-
Paxos工程实践
Overview
- 是不是感觉看了这篇 Paxos算法 感觉完全没看懂?2333我也是
- 之前Paxos算法在工程实现的过程中,会遇到非常多的问题。
Chubby
- Google Chubby是一个大名鼎鼎的分布式锁服务
- GFS和Big Table等大型系统都用它来解决分布式协作、元数据存储和Master选举等一系列与分布式锁服务相关的问题。
- Chubby的底层一致性实现就是以Paxos算法为基础的。
Overview
- Chubby是一个面向松耦合分布式系统的锁服务,通常用于一个由大量小型计算机构成的松耦合分布式系统提供高可用的分布式锁服务。
- 一个分布式锁服务的目的是允许它的客户端进程同步彼此的操作,并对当前所处环境的基本状态信息达成一致。
- 针对这个目的,Chubby提供了粗粒度的分布式锁服务,开发人员不需要使用复杂的同步协议,而是直接调用Chubby的锁服务接口即可实现分布式系统中多个进程之间粗粒度的同步控制,从而保证分布式数据的一致性。
- Chubby的客户端接口设计非常类似UNIX文件系统结构,应用程序通过Chubby的客户端接口,不仅可以对Chubby服务器上的整个文件进行读写操作,还能够添加对文件节点的锁控制,并且能订阅Chubby服务端发出的一系列文件变动的事件通知。
应用场景
- 最典型的就是Master选举啦。
- 借助Chubby,master能够非常方便地感知到其所控制的那些服务器。同时,BigTable的客户端还能够很方便地定位到当前集群的master服务器。此外,在GFS和BigTable中,都使用Chubby来进行系统运行时元数据的存储。
设计目标
- Chubby设计上不同于Paxos的一点在于:Chubby被设计成一个需要访问中心化节点的分布式锁服务。而不是一个包含Paxos算法的协议库。
- 锁服务相比于传统算法库的优点:
- 对上层应用程序的侵入性更小
- 便于提供数据的发布和订阅
- ....
Chubby技术架构
系统结构
- Chubby的整个系统结构主要由服务端和客户端两部分组成。
- 客户端通过RPC调用与服务端进行通信。
- 一个典型的Chubby集群,或称为Chubby cell,通常由5台服务器组成。
- 这些副本服务采用Paxos协议,通过投票的方式来选举产生一个获得过半投票的服务器作为master。

Master
- 一旦某台服务器称为了master,Chubby就会保证在一段时间内不会再有其他服务器称为master。该端时间被称为master租期(Master lease). 而Master会不断续租来延长租期。而若master服务器出现故障,则余下服务器会进行新一轮的master选举。
- 集群中的每个服务器都维护着一份服务器数据库的副本,但在实际运行过程中,只有master服务器才能对数据库进行写操作。其他服务器都是使用Paxos协议从master服务器上同步更新。
- 针对写请求,master会采用一致性协议将其广播给集群中所有副本服务器,并且在过半的服务器接受了该请求后,再响应给客户端正确的应答。
- 对于读请求,则不需要广播,直接由master单独处理即可。
Client
- 那么还有一个问题是,Chubby的客户端如何定位到master服务器的。Chubby客户端向记录有Chubby服务器列表的DNS来请求获取所有的Chubby服务器列表,然后逐个发起请求询问。而非Master服务器则会反馈当前master所在的服务器标识给client。
故障
- 若当前master崩溃,则集群中其他服务器会在Master续租到期后,重新开启新一轮的Master选举。通常master选举需花费几秒钟。(DownTime)
- 若非master崩溃,则集群不会停止工作,而该崩溃的服务器会在恢复之后自动加入到Chubby集群。新加入的服务器首先需要同步Chubby最新的数据库数据,完成同步之后,新的服务器就可以加入到正常的Paxos运作流程。
- 若某服务器发生崩溃并在几小时后仍无法恢复,则需要加入新的机器,同时更新DNS列表。
- Chubby服务器的更换:启动Chubby服务端程序,然后更新DNS上的机器列表即可。在Chubby运行过程中,master会周期性地轮训DNS列表,从而服务器地址变更会很快被master感应。从而集群内其他副本服务器通过复制即可。
目录与文件
- Chubby对外提供了一套与Unix文件系统非常相近但是更简单的访问接口。
- Chubby的数据结构可以看做是一个由文件和目录组成的树。
- 其中的每一个节点都可以表示为一个使用斜杠分割的字符串,典型的节点路径如下:
/ls/foo/wombat/pouch
- 其中,ls(Look service)是所有Chubby节点所共有的前缀,代表着锁服务;
- foo则是指定了Chubby集群的名字,从DNS可以查到一个或多个服务器组成该Chubby集群;
- 剩下部分的路径则是一个真正包含业务含义的节点名字,由Chubby内部解析并定位到数据节点。
- Chubby的命名空间,包括文件和目录,被称为节点(nodes, 泛指Chubby的文件或目录)。
- 同一个Chubby集群数据库中,每一个节点都是全局唯一的。
- nodes分为持久节点和临时节点两大类:
- 持久节点需要显式调用API进行删除;
- 临时节点则会在client会话结束后被自动删除。因此,临时节点通常可被用作进行客户端会话有消息的判断依据。
- 另外,Chubby上的每个数据节点都包含了少量的元数据信息,其中包括ACL信息。同时,每个节点的元数据中还包括4个单调递增的64位编号:
- 实例编号:用于标识Chubby创建该数据节点的顺序。从而client可以方便地识别出是否是同一个数据节点。
- 文件内容编号(only for file):用于标识文件内容的变化情况,会在文件内容被写入时增加。
- 锁编号:用于标识节点锁状态变更情况,会在节点锁从free到held状态时增加。
- ACL编号:用于标识节点的ACL信息变更情况,会在节点的ACL配置信息被写入时增加。
锁与锁序列器
- 由于网络通信的不确定性,在分布式系统中,锁是一个非常复杂的问题。消息的延迟或是乱序都可能引发锁的失效。eg:
客户端C1获取到了互斥锁L,并且在锁L的保护下发出请求R,但请求R迟迟没有到达服务端,这是应用程序会认为该客户端进程已经失败,于是会为另一个客户端C2分配锁L,然后再重新发起之前的请求R,并且成功应用到了服务器上。这时,不幸的事情发生了,客户端C1的请求最终到达了服务器端,从而可能覆盖了C2的操作,导致系统数据出现不一致。
对于上述问题,典型的解决方案包括虚拟时间和虚拟同步(这并非Chubby中所涉及的方案)。
- 在Chubby中,任意一个数据节点都可以充当一个读写锁来使用:一种是单个客户端以排他(写)模式持有这个锁,另一种则是任意数目的客户端以共享(读)模式持有这个锁。同时,在Chubby的锁机制中需注意的一点是,Chubby舍弃了严格的强制锁,client可以在没有获取锁的情况下访问Chubby的文件,也即持有锁F既不是访问文件F的必要条件,也不会组织其他客户端访问文件F。
- 在Chubby中,主要采用锁延迟和锁序列器两种策略来解决上述由于消息延迟和重排序引起的分布式锁问题。
- 延迟锁:即在锁因为client异常(如client无响应)而被释放时,Chubby服务器会为该锁保留一定的时间,即lock-delay。延迟锁能够很好地防止一些client由于网络闪断等原因与服务器暂时断开连接的场景出现。
- 锁序列器:该方式需要Chubby的上层应用配合在代码中加入相应的修改逻辑。任何时候,锁的持有者都可以向Chubby请求一个锁序列器,包括锁的名字、锁模式(排他or共享模式)、以及锁序号。Chubby服务器接收到这样的请求后,首先会监测该序列器是否有效以及client是否处于恰当的锁模式。
Chubby中的事件通知机制
- 为避免大量client轮询Chubby服务器状态所带来的压力,Chubby提供了事件通知机制。
- Chubby client可以向服务端注册事件通知。
- 消息通知都是通过异步的方式发送给client的。
- 常见Chubby事件如下:
- 文件内容变更:
- 如BigTable集群使用Chubby锁来确定集群中哪台机器是Master:获得锁的BigTable master会将自身信息写入Chubby上对应文件中。BigTable中其他client可以通过监视这个Chubby文件的变化来确定新的master。
- 节点删除:这通常在临时节点中比较常见,可以利用该特性来间接判断该临时节点对应的client会话的有效性。
- 子节点新增、删除
- master服务器转移
Chubby中的缓存
- 为提高Chubby性能,同时减少client和server间的频繁读请求对server的压力,还在客户端实现了缓存,即在client对文件内容和元数据信息进行缓存。
- 最主要的问题是如何保证缓存的一致性。
- 在Chubby中,通过租期来保证缓存的一致性:
- Chubby缓存的生命周期和master租期机制紧密相关。
- master会维护每个client的数据缓存情况,并通过向客户端发送过期信息的方式来保证client数据的一致性。
- 即,每个client的缓存都有一个租期,租期到期时client需要向server续订租期。
- 当文件数据或元数据信息被修改时,Chubby服务端首先会阻塞该操作,然后向master所有可能缓存了该数据的client发过期信号,使其缓存失效,等到master接收到所有相关client应答后,再继续修改操作。
- 可见,Chubby的缓存数据保证了强一致性。尽管这对性能的开销和系统的吞吐影响很大,但弱一致性在实际使用中容易出现问题。
会话和会话激活(KeepAlive)
- Chubby client和server之间通过创建一个TCP连接来进行所有的网络通信操作,该连接称为会话(session)。
- 会话是有生命周期的,存在一个超时时间。在超时时间内,Chubby clinet和server之间可以通过心跳监测来保持会话的活性,以使会话周期得到延续,这个过程称为KeepAlive(会话激活)。
KeepAlive请求
- master接收到client的KeepAlive请求时,会首先将该请求阻塞住,并等到该client的当前会话租期即将过期时,才为期续租该client的会话租期,之后再想client响应该请求,并同时将最新的会话租期超时时间反馈给client。
- master对于会话租期时间的设置,默认是12s,但该值会根据实际运行情况调整。例如当master处于高负载状态时,会适当延长会话租期的长度,以减少client KeepAlive请求的发送频率。(client在接收到master的续租响应后会立即发起一个新的KeepAlive请求,再由master进行阻塞。) 因此,每个Chubby client总会有一个KeepAlive请求阻塞在master上。
会话超时
- Chubby client也会维持一个和master端近似的会话租期。因为KeepAlive响应在网络传输过程中会花费一定的时间,并且,master server和client server存在时钟不一致现象。
- 当client会话过期却尚未接收到master的KeepAlive响应时,client处于“危险状态”。但client还会等待一个“宽期限”。
Chubby Master故障恢复
- master上运行着会话租期计时器,for管理所有会话的生命周期。
- 旧的master崩溃到新的master选举产生所花费的时间将不计入会话超时时间内。这里可以看出由于“宽期限”的存在,使得会话能够很好地在master转换过程中得到维持。
- 一旦client与新的master建立连接后,client和master之间会通过互相配合来实现对故障的平滑恢复:
- 新的master首先确定master周期(master周期用来唯一标识一个Chubby集群的master统治轮次,以便区分不同的master。) 这之后,master会拒绝所有携带其他master周期编号的client请求,并告知其最新的master周期编号。
- master根据本地数据库存储的会话和锁信息,来构建服务器的内存状态。
- ...
Paxos协议实现
- Chubby server的基本架构大致分为三层:
- 最底层是容错日志系统(Fault-Tolerant Log), 通过paxos算法能保证集群中所有机器上的日志完全一致,同时具备较好的容错性。
- 再往上是Key-Value类型的容错数据库(Fault-Tolerant DB),其通过下层的日志来保证一致性和容错性。
- 存储层之上就是Chubby对外提供的分布式锁服务和小文件存储服务。
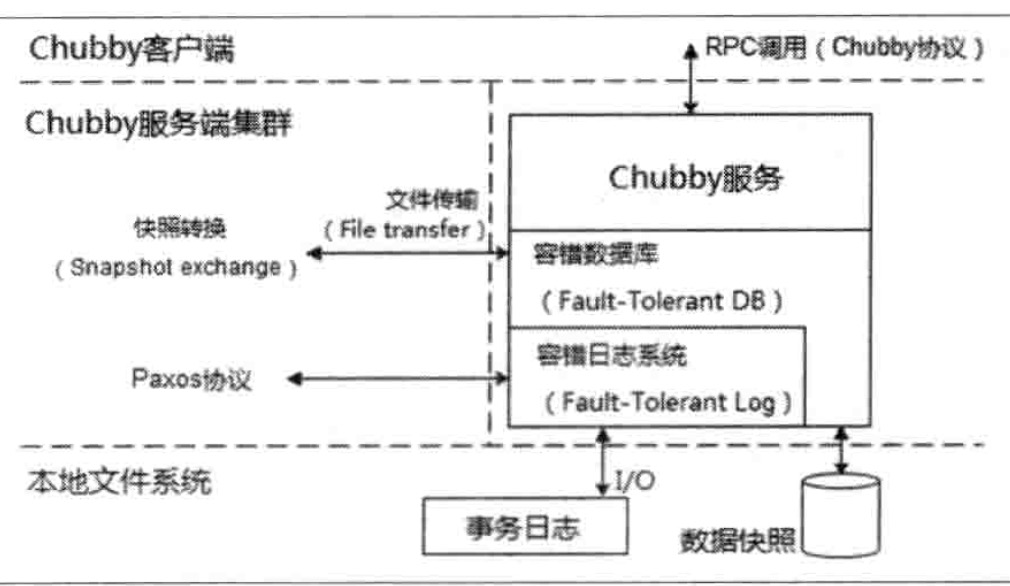
- Paxos算法的作用就在于保证集群内各个副本节点的日志能够保持一致。Chubby事务日志中的每个value对应Paxos算法中的一个Instance。
-
相关阅读:
splice九重天
数组
数组方法valueOf的用武之地
已经有一个项目的源码如何将其推送到远程服务器
【holm】并行Linq(PLinq)
【holm】C# 使用Stopwatch准确测量程序运行时间
【holm】url,href,src三者之间的关系
【holm】C#线程监视器Monitor类使用指南
【holm】MySQL锁机制
【holm】MySQL事务的使用
-
原文地址:https://www.cnblogs.com/wttttt/p/7497855.html
Copyright © 2020-2023
润新知