1、主要创新
1)提出了一种新的layer module:the inverted residual with linear bottleneck,
2)short connect被置于bottleneck层之间,比置于expanded层之间可以取得更好的效果
3)采用线性bottleneck层(即不同ReLU函数),因为非线性会破坏低维空间信息
4)使用ReLU6作为非线性函数,因为它在低精度计算时具有鲁棒性
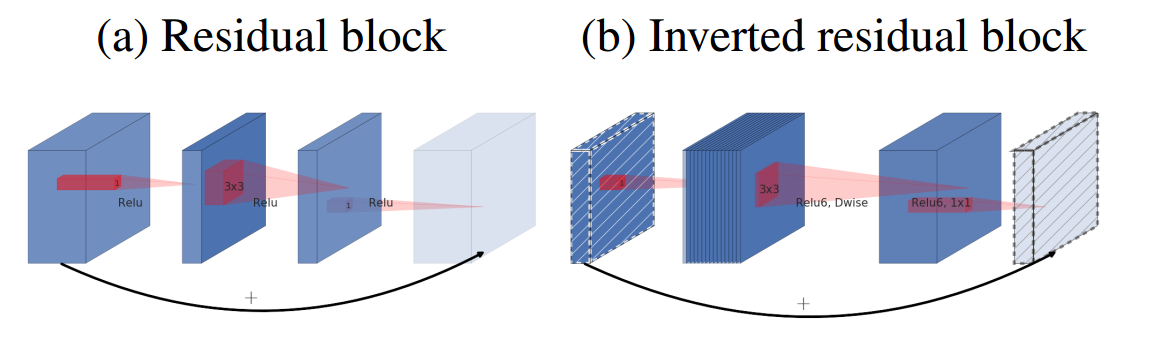
2、网络结构
1)传统Residual block
先用1x1降通道过ReLU,再3x3空间卷积过ReLU,再用1x1ReLU卷积恢复通道,并和输入相加。之所以要1x1卷积降通道,是为了减少计算量,不然中间的3x3空间卷积计算量太大。所以Residual block是沙漏形,两边宽中间窄。
2)Inverted residual block
现在中间的3x3卷积变为了Depthwise的了,计算量很少了,通道可以多一点,效果更好,所以通过1x1卷积先提升通道数,再Depthwise的3x3空间卷积,再用1x1卷积降低维度。两端的通道数都很小,所以1x1卷积升通道或降通道计算量都并不大,而中间通道数虽然多,但是Depthwise 的卷积计算量也不大。作者称之为Inverted Residual Block,两边窄中间宽,像柳叶,较小的计算量得到较好的性能.
3)ReLU6
首先说明一下 ReLU6,卷积之后通常会接一个 ReLU 非线性激活,在 MobileNet V1 里面使用 ReLU6,ReLU6 就是普通的ReLU但是限制最大输出值为 6,这是为了在移动端设备 float16/int8 的低精度的时候,也能有很好的数值分辨率,如果对 ReLU 的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16/int8无法很好地精确描述如此大范围的数值,带来精度损失。

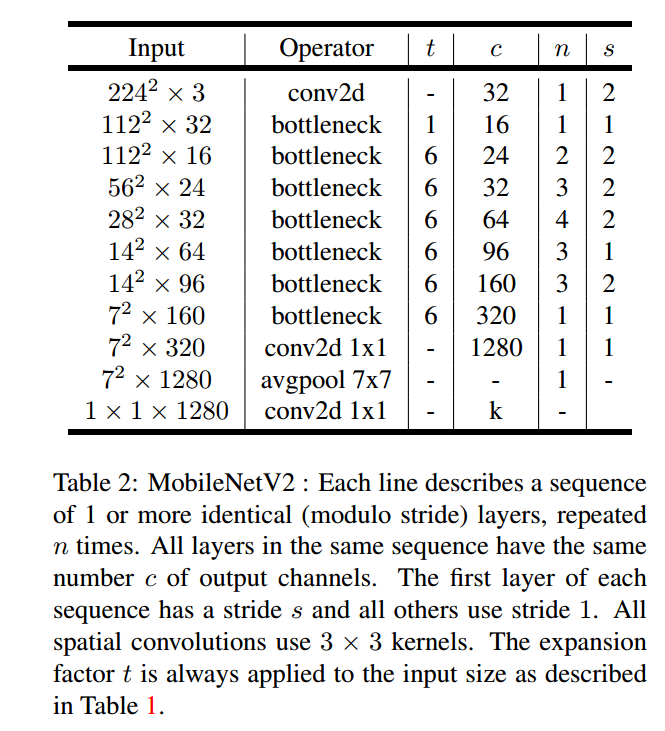
3、与其他模型的结构对比

4、训练环境
1)decay and momentum set to 0.9
2)standard weight decay is set to 0.00004
3)initial learning rate of 0.045, and learning rate decay rate of 0.98 per epoch.
4)batch size:96
5、性能对比(ImageNet)

6、分割研究
