原文链接地址:http://www.cnblogs.com/lyhabc/p/3732942.html
这一节主要介绍MYSQL里的基本查询(MYSQL官方参考手册)
MySQL中select的基本语法形式:
select 属性列表 from 表名和视图列表 [where 条件表达式] [group by 属性名[having 条件表达式]] [order by 属性名[asc|desc]] [limit <offset>,row count]
说明:
where子句:按照“条件表达式”指定的条件进行查询。
group by子句:按照“属性名”指定的字段进行分组。
having子句:有group by才能having子句,只有满足“条件表达式”中指定的条件的才能够输出。
group by子句通常和count()、sum()等聚合函数一起使用。
order by子句:按照“属性名”指定的字段进行排序。排序方式由“asc”和“desc”两个参数指出,默认是按照“asc”来排序,即升序。
建立测试表
创建测试表
CREATE TABLE fruits ( f_id CHAR(10) NOT NULL, s_id INT NOT NULL, f_name CHAR(255) NOT NULL, f_price DECIMAL(8,2) NOT NULL, PRIMARY KEY(f_id) )
插入测试数据
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('a1',101,'apple',5.2), ('b1',102,'blackberry',5.2), ('bs1',105,'orange',5.2), ('bs2',103,'melon',5.2), ('t1',106,'banana',5.2);
使用select语句查询f_id字段的数据
SELECT f_id,f_name FROM fruits
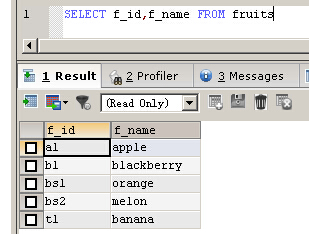
注意:MYSQL中SQL语句是不区分大小写的,因此select和SELECT作用是相同的
这一点跟SQLSERVER是一样的!
常用查询
SELECT * FROM fruitsSELECT f_id,f_name FROM fruits WHERE f_price >5.1SELECT f_id,f_name FROM fruits WHERE s_id IN(101,102)SELECT f_id,f_name FROM fruits WHERE s_id NOT IN(101,102)SELECT f_id,f_name FROM fruits WHERE f_price BETWEEN 2 AND 10SELECT f_id,f_name FROM fruits WHERE f_price NOT BETWEEN 2 AND 10
带like的字符匹配查询
1、百分号通配符“%”,匹配任意长度的字符,甚至包括零字符
SELECT f_id,f_name FROM fruits WHERE f_name LIKE 'b%y'
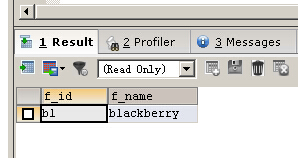
2、下划线通配符“_”,一次只能匹配任意一个字符
下面语句有四个下划线
SELECT f_id,f_name FROM fruits WHERE f_name LIKE '____n'
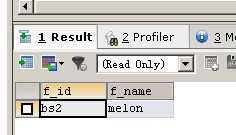
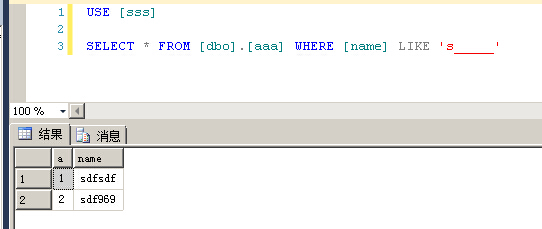
同样,在SQLSERVER里面也是有的
USE [sss] GO SELECT * FROM [dbo].[aaa] WHERE [name] LIKE 's_____'
查询空值
CREATE TABLE customers ( c_id INT NOT NULL AUTO_INCREMENT, c_name CHAR(25) NOT NULL, c_city CHAR(50) NULL, PRIMARY KEY(c_id) )
INSERT INTO customers(c_name,c_city) VALUES('liming','china'), ('hongfang',NULL)SELECT * FROM customers WHERE c_city IS NULL

SELECT * FROM customers WHERE c_city IS NOT NULL
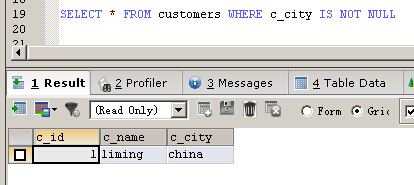
AND、OR、DISTINCT关键字
SELECT f_id,f_name FROM fruits WHERE f_name LIKE '____n' AND f_id='bs2'SELECT f_id,f_name FROM fruits WHERE f_name LIKE '____n' OR f_id='bs2'SELECT DISTINCT s_id FROM fruits
GROUP BY
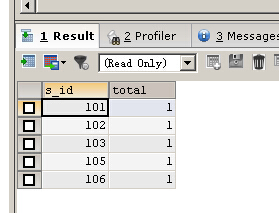
SELECT s_id ,COUNT(1) AS total FROM fruits GROUP BY s_id
再插入两条记录
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('a6',101,'cherry',6), ('a8',102,'coconut',7)
如果要查看每个供应商提供的水果的种类的名称,MYSQL中可以在GROUP BY中使用GROUP_CONCAT()函数,
将每个分组中各个字段的值显示出来
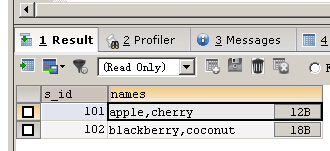
SELECT s_id,GROUP_CONCAT(f_name) AS NAMES FROM fruits GROUP BY s_id

SQLSERVER是没有GROUP_CONCAT()函数的,SQLSERVER要达到同样效果需要使用xml函数,MYSQL这方面做得非常好
having:过滤分组
根据s_id对fruits表中的数据进行分组,并显示水果种类大于1的分组信息
SELECT s_id ,GROUP_CONCAT(f_name) AS NAMES FROM fruits GROUP BY s_id HAVING COUNT(f_name)>1
在group by中使用with rollup
SELECT s_id ,COUNT(1) AS total FROM fruits GROUP BY s_id WITH ROLLUP
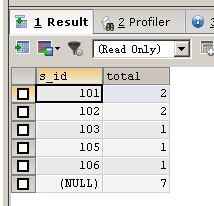
增加了最后一行,7表示total列的所有值的总和
而rollup关键字在SQLSERVER里面也有,详见:SQLSERVER中的ALL、PERCENT、CUBE关键字、ROLLUP关键字和GROUPING函数
注意:当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的!
limit限制查询结果的数量
在SQLSERVER中是使用TOP关键字,而在MYSQL中是使用LIMIT关键字
LIMIT[位置偏移量],行数
第一个“位置偏移量”参数指示MYSQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移量”
将会从表中第一条记录开始(第一条记录的位置偏移量是0,第二天记录的位置偏移量是1......以此类推)
第二个参数“行数”指示返回的记录条数
SELECT * FROM fruits
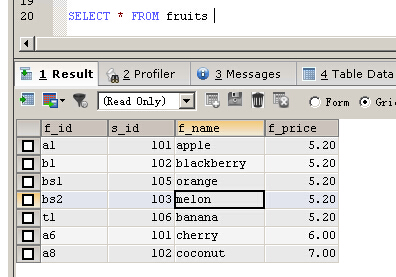
SELECT * FROM fruits LIMIT 4,3

上面结果返回从第5条记录行(因为从0开始数)开始之后的3条记录
注意:在MYSQL5.6中可以使用 LIMIT 4 OFFSET 3 ,意思是获取从第5行记录开始的3条记录,和 LIMIT 4,3 返回的结果是一样的
在SQLSERVER2012里面开始支持类似MYSQL的这种语法,但是需要按某一列先排序,而不像MYSQL那样不用按照某一列排序
USE [sss] GO CREATE TABLE fruits ( f_id CHAR(10) NOT NULL , s_id INT NOT NULL , f_name CHAR(255) NOT NULL , f_price DECIMAL(8, 2) NOT NULL , PRIMARY KEY ( f_id ) ) INSERT INTO fruits ( f_id , s_id , f_name , f_price ) SELECT 'a1' , 101 , 'apple' , 5.2 UNION ALL SELECT 'b1' , 102 , 'blackberry' , 5.2 UNION ALL SELECT 'bs1' , 105 , 'orange' , 5.2 UNION ALL SELECT 'bs2' , 103 , 'melon' , 5.2 UNION ALL SELECT 't1' , 106 , 'banana' , 5.2 UNION ALL SELECT 'a6' , 101 , 'cherry' , 6 UNION ALL SELECT 'a8' , 102 , 'coconut' , 7
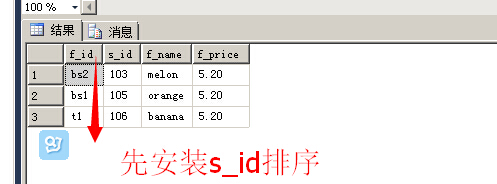
先按s_id排序,然后返回第5行开始的3条记录
SELECT * FROM [dbo].[fruits] ORDER BY [s_id] ASC OFFSET 4 ROWS FETCH NEXT 3 ROWS ONLY;
虽然没有MYSQL那么方便,不过也算是一种进步,而对于OFFSET FETCH NEXT的性能可以参考宋沄剑的文章:
子查询
子查询这个特性从MYSQL4.1开始引入。
插入测试数据
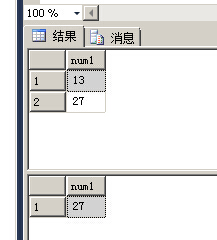
CREATE TABLE tbl1(num1 INT NOT NULL); CREATE TABLE tbl2(num2 INT NOT NULL) INSERT INTO tbl1 VALUES(1),(4),(13),(27); INSERT INTO tbl2 VALUES(6),(14),(11),(20)
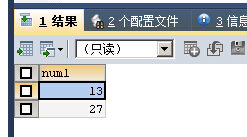
ANY关键字接在一个比较操作符的后面,表示若与子查询返回的任何值比较为TRUE,则返回TRUE
返回tbl2表的所有num2列,然后将tbl1中的num1的值与之进行比较,只要大于num2的任何一个值,即为符合查询条件的结果
SELECT num1 FROM tbl1 WHERE num1>ANY(SELECT num2 FROM tbl2)
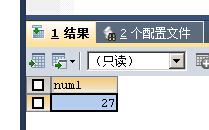
ALL关键字接在一个比较操作符的后面,表示与子查询返回的所有值比较为TRUE,则返回TRUE
SELECT num1 FROM tbl1 WHERE num1>ALL(SELECT num2 FROM tbl2)
在SQLSERVER中也可以使用ANY和ALL关键字
USE [sss] GO CREATE TABLE tbl1(num1 INT NOT NULL) CREATE TABLE tbl2(num2 INT NOT NULL) INSERT INTO tbl1 VALUES(1),(4),(13),(27) INSERT INTO tbl2 VALUES(6),(14),(11),(20) SELECT num1 FROM tbl1 WHERE num1>ANY(SELECT num2 FROM tbl2) SELECT num1 FROM tbl1 WHERE num1>ALL(SELECT num2 FROM tbl2)
结果是一样的
合并查询
使用UNION关键字,合并结果时,两个查询对应的列数和数据类型必须相同。
各个SELECT语句之间使用UNION或UNION ALL关键字分隔
UNION:执行的时候删除重复的记录,所有返回的行都是唯一的
UNION ALL:不删除重复行也不对结果进行自动排序
SELECT s_id,f_name,f_price FROM fruits WHERE f_price<9.0 UNION SELECT s_id,f_name,f_price FROM fruits WHERE s_id IN (101,103)
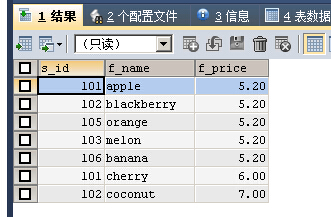
第一个查询把f_price小于9.0的记录查询出来,第二个查询把s_id为101和103的记录查询处理
因为f_price小于9.0的记录里有些记录的s_id是102、105、106,这些结果不会被去掉会跟第二个查询进行合并
所以最终的结果会有s_id为102、105、106的记录
正则表达式查询
正则表达式在SQLSERVER里面是没有的,但是在MYSQL里不单只有,而且功能也比较丰富
MYSQL中使用REGEXP关键字指定正则表达式的字符匹配模式
1、查询以特定字符或字符串开头的记录
字符“^”匹配以特定字符或者字符串开头的文本
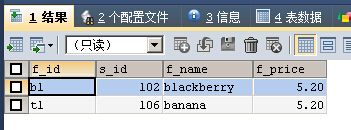
SELECT * FROM fruits WHERE f_name REGEXP '^b'
返回f_name字段以b开头的记录
2、查询以特定字符或字符串结尾的记录
字符“$”匹配以特定字符或者字符串结尾的文本
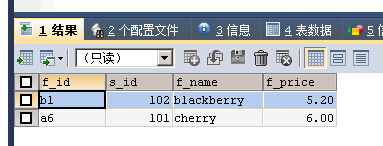
SELECT * FROM fruits WHERE f_name REGEXP 'y$'
返回f_name字段以y结尾的记录

3、用符号“.”来代替字符串中的任意一个字符
字符“.”匹配任意一个字符
SELECT * FROM fruits WHERE f_name REGEXP 'a.g'
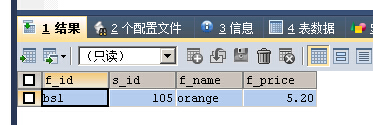
a和g两个字母之间包含单个字符,orange符合要求
4、使用“*”和“+”来匹配多个字符
星号“*”匹配前面的字符任意多次,包括0次。加号“+”匹配前面的字符至少一次
SELECT * FROM fruits WHERE f_name REGEXP '^ba*'
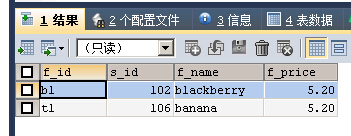
blackberry和banana符合要求,b开头,a匹配任意多次,不管出现的顺序在哪里
SELECT * FROM fruits WHERE f_name REGEXP '^ba+'
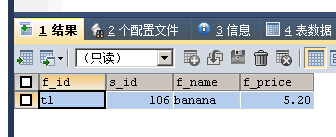
“a+”匹配字母“a”至少一次,只有banana满足匹配条件
5、匹配指定字符串
正则表达式可以匹配指定字符串,只要这个字符串在查询文本中即可,如要匹配多个字符串,多个字符串之间使用分隔符“|”隔开
SELECT * FROM fruits WHERE f_name REGEXP 'on|ap'
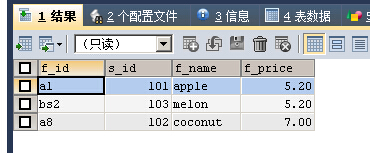
可以看到apple 、melon 、coconut 3个值中都包含有字符串“on”和“ap”,满足匹配条件
6、匹配指定字符中的任意一个
方括号“[]”指定一个字符集合,只匹配其中任何一个字符,即为所查找的文本
SELECT * FROM fruits WHERE f_name REGEXP '[ot]'
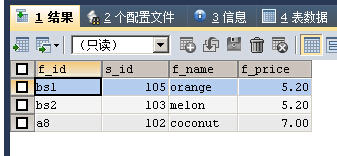
方括号[]还可以指定数值集合
SELECT * FROM fruits WHERE s_id REGEXP '[456]'
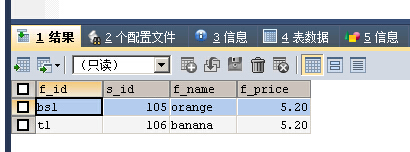
s_id字段值中有3个数字中的1个即为匹配记录字段
[456]也可以写成[4-6]即指定集合区间
7、匹配指定字符以外的字符
“[^字符集合]”匹配不在指定集合中的任何字符
SELECT * FROM fruits WHERE f_id REGEXP '[^a-e1-2]'

返回开头不在a-e 1-2字母的记录,例如a1,b1这些记录就不符合要求
8、使用{n,} 或者{n,m}来指定字符串连续出现的次数
“字符串{n,}”,表示至少匹配n次前面的字符;“字符串{n,m}”表示匹配前面的字符串不少于n次,不多于m次。
SELECT * FROM fruits WHERE f_name REGEXP 'b{1,}'
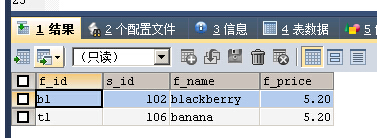
至少匹配1次字母b,blackberry和banana都符合要求
SELECT * FROM fruits WHERE f_name REGEXP 'ba{1,3}'
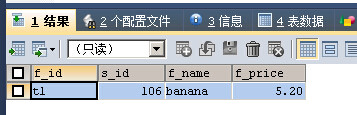
“ba”字符串最少出现一次,最多三次,banana这个字符串符合要求
总结
这一节介绍了MYSQL里的查询,并且比较了与SQLSERVER的区别,特别是MYSQL里的正则查询灵活多变
这一点比SQLSERVER略为优胜