一、web应用
web应用程序是一种可以通过Web访问的应用程序,程序的最大好处是用户很容易访问应用程序,用户只需要有浏览器即可,不需要再安装其他软件。应用程序有两种模式C/S、B/S。C/S是客户端/服务器端程序,也就是说这类程序一般独立运行。而B/S就是浏览器端/服务器端应用程序,这类应用程序一般借助谷歌,火狐等浏览器来运行。WEB应用程序一般是B/S模式。Web应用程序首先是“应用程序”,和用标准的程序语言,如java,python等编写出来的程序没有什么本质上的不同。在网络编程的意义下,浏览器是一个socket客户端,服务器是一个socket服务端。
B/S架构,是浏览器先发送请求,服务器响应请求,返回数据给客户端。
简单socket服务器
举例:
新建server.py文件,代码如下:


import socket sk = socket.socket() sk.bind(('127.0.0.1',8800)) sk.listen() while True: print('server waiting...') conn,addr = sk.accept() # 服务器首先是接收数据 data = conn.recv(1024) # 打印接收信息 print('data',data) # 发送给客户端 conn.send(b'Hi,JD') conn.close() sk.close()
启动py文件,页面访问url:
http://127.0.0.1:8800/
网页输出:
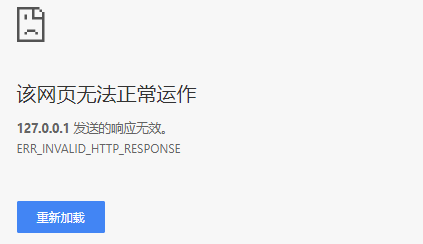
上面提示无效的响应,为什么?是因为服务器响应信息,不符合HTTP规范。
查看pycharm控制台的输出信息
data b'GET / HTTP/1.1 Host: 127.0.0.1:8800 Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Cookie: csrftoken=IwhDDZ9RiKQUV4T5CbzGIhAcVZNxYuvAYdS7RKc0tmOmk02hHWfQ8sWnIGrN1pzC '
它才是一个完整的HTTP请求信息。
更改socket代码,将conn.send改成下面的
conn.send(b'HTTP://1.1 200 OK Hi,JD')
重启py文件,再次访问页面
页面输出: Hi,JD
修饰返回信息
响应的信息,可以加入一些html标签,比如H1和img
import socket sk = socket.socket() sk.bind(('127.0.0.1',8800)) sk.listen() while True: print('server waiting...') conn,addr = sk.accept() # 服务器首先是接收数据 data = conn.recv(1024) # 打印接收信息 print('data',data) # 发送给客户端 html=b'<h1>Hi,JD</h1><img src="https://img20.360buyimg.com/da/jfs/t24334/1/45221916/115081/515da78a/5b2393d4N05f8a4c2.gif?t=1529495461508"/>' conn.send(b'HTTP://1.1 200 OK %s'%html) conn.close() sk.close()
重启py文件,再次访问页面,效果如下:

但是用字符串拼接,太麻烦了。
登录页面
可以引入一个index.html文件,来展示页面
新建文件index.html,代码如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <form action=""> <lable>用户名</lable> <input type="text"> <lable>密码</lable> <input type="text"> <input type="submit"> </form> </body> </html>
修改server.py,代码如下:
import socket sk = socket.socket() sk.bind(('127.0.0.1',8800)) sk.listen() while True: print('server waiting...') conn,addr = sk.accept() # 服务器首先是接收数据 data = conn.recv(1024) # 打印接收信息 print('data',data) # 发送给客户端 with open("index.html","rb") as f: #必须使用rb模式打开 data = f.read() # 读取所有内容 conn.send(b'HTTP://1.1 200 OK %s'%data) conn.close() sk.close()
重启py文件,再次访问页面,效果如下:

二、http协议简介
http协议简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于万维网(WWW:World Wide Web )服务器与本地浏览器之间传输超文本的传送协议。
HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。

http协议特性
(1) 基于TCP/IP
http协议是基于TCP/IP协议之上的应用层协议。
请求协议(浏览器-->服务器)
响应协议(服务器-->浏览器)
比如:张三要发送一段信息为李四。发送的信息为
s = "zhangsan--24--shanghai"
那么李四接收的时候,必须用--切割才能得到信息。否则李四不知道,这段信息是干啥的。这个是一个简单的基于内容的协议。
对于HTTP而言,服务器和浏览器双方遵循了共同的协议。
没有请求,就没有响应
(2) 基于请求-响应模式
HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并 返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有 接收到请求之前不会发送响应

(3) 无状态保存
HTTP是一种不保存状态,即无状态(stateless)协议。HTTP协议 自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个 级别,协议对于发送过的请求或响应都不做持久化处理。

使用HTTP协议,每当有新的请求发送时,就会有对应的新响应产 生。协议本身并不保留之前一切的请求或响应报文的信息。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把HTTP协议设计成 如此简单的。可是,随着Web的不断发展,因无状态而导致业务处理变得棘手 的情况增多了。比如,用户登录到一家购物网站,即使他跳转到该站的 其他页面后,也需要能继续保持登录状态。针对这个实例,网站为了能 够掌握是谁送出的请求,需要保存用户的状态。HTTP/1.1虽然是无状态协议,但为了实现期望的保持状态功能, 于是引入了Cookie技术。有了Cookie再用HTTP协议通信,就可以管 理状态了。有关Cookie的详细内容稍后讲解。
无连接
无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
比如访问jd网页,服务器响应请求,返回html代码给浏览器。浏览器接收后,连接就断开了。
扩展:还有一个短连接,比如请求响应之后,维持3秒。如果客户端没有操作,连接就断开了。
http请求协议与响应协议
http协议包含由浏览器发送数据到服务器需要遵循的请求协议与服务器发送数据到浏览器需要遵循的请求协议。用于HTTP协议交互的信被为HTTP报文。请求端(客户端)的HTTP报文 做请求报文,响应端(服务器端)的 做响应报文。HTTP报文本身是由多行数据构成的字 文本。
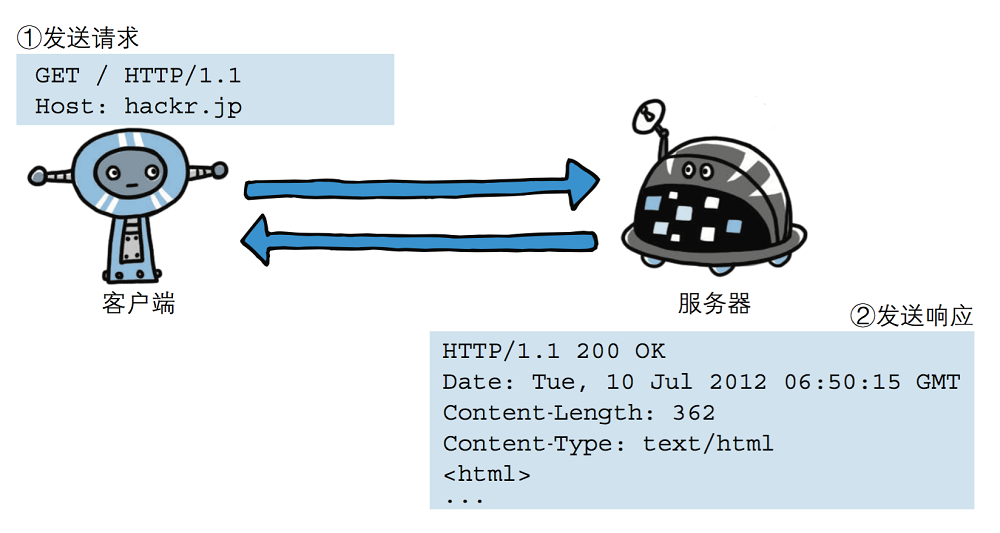
请求协议
请求格式
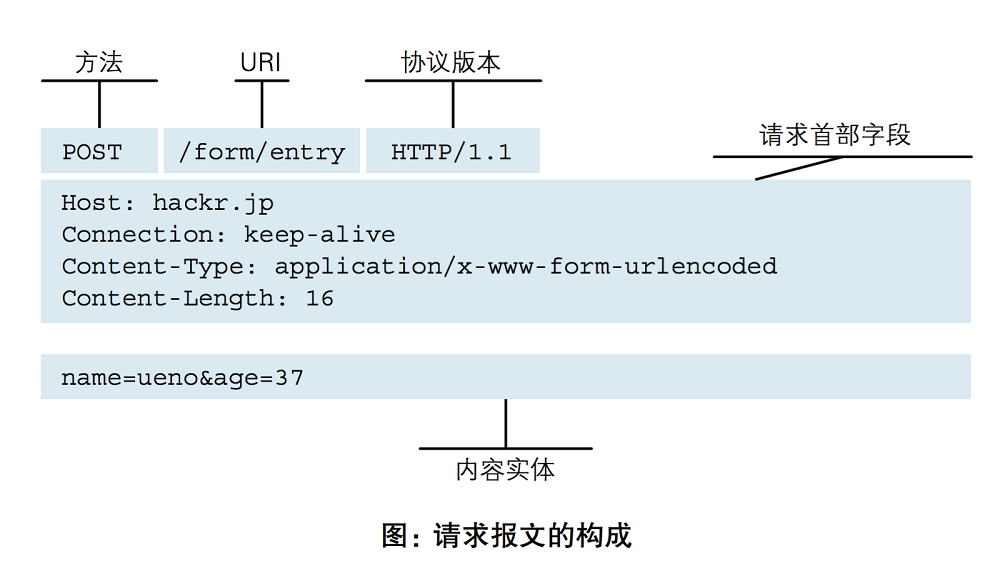
注意:name=ueno&age=37 上面有一个空行。
Host和Conten-Length 之间的内容属于请求体,它是用来解释本次请求的信息。
请求方式: get与post请求
-
GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的请求体中.
-
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
-
GET与POST请求在服务端获取请求数据方式不同。
响应协议
响应格式

请求协议(浏览器-->服务器)
" 请求首行:请求协议 url 请求方式 请求头: 它是key:value形式的数据 请求体...(注意:请求体和请求头,必须有一个空行,也就是/r/n) "
看下面2个url
https://passport.jd.com/new/login.aspx?
ReturnUrl=http%3A%2F%2Fhome.jd.com%2F http://127.0.0.1:8000/books/113/?age=18
第一个url使用了域名,它涉及到一个dns解析过程。域名后面没有端口,表示使用默认端口。https端口为443
第二个url,端口之后和问号之间的部分,叫做路径。不管多少层,只要没遇到问号,都属于路径部分。
问号之后的部分,叫做数据。
看这个url: https://www.jd.com/ 它的路径就是 / 。/表示根路径
所以一个完整的url由4部分组成:协议、域名/IP和端口、路径、数据
查看Pycharm控制台,使用谷歌浏览器访问一次网页。实际上,是有2次请求的。
data b'GET / HTTP/1.1 Host: 127.0.0.1:8800 Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Cookie: csrftoken=IwhDDZ9RiKQUV4T5CbzGIhAcVZNxYuvAYdS7RKc0tmOmk02hHWfQ8sWnIGrN1pzC ' server waiting... data b'GET /favicon.ico HTTP/1.1 Host: 127.0.0.1:8800 Connection: keep-alive User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36 Accept: image/webp,image/apng,image/*,*/*;q=0.8 Referer: http://127.0.0.1:8800/ Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Cookie: csrftoken=IwhDDZ9RiKQUV4T5CbzGIhAcVZNxYuvAYdS7RKc0tmOmk02hHWfQ8sWnIGrN1pzC '
第一次,是正常请求。第二次是,favicon.ico请求,它是网页图标问题。这个请求,忽略即可。
将/r/n替换为换行,得到以下信息
GET / HTTP/1.1 Host: 127.0.0.1:8800 Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Cookie: csrftoken=IwhDDZ9RiKQUV4T5CbzGIhAcVZNxYuvAYdS7RKc0tmOmk02hHWfQ8sWnIGrN1pzC
可以看到,GET的数据,是放到url后面的。POST数据是放在请求体后面的。
打个比方:比如早期时候,用的信封。get相当于,直接写在封面上了。post相当于写在信封里面了。
举例:
使用表单模拟post请求
更改index.html,代码如下:
注意:action不能和当前网页路径一样,比如http://127.0.0.1:8800,否则提交之后,页面会卡死。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <form action="/abc" method="post"> <lable>用户名</lable><input type="text" name="user"/> <lable>密码</lable><input type="password" name="pwd"/> <input type="submit"/> </form> </body> </html>
重启server.py文件,访问页面
输入用户名和密码,点击提交

查看pycharm的控制台,查看post请求
data b'POST /abc HTTP/1.1 Host: 127.0.0.1:8800 Connection: keep-alive Content-Length: 17 Cache-Control: max-age=0 Origin: http://127.0.0.1:8800 Upgrade-Insecure-Requests: 1 Content-Type: application/x-www-form-urlencoded User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Referer: http://127.0.0.1:8800/abc?user=xiao&pwd=123 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Cookie: csrftoken=IwhDDZ9RiKQUV4T5CbzGIhAcVZNxYuvAYdS7RKc0tmOmk02hHWfQ8sWnIGrN1pzC user=xiao&pwd=123'
看最后的信息,就可以看到user=xiao&pwd=123'
模拟get请求
修改index.html,代码如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <form action="" method="get"> <lable>用户名</lable><input type="text" name="user"/> <lable>密码</lable><input type="password" name="pwd"/> <input type="submit"/> </form> </body> </html>
输入用户名和密码,点击提交
发现url就发生变化了,数据保存到url中

响应协议(服务器-->浏览器)
响应首行: 请求协议 协议码 OK
响应头:key:value
响应体
注意:响应体和响应头有一个空行。
响应头,可要可不要。比如上面的socket,响应信息,就没有响应头。
响应体,是浏览器真正加载的内容。
使用谷歌浏览器打开网页,按f12打开控制台-->networkd-->点击左边的连接-->Respone,这里面就是响应体

浏览器发送也是一堆字符串
浏览器从服务器得到响应信息,也是拿到一堆字符串
增加一个响应头,比如Content-Type: text/html
修改server.py,代码如下:
#!/usr/bin/env python # -*- coding: utf-8 -*- import socket sk = socket.socket() sk.bind(('127.0.0.1',8800)) sk.listen(5) while True: print('server waiting...') conn,addr = sk.accept() # 服务器首先是接收数据 data = conn.recv(1024) # 打印接收信息 print('data',data) # 发送给客户端 with open("index.html","rb") as f: #必须使用rb模式打开 data = f.read() # 读取所有内容 conn.send(b'HTTP://1.1 200 OK Content-Type: text/html %s'%data) conn.close() sk.close()
重启socket.py,打开控制台,查看网络。访问网页http://127.0.0.1:8800/
发现多了一个响应头
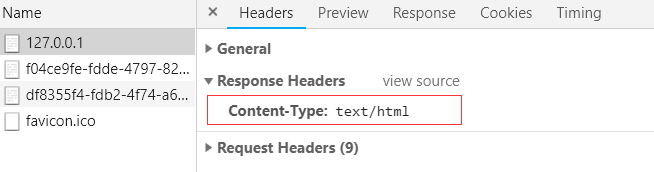
请求头和响应头,都是很有意义的
请求头有啥用呢?
比如这个:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36
爬虫应用,如果没有带user-agent。那么服务器,就拒绝请求。
响应式页面,也是通过user-agent来判断的
响应状态码
状态码的职 是当客户端向服务器端发送请求时, 返回的请求 结果。借助状态码,用户可以知道服务器端是正常 理了请求,还是出 现了 。状态码如200 OK,以3位数字和原因 成。数字中的 一位指定了响应 别,后两位无分 。响应 别有以5种。

以后会大量用到3xx状态
301 永久性重定向
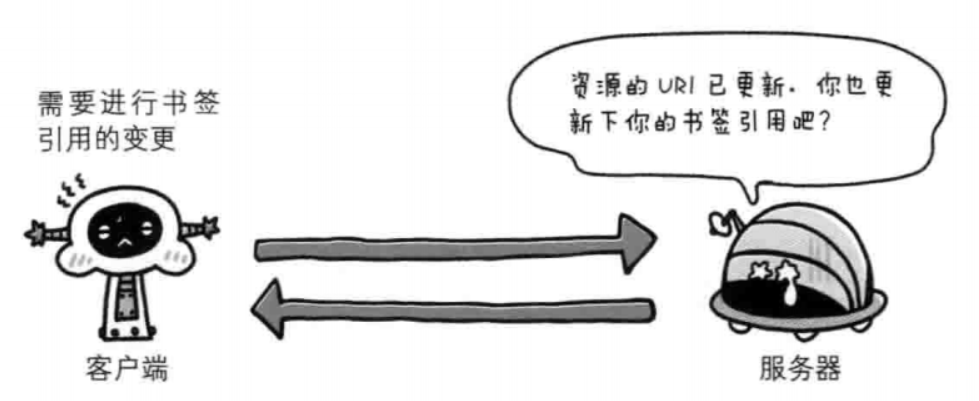
永久性重定向。该状态码表示请求的资源已被分配了新的UR1,以后应使用资源现在所指的URI。也就是说,如果已经把资源对应的UR1保存为书签了,这时应该按Location首部字段提示的UR1重新保存。
像下方给出的请求URI,当指定资源路径的最后忘记添加斜杠"/",就会产生301状态码。
http://example.com/sample
301使用2次请求。 一次是初始请求,第二次是访问新的链接。
302临时性重定向

临时性重定向。该状态码表示请求的资源已被分配了新的URI,希望用户(本次)能使用新的URI访问。
和301MovedPermanently状态码相似,但302状态码代表的资源不是被永久移动,只是临时性质的。换句话说,已移动的资源对应的URI将来还有可能发生改变。比如,用户把UR丨保存成书签,但不会像301状态码出现时那样去更新书签,而是仍旧保留返回302状态码的页面对应的UR1。
注意:面试会问道301和302的区别
《HTTP图解》这本书可以看一下
还有一本,《HTTP权威指南》这个太复杂了,目前可以不看。
三、web框架
Web框架
Web框架(Web framework)是一种开发框架,用来支持动态网站、网络应用和网络服务的开发。这大多数的web框架提供了一套开发和部署网站的方式,也为web行为提供了一套通用的方法。web框架已经实现了很多功能,开发人员使用框架提供的方法并且完成自己的业务逻辑,就能快速开发web应用了。浏览器和服务器的是基于HTTP协议进行通信的。也可以说web框架就是在以上十几行代码基础张扩展出来的,有很多简单方便使用的方法,大大提高了开发的效率。
wsgiref模块
最简单的Web应用就是先把HTML用文件保存好,用一个现成的HTTP服务器软件,接收用户请求,从文件中读取HTML,返回。
如果要动态生成HTML,就需要把上述步骤自己来实现。不过,接受HTTP请求、解析HTTP请求、发送HTTP响应都是苦力活,如果我们自己来写这些底层代码,还没开始写动态HTML呢,就得花个把月去读HTTP规范。
正确的做法是底层代码由专门的服务器软件实现,我们用Python专注于生成HTML文档。因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口协议来实现这样的服务器软件,让我们专心用Python编写Web业务。这个接口就是WSGI:Web Server Gateway Interface。而wsgiref模块就是python基于wsgi协议开发的服务模块。
由于url路径在请求信息,里面有大量的字符串.比如下面的一段消息:
GET /index/ HTTP/1.1 Host: 127.0.0.1:8800 Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Cookie: csrftoken=IwhDDZ9RiKQUV4T5CbzGIhAcVZNxYuvAYdS7RKc0tmOmk02hHWfQ8sWnIGrN1pzC
要得到/index/,可以使用正则、split切割...等方式。但是这样太麻烦了。
现在有一个内置模块wsgiref,它可以解析这些信息,并返回一个字典格式。那么就可以方便取数据了。
举例:
新建文件wsgiref_start.py,内容如下:
#!/usr/bin/env python # -*- coding: utf-8 -*- from wsgiref.simple_server import make_server #所有请求信息都在environ,它会传给application def application(environ, start_response): print(environ) #打印environ信息 start_response('200 OK', [('Content-Type', 'text/html')]) return [b'<h1>Hello, web!</h1>'] #不写ip,默认监听本机ip地址 httpd = make_server('', 8888, application) print('Serving HTTP on port 8888...') # 开始监听HTTP请求: httpd.serve_forever()
运行py文件,访问页面
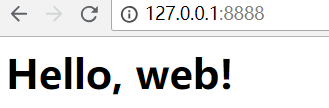
如果访问页面失败,尝试换一个端口,就可以了。
DIY一个web框架
访问首页,查看Pycharm控制台输出信息,这就是完整的environ信息,返回的是字典格式。
{'wsgi.errors': <_io.TextIOWrapper name='<stderr>' mode='w'
encoding='UTF-8'>, 'PROCESSOR_ARCHITECTURE': 'AMD64', 'HOMEPATH': '\Users\xiao', 'PATH':
'C:\Python35\Scripts\;C:\Python35\;C:\Program
Files\Python36\Scripts\;C:\Program Files\Python36\;C:\Program
Files (x86)\Common Files\NetSarang;C:\Program Files
(x86)\Intel\iCLS Client\;C:\Program
Files\Intel\iCLS Client\;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;C:\Program
Files (x86)\NVIDIA Corporation\PhysX\Common;C:\Program Files
(x86)\Intel\Intel(R) Management Engine Components\DAL;C:\Program Files\Intel\Intel(R) Management Engine Components\DAL;C:\Program Files
(x86)\Intel\Intel(R) Management Engine Components\IPT;C:\Program Files\Intel\Intel(R) Management Engine Components\IPT;C:\Program Files\Intel\WiFi\bin\;C:\Program Files\Common
Files\Intel\WirelessCommon\;D:\Program Files\Git\bin;C:\Program Files (x86)\Windows Kits\8.1\Windows Performance Toolkit\;C:\WINDOWS\system32;C:\WINDOWS;C:\WINDOWS\System32\Wbem;C:\WINDOWS\System32\WindowsPowerShell\v1.0\;D:\Program
Files (x86)\ffmpeg-20180518-16b4f97-win64-shared\bin;C:\Program Files\nodejs\;D:\Program Files (x86)\mysql-5.7.22-winx64\bin;C:\Users\xiao\AppData\Local\Microsoft\WindowsApps;D:\Program Files\Git\bin;C:\Users\xiao\AppData\Roaming\npm;C:\Python35\lib\site-packages\numpy\.libs', 'COMMONPROGRAMFILES': 'C:\Program Files\Common Files', 'COMSPEC': 'C:\WINDOWS\system32\cmd.exe', 'HTTP_ACCEPT': 'image/webp,image/apng,image/*,*/*;q=0.8', 'PATH_INFO': '/favicon.ico', 'HTTP_REFERER': 'http://127.0.0.1:8888/', 'COMMONPROGRAMW6432': 'C:\Program Files\Common Files', 'PYCHARM_MATPLOTLIB_PORT': '50111', 'HTTP_USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36', 'LOCALAPPDATA': 'C:\Users\xiao\AppData\Local', 'PROGRAMDATA': 'C:\ProgramData', 'SERVER_PROTOCOL': 'HTTP/1.1', 'WINDIR': 'C:\WINDOWS', 'VS140COMNTOOLS': 'C:\Program Files (x86)\Microsoft Visual Studio 14.0\Common7\Tools\', 'ALLUSERSPROFILE': 'C:\ProgramData', 'REQUEST_METHOD': 'GET', 'OS': 'Windows_NT', 'USERDOMAIN_ROAMINGPROFILE': 'DESKTOP-CFMVJ8G', 'HTTP_ACCEPT_ENCODING': 'gzip, deflate, br', 'PROGRAMFILES(X86)': 'C:\Program Files (x86)', 'REMOTE_HOST': '', 'SCRIPT_NAME': '', 'APPDATA': 'C:\Users\xiao\AppData\Roaming', 'HTTP_HOST': '127.0.0.1:8888', 'wsgi.multiprocess': False, 'GATEWAY_INTERFACE': 'CGI/1.1', 'wsgi.version': (1, 0), 'PROCESSOR_LEVEL': '6', 'SERVER_SOFTWARE': 'WSGIServer/0.2', 'wsgi.file_wrapper': <class 'wsgiref.util.FileWrapper'>, 'COMPUTERNAME': 'DESKTOP-CFMVJ8G', 'SESSIONNAME': 'Console', 'REMOTE_ADDR': '127.0.0.1', 'CONTENT_TYPE': 'text/plain', 'SYSTEMROOT': 'C:\WINDOWS', 'HTTP_CONNECTION': 'keep-alive', 'TEMP': 'C:\Users\xiao\AppData\Local\Temp', 'PATHEXT': '.COM;.EXE;.BAT;.CMD;.VBS;.VBE;.JS;.JSE;.WSF;.WSH;.MSC;.PY;.PYW', 'SERVER_NAME': 'DESKTOP-CFMVJ8G', 'LOGONSERVER': '\\DESKTOP-CFMVJ8G', 'PROGRAMW6432': 'C:\Program Files', 'HOMEDRIVE': 'C:', 'HTTP_ACCEPT_LANGUAGE': 'zh-CN,zh;q=0.9', 'QUERY_STRING': '', 'PUBLIC': 'C:\Users\Public', 'PROCESSOR_REVISION': '5e03', 'USERNAME': 'xiao', 'wsgi.run_once': False, 'PYTHONPATH': 'C:\Program Files\JetBrains\PyCharm 2018.1.1\helpers\pycharm_matplotlib_backend;E:\python_script', 'VS90COMNTOOLS': 'D:\Program Files (x86)\Microsoft Visual Studio 9.0\Common7\Tools\', 'PYCHARM_HOSTED': '1', 'USERPROFILE': 'C:\Users\xiao', 'COMMONPROGRAMFILES(X86)': 'C:\Program Files (x86)\Common Files', 'PROCESSOR_IDENTIFIER': 'Intel64 Family 6 Model 94 Stepping 3, GenuineIntel', 'TMP': 'C:\Users\xiao\AppData\Local\Temp', 'PROGRAMFILES': 'C:\Program Files', 'wsgi.multithread': True, 'USERDOMAIN': 'DESKTOP-CFMVJ8G', 'HTTP_COOKIE': 'csrftoken=IwhDDZ9RiKQUV4T5CbzGIhAcVZNxYuvAYdS7RKc0tmOmk02hHWfQ8sWnIGrN1pzC', 'PSMODULEPATH': 'C:\Program Files\WindowsPowerShell\Modules;C:\WINDOWS\system32\WindowsPowerShell\v1.0\Modules', 'SERVER_PORT': '8888', 'PYTHONUNBUFFERED': '1', 'wsgi.input': <_io.BufferedReader name=340>, 'NUMBER_OF_PROCESSORS': '8', 'SYSTEMDRIVE': 'C:', 'CONTENT_LENGTH': '', 'wsgi.url_scheme': 'http', 'PYTHONIOENCODING': 'UTF-8'}
PATH_INFO就是请求路径
上面信息太多了,只打印PATH_INFO,更改print(environ)为:
print('path:',environ.get("PATH_INFO"))
重启py文件,再次访问页面,查看pycharm控制台,输出
path: / 127.0.0.1 - - [20/Jun/2018 23:22:33] "GET / HTTP/1.1" 200 20 127.0.0.1 - - [20/Jun/2018 23:22:33] "GET /favicon.ico HTTP/1.1" 200 20 path: /favicon.ico
得到路径,就可以根据路径判断,来渲染不同的html文件了
创建index.html,代码如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <h3>Index</h3> </body> </html>
创建login.html,代码如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <form action="/abc" method="post"> <lable>用户名</lable><input type="text" name="user"/> <lable>密码</lable><input type="password" name="pwd"/> <input type="submit"/> </form> </body> </html>
编辑wsgiref_start.py文件,加入路径判断.
#!/usr/bin/env python # -*- coding: utf-8 -*- from wsgiref.simple_server import make_server #所有请求信息都在environ,它会传给application def application(environ, start_response): # print('path:',environ.get("PATH_INFO")) path = environ.get("PATH_INFO") start_response('200 OK', [('Content-Type', 'text/html')]) if path == '/login/': # 注意路径后面,必须有/ with open("login.html","rb") as f: data = f.read() return [data] elif path == '/index/': with open("index.html","rb") as f: data = f.read() return [data] else: return [b"<h1>404</h1>"] #不写ip,默认监听本机ip地址 httpd = make_server('', 8888, application) print('Serving HTTP on port 8888...') # 开始监听HTTP请求: httpd.serve_forever()
重启py文件,访问以下url:
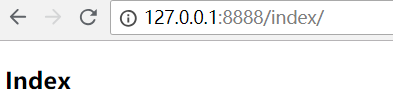
http://127.0.0.1:8888/index/
注意:index后面必须有一个/,否则输出404
页面输出:
http://127.0.0.1:8888/login/
注意:login后面必须有一个/,否则输出404
页面输出:

http://127.0.0.1:8888/abc/
访问不存在的,页面输出:

将url判断和页面输出部分,封装成函数,wsgiref_start.py代码如下:
#!/usr/bin/env python # -*- coding: utf-8 -*- from wsgiref.simple_server import make_server #视图函数,如果需要用到请求信息,必须要传environ变量 def login(environ): with open("login.html", "rb") as f: data = f.read() return data def index(environ): with open("index.html" , "rb") as f: data = f.read() return data #所有请求信息都在environ,它会传给application def application(environ, start_response): #当前访问路径 current_path = environ.get("PATH_INFO") #响应给客户端200状态 start_response('200 OK', [('Content-Type', 'text/html')]) #url控制,匹配url时,调用对应的视图函数 urlpatterns = [ ("/login/", login), ("/index/", index), ] #初始变量 func = None #遍历url列表 for item in urlpatterns: #当列表的url和当前访问路径相同时 if item[0] == current_path: #将视图函数赋值给func,注意:这里并没有执行函数 func = item[1] #这里必须要跳出循环 break #判断func变量不为None if func: ret = func(environ) # 执行视图函数,必须传入environ return [ret] # 返回给浏览器 else: return [b"<h1>404</h1>"] # 输出404页面 #不写ip,默认监听本机ip地址 httpd = make_server('', 8888, application) print('Serving HTTP on port 8888...') # 开始监听HTTP请求: httpd.serve_forever()
重启py文件,再次访问上面3个url。访问结果一致,说明ok了。
拆分代码
上面的代码,逻辑部分都集中在一个py中,这样不方便以后的扩展。
比如有30个url,写30个if判断吗?太low了。需要解耦
1. 分离url
新建urls.py文件,代码如下:
import views urlpatterns=[ ("/login/",views.login), ("/index/",views.index), ]
2.分离视图函数
新建views.py文件,代码如下:
def login(environ): with open("templates/login.html", "rb") as f: data = f.read() return data def index(environ): with open("templates/index.html" , "rb") as f: data = f.read() return data
3.分离模板文件,比如html文件
创建目录templates,将index.html和login.html移动到此目录
4.修改wsgiref_start.py文件,代码如下:
from wsgiref.simple_server import make_server from urls import urlpatterns # 导入自定义的urls模块 #所有请求信息都在environ,它会传给application def application(environ, start_response): #当前访问路径 current_path = environ.get("PATH_INFO") print(current_path) #响应给客户端200状态 start_response('200 OK', [('Content-Type', 'text/html')]) #初始变量 func = None #遍历url列表 for item in urlpatterns: #当列表的url和当前访问路径相同时 if item[0] == current_path: #将视图函数赋值给func,注意:这里并没有执行函数 func = item[1] #这里必须要跳出循环 break #判断func变量不为None if func: ret = func(environ) # 执行视图函数,必须传入environ return [ret] # 返回给浏览器 else: return [b"<h1>404</h1>"] # 输出404页面 #不写ip,默认监听本机ip地址 httpd = make_server('', 8888, application) print('Serving HTTP on port 8888...') # 开始监听HTTP请求: httpd.serve_forever()
重启pwsgiref_start.py文件,再次访问上面3个url。访问结果一致,说明ok了。
到这里,一个简单web框架,就完成了!
将当前文件夹打包,扔到别的电脑或者服务器,只有有python环境,就可以运行了。
新整页面
修改urls.py,增加一个路径timer,用来显示当前时间
import views urlpatterns=[ ("/login/",views.login), ("/index/",views.index), ("/timer/",views.timer) ]
修改views.py,增加一个视图函数
import datetime def login(environ): with open("templates/login.html", "rb") as f: data = f.read() return data def index(environ): with open("templates/index.html" , "rb") as f: data = f.read() return data def timer(environ): # 返回当前时间 # 获得当前时间 now = datetime.datetime.now() # 转换为指定的格式: otherStyleTime = now.strftime("%Y-%m-%d %H:%M:%S") return otherStyleTime.encode('utf-8') # 必须为bytes类型
重启pwsgiref_start.py文件,访问url:
http://127.0.0.1:8888/timer/
页面输出:
