平时在处理df series格式的时候并没有注意 map和apply的差异
总感觉没啥却别。不过还是有区别的。下面总结一下:
import pandas as pd
df1= pd.DataFrame({
"sales1":[-1,2,3],
"sales2":[3,-5,7],
})
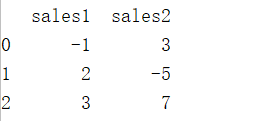
1.apply
1、当我们要对数据框(DataFrame)的数据进行按行或按列操作时用apply()
note:操作的原子是行和列 ,可以用行列统计描述符 min max mean ......
当axis=0的时候是对“列”进行操作
df2=df1.apply(lambda x: x.max()-x.min(),axis=0)
print(type(df2)," ",df2)

axis=1的时候是对“行”进行操作
df3=df1.apply(lambda x: x.max()-x.min(),axis=1)
print(type(df3)," ",df3)

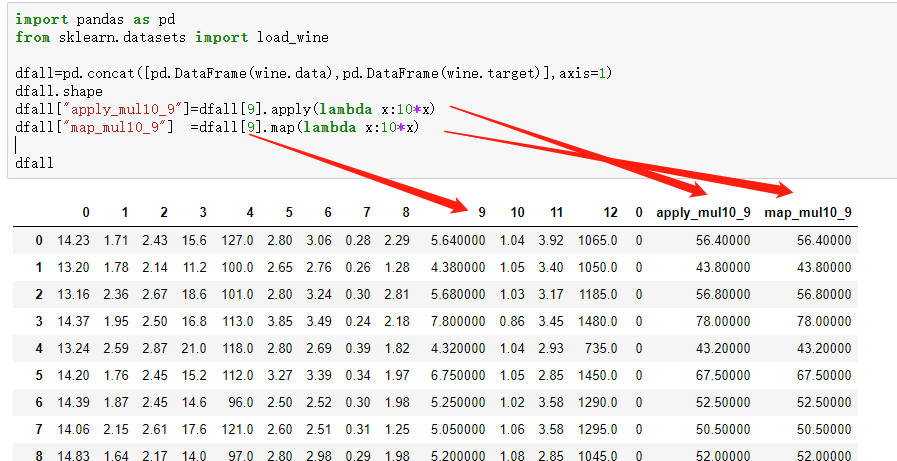
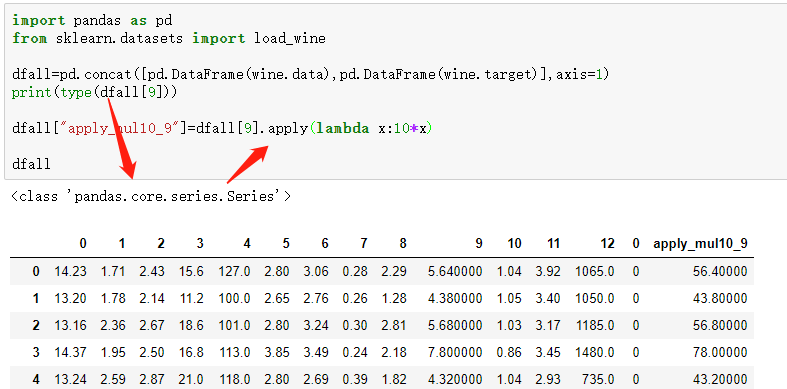
2.也可以直接选定一列series,或者df直接操作
2.applymap
1.applymap函数之后,自动对DataFrame每一个元素进行处理,判断之后输出结果
df4=df1.applymap(lambda x: x>0)
print(type(df4)," ",df4)

2.applymap是对 DataFrame 进行每个元素的单独操作
ie:不能添加列统计函数,因为是只针对单个元素的操作
df5=df1.applymap(lambda x: x.min()) print(type(df5)," ",df5)

3.'Series' object has no attribute 'applymap'
df4=df1["sales1"].applymap(lambda x: x>0) print(type(df4)," ",df4)

3.map
1.'DataFrame' object has no attribute 'map'
df4=df1.map(lambda x: x**2) print(type(df4)," ",df4)

2.map其实是对 列,series 等 进行每个元素的单独操作
ie:不能添加列统计函数,因为是只针对单个元素的操作
df3=df1["sales1"].map(lambda x: x.max()-x.min()) print(type(df3)," ",df3)

3.正常
df4=df1["sales1"].map(lambda x: x**2) print(type(df4)," ",df4)
