java对象模型其实就是JVM中对象的内存布局。一个对象本身内在结构的描述信息以字节码的方式存储在方法区中(参见java内存区域),说白了就是class文件。那么如何获取到对象的class信息呢?虚拟机使用对象头部的一个指针指向 Class 区域,找到对象的 Class 描述。在虚拟机中,对象在内存中的存储布局分为 3 块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding):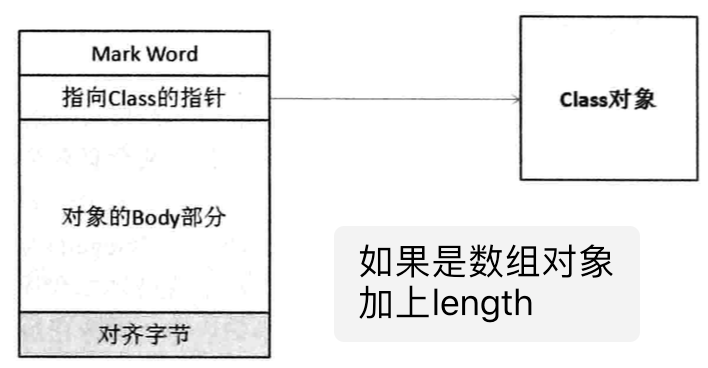
一、对象头
包括两部分(非数组对象)信息:
第一部分用于存储对象自身的运行时数据,如哈希码(HashCode)、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳、对象分代年龄,这部分信息称为“Mark Word”。Mark Word 被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据自己的状态复用自己的存储空间;
第二部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例;
如果是数组对象,那么还有第三部分:一块用于记录数组长度的数据。虚拟机可以通过普通Java对象的元数据信息确定对象的大小,但是从数组的元数据信息却无法确定数组的大小。

对象头的数据的长度在 32 位和 64 位的虚拟机(未开启压缩指针)中分别为32bit 和 64bit。在 32 位的 HotSpot 虚拟机中,如果对象处于未被锁定的状态下,那么 Mark Word 的 32bit 空间中的 25bit 用于存储对象哈希码,4bit 用于存储对象分代年龄,2bit 用于存储锁标志位,1bit 固定为 0,如下表所示:
在 32 位系统下,存放 Class 指针的空间大小是 4 字节,Mark Word 空间大小也是4字节,因此头部就是 8 字节,如果是数组就需要再加 4 字节表示数组的长度,如下表所示:
在 64 位系统及 64 位 JVM 下,开启指针压缩,那么头部存放 Class 指针的空间大小还是4字节,而 Mark Word 区域会变大,变成 8 字节,也就是头部最少为 12 字节,如下表所示:

开启指针压缩使用算法开销带来内存节约,Java 对象都是以 8 字节对齐的,也就是以 8 字节为内存访问的基本单元,那么在地理处理上,就有 3 个位是空闲的,这 3 个位可以用来虚拟,利用 32 位的地址指针原本最多只能寻址 4GB,但是加上 3 个位的 8 种内部运算,就可以变化出 32GB 的寻址。
代码清单2-2为HotSpot虚拟机markOop.cpp中的代码(注释)片段,它描述了32bit下Mark Word的存储状态:

二、实例数据
实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。
这部分的存储顺序会受到虚拟机分配策略参数(FieldsAllocationStyle)和字段在 Java 源码中定义顺序的影响。
HotSpot虚拟机默认的分配策略为longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Pointers),从分配策略中可以看出,相同宽度的字段总是被分配到一起。在满足这个前提条件的情况下,在父类中定义的变量会出现在子类之前。如果 CompactFields参数值为true(默认为true),那子类之中较窄的变量也可能会插入到父类变量的空隙之中。
三、对齐信息
对齐填充不是必然存在的,没有特别的含义,它仅起到占位符的作用。
由于 HotSpot VM 的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,也就是说对象的大小必须是 8 字节的整数倍。对象头部分是 8 字节的倍数,所以当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
四、对象的大小
class的大小通常是KB级别,随便找个类文件一看便知:
$ ll total 12 -rw-r--r-- 1 wulf 1049089 5172 11月 30 17:56 CycleTypes.class -rw-r--r-- 1 wulf 1049089 1245 11月 30 17:56 User.class
从上面可以看到,两个class,一个是5172字节,一个是1245字节。那么对象一般是多大呢?32 位系统下,当使用 new Object() 时,JVM 将会分配 8(Mark Word+类型指针) 字节的空间,128 个 Object 对象将占用 1KB 的空间。
如果是 new Integer(),那么对象里还有一个 int 值,其占用 4 字节,这个对象也就是 8+4=12 字节,对齐后,该对象就是 16 字节。
如果对象存在多个属性字段,它的内部属性是怎么排布的?
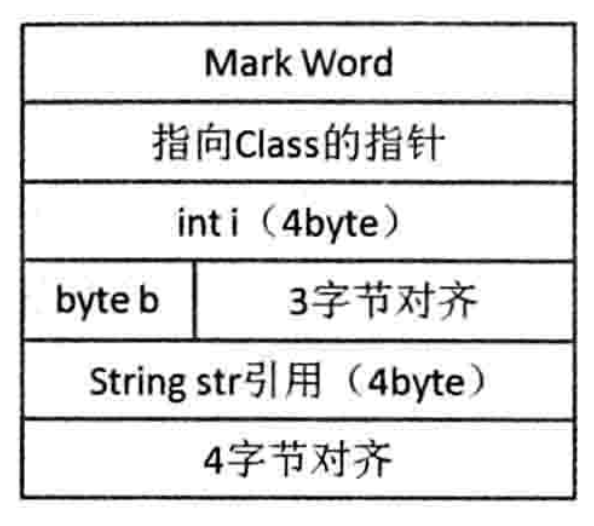
Class A { int i; byte b; String str; }
其中对象头部占用 ‘Mark Word’4字节 + ‘类型指针’4字节 = 8 字节;int 32 位长,占用 4 字节;byte 8 位长,占用 1 字节;String 只有引用,占用 4 字节;那么对象 A 一共占用了 8+4+1+4=17 字节,按照 8 字节对齐原则,对象大小也就是 24 字节。这个计算看起来是没有问题的,对象的大小也确实是 24 字节,但是对齐(padding)的位置并不对:在 HotSpot VM 中,对象排布时,间隙是在 4 字节基础上的(在 32 位和 64 位压缩模式下),上述例子中,int 后面的 byte,空隙只剩下 3 字节,接下来的 String 对象引用需要 4 字节来存放,因此 byte 和对象引用之间就会有 3 字节对齐,对象引用排布后,最后会有 4 字节对齐,因此结果上依然是 7 字节对齐。此时对象的结构示意图,如下图所示: