一,mysql-mha环境准备
1.1 实验环境:
1.1 实验环境:
| 主机名 | IP地址(NAT) | 描述 |
|---|---|---|
| mysql-master | eth0:10.1.1.154 | 系统:CentOS6.5(6.x都可以) 安装:mysql5.6 |
| mysql-slaveA | eth0:10.1.1.155 | 系统:CentOS6.5(6.x都可以) 安装:mysql5.6 |
| mysql-slaveB | eth0:10.1.1.156 |
系统:CentOS6.5(6.x都可以) 安装:mysql5.6 |
1.2 软件包
1) mha管理节点安装包:
mha4mysql-manager-0.56-0.el6.noarch.rpm
mha4mysql-manager-0.56.tar.gz
2) mha node节点安装包:
mha4mysql-node-0.56-0.el6.noarch.rpm
mha4mysql-node-0.56.tar.gz
3) mysql中间件:
Atlas-2.2.1.el6.x86_64.rpm
4) mysql源码安装包
mysql-5.6.17-linux-glibc2.5-x86_64.tar
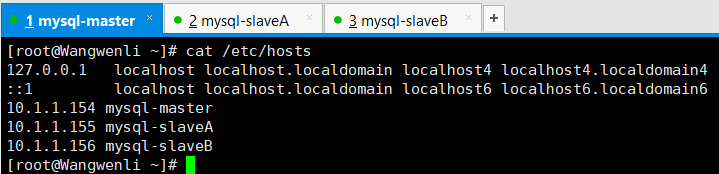
1.3 主机名映射
1.4 关闭selinux和iptables

二,简介
2.1 作者简介

姓名:松信嘉范
MySQL/Linux专家
2001年索尼公司入职
2001年开始使用oracle
2004年开始使用MySQL
2006年9月-2010年8月MySQL从事顾问
2010年-2012年DeNA
2012年至今Facebook
2.2 软件简介
- MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换过程中,MHA能最大程度上保证数据库的一致性,以达到真正意义上的高可用。
- MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave上。当Master出现故障时,它可以自动将最新数据的Slave提升为新的Master,然后将所有其他的Slave重新指向新的Master。整个故障转移过程对应程序是完全透明的。
2.3 工作流程
- 从宕机崩溃的master保存二进制日志事件(binlog events);
- 识别含有最新更新的slave;
- 应用差异的中继日志(relay log)到其他的slave;
- 应用从master保存的二进制日志事件(binlog events);
- 提升一个slave为新的master;
- 使其他的slave连接新的master进行复制;
2.4 MHA架构图

2.5 MHA工具介绍
MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下:
#Manager工具包主要包括以下几个工具:分割线masterha_check_ssh #检查MHA的SSH配置状况masterha_check_repl #检查MySQL复制状况masterha_check_status #检测当前MHA运行状态masterha_master_monitor #检测master是否宕机masterha_manger #启动MHAmasterha_master_switch #控制故障转移(自动或者手动)masterha_conf_host #添加或删除配置的server信息masterha_secondary_check #试图建立TCP连接从远程服务器masterha_stop #停止MHA分割线#Node工具包主要包括以下几个工具:save_binary_logs #保存和复制master的二进制日志apply_diff_relay_logs #识别差异的中继日志事件filter_mysqlbinlog #去除不必要的ROLLBACK事件purge_relay_logs #清除中继日志
三,mysql环境准备
3.1 环境检查

3.2 安装mysql
3.2.1 安装包准备

3.2.2 安装(3台都装)
3.2.3 加入开机自启动并启动mysql



3.2.4 配置密码

四,配置基于GTID的主从复制
4.1 先决条件
- 主库和从库都要开启binlog
- 主库和从库server-id不同
- 要有主从复制用户
4.2 主库操作(mysql-master)
修改主库配置文件/etc/my.cnf并 重启动MySQL服务
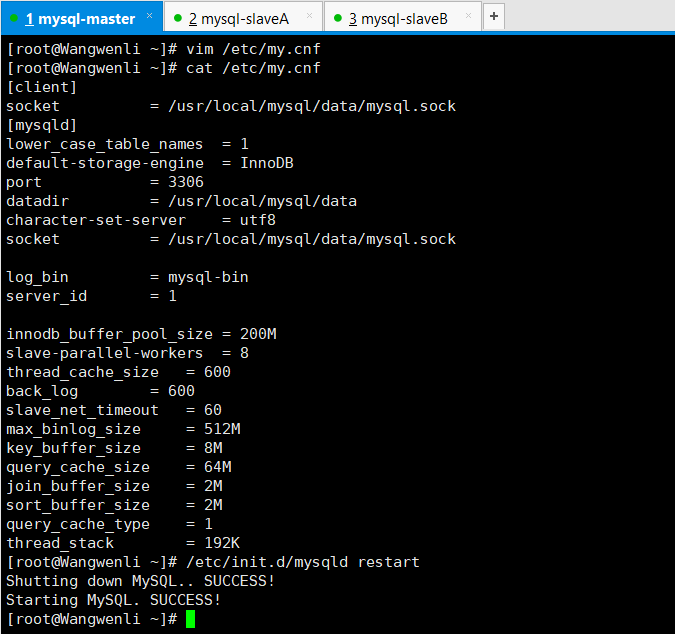

log_bin = mysql-bin #开启binlog日志
server_id = 1 #设置server_id
创建主从复制用户


4.3 从库操作(mysql-slaveA和mysql-slaveB)
修改mysql-slaveA配置文件(和mysql-master配置文件一致)
只需要修改server-id = 5选项

log_bin = mysql-bin #从binlog也要打开server_id = 5 #仅需修改此项
修改mysql-slaveB配置文件(和mysql-master配置文件一致)
只需要修改server-id = 10选项

log_bin = mysql-bin #从binlog也要打开server_id = 10 #只需修改此项

在以往如果是基于binlog日志的主从复制,则必须要记住主库的master状态信息。但是在MySQL5.6版本里多了一个Gtid的功能,可以自动记录主从复制位置点的信息,并在日志中输出出来。
4.4 开启GTID
没开启之前先看一下GTID状态 关闭
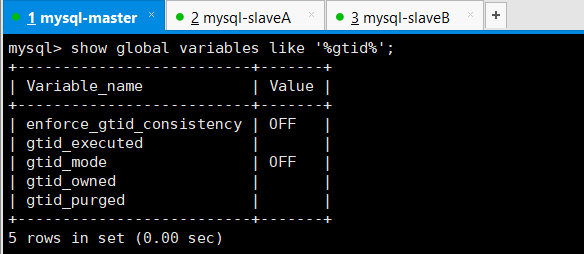
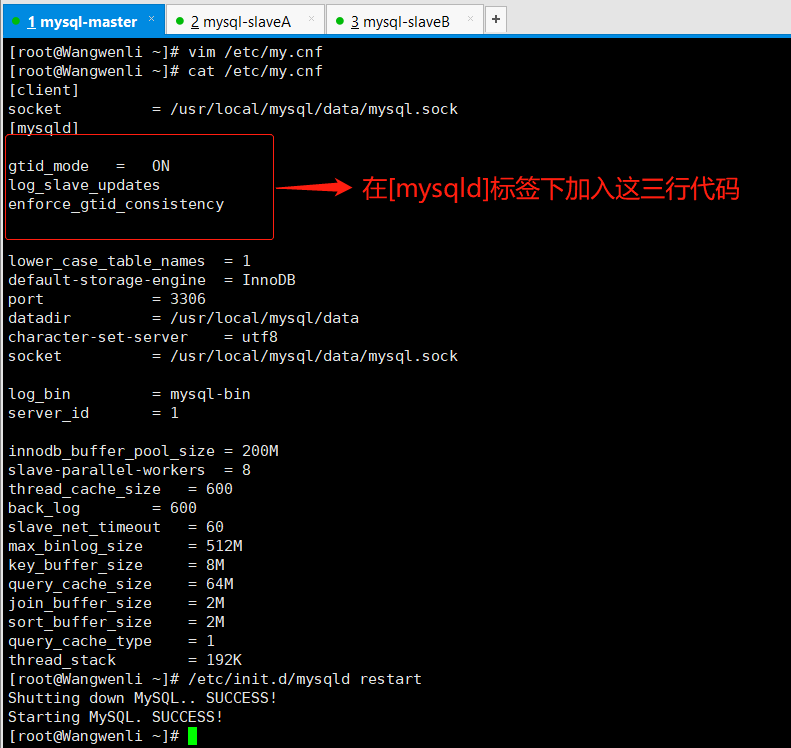
编辑mysql配置文件(主库从库都需要修改)mysql-master,mysql-slaveA,mysql-slaveB都需要加入下图的3行代码,主库从库都必须要开启GTID,否则在做主从复制的时候就会报错.


再次查看GTID状态

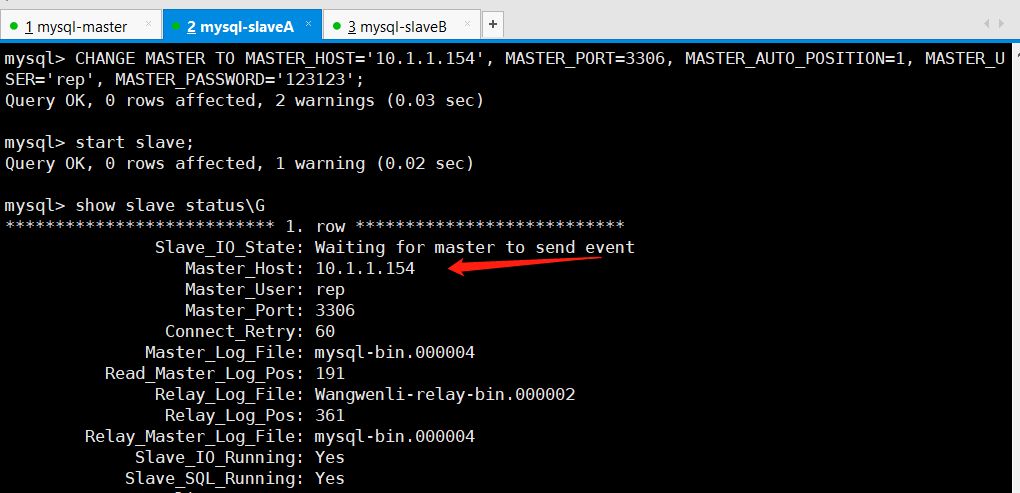
4.5 配置主从复制(mysql-slaveA,mysql-slaveB)
mysql> change master to-> master_host='10.1.1.154', #主库IP-> master_user='rep', #主库复制用户-> master_password='123123', #主库复制用户密码-> master_auto_position=1; #GTID位置点(自动追踪需要同步的positiositionsition)


4.6 开启从库的主从复制功能(mysql-slaveA,mysql-slaveB)
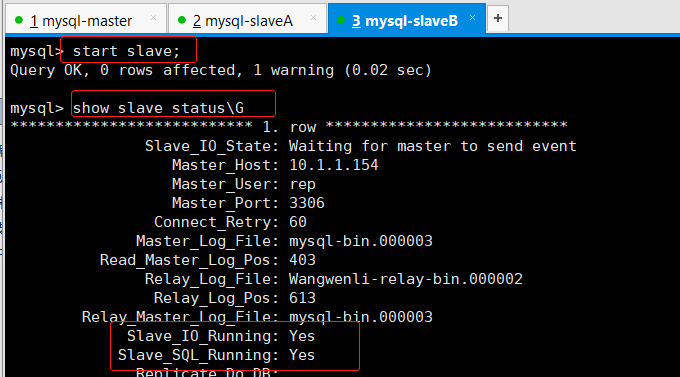
start slave; #开启主从同步功能
Slave_IO_Running: Yes #此项yes代表成功
Slave_SQL_Running: Yes #此项yes代表成功
两项都是yes才是成功。两个从库都要做以上步骤。

4.7 什么是GTID
- GTID(Global Transaction)全局事务标识符:是一个唯一的标识符,它创建并与源服务器(主)上提交的每个事务相关联。此标识符不仅对其发起的服务器是唯一的,而且在给定复制设置中的所有服务器上都是唯一的。所有交易和所有GTID之间都有1对1的映射。
- GTID实际上是由UUID+TID组成的。其中UUID是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。
- 下面是一个GTID的具体形式:
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
4.8 GTID的新特性
(1)支持多线程复制:事实上是针对每个database开启相应的独立线程,即每个库有一个单独的(sql thread)
(2)支持启用GTID,在配置主从复制,传统的方式里,你需要找到binlog和POS点,然后change master to 指向。在mysql5.6里,无须再知道binlog和POS点,只需要知道master的IP/端口/账号密码即可,因为同步复制是自动的,MySQL通过内部机制GTID自动找点同步。
(3)基于Row复制只保存改变的列,大大节省磁盘空间,网络,内存等
(4)支持把Master和Slave的相关信息记录在Table中;原来是记录在文件里,现在则记录在表里,增强可用性
(5)支持延迟复制
4.9 开启方法
mysql配置文件:
[mysqld]
gtid_mode=ON
enforce_gtid_consistency
查看show global variables like ‘%gtid%’;
4.10 从库设置
登陆从库,临时禁用自动删除relay log功能命令:set global relay_log_purge = 0;
设置只读命令:set global read_only=1;
永久禁用编辑配置文件/etc/my.cnf



五,部署MHA
5.1 环境准备(所有节点mysql-master,mysql-slaveA,mysql-slaveB)
光盘安装依赖包,安装mha4mysql-node-0.56-0.el6.noarch.rpm
3台MySQL都需要安装mha4mysql-node-0.56-0.el6.noarch.rpm






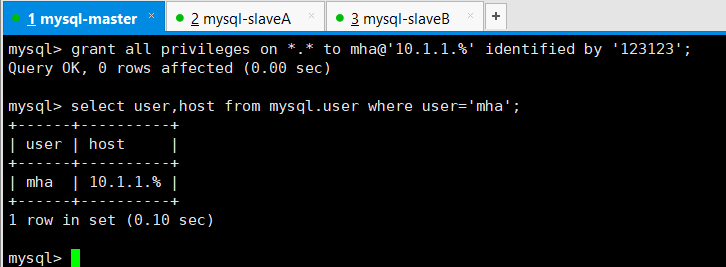
创建mha管理账号,主库上创建从库会自动复制

5.2 部署管理节点(mha-manager)
5.2.1 在mysql-slaveB上部署管理节点
使用阿里云源+epel源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.rep
wget -O /etc/yum.repos.d/epel-6.repo http://mirrors.aliyun.com/repo/epel-6.repo
安装manager依赖包(需要公网源)

安装manager包

5.2.2 编辑配置文件
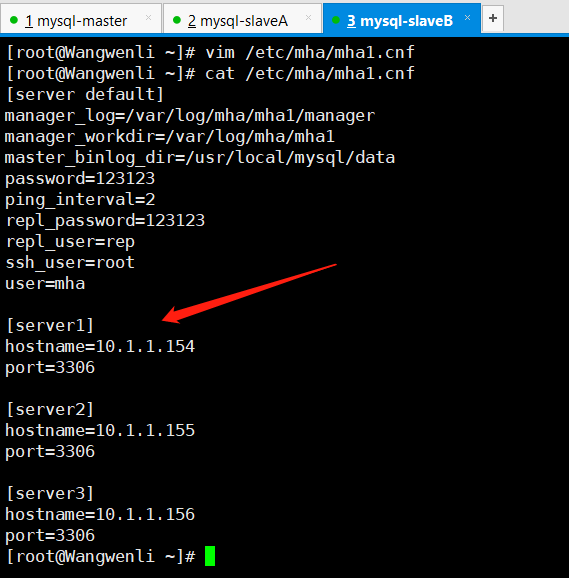
创建配置文件目录,创建配置文件(默认没有)
manager_log=/var/log/mha/mha1/manager #manager管理日志存放路径
manager_workdir=/var/log/mha/mha1 #manager管理日志的目录路径
master_binlog_dir=/usr/local/mysql/data #binlog日志的存放路径
user=mha #管理账户
password=123123 #管理账户密码
ping_interval=2 #存活检查的间隔时间
repl_user=rep #主从复制的授权账户
repl_password=123123 #主从复制的授权账户密码
ssh_user=root #用于ssh连接的账户
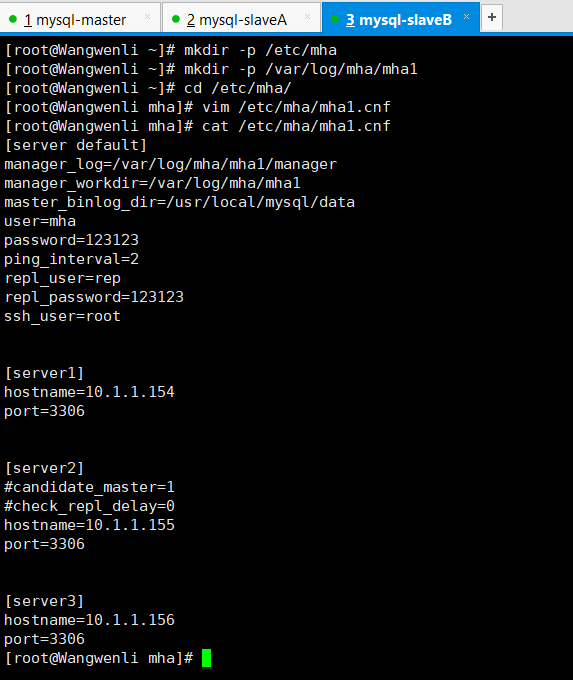
#candidate_master=1 #此条暂时注释掉(后面解释)#check_repl_delay=0 #此条暂时注释掉(后面解释)
以上配置文件内容里每行的最后不要留有空格
特别说明:
参数:candidate_master=1
解释:设置为候选master,如果设置该参数以后,发生主从切换以后会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
参数:check_repl_delay=0
解释:默认情况下如果一个slave落后master 100M的relay logs 的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
5.3 配置ssh信任(所有节点mysql-master,mysql-slaveA,mysql-slaveB)
创建密钥对


发送mysql-master公钥,包括自己
发送mysql-slaveA公钥,包括自己
发送mysql-slaveB公钥,包括自己

5.4 启动测试
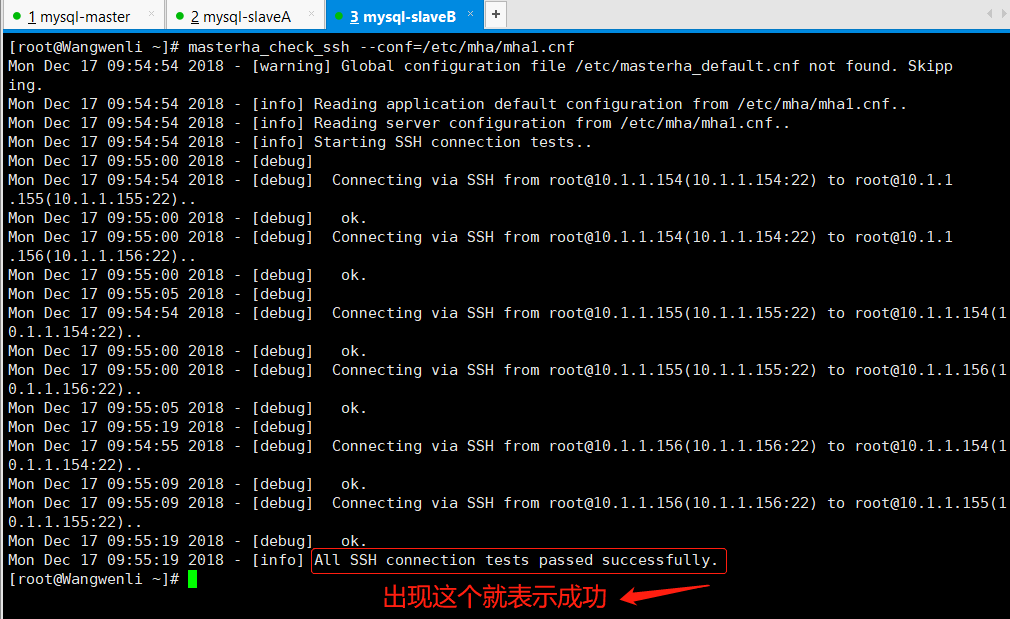
5.4.1 ssh检查检测 masterha_check_ssh --conf=/etc/mha/mha1.cnf #ssh检查命令
5.4.2 主从复制检测
(1)错误的主从复制检测masterha_check_repl --conf=/etc/mha/mha1.cnf
如果不出意外,检测结果都会是下面的样子
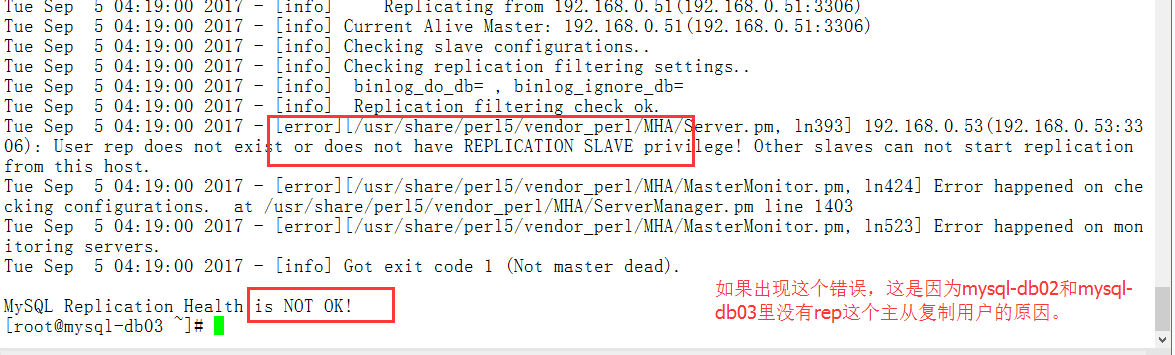
因此在mysql-slaveA和mysql-slaveB上添加主从复制的用户即可。
grant replication slave on *.* to rep@'10.1.1.%' identified by '123123';
再次检查如下图所示:
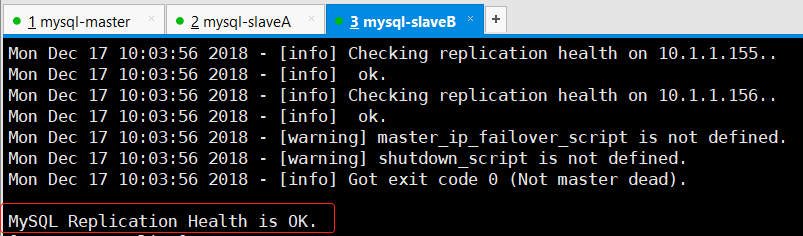
5.5 启动MHA
说明:
nohup:启动命令
--conf:指定配置文件位置
--remove_dead_master_conf:如果有master down了,就去掉配置文件里该master的部分。
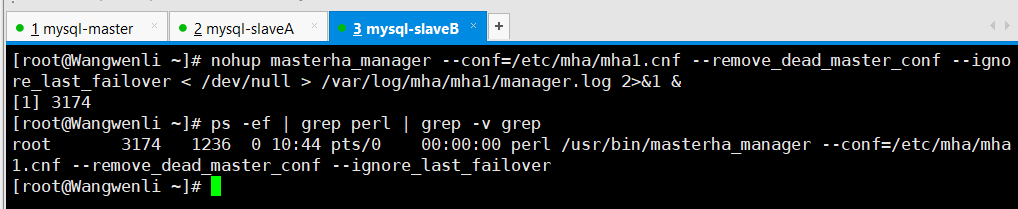
5.6 进行mha自动切换master的测试
1)登陆mysql-slaveA(10.1.1.155)查看信息状态


(2)停掉mysql-master(10.1.1.154)上的MySQL服务

(3)查看mysql-slaveB上的MySQL从库同步状态

(4)查看mysql-slaveA上的MySQL,主库同步状态。

(5)查看mysql-slaveB上的mha进程状态
查询发现mha进程已经没了

(6)查看mha配置文件信息

说明:
当作为主库的mysql-master上的MySQL宕机以后,mha通过检测发现mysql-master宕机,那么会将binlog日志最全的从库立刻提升为主库,而其他的从库会指向新的主库进行再次同步。
此处需要进行简单的mha日志记录的讲解:/var/log/mha/mha1/manager

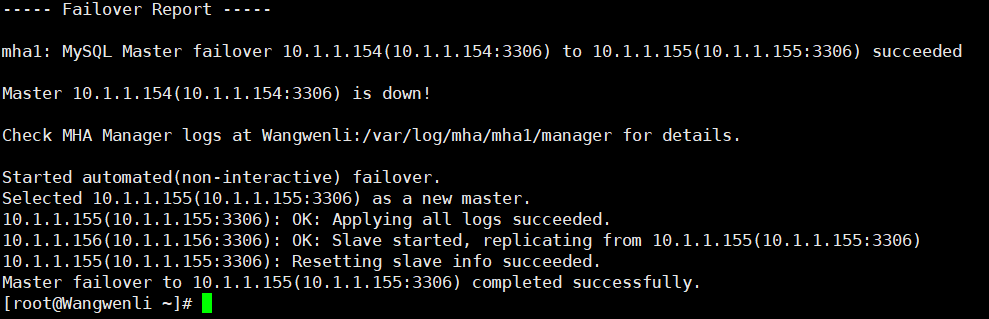
5.7 进行mha的故障还原测试
由于mysql-master的MySQL服务宕机,因此mha将mysql-slaveA提升为了主库。因此,我们需要将宕机的mysql-master的MySQL服务启动,然后作为主库mysql-slaveA的从库。
(1)将故障宕机的mysql-db01的MySQL服务启动并授权进行从同步
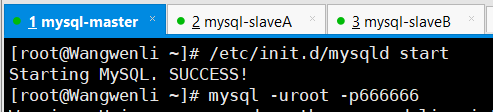
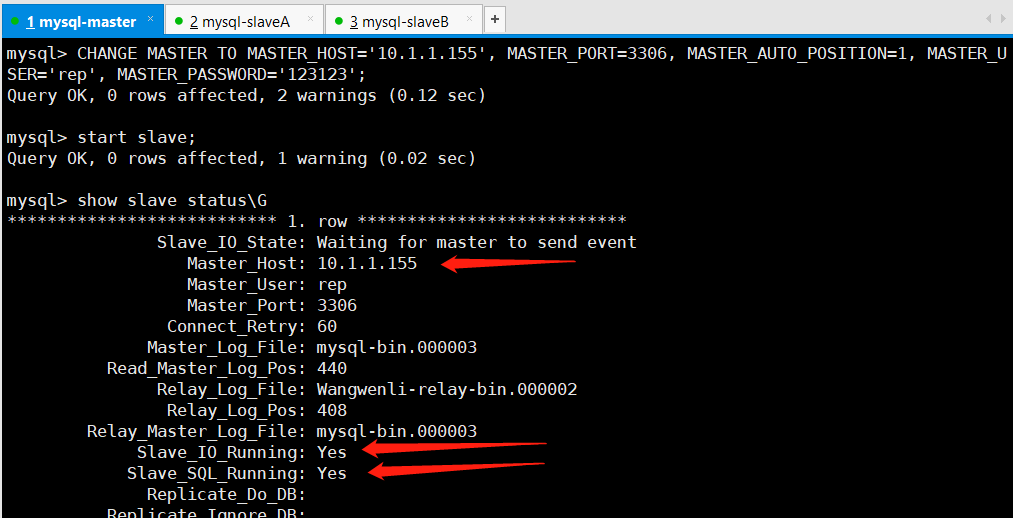
(2)将mha配置文件里缺失的部分补全
(3)启动mha进程

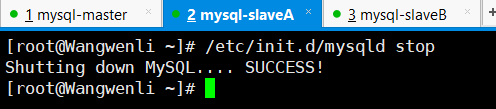
(4)停掉mysql-slaveA上的MySQL服务
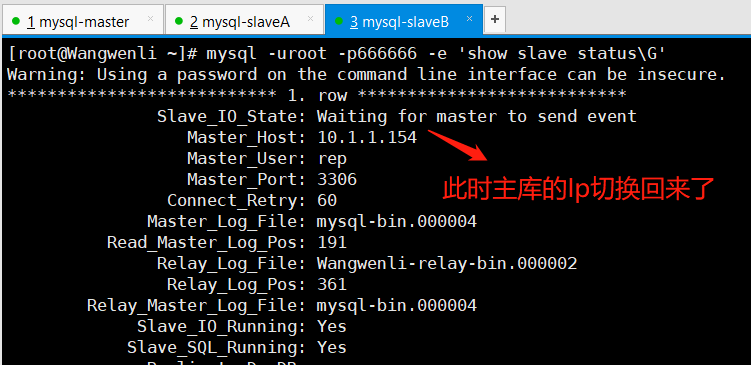
(5)查看mysql-slaveB上的主从同步状态:
(6)启动mysql-slaveA上的MySQL服务


(7)再次补全mha配置文件后,启动mha进程


六,配置VIP漂移
| 主机名 | IP地址(NAT) | 漂移VIP | 描述 |
|---|---|---|---|
| mysql-master | eth0:10.1.1.154 | VIP:10.1.1.60 | 系统:CentOS6.5(6.x都可以) 安装:mysql5.6 |
| mysql-slaveA | eth0:10.1.1.155 | VIP:10.1.1.60 | 系统:CentOS6.5(6.x都可以) 安装:mysql5.6 |
| mysql-slaveB | eth0:10.1.1.156 | VIP:10.1.1.60 | 系统:CentOS6.5(6.x都可以) 安装:mysql5.6 |
6.1 IP漂移的两种方式
- 通过keepalived的方式,管理虚拟IP的漂移
- 通过MHA自带脚本方式,管理虚拟IP的漂移
6.2 MHA脚本管理方式
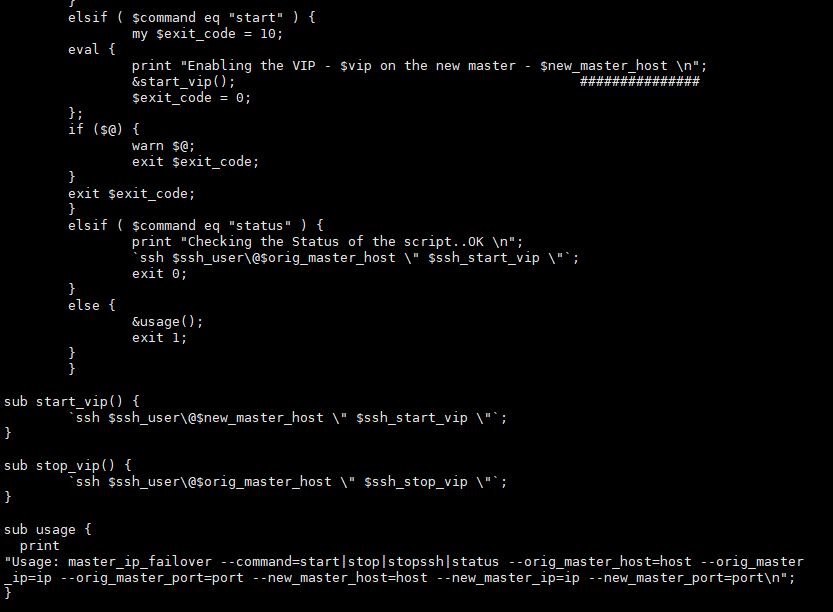
(1)获取管理脚本master_ip_failover
yum安装的manager是没有这个脚本的。 我们需要从manager的源码包里复制一个。
自带的脚本不好用,用自己的脚本。由于自带的模板脚本特别的坑,需要修改的地方太多,因此可以直接拷贝脚本文件放到/usr/local/bin目录下,并赋予x权限。

记得修改脚本里的vip哦
(2)修改mha配置文件

修改后的master_ip_failover脚本的内容如下:

(4)重启动mha管理端



如果启动mha进程失败,需要进行mha的连接检测
masterha_check_ssh --conf=/etc/mha/mha1.cnf ssh连接检测
masterha_check_repl --conf=/etc/mha/mha1.cnf 主从复制检测
或者配置文件的问题,配置文件有错误。
6.3 VIP漂移脚本验证测试。
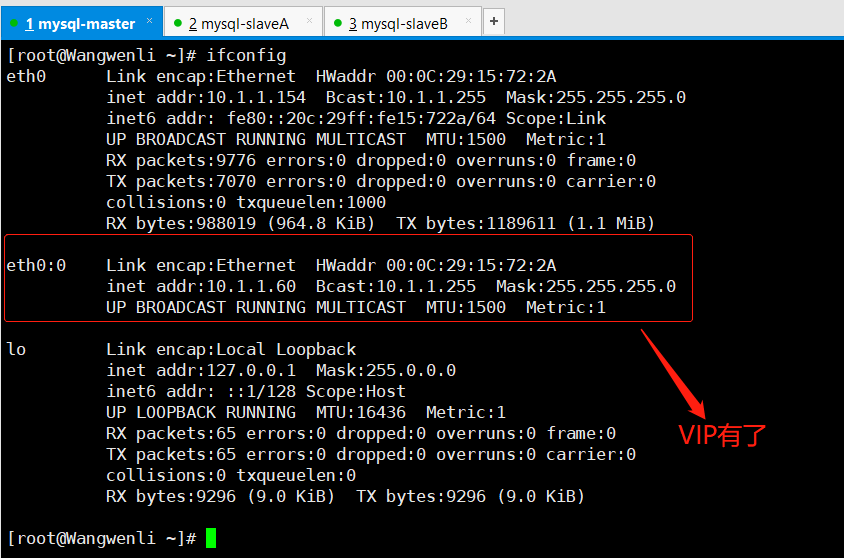
(1)查看mysql-master网络状态
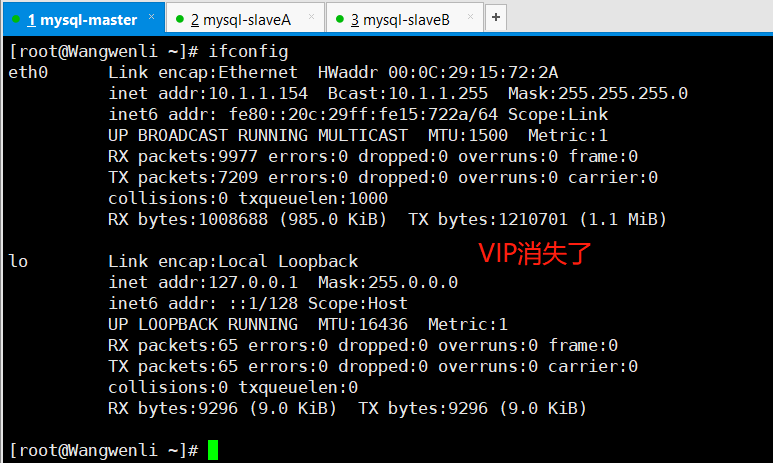
(2)停掉mysql-master的MySQL数据库服务

(3)查看mysql-slaveA

(4)查看mysql-slaveB的主从同步情况

(5)mysql-master故障恢复


(6)补上缺失的mha配置文件

(7)启动mha管理进程

七,配置binlog-server备份服务器
主库宕机,也许会造成主库binlog复制不及时而导致数据丢失的情况出现,因此配置binlog-server进行时时同步备份,是必要的一种安全手段。
7.1 修改mha配置文件
master_binlog_dir=/usr/local/mysql/data #全局的binlog存放位置
[binlog1] #添加binlog模块
no_master=1 #不允许切换为主
hostname=192.168.0.53 #存放IP
master_binlog_dir=/data/mysql/binlog/ #binlog存放位置优先级比全局的高

7.2 拉取主库上的binlog日志到mysq-slaveB的存放目录里
mysqlbinlog -R --host=10.1.1.60 --user=mha --password=123123 --raw --stop-never mysql-bin.000001 & #拉取主库binlog
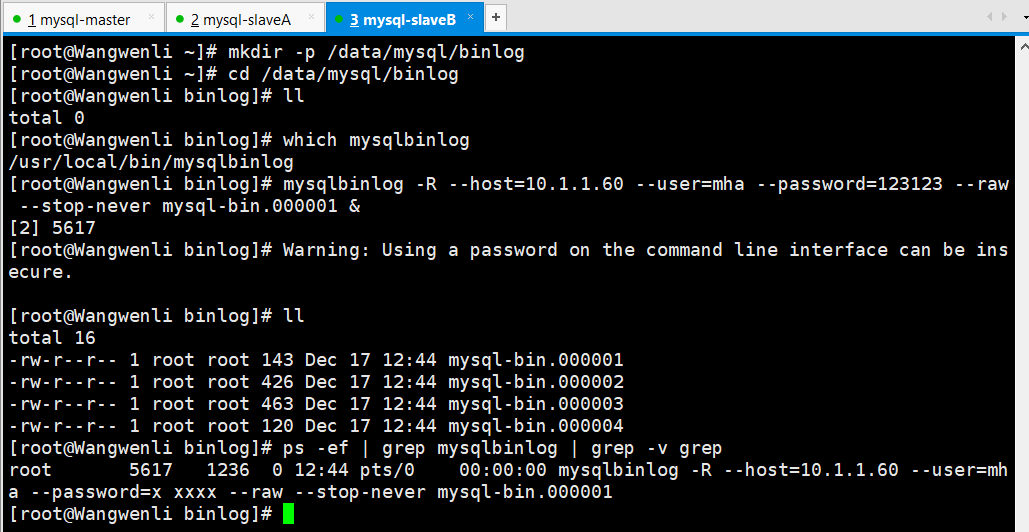
7.3 启动mha管理进程

以上就是整个MHA的过程。