2d(net, 64, [1, 1], scope='core/core_4')
# 简便方法:
net = slim.stack(input_x, slim.conv2d, [(32, [3, 3]), (32, [1, 1]), (64, [3, 3]), (64, [1, 1])], scope='core')
3.scope
除了tensorflow中的name_scope和variable_scope, tf.slim新增了arg_scope操作,这一操作符可以让定义在这一scope中的操作共享参数,即如不指定参数的话,则使用默认参数。且参数可以被局部覆盖。
如果你的网络有大量相同的参数,如下:
net = slim.conv2d(input_x, 64, [11, 11], 4, padding='SAME',
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.0005), scope='conv1')
net = slim.conv2d(net, 128, [11, 11], padding='VALID',
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.0005), scope='conv2')
net = slim.conv2d(net, 256, [11, 11], padding='SAME',
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.0005), scope='conv3')
然后我们用arg_scope处理一下:
#使用arg_scope
with slim.arg_scope([slim.conv2d], padding='SAME',
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):
net = slim.conv2d(input_x, 64, [11, 11], scope='conv1')
net = slim.conv2d(net, 128, [11, 11], padding='VALID', scope='conv2')
net = slim.conv2d(net, 256, [11, 11], scope='conv3')
如上倒数第二行代码,对padding进行了重新赋值。那如果除了卷积层还有其他层呢?那就要如下定义:
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):
with slim.arg_scope([slim.conv2d], stride=1, padding='SAME'):
net = slim.conv2d(input_x, 64, [11, 11], 4, padding='VALID', scope='conv1')
net = slim.conv2d(net, 256, [5, 5],
weights_initializer=tf.truncated_normal_initializer(stddev=0.03),
scope='conv2')
net = slim.fully_connected(net, 1000, activation_fn=None, scope='fc')
写两个arg_scope就行了。采用如上方法,定义一个VGG也就十几行代码的事了。
#定义一个vgg16网络
def vgg16(inputs):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
net = slim.max_pool2d(net, [2, 2], scope='pool3')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [2, 2], scope='pool4')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5')
net = slim.max_pool2d(net, [2, 2], scope='pool5')
net = slim.fully_connected(net, 4096, scope='fc6')
net = slim.dropout(net, 0.5, scope='dropout6')
net = slim.fully_connected(net, 4096, scope='fc7')
net = slim.dropout(net, 0.5, scope='dropout7')
net = slim.fully_connected(net, 1000, activation_fn=None, scope='fc8')
return net
三.训练模型
这里直接选用经典网络。
import tensorflow as tf
vgg = tf.contrib.slim.nets.vgg
# Load the images and labels.
images, labels = ...
# Create the model.
predictions, _ = vgg.vgg_16(images)
# Define the loss functions and get the total loss.
loss = slim.losses.softmax_cross_entropy(predictions, labels)
关于loss,要说一下定义自己的loss的方法,以及注意不要忘记加入到slim中让slim看到你的loss。
还有正则项也是需要手动添加进loss当中的,不然最后计算的时候就不优化正则目标了。
# Load the images and labels.
images, scene_labels, depth_labels, pose_labels = ...
# Create the model.
scene_predictions, depth_predictions, pose_predictions = CreateMultiTaskModel(images)
# Define the loss functions and get the total loss.
classification_loss = slim.losses.softmax_cross_entropy(scene_predictions, scene_labels)
sum_of_squares_loss = slim.losses.sum_of_squares(depth_predictions, depth_labels)
pose_loss = MyCustomLossFunction(pose_predictions, pose_labels)
slim.losses.add_loss(pose_loss) # Letting TF-Slim know about the additional loss.
# The following two ways to compute the total loss are equivalent:
regularization_loss = tf.add_n(slim.losses.get_regularization_losses())
total_loss1 = classification_loss + sum_of_squares_loss + pose_loss + regularization_loss
# (Regularization Loss is included in the total loss by default).
total_loss2 = slim.losses.get_total_loss()
slim在learning.py中提供了一个简单而有用的训练模型的工具。我们只需调用slim.learning.create_train_op 和slim.learning.train就可以完成优化过程。
slim.learning.train函数被用来训练神经网络,函数定义如下:
def slim.learning.train(train_op, logdir, train_step_fn=train_step, train_step_kwargs=_USE_DEFAULT, log_every_n_steps=1, graph=None, master='', is_chief=True, global_step=None, number_of_steps=None, init_op=_USE_DEFAULT, init_feed_dict=None, local_init_op=_USE_DEFAULT, init_fn=None, ready_op=_USE_DEFAULT, summary_op=_USE_DEFAULT, save_summaries_secs=600, summary_writer=_USE_DEFAULT, startup_delay_steps=0, saver=None, save_interval_secs=600, sync_optimizer=None, session_config=None, trace_every_n_steps=None):
其中部分参数的说明如下:
- train_op: A `Tensor` that, when executed, will apply the gradients and return the loss value.
- logdir: The directory where training logs are written to. If None, model checkpoints and summaries will not be written.检查点文件和日志文件的保存路径。
- number_of_steps: The max number of gradient steps to take during training,as measured by 'global_step': training will stop if global_step is greater than 'number_of_steps'. If the value is left as None, training proceeds indefinitely.默认是一致循环训练。
- save_summaries_secs: How often, in seconds, to save summaries.
- summary_writer: `SummaryWriter` to use. Can be `None` to indicate that no summaries should be written. If unset, we create a SummaryWriter.
- startup_delay_steps: The number of steps to wait for before beginning. Note that this must be 0 if a sync_optimizer is supplied.
- saver: Saver to save checkpoints. If None, a default one will be created and used.
- save_interval_secs: How often, in seconds, to save the model to `logdir`.
g = tf.Graph()
# Create the model and specify the losses...
...
total_loss = slim.losses.get_total_loss()
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
# create_train_op ensures that each time we ask for the loss, the update_ops
# are run and the gradients being computed are applied too.
train_op = slim.learning.create_train_op(total_loss, optimizer)
logdir = ... # Where checkpoints are stored.
slim.learning.train(
train_op,
logdir,
number_of_steps=1000, #迭代次数
save_summaries_secs=300, #存summary间隔秒数
save_interval_secs=600) #存模型间隔秒数
四.读取保存模型变量
在迁移学习中,我们经常会用到别人已经训练好的网络和模型参数,这时候我们可能需要从检查点文件中加载部分变量,下面我就会讲解如何加载指定变量。以及当前图的变量名和检查点文件中变量名不一致时怎么办。
1. 从检查恢复部分变量
通过以下功能我们可以载入模型的部分变量:
# Create some variables. v1 = tf.Variable(..., name="v1") v2 = tf.Variable(..., name="v2") ... # Add ops to restore all the variables. restorer = tf.train.Saver() # Add ops to restore some variables. restorer = tf.train.Saver([v1, v2]) # Later, launch the model, use the saver to restore variables from disk, and # do some work with the model. with tf.Session() as sess: # Restore variables from disk. restorer.restore(sess, "/tmp/model.ckpt") print("Model restored.") # Do some work with the model ...
通过这种方式我们可以加载不同变量名的变量!
2 从从检查点恢复部分变量还可以采用其他方法
# Create some variables. v1 = slim.variable(name="v1", ...) v2 = slim.variable(name="nested/v2", ...) ... # Get list of variables to restore (which contains only 'v2'). These are all # equivalent methods: #从检查点文件中恢复name='v2'的变量 variables_to_restore = slim.get_variables_by_name("v2") # or 从检查点文件中恢复name带有2的所有变量 variables_to_restore = slim.get_variables_by_suffix("2") # or 从检查点文件中恢复命名空间scope='nested'的所有变量 variables_to_restore = slim.get_variables(scope="nested") # or 恢复命名空间scope='nested'的所有变量 variables_to_restore = slim.get_variables_to_restore(include=["nested"]) # or 除了命名空间scope='v1'的变量 variables_to_restore = slim.get_variables_to_restore(exclude=["v1"]) # Create the saver which will be used to restore the variables. restorer = tf.train.Saver(variables_to_restore) with tf.Session() as sess: # Restore variables from disk. restorer.restore(sess, "/tmp/model.ckpt") print("Model restored.") # Do some work with the model ...
3.当图的变量名与checkpoint中的变量名不同时,恢复模型参数
当从checkpoint文件中恢复变量时,Saver在checkpoint文件中定位到变量名,并且把它们映射到当前图中的变量中。之前的例子中,我们创建了Saver,并为其提供了变量列表作为参数。这时,在checkpoint文件中定位的变量名,是隐含地从每个作为参数给出的变量的var.op.name而获得的。这一方式在图与checkpoint文件中变量名字相同时,可以很好的工作。而当名字不同时,必须给Saver提供一个将checkpoint文件中的变量名映射到图中的每个变量的字典。
假设我们定义的网络变量是conv1/weights,而从VGG检查点文件加载的变量名为vgg16/conv1/weights,正常load肯定会报错(找不到变量名),但是可以这样:例子见下:
# Assuming that 'conv1/weights' should be restored from 'vgg16/conv1/weights' def name_in_checkpoint(var): return 'vgg16/' + var.op.name # Assuming that 'conv1/weights' and 'conv1/bias' should be restored from 'conv1/params1' and 'conv1/params2' def name_in_checkpoint(var): if "weights" in var.op.name: return var.op.name.replace("weights", "params1") if "bias" in var.op.name: return var.op.name.replace("bias", "params2") variables_to_restore = slim.get_model_variables() variables_to_restore = {name_in_checkpoint(var):var for var in variables_to_restore} restorer = tf.train.Saver(variables_to_restore) with tf.Session() as sess: # Restore variables from disk. restorer.restore(sess, "/tmp/model.ckpt")
4.在一个不同的任务上对网络进行微调
比如我们要将1000类的imagenet分类任务应用于20类的Pascal VOC分类任务中,我们只导入部分层,见下例:
image, label = MyPascalVocDataLoader(...) images, labels = tf.train.batch([image, label], batch_size=32) # Create the model,20类 predictions = vgg.vgg_16(images,num_classes=20) train_op = slim.learning.create_train_op(...) # Specify where the Model, trained on ImageNet, was saved. model_path = '/path/to/pre_trained_on_imagenet.checkpoint' # Specify where the new model will live: log_dir = '/path/to/my_pascal_model_dir/' # Restore only the convolutional layers: 从检查点载入除了fc6,fc7,fc8层之外的参数 variables_to_restore = slim.get_variables_to_restore(exclude=['fc6', 'fc7', 'fc8']) init_fn = assign_from_checkpoint_fn(model_path, variables_to_restore) # Start training. slim.learning.train(train_op, log_dir, init_fn=init_fn)
下面会显示一个具体迁移学习的案例。
五 预训练
如果我们仍然是对1000类的数据集进行分类,此时我们可以利用训练好的模型参数进行初始化,然后继续训练。
文件夹结构如下,不懂得话,可以参考第二十二节,TensorFlow中的图片分类模型库slim的使用、数据集处理,其中vgg预训练模型下载地址:https://github.com/tensorflow/models/tree/master/research/slim/#Pretrained


代码如下:
def retrain(): ''' 演示一个VGG16网络的例子 从头开始训练 ''' batch_size = 128 learning_rate = 1e-4 #用于保存微调后的检查点文件和日志文件路径 train_log_dir = './log/vgg16/slim_retrain' #官方下载的检查点文件路径 checkpoint_file = './log/vgg16/vgg_16.ckpt' if not tf.gfile.Exists(train_log_dir): tf.gfile.MakeDirs(train_log_dir) #创建一个图,作为当前图 with tf.Graph().as_default(): #加载数据 train_images, train_labels = .... #创建vgg16网络 如果想冻结所有层,可以指定slim.conv2d中的 trainable=False logits,end_points = vgg.vgg_16(train_images, is_training=True) #交叉熵代价函数 slim.losses.softmax_cross_entropy(logits, onehot_labels=train_labels) total_loss = slim.losses.get_total_loss() #设置写入到summary中的变量 tf.summary.scalar('losses/total_loss', total_loss) ''' 设置优化器 这里不能指定成Adam优化器,因为我们的官方模型文件中使用的就是GradientDescentOptimizer优化器, 因此我们要和官方模型一致,如果想使用AdamOptimizer优化器,我们可以在调用完vgg16()网络后,就执行恢复模型。 而把执行恢复模型的代码放在后面,会由于我们在当前图中定义了一些检查点中不存在变量,恢复时在检查点文件找不 到变量,因此会报错。 ''' optimizer = tf.train.GradientDescentOptimizer(learning_rate) #optimizer = tf.train.AdamOptimizer(learning_rate) # create_train_op that ensures that when we evaluate it to get the loss, # the update_ops are done and the gradient updates are computed. train_tensor = slim.learning.create_train_op(total_loss, optimizer) # Restore only the convolutional layers: 从检查点载入除了fc8层之外的参数到当前图 variables_to_restore = slim.get_variables_to_restore(exclude=['vgg_16/fc8']) init_fn = slim.assign_from_checkpoint_fn(checkpoint_file, variables_to_restore) print('开始训练!') #开始训练网络 slim.learning.train(train_tensor, train_log_dir, number_of_steps=100, #迭代次数 一次迭代batch_size个样本 save_summaries_secs=300, #存summary间隔秒数 save_interval_secs=300, #存模模型间隔秒数 init_fn=init_fn)
六 微调
有时候我们数据集比较少的时候,可能使用已经训练的网络模型。比如我们想对flowers数据集进行分类。该数据集分成了两部分,训练集数据有3320张,校验集数据有350张。我们使用slim库下已经写好的vgg16网络,并下载对应的模型参数文件。由于模型参数是针对ImageNet数据集训练的得到的,而我们Flower数据集只有5类,因此需要把vgg16最后一层分类数改为5。
这里我们仍然先使用TensorFlow的网络架构来实现微调功能,后面我们再演示一个使用slim库简化之后的代码。
1.TensorFlow实现代码
# -*- coding: utf-8 -*- """ Created on Wed Jun 6 11:56:58 2018 @author: zy """ ''' 利用已经训练好的vgg16网络对flowers数据集进行微调 把最后一层分类由2000->5 然后重新训练,我们也可以冻结其它所有层,只训练最后一层 ''' from nets import vgg import matplotlib.pyplot as plt import tensorflow as tf import numpy as np import input_data import os slim = tf.contrib.slim DATA_DIR = './datasets/data/flowers' #输出类别 NUM_CLASSES = 5 #获取图片大小 IMAGE_SIZE = vgg.vgg_16.default_image_size def flowers_fine_tuning(): ''' 演示一个VGG16的例子 微调 这里只调整VGG16最后一层全连接层,把1000类改为5类 对网络进行训练 ''' ''' 1.设置参数,并加载数据 ''' #用于保存微调后的检查点文件和日志文件路径 train_log_dir = './log/vgg16/fine_tune' train_log_file = 'flowers_fine_tune.ckpt' #官方下载的检查点文件路径 checkpoint_file = './log/vgg16/vgg_16.ckpt' #设置batch_size batch_size = 256 learning_rate = 1e-4 #训练集数据长度 n_train = 3320 #测试集数据长度 #n_test = 350 #迭代轮数 training_epochs = 3 display_epoch = 1 if not tf.gfile.Exists(train_log_dir): tf.gfile.MakeDirs(train_log_dir) #加载数据 train_images, train_labels = input_data.get_batch_images_and_label(DATA_DIR,batch_size,NUM_CLASSES,True,IMAGE_SIZE,IMAGE_SIZE) test_images, test_labels = input_data.get_batch_images_and_label(DATA_DIR,batch_size,NUM_CLASSES,False,IMAGE_SIZE,IMAGE_SIZE) #获取模型参数的命名空间 arg_scope = vgg.vgg_arg_scope() #创建网络 with slim.arg_scope(arg_scope): ''' 2.定义占位符和网络结构 ''' #输入图片 input_images = tf.placeholder(dtype=tf.float32,shape = [None,IMAGE_SIZE,IMAGE_SIZE,3]) #图片标签 input_labels = tf.placeholder(dtype=tf.float32,shape = [None,NUM_CLASSES]) #训练还是测试?测试的时候弃权参数会设置为1.0 is_training = tf.placeholder(dtype = tf.bool) #创建vgg16网络 如果想冻结所有层,可以指定slim.conv2d中的 trainable=False logits,end_points = vgg.vgg_16(input_images, is_training=is_training,num_classes = NUM_CLASSES) #print(end_points) 每个元素都是以vgg_16/xx命名 ''' #从当前图中搜索指定scope的变量,然后从检查点文件中恢复这些变量(即vgg_16网络中定义的部分变量) #如果指定了恢复检查点文件中不存在的变量,则会报错 如果不知道检查点文件有哪些变量,我们可以打印检查点文件查看变量名 params = [] conv1 = slim.get_variables(scope="vgg_16/conv1") params.extend(conv1) conv2 = slim.get_variables(scope="vgg_16/conv2") params.extend(conv2) conv3 = slim.get_variables(scope="vgg_16/conv3") params.extend(conv3) conv4 = slim.get_variables(scope="vgg_16/conv4") params.extend(conv4) conv5 = slim.get_variables(scope="vgg_16/conv5") params.extend(conv5) fc6 = slim.get_variables(scope="vgg_16/fc6") params.extend(fc6) fc7 = slim.get_variables(scope="vgg_16/fc7") params.extend(fc7) ''' # Restore only the convolutional layers: 从检查点载入当前图除了fc8层之外所有变量的参数 params = slim.get_variables_to_restore(exclude=['vgg_16/fc8']) #用于恢复模型 如果使用这个保存或者恢复的话,只会保存或者恢复指定的变量 restorer = tf.train.Saver(params) #预测标签 pred = tf.argmax(logits,axis=1) ''' 3 定义代价函数和优化器 ''' #代价函数 cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=input_labels,logits=logits)) #设置优化器 optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost) #预测结果评估 correct = tf.equal(pred,tf.argmax(input_labels,1)) #返回一个数组 表示统计预测正确或者错误 accuracy = tf.reduce_mean(tf.cast(correct,tf.float32)) #求准确率 num_batch = int(np.ceil(n_train / batch_size)) #用于保存检查点文件 save = tf.train.Saver(max_to_keep=1) #恢复模型 with tf.Session() as sess: sess.run(tf.global_variables_initializer()) #检查最近的检查点文件 ckpt = tf.train.latest_checkpoint(train_log_dir) if ckpt != None: save.restore(sess,ckpt) print('从上次训练保存后的模型继续训练!') else: restorer.restore(sess, checkpoint_file) print('从官方模型加载训练!') #创建一个协调器,管理线程 coord = tf.train.Coordinator() #启动QueueRunner, 此时文件名才开始进队。 threads = tf.train.start_queue_runners(sess=sess,coord=coord) ''' 4 查看预处理之后的图片 ''' imgs, labs = sess.run([train_images, train_labels]) print('原始训练图片信息:',imgs.shape,labs.shape) show_img = np.array(imgs[0],dtype=np.uint8) plt.imshow(show_img) plt.title('Original train image') plt.show() imgs, labs = sess.run([test_images, test_labels]) print('原始测试图片信息:',imgs.shape,labs.shape) show_img = np.array(imgs[0],dtype=np.uint8) plt.imshow(show_img) plt.title('Original test image') plt.show() print('开始训练!') for epoch in range(training_epochs): total_cost = 0.0 for i in range(num_batch): imgs, labs = sess.run([train_images, train_labels]) _,loss = sess.run([optimizer,cost],feed_dict={input_images:imgs,input_labels:labs,is_training:True}) total_cost += loss #打印信息 if epoch % display_epoch == 0: print('Epoch {}/{} average cost {:.9f}'.format(epoch+1,training_epochs,total_cost/num_batch)) #进行预测处理 imgs, labs = sess.run([test_images, test_labels]) cost_values,accuracy_value = sess.run([cost,accuracy],feed_dict = {input_images:imgs,input_labels:labs,is_training:False}) print('Epoch {}/{} Test cost {:.9f}'.format(epoch+1,training_epochs,cost_values)) print('准确率:',accuracy_value) #保存模型 save.save(sess,os.path.join(train_log_dir,train_log_file),global_step = epoch) print('Epoch {}/{} 模型保存成功'.format(epoch+1,training_epochs)) print('训练完成') #终止线程 coord.request_stop() coord.join(threads) def flowers_test(): ''' 使用微调好的网络进行测试 ''' ''' 1.设置参数,并加载数据 ''' #微调后的检查点文件和日志文件路径 save_dir = './log/vgg16/fine_tune' #设置batch_size batch_size = 128 #加载数据 train_images, train_labels = input_data.get_batch_images_and_label(DATA_DIR,batch_size,NUM_CLASSES,True,IMAGE_SIZE,IMAGE_SIZE) test_images, test_labels = input_data.get_batch_images_and_label(DATA_DIR,batch_size,NUM_CLASSES,False,IMAGE_SIZE,IMAGE_SIZE) #获取模型参数的命名空间 arg_scope = vgg.vgg_arg_scope() #创建网络 with slim.arg_scope(arg_scope): ''' 2.定义占位符和网络结构 ''' #输入图片 input_images = tf.placeholder(dtype=tf.float32,shape = [None,IMAGE_SIZE,IMAGE_SIZE,3]) #训练还是测试?测试的时候弃权参数会设置为1.0 is_training = tf.placeholder(dtype = tf.bool) #创建vgg16网络 logits,end_points = vgg.vgg_16(input_images, is_training=is_training,num_classes = NUM_CLASSES) #预测标签 pred = tf.argmax(logits,axis=1) restorer = tf.train.Saver() #恢复模型 with tf.Session() as sess: sess.run(tf.global_variables_initializer()) ckpt = tf.train.latest_checkpoint(save_dir) if ckpt != None: #恢复模型 restorer.restore(sess,ckpt) print("Model restored.") #创建一个协调器,管理线程 coord = tf.train.Coordinator() #启动QueueRunner, 此时文件名才开始进队。 threads = tf.train.start_queue_runners(sess=sess,coord=coord) ''' 查看预处理之后的图片 ''' imgs, labs = sess.run([test_images, test_labels]) print('原始测试图片信息:',imgs.shape,labs.shape) show_img = np.array(imgs[0],dtype=np.uint8) plt.imshow(show_img) plt.title('Original test image') plt.show() pred_value = sess.run(pred,feed_dict = {input_images:imgs,is_training:False}) print('预测结果为:',pred_value) print('实际结果为:',np.argmax(labs,1)) correct = np.equal(pred_value,np.argmax(labs,1)) print('准确率为:', np.mean(correct)) #终止线程 coord.request_stop() coord.join(threads) if __name__ == '__main__': tf.reset_default_graph() flowers_fine_tuning() flowers_test()
这里我在训练的时候,冻结了出输出层之外的所有层,运行结果如下:
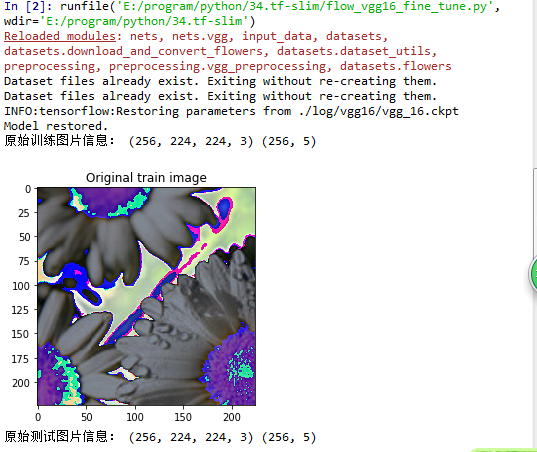
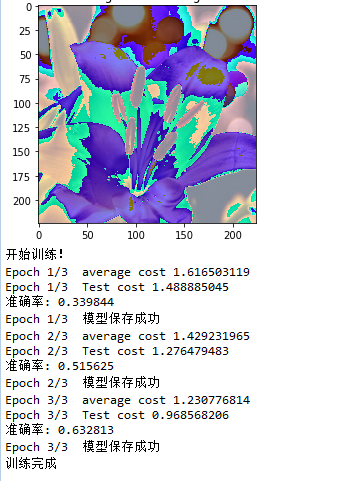

三轮之后,我们可以看到准确率大概在60%。
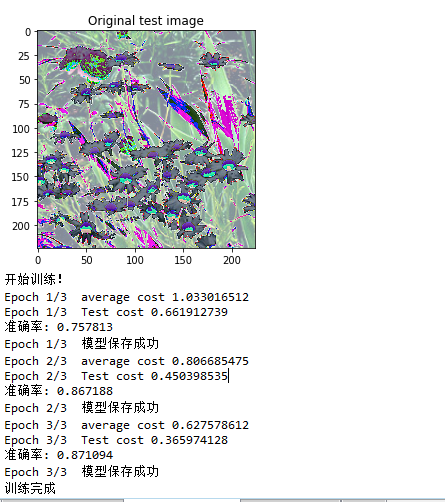
如果我们不冻结其它层,(训练所有层,速度慢),3轮下来,准确率可以达到90%左右。
2.Slim库实现代码
使用slim库简化上面的代码:
def flowers_simple_fine_tuning(): ''' 演示一个VGG16的例子 微调 这里只调整VGG16最后一层全连接层,把1000类改为5类 对网络进行训练 使用slim库简化代码 ''' batch_size = 128 learning_rate = 1e-4 #用于保存微调后的检查点文件和日志文件路径 train_log_dir = './log/vgg16/slim_fine_tune' #官方下载的检查点文件路径 checkpoint_file = './log/vgg16/vgg_16.ckpt' if not tf.gfile.Exists(train_log_dir): tf.gfile.MakeDirs(train_log_dir) #创建一个图,作为当前图 with tf.Graph().as_default(): #加载数据 train_images, train_labels = input_data.get_batch_images_and_label(DATA_DIR,batch_size,NUM_CLASSES,True,IMAGE_SIZE,IMAGE_SIZE) #创建vgg16网络 如果想冻结所有层,可以指定slim.conv2d中的 trainable=False logits,end_points = vgg.vgg_16(train_images, is_training=True,num_classes = NUM_CLASSES) #交叉熵代价函数 slim.losses.softmax_cross_entropy(logits, onehot_labels=train_labels) total_loss = slim.losses.get_total_loss() #设置写入到summary中的变量 tf.summary.scalar('losses/total_loss', total_loss) ''' 设置优化器 这里不能指定成Adam优化器,因为我们的官方模型文件中使用的就是GradientDescentOptimizer优化器, 因此我们要和官方模型一致,如果想使用AdamOptimizer优化器,我们可以在调用完vgg16()网络后,就执行恢复模型。 而把执行恢复模型的代码放在后面,会由于我们在当前图中定义了一些检查点中不存在变量,恢复时在检查点文件找不 到变量,因此会报错。 ''' optimizer = tf.train.GradientDescentOptimizer(learning_rate) #optimizer = tf.train.AdamOptimizer(learning_rate) # create_train_op that ensures that when we evaluate it to get the loss, # the update_ops are done and the gradient updates are computed. train_tensor = slim.learning.create_train_op(total_loss, optimizer) #检查最近的检查点文件 ckpt = tf.train.latest_checkpoint(train_log_dir) if ckpt != None: variables_to_restore = slim.get_model_variables() init_fn = slim.assign_from_checkpoint_fn(ckpt,variables_to_restore) print('从上次训练保存后的模型继续训练!') else: # Restore only the convolutional layers: 从检查点载入除了fc8层之外的参数到当前图 variables_to_restore = slim.get_variables_to_restore(exclude=['vgg_16/fc8']) init_fn = slim.assign_from_checkpoint_fn(checkpoint_file, variables_to_restore) print('从官方模型加载训练!') print('开始训练!') #开始训练网络 slim.learning.train(train_tensor, train_log_dir, number_of_steps=100, #迭代次数 一次迭代batch_size个样本 save_summaries_secs=300, #存summary间隔秒数 save_interval_secs=300, #存模模型间隔秒数 init_fn=init_fn)
上面的代码中我们用到了input_data.py文件,主要负责加载数据集,程序如下:


# -*- coding: utf-8 -*- """ Created on Fri Jun 8 08:52:30 2018 @author: zy """ ''' 导入flowers数据集 ''' from datasets import download_and_convert_flowers from preprocessing import vgg_preprocessing from datasets import flowers import tensorflow as tf slim = tf.contrib.slim def read_flower_image_and_label(dataset_dir,is_training=False): ''' 下载flower_photos.tgz数据集 切分训练集和验证集 并将数据转换成TFRecord格式 5个训练数据文件(3320),5个验证数据文件(350),还有一个标签文件(存放每个数字标签对应的类名) args: dataset_dir:数据集所在的目录 is_training:设置为TRue,表示加载训练数据集,否则加载验证集 return: image,label:返回随机读取的一张图片,和对应的标签 ''' download_and_convert_flowers.run(dataset_dir) ''' 利用slim读取TFRecord中的数据 ''' #选择数据集train if is_training: dataset = flowers.get_split(split_name = 'train',dataset_dir=dataset_dir) else: dataset = flowers.get_split(split_name = 'validation',dataset_dir=dataset_dir) #创建一个数据provider provider = slim.dataset_data_provider.DatasetDataProvider(dataset) #通过provider的get随机获取一条样本数据 返回的是两个张量 [image,label] = provider.get(['image','label']) return image,label def get_batch_images_and_label(dataset_dir,batch_size,num_classes,is_training=False,output_height=224, output_width=224,num_threads=10): ''' 每次取出batch_size个样本 注意:这里预处理调用的是slim库图片预处理的函数,例如:如果你使用的vgg网络,就调用vgg网络的图像预处理函数 如果你使用的是自己定义的网络,则可以自己写适合自己图像的预处理函数,比如归一化处理也可以使用其他网络已经写好的预处理函数 args: dataset_dir:数据集所在的目录 batch_size:一次取出的样本数量 num_classes:输出的类别 用于对标签one_hot编码 is_training:设置为TRue,表示加载训练数据集,否则加载验证集 output_height:输出图片高度 output_width:输出图片宽 return: images,labels:返回随机读取的batch_size张图片,和对应的标签one_hot编码 ''' #获取单张图像和标签 image,label = read_flower_image_and_label(dataset_dir,is_training) # 图像预处理 这里要求图片数据是tf.float32类型的 image = vgg_preprocessing.preprocess_image(image, output_height, output_width,is_training=is_training) #缩放处理 #image = tf.image.convert_image_dtype(image, dtype=tf.float32) #image = tf.image.resize_image_with_crop_or_pad(image, output_height, output_width) # shuffle_batch 函数会将数据顺序打乱 # bacth 函数不会将数据顺序打乱 images, labels = tf.train.batch( [image, label], batch_size = batch_size, capacity=5 * batch_size, num_threads = num_threads) #one-hot编码 labels = slim.one_hot_encoding(labels,num_classes) return images,labels
3.CNN网络代码,与vgg16微调效果对比
我们这里使用三层的cnn网络对flower数据集进行分类,测试一下其效果如何:
# -*- coding: utf-8 -*- """ Created on Fri Jun 8 08:51:45 2018 @author: zy """ ''' 使用卷积神经网络训练flowers数据集 用来和微调后的VGG网络对比 ''' import tensorflow as tf import input_data import numpy as np slim = tf.contrib.slim def cnn(inputs,num_classes=5): ''' 定义一个cnn网络结构 args: inputs:输入形状为[batch_size,in_height,in_width,in_channel] 输入图片大小为224 x 224 x3 num_classes:类别数 ''' with tf.variable_scope('cnn'): with slim.arg_scope([slim.conv2d,slim.fully_connected,slim.max_pool2d,slim.avg_pool2d], padding='SAME', ): net = slim.conv2d(inputs,64,[5,5],4,weights_initializer=tf.truncated_normal_initializer(stddev=0.01),scope='conv1') #batch_size x 56 x 56 x64 net = slim.max_pool2d(net,[2,2],scope='pool1') #batch_size x 28 x 28 x64 net = slim.conv2d(net,64,[3,3],2,weights_initializer=tf.truncated_normal_initializer(stddev=0.01),scope='conv2') #batch_size x 14 x 14 x64 net = slim.max_pool2d(net,[2,2],scope='pool2') #batch_size x 7 x 7 x64 #net = slim.conv2d(net,num_classes,[7,7],7,weights_initializer=tf.truncated_normal_initializer(stddev=0.01),scope='conv3') #batch_size x 1 x 1 x num_classes net = slim.conv2d(net,num_classes,[1,1],1,weights_initializer=tf.truncated_normal_initializer(stddev=0.01),scope='conv3') #batch_size x7 x 7 xnum_classes net = slim.avg_pool2d(net,[7,7],7,scope='pool3') #全局平均池化层 net = tf.squeeze(net,[1,2]) #batch_size x num_classes return net DATA_DIR = './datasets/data/flowers' #输出类别 NUM_CLASSES = 5 IMAGE_SIZE = 224 def flower_cnn(): ''' 使用CNN网络训练flower数据集 ''' #设置batch_size batch_size = 128 learning_rate = 1e-4 #训练集数据长度 n_train = 3320 #测试集数据长度 #n_test = 350 #迭代轮数 training_epochs = 20 display_epoch = 1 #加载数据 train_images, train_labels = input_data.get_batch_images_and_label(DATA_DIR,batch_size,NUM_CLASSES,True,IMAGE_SIZE,IMAGE_SIZE) test_images, test_labels = input_data.get_batch_images_and_label(DATA_DIR,batch_size,NUM_CLASSES,True,IMAGE_SIZE,IMAGE_SIZE) #定义占位符 input_images = tf.placeholder(dtype=tf.float32,shape = [None,IMAGE_SIZE,IMAGE_SIZE,3]) input_labels = tf.placeholder(dtype=tf.float32,shape = [None,NUM_CLASSES]) is_training = tf.placeholder(dtype = tf.bool) #创建cnn网络 logits = cnn(input_images,num_classes = NUM_CLASSES) #预测标签 pred = tf.argmax(logits,axis=1) #代价函数 cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=input_labels,logits=logits)) #设置优化器 optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost) #预测结果评估 correct = tf.equal(pred,tf.argmax(input_labels,1)) #返回一个数组 表示统计预测正确或者错误 accuracy = tf.reduce_mean(tf.cast(correct,tf.float32)) #求准确率 num_batch = int(np.ceil(n_train / batch_size)) ''' 启动会话,开始训练 ''' with tf.Session() as sess: sess.run(tf.global_variables_initializer()) #创建一个协调器,管理线程 coord = tf.train.Coordinator() #启动QueueRunner, 此时文件名才开始进队。 threads=tf.train.start_queue_runners(sess=sess,coord=coord) print('开始训练!') for epoch in range(training_epochs): total_cost = 0.0 for i in range(num_batch): imgs, labs = sess.run([train_images, train_labels]) _,loss = sess.run([optimizer,cost],feed_dict={input_images:imgs,input_labels:labs,is_training:True}) total_cost += loss #打印信息 if epoch % display_epoch == 0: print('Epoch {}/{} Train average cost {:.9f}'.format(epoch+1,training_epochs,total_cost/num_batch)) #进行预测处理 imgs, labs = sess.run([test_images, test_labels]) cost_values,accuracy_value = sess.run([cost,accuracy],feed_dict = {input_images:imgs,input_labels:labs,is_training:False}) print('Epoch {}/{} Test cost {:.9f}'.format(epoch+1,training_epochs,cost_values)) print('准确率:',accuracy_value) print('训练完成') #终止线程 coord.request_stop() coord.join(threads) if __name__ == '__main__': tf.reset_default_graph() flower_cnn()
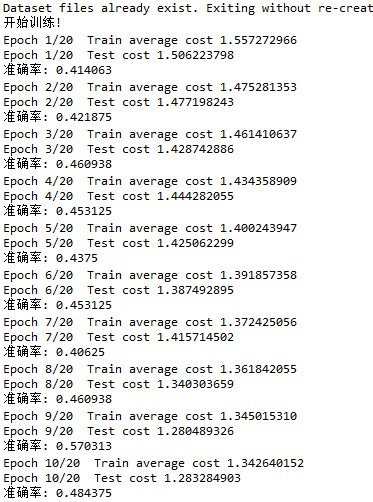
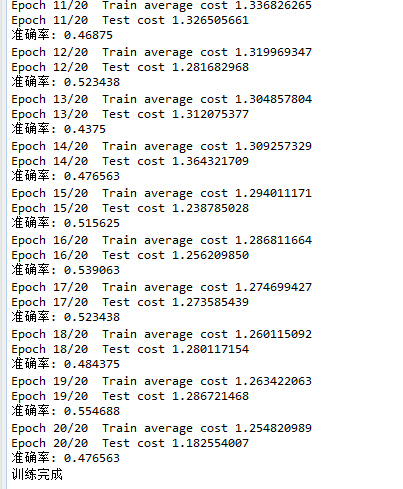
我们可以看到20轮下来准确率大概在55%,效果并不是很好。而使用vgg16微调的效果明显更高。
参考文章
[1]【Tensorflow】辅助工具篇——tensorflow slim(TF-Slim)介绍
[2]TF-Slim简介