认识Jsoup
一个解析网页的工具
无论你用什么语言爬虫,都要解析网页,今天,我们用一款常用的网页解析Jsoup,来开启爬虫的第一课
认识网页,认识爬虫,认识你自己
快速上手
了解一个新东西最快的方法就是频繁的使用和练习,让我们从最基础的地方开始
- 解析一个HTML字符串
// 使用静态Jsoup.parse(String html) 方法或 Jsoup.parse(String html, String baseUri)
val html = "<html><head><title>First parse</title> </head><body><p>Parsed HTML into a doc.</p></body></html>"
val doc = Jsoup.parse(html)
println(doc)
输出如图:

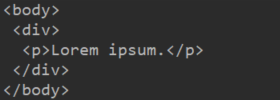
- 解析一个body片断
// 使用Jsoup.parseBodyFragment(String html)
val html ="<div><p>Lorem ipsum.</p>"
val doc = Jsoup.parseBodyFragment(html)
println(doc.body())
输出如图:
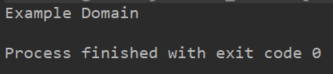
- 从一个URL加载一个Document
示例网站,网站结构如下:

// 使用Jsoup.parseBodyFragment(String html)
val doc:Document = Jsoup.connect("http://example.com/").get()
val title = doc.title()
println(title)
输出如图:
说明
connect(String url) 方法创建一个新的 Connection, 和 get() 取得和解析一个HTML文件。如果从该URL获取HTML时发生错误,便会抛出 IOException,应适当处理
val doc:Document = Jsoup.connect("http://example.com") //要链接的网址
.data("query", "Java") //添加链接信息
.userAgent("Mozilla") //模拟浏览器
.cookie("auth", "token") //模拟cookie
.timeout(3000) //设置超时时长,单位ms
.post() //链接方式
到这里为止,你应该对Jsoup不陌生了,接下来,讲解一下爬虫中Jsoup最常用的部分
常用方法(核心)
解析网页的过程,其实就是一个逐级选中的过程
讲解具体方法之前,先给大家上一个简单安全的框架:
// 爬取的网址
val url = "https://www.zhihu.com/explore/recommendations"
// 加上TryCatch框架
Try(Jsoup.connect(url).get())match {
case Failure(e) =>
// 打印异常信息
println(e.getMessage)
case Success(doc:Document) =>
// 解析正常则返回Document,然后提取Document内所需信息
println(doc.body())
}
有了这个框架之后,我们就可以更加肆无忌惮的调试我们的代码了
下面我们通过知乎推荐这个网站来讲解Jsoup的核心函数
网站URL: https://www.zhihu.com/explore/recommendations
网页内容如下:
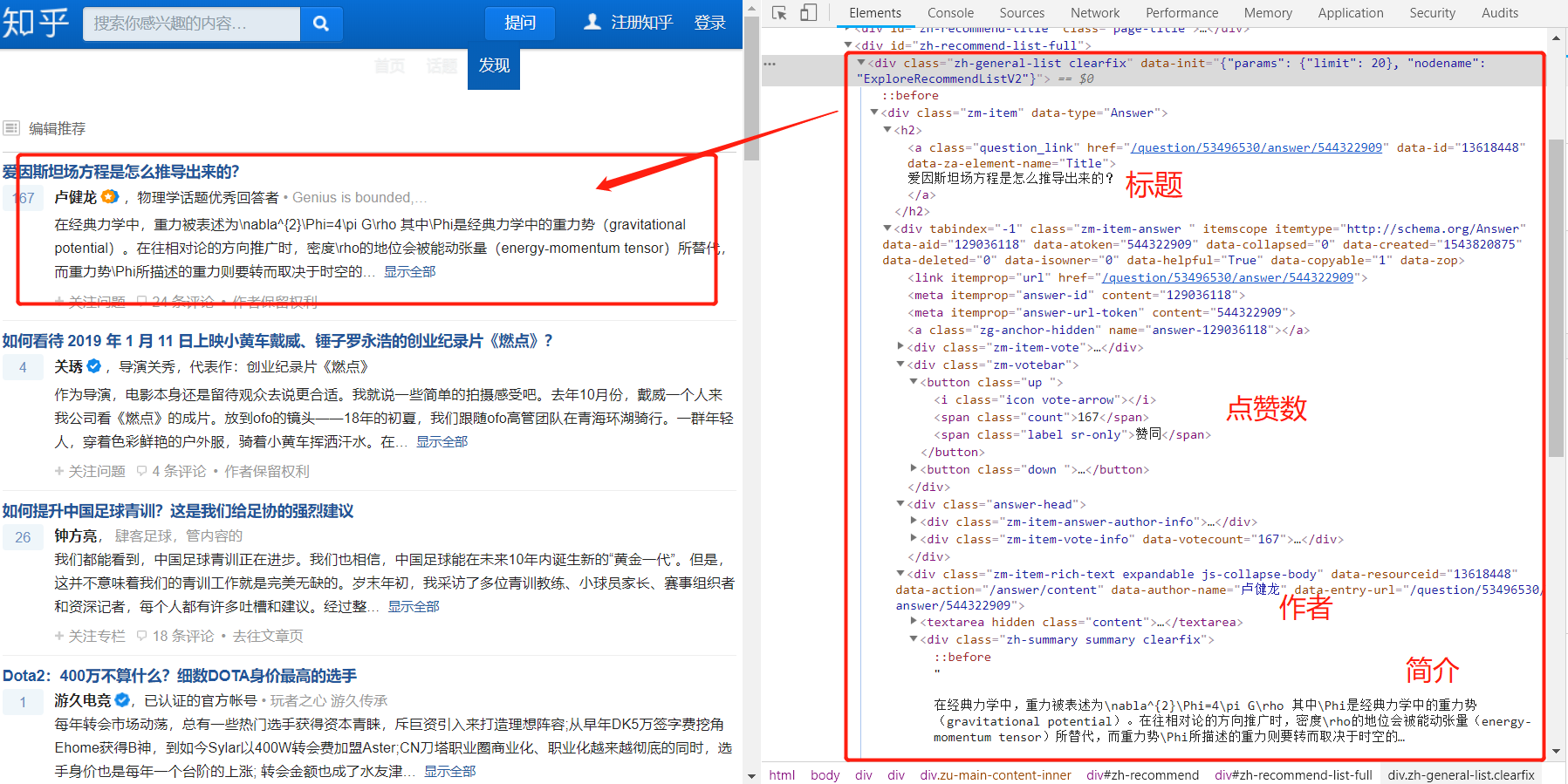
我们要解析的内容如下:
- 标题
- 点赞
- 作者
- 简介
下面我们一点一点来解析这个网页:
- 首先是标题提取
// 爬取的网址
val url = "https://www.zhihu.com/explore/recommendations"
// 加上TryCatch框架
Try(Jsoup.connect(url).get())match {
case Failure(e) =>
// 打印异常信息
println(e.getMessage)
case Success(doc:Document) =>
// 解析正常则返回Document,然后提取Document内所需信息
val links = doc.select("div.zm-item") //选取class为"zm-item"的div
for (link<-links.asScala){ //遍历每一个这样的div
val title = link.select("h2").text() //选取div中的所有"h2"标签,并读取它的文本内容
println(title) //打印标题
}
}
输出结果如下:
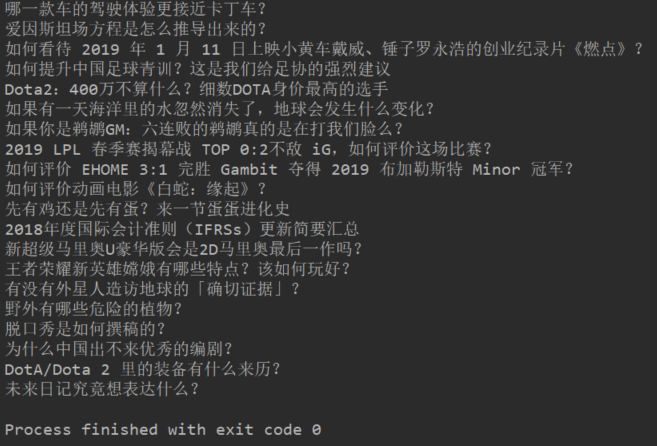
- 点赞,作者,简介的提取大同小异
// 爬取的网址
val url = "https://www.zhihu.com/explore/recommendations"
// 加上TryCatch框架
Try(Jsoup.connect(url).get())match {
case Failure(e) =>
// 打印异常信息
println(e.getMessage)
case Success(doc:Document) =>
// 解析正常则返回Document,然后提取Document内所需信息
val links = doc.select("div.zm-item") //选取class为"zm-item"的div
for (link<-links.asScala){ //遍历每一个这样的div
val title = link.select("h2").text() //选取div中的所有"h2"标签,并读取它的文本内容
val approve = link.select("div.zm-item-vote").text() //找到赞同的位置,选中它并读取它的文本内容
//逐层找到唯一识别的标签,然后选中(唯一识别很关键)
val author = link.select("div.answer-head").select("span.author-link-line").select("a").text()
// val content = link.select("div.zm-item-answer").select("div[data-action=/answer/content]")
// .select(":not(.content)").first().text() //对比下面简洁直接的定位
val content = link.select("div.zh-summary.summary.clearfix").text() //多个class类型,直接加.就行,如.A.B.C
println("标题:"+title) //打印标题
println("赞同:"+approve) //打印回答点赞数
println("作者:"+author) //打印作者
println("回答简介:"+content) //打印回答简介
}
}

ps:只要能定位到你想提取的文本,自然是越简洁越好
有时间的话,强烈推荐跟着官网练习一下,我也只是带着你练习而已,学会阅读文档,是一项很重要的技能
文档中是Java语法写的,如果你看的代码多了,你会发现,什么Java,scala,python,都是工具(完了完了,我膨胀了)
最常用到的是其中的 使用选择器语法来查找元素
结尾唠叨两句
如果你对我的文章感兴趣,欢迎你点开我下一篇文章,后面我将手把手带你一起完成一个个小case,对了如果你也有好的想法,欢迎沟通交流
今天的评论区强烈欢迎大家讲讲爬网站遇到的问题
如果有种子链接,免费代爬,苍老师是世界的!
结尾附上 使用选择器语法来查找元素 方法,以便大家快速查找
-
Selector选择器概述
- tagname: 通过标签查找元素,比如:a
- ns|tag: 通过标签在命名空间查找元素,比如:可以用 fb|name 语法来查找 fb:name 元素
-
id: 通过ID查找元素,比如:#logo
- .class: 通过class名称查找元素,比如:.masthead
- [attribute] : 利用属性查找元素,比如:[href]
- [attr=value] : 利用属性值来查找元素,比如:[width=500]
- [attr^=value], [attr$=value], [attr=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如:[href=/path/]
- [attr~=regex]: 利用属性值匹配正则表达式来查找元素,比如: img[src~=(?i).(png|jpe?g)]
- *: 这个符号将匹配所有元素
-
Selector选择器组合使用
- el#id: 元素+ID,比如: div#logo
- el.class: 元素+class,比如: div.masthead
- el[attr]: 元素+class,比如: a[href]
- 任意组合,比如:a[href].highlight
- ancestor child: 查找某个元素下子元素,比如:可以用.body p 查找在"body"元素下的所有 p元素
- parent > child: 查找某个父元素下的直接子元素,比如:可以用div.content > p 查找 p 元素,也可以用body > * 查找body标签下所有直接子元素
- siblingA + siblingB: 查找在A元素之前第一个同级元素B,比如:div.head + div
- siblingA ~ siblingX: 查找A元素之前的同级X元素,比如:h1 ~ p
- el, el, el:多个选择器组合,查找匹配任一选择器的唯一元素,例如:div.masthead, div.logo
-
伪选择器selectors
- :lt(n): 查找哪些元素的同级索引值(它的位置在DOM树中是相对于它的父节点)小于n,比如:td:lt(3) 表示小于三列的元素
- :gt(n):查找哪些元素的同级索引值大于n,比如: div p:gt(2)表示哪些div中有包含2个以上的p元素
- :eq(n): 查找哪些元素的同级索引值与n相等,比如:form input:eq(1)表示包含一个input标签的Form元素
- :has(seletor): 查找匹配选择器包含元素的元素,比如:div:has(p)表示哪些div包含了p元素
- :not(selector): 查找与选择器不匹配的元素,比如: div:not(.logo) 表示不包含 class=logo 元素的所有 div 列表
- :contains(text): 查找包含给定文本的元素,搜索不区分大不写,比如: p:contains(jsoup)
- :containsOwn(text): 查找直接包含给定文本的元素
- :matches(regex): 查找哪些元素的文本匹配指定的正则表达式,比如:div:matches((?i)login)
- :matchesOwn(regex): 查找自身包含文本匹配指定正则表达式的元素
- 注意:上述伪选择器索引是从0开始的,也就是说第一个元素索引值为0,第二个元素index为1等