分类方法常用的评估模型好坏的方法.
0.预设问题
假设我现在有一个二分类任务,是分析100封邮件是否是垃圾邮件,其中不是垃圾邮件有65封,是垃圾邮件有35封.模型最终给邮件的结论只有两个:是垃圾邮件与 不是垃圾邮件.
经过自己的努力,自己设计了模型,得到了结果,分类结果如下:
- 不是垃圾邮件70封(其中真实不是垃圾邮件60封,是垃圾邮件有10封)
- 是垃圾邮件30封(其中真实是垃圾邮件25封,不是垃圾邮件5封)
现在我们设置,不是垃圾邮件.为正样本,是垃圾邮件为负样本
我们一般使用四个符号表示预测的所有情况:
- TP(真阳性):正样本被正确预测为正样本,例子中的60
- FP(假阳性):负样本被错误预测为正样本,例子中的10
- TN(真阴性):负样本被正确预测为负样本,例子中的25
- FN(假阴性):正样本被错误预测为负样本,例子中的5
1.评价方法介绍
先看最终的计算公式:

1.Precision(精确率)
关注预测为正样本的数据(可能包含负样本)中,真实正样本的比例
计算公式

例子解释:对上前面例子,关注的部分就是预测结果的70封不是垃圾邮件中真实不是垃圾邮件占该预测结果的比率,现在Precision=60/(600+10)=85.71%
2.Recall(召回率)
关注真实正样本的数据(不包含任何负样本)中,正确预测的比例
计算公式
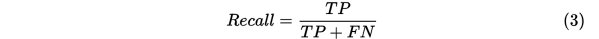
例子解释:对上前面例子,关注的部分就是真实有65封不是垃圾邮件,这其中你的预测结果中有多少预测正确了,Recall=60/(60+5)=92.31%
3.F-score中β值的介绍
β是用来平衡Precision,Recall在F-score计算中的权重,取值情况有以下三种:
- 如果取1,表示Precision与Recall一样重要
- 如果取小于1,表示Precision比Recall重要
- 如果取大于1,表示Recall比Precision重要
一般情况下,β取1,认为两个指标一样重要.此时F-score的计算公式为:
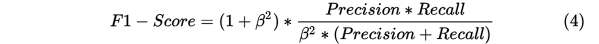
前面计算的结果,得到Fscore=(2*0.8571*0.9231)/(0.8571+0.9231)=88.89%
3.其他考虑
预测模型无非就是两个结果
- 准确预测(不管是正样子预测为正样本,还是负样本预测为负样本)
- 错误预测
那我就可以直接按照下面的公式求预测准确率,用这个值来评估模型准确率不就行了

那为什么还要那么复杂算各种值.理由是一般而言:负样本远大于正样本。
可以想象,两个模型的TN变化不大的情况下,但是TP在两个模型上有不同的值,TN>>TP是不是可以推断出:两个模型的(TN+TP)近似相等.这不就意味着两个模型按照以上公式计算的Accuracy近似相等了.那用这个指标有什么用!!!
所以说,对于这种情况的二分类问题,一般使用Fscore去评估模型.
需要注意的是:Fscore只用来评估二分类的模型,Accuracy没有这限制
参考
1.机器学习中的 precision、recall、accuracy、F1 Score
2.分类模型的评估方法-F分数(F-Score)