k-means Clustering(k平均聚类算法)
简介:
无监督学习对图像进行分类时,可以采用k-means算法。该算法实现简单,运行速度快。该算法要求事先知道数据所具有的类别数。k-means时数据最初的随机分类类别会对最终结果产生很大的影响。数据较少时k-means算法分类可能会失败。
k-means 算法:
- 为每个数据随机分配类
- 计算每个类的重心
- 计算每个数据与重心之间的距离,将该数据分配到重心距离最近的那个类
- 重复步骤2和步骤3直到没有数据的类别发生改变为止
实验:
类似于上一篇文章 讲解有监督学习实例 ,将色彩量化后图像的直方图作为识别时的特征量。
实验流程:
- 对图像进行减色化处理,然后计算直方图,将其用作特征量
- 对每张图随机分配类别0或类别1(已知类别数为2)
- 分别计算类别0和类别1的特征量的质心(质心存储在 gs=np.zeros((Class,12),dtype=np.float32)中),gs具有如下图所示的形状和内容:
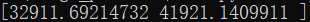
- 对于每个图像,计算特征量与质心之间的距离(在此取欧式距离),并将图像类别指定为距离最近的质心所代表的类别
- 重复步骤3和步骤4直到没有数据的类别发生改变为止
实验代码(python):
import cv2
import numpy as np
import matplotlib.pyplot as plt
from glob import glob
# Dicrease color
def dic_color(img):
img //= 63
img = img * 64 + 32
return img
# Database
def get_DB():
# get training image path
train = glob("../dataset/train/*")
train.sort()
# prepare database
db = np.zeros((len(train), 13), dtype=np.int32)
pdb = []
# each train
for i, path in enumerate(train):
# read image
img = dic_color(cv2.imread(path))
# histogram
for j in range(4):
db[i, j] = len(np.where(img[..., 0] == (64 * j + 32))[0])
db[i, j+4] = len(np.where(img[..., 1] == (64 * j + 32))[0])
db[i, j+8] = len(np.where(img[..., 2] == (64 * j + 32))[0])
# get class
if 'akahara' in path:
cls = 0
elif 'madara' in path:
cls = 1
# store class label
db[i, -1] = cls
# add image path
pdb.append(path)
return db, pdb
# k-Means
def k_means(db, pdb, Class=2, th=0.5):
# copy database
feats = db.copy()
# initiate random seed
np.random.seed(4)
# assign random class
for i in range(len(feats)):
if np.random.random() < th:
feats[i, -1] = 0
else:
feats[i, -1] = 1
while True:
# prepare gravity
gs = np.zeros((Class, 12), dtype=np.float32)
change_count = 0
# compute gravity
for i in range(Class):
gs[i] = np.mean(feats[np.where(feats[..., -1] == i)[0], :12], axis=0)
# re-labeling
for i in range(len(feats)):
# get distance each nearest graviry
dis = np.sqrt(np.sum(np.square(np.abs(gs - feats[i, :12])), axis=1))
# get new label
pred = np.argmin(dis, axis=0)
# if label is difference from old label
if int(feats[i, -1]) != pred:
change_count += 1
feats[i, -1] = pred
if change_count < 1:
break
for i in range(db.shape[0]):
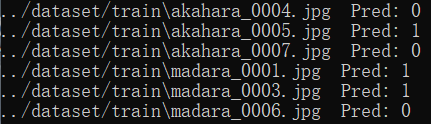
print(pdb[i], " Pred:", feats[i, -1])
db, pdb = get_DB()
k_means(db, pdb, th=0.3)
实验结果: