滑动平均原理部分:
注释:原理部分参考http://www.mbalib.com/,不过这个讲解的太菜了,评论清一色都是看不懂,大家简单看一下原理,例子别看了,越看越糊涂~~
简单移动平均的各元素的权重都相等。简单的移动平均的计算公式如下: Ft=(At-1+At-2+At-3+…+At-n)/n式中,
·Ft--对下一期的预测值;
·n--移动平均的时期个数;
·At-1--前期实际值;
·At-2,At-3和At-n分别表示前两期、前三期直至前n期的实际值。
加权移动平均给固定跨越期限内的每个变量值以不同的权重。其原理是:历史各期产品需求的数据信息对预测未来期内的需求量的作用是不一样的。除了以n为周期的周期性变化外,远离目标期的变量值的影响力相对较低,故应给予较低的权重。加权移动平均法的计算公式如下:
Ft=w1At-1+w2At-2+w3At-3+…+wnAt-n式中,
·w1--第t-1期实际销售额的权重;
·w2--第t-2期实际销售额的权重;
·wn--第t-n期实际销售额的权
·n--预测的时期数;w1+ w2+…+ wn=1
TF滑动平均原理:
TensorFlow中提供了tf.train.ExponentialMovingAverage 来实现滑动平均模型,在采用随机梯度下降算法训练神经网络时,使用其可以提高模型在测试数据上的健壮性(robustness)。
TensorFlow下的 tf.train.ExponentialMovingAverage 需要提供一个衰减率decay。该衰减率用于控制模型更新的速度。该衰减率用于控制模型更新的速度,ExponentialMovingAverage 对每一个待更新的变量(variable)都会维护一个影子变量(shadow variable),影子变量的初始值就是这个变量的初始值.
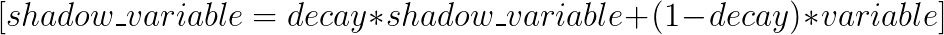
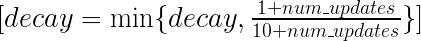
注释:其实原理大家一眼看去就明白了,但是实际操作还是有点麻烦的,我在这里不去单纯的讲解原理怎么实现,下面结合TF的例子和源代码去分析。
TF程序原理:
1 import tensorflow as tf 2 v1 = tf.Variable(0, dtype=tf.float32)#初始化v1变量 3 step = tf.Variable(0, trainable=False) #初始化step为0 4 ema = tf.train.ExponentialMovingAverage(0.99,step) #定义平滑类,设置参数以及step 5 maintain_averages_op = ema.apply([v1]) #定义更新变量平均操作, 6 with tf.Session() as sess: 7 # 初始化 8 init_op = tf.global_variables_initializer() 9 sess.run(init_op) 10 print (sess.run([v1, ema.average(v1)])) 11 # 更新变量v1的取值 12 sess.run(tf.assign(v1, 5)) 13 sess.run(maintain_averages_op) 14 print (sess.run([v1, ema.average(v1)])) 15 # 更新step和v1的取值 16 sess.run(tf.assign(step, 1)) 17 sess.run(tf.assign(v1, 1000)) 18 sess.run(maintain_averages_op) 19 print (sess.run([v1, ema.average(v1)])) 20 # 更新一次v1的滑动平均值 21 sess.run(maintain_averages_op) 22 print (sess.run([v1, ema.average(v1)]))
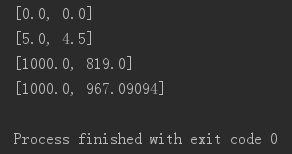
程序运行过程:
step1:V0 = 0 , step = 0 , decay = 0.1
result : [0.0,0.0]
step2:V1 = 0 , step = 0, decay = 0.1
result:[5.0,4.5]
step3:V1 = 1000 , step = 1, decay = 0.1818
result:[1000,819.0]
step4:V1 = 1000 , step = 1, decay = 0.1818
result:[1000,967.09094]
TF源代码:1 # Copyright 2015 The TensorFlow Authors. All Rights Reserved. 2 # 3 # Licensed under the Apache License, Version 2.0 (the "License"); 4 # you may not use this file except in compliance with the License. 5 # You may obtain a copy of the License at 6 # 7 # http://www.apache.org/licenses/LICENSE-2.0 8 # 9 # Unless required by applicable law or agreed to in writing, software 10 # distributed under the License is distributed on an "AS IS" BASIS, 11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 # See the License for the specific language governing permissions and 13 # limitations under the License. 14 # ============================================================================== 15 """Maintain moving averages of parameters.""" 16 from __future__ import absolute_import 17 from __future__ import division 18 from __future__ import print_function 19 20 from tensorflow.python.framework import dtypes 21 from tensorflow.python.framework import ops 22 from tensorflow.python.ops import control_flow_ops 23 from tensorflow.python.ops import init_ops 24 from tensorflow.python.ops import math_ops 25 from tensorflow.python.ops import state_ops 26 from tensorflow.python.ops import variable_scope 27 from tensorflow.python.ops import variables 28 from tensorflow.python.training import slot_creator 29 from tensorflow.python.util.tf_export import tf_export 30 31 32 # TODO(touts): switch to variables.Variable. 33 def assign_moving_average(variable, value, decay, zero_debias=True, name=None): 34 """Compute the moving average of a variable. 35 36 The moving average of 'variable' updated with 'value' is: 37 variable * decay + value * (1 - decay) 38 39 The returned Operation sets 'variable' to the newly computed moving average. 40 41 The new value of 'variable' can be set with the 'AssignSub' op as: 42 variable -= (1 - decay) * (variable - value) 43 44 Since variables that are initialized to a `0` value will be `0` biased, 45 `zero_debias` optionally enables scaling by the mathematically correct 46 debiasing factor of 47 1 - decay ** num_updates 48 See `ADAM: A Method for Stochastic Optimization` Section 3 for more details 49 (https://arxiv.org/abs/1412.6980). 50 51 The names of the debias shadow variables, by default, include both the scope 52 they were created in and the scope of the variables they debias. They are also 53 given a uniqifying-suffix. 54 55 E.g.: 56 57 ``` 58 with tf.variable_scope('scope1'): 59 with tf.variable_scope('scope2'): 60 var = tf.get_variable('foo') 61 tf.assign_moving_average(var, 0.0, 1.0) 62 tf.assign_moving_average(var, 0.0, 0.9) 63 64 # var.name: 'scope1/scope2/foo' 65 # shadow var names: 'scope1/scope2/scope1/scope2/foo/biased' 66 # 'scope1/scope2/scope1/scope2/foo/biased_1' 67 ``` 68 69 Args: 70 variable: A Variable. 71 value: A tensor with the same shape as 'variable'. 72 decay: A float Tensor or float value. The moving average decay. 73 zero_debias: A python bool. If true, assume the variable is 0-initialized 74 and unbias it, as in https://arxiv.org/abs/1412.6980. See docstring in 75 `_zero_debias` for more details. 76 name: Optional name of the returned operation. 77 78 Returns: 79 A reference to the input 'variable' tensor with the newly computed 80 moving average. 81 """ 82 with ops.name_scope(name, "AssignMovingAvg", 83 [variable, value, decay]) as scope: 84 with ops.colocate_with(variable): 85 decay = ops.convert_to_tensor(1.0 - decay, name="decay") 86 if decay.dtype != variable.dtype.base_dtype: 87 decay = math_ops.cast(decay, variable.dtype.base_dtype) 88 if zero_debias: 89 update_delta = _zero_debias(variable, value, decay) 90 else: 91 update_delta = (variable - value) * decay 92 return state_ops.assign_sub(variable, update_delta, name=scope) 93 94 95 def weighted_moving_average(value, 96 decay, 97 weight, 98 truediv=True, 99 collections=None, 100 name=None): 101 """Compute the weighted moving average of `value`. 102 103 Conceptually, the weighted moving average is: 104 `moving_average(value * weight) / moving_average(weight)`, 105 where a moving average updates by the rule 106 `new_value = decay * old_value + (1 - decay) * update` 107 Internally, this Op keeps moving average variables of both `value * weight` 108 and `weight`. 109 110 Args: 111 value: A numeric `Tensor`. 112 decay: A float `Tensor` or float value. The moving average decay. 113 weight: `Tensor` that keeps the current value of a weight. 114 Shape should be able to multiply `value`. 115 truediv: Boolean, if `True`, dividing by `moving_average(weight)` is 116 floating point division. If `False`, use division implied by dtypes. 117 collections: List of graph collections keys to add the internal variables 118 `value * weight` and `weight` to. 119 Defaults to `[GraphKeys.GLOBAL_VARIABLES]`. 120 name: Optional name of the returned operation. 121 Defaults to "WeightedMovingAvg". 122 123 Returns: 124 An Operation that updates and returns the weighted moving average. 125 """ 126 # Unlike assign_moving_average, the weighted moving average doesn't modify 127 # user-visible variables. It is the ratio of two internal variables, which are 128 # moving averages of the updates. Thus, the signature of this function is 129 # quite different than assign_moving_average. 130 if collections is None: 131 collections = [ops.GraphKeys.GLOBAL_VARIABLES] 132 with variable_scope.variable_scope(name, "WeightedMovingAvg", 133 [value, weight, decay]) as scope: 134 value_x_weight_var = variable_scope.get_variable( 135 "value_x_weight", 136 shape=value.get_shape(), 137 dtype=value.dtype, 138 initializer=init_ops.zeros_initializer(), 139 trainable=False, 140 collections=collections) 141 weight_var = variable_scope.get_variable( 142 "weight", 143 shape=weight.get_shape(), 144 dtype=weight.dtype, 145 initializer=init_ops.zeros_initializer(), 146 trainable=False, 147 collections=collections) 148 numerator = assign_moving_average( 149 value_x_weight_var, value * weight, decay, zero_debias=False) 150 denominator = assign_moving_average( 151 weight_var, weight, decay, zero_debias=False) 152 153 if truediv: 154 return math_ops.truediv(numerator, denominator, name=scope.name) 155 else: 156 return math_ops.div(numerator, denominator, name=scope.name) 157 158 159 def _zero_debias(unbiased_var, value, decay): 160 """Compute the delta required for a debiased Variable. 161 162 All exponential moving averages initialized with Tensors are initialized to 0, 163 and therefore are biased to 0. Variables initialized to 0 and used as EMAs are 164 similarly biased. This function creates the debias updated amount according to 165 a scale factor, as in https://arxiv.org/abs/1412.6980. 166 167 To demonstrate the bias the results from 0-initialization, take an EMA that 168 was initialized to `0` with decay `b`. After `t` timesteps of seeing the 169 constant `c`, the variable have the following value: 170 171 ``` 172 EMA = 0*b^(t) + c*(1 - b)*b^(t-1) + c*(1 - b)*b^(t-2) + ... 173 = c*(1 - b^t) 174 ``` 175 176 To have the true value `c`, we would divide by the scale factor `1 - b^t`. 177 178 In order to perform debiasing, we use two shadow variables. One keeps track of 179 the biased estimate, and the other keeps track of the number of updates that 180 have occurred. 181 182 Args: 183 unbiased_var: A Variable representing the current value of the unbiased EMA. 184 value: A Tensor representing the most recent value. 185 decay: A Tensor representing `1-decay` for the EMA. 186 187 Returns: 188 The amount that the unbiased variable should be updated. Computing this 189 tensor will also update the shadow variables appropriately. 190 """ 191 with variable_scope.variable_scope( 192 unbiased_var.op.name, values=[unbiased_var, value, decay]) as scope: 193 with ops.colocate_with(unbiased_var): 194 with ops.init_scope(): 195 biased_initializer = init_ops.zeros_initializer( 196 dtype=unbiased_var.dtype)(unbiased_var.get_shape()) 197 local_step_initializer = init_ops.zeros_initializer() 198 def _maybe_get_unique(name): 199 """Get name for a unique variable, if not `reuse=True`.""" 200 if variable_scope.get_variable_scope().reuse: 201 return name 202 vs_vars = [x.op.name for x in 203 variable_scope.get_variable_scope().global_variables()] 204 full_name = variable_scope.get_variable_scope().name + "/" + name 205 if full_name not in vs_vars: return name 206 idx = 1 207 while full_name + ("_%d" % idx) in vs_vars: 208 idx += 1 209 return name + ("_%d" % idx) 210 biased_var = variable_scope.get_variable( 211 _maybe_get_unique("biased"), initializer=biased_initializer, 212 trainable=False) 213 local_step = variable_scope.get_variable( 214 _maybe_get_unique("local_step"), 215 shape=[], 216 dtype=unbiased_var.dtype, 217 initializer=local_step_initializer, 218 trainable=False) 219 220 # Get an update ops for both shadow variables. 221 update_biased = state_ops.assign_sub(biased_var, 222 (biased_var - value) * decay, 223 name=scope.name) 224 update_local_step = local_step.assign_add(1) 225 226 # Compute the value of the delta to update the unbiased EMA. Make sure to 227 # use the new values of the biased variable and the local step. 228 with ops.control_dependencies([update_biased, update_local_step]): 229 # This function gets `1 - decay`, so use `1.0 - decay` in the exponent. 230 unbiased_ema_delta = (unbiased_var - biased_var.read_value() / 231 (1 - math_ops.pow( 232 1.0 - decay, local_step.read_value()))) 233 234 return unbiased_ema_delta 235 236 237 @tf_export("train.ExponentialMovingAverage") 238 class ExponentialMovingAverage(object): 239 """Maintains moving averages of variables by employing an exponential decay. 240 241 When training a model, it is often beneficial to maintain moving averages of 242 the trained parameters. Evaluations that use averaged parameters sometimes 243 produce significantly better results than the final trained values. 244 245 The `apply()` method adds shadow copies of trained variables and add ops that 246 maintain a moving average of the trained variables in their shadow copies. 247 It is used when building the training model. The ops that maintain moving 248 averages are typically run after each training step. 249 The `average()` and `average_name()` methods give access to the shadow 250 variables and their names. They are useful when building an evaluation 251 model, or when restoring a model from a checkpoint file. They help use the 252 moving averages in place of the last trained values for evaluations. 253 254 The moving averages are computed using exponential decay. You specify the 255 decay value when creating the `ExponentialMovingAverage` object. The shadow 256 variables are initialized with the same initial values as the trained 257 variables. When you run the ops to maintain the moving averages, each 258 shadow variable is updated with the formula: 259 260 `shadow_variable -= (1 - decay) * (shadow_variable - variable)` 261 262 This is mathematically equivalent to the classic formula below, but the use 263 of an `assign_sub` op (the `"-="` in the formula) allows concurrent lockless 264 updates to the variables: 265 266 `shadow_variable = decay * shadow_variable + (1 - decay) * variable` 267 268 Reasonable values for `decay` are close to 1.0, typically in the 269 multiple-nines range: 0.999, 0.9999, etc. 270 271 Example usage when creating a training model: 272 273 ```python 274 # Create variables. 275 var0 = tf.Variable(...) 276 var1 = tf.Variable(...) 277 # ... use the variables to build a training model... 278 ... 279 # Create an op that applies the optimizer. This is what we usually 280 # would use as a training op. 281 opt_op = opt.minimize(my_loss, [var0, var1]) 282 283 # Create an ExponentialMovingAverage object 284 ema = tf.train.ExponentialMovingAverage(decay=0.9999) 285 286 with tf.control_dependencies([opt_op]): 287 # Create the shadow variables, and add ops to maintain moving averages 288 # of var0 and var1. This also creates an op that will update the moving 289 # averages after each training step. This is what we will use in place 290 # of the usual training op. 291 training_op = ema.apply([var0, var1]) 292 293 ...train the model by running training_op... 294 ``` 295 296 There are two ways to use the moving averages for evaluations: 297 298 * Build a model that uses the shadow variables instead of the variables. 299 For this, use the `average()` method which returns the shadow variable 300 for a given variable. 301 * Build a model normally but load the checkpoint files to evaluate by using 302 the shadow variable names. For this use the `average_name()` method. See 303 the @{tf.train.Saver} for more 304 information on restoring saved variables. 305 306 Example of restoring the shadow variable values: 307 308 ```python 309 # Create a Saver that loads variables from their saved shadow values. 310 shadow_var0_name = ema.average_name(var0) 311 shadow_var1_name = ema.average_name(var1) 312 saver = tf.train.Saver({shadow_var0_name: var0, shadow_var1_name: var1}) 313 saver.restore(...checkpoint filename...) 314 # var0 and var1 now hold the moving average values 315 ``` 316 """ 317 318 def __init__(self, decay, num_updates=None, zero_debias=False, 319 name="ExponentialMovingAverage"): 320 """Creates a new ExponentialMovingAverage object. 321 322 The `apply()` method has to be called to create shadow variables and add 323 ops to maintain moving averages. 324 325 The optional `num_updates` parameter allows one to tweak the decay rate 326 dynamically. It is typical to pass the count of training steps, usually 327 kept in a variable that is incremented at each step, in which case the 328 decay rate is lower at the start of training. This makes moving averages 329 move faster. If passed, the actual decay rate used is: 330 331 `min(decay, (1 + num_updates) / (10 + num_updates))` 332 333 Args: 334 decay: Float. The decay to use. 335 num_updates: Optional count of number of updates applied to variables. 336 zero_debias: If `True`, zero debias moving-averages that are initialized 337 with tensors. 338 name: String. Optional prefix name to use for the name of ops added in 339 `apply()`. 340 """ 341 self._decay = decay 342 self._num_updates = num_updates 343 self._zero_debias = zero_debias 344 self._name = name 345 self._averages = {} 346 def apply(self, var_list=None): 347 """Maintains moving averages of variables. 348 349 `var_list` must be a list of `Variable` or `Tensor` objects. This method 350 creates shadow variables for all elements of `var_list`. Shadow variables 351 for `Variable` objects are initialized to the variable's initial value. 352 They will be added to the `GraphKeys.MOVING_AVERAGE_VARIABLES` collection. 353 For `Tensor` objects, the shadow variables are initialized to 0 and zero 354 debiased (see docstring in `assign_moving_average` for more details). 355 356 shadow variables are created with `trainable=False` and added to the 357 `GraphKeys.ALL_VARIABLES` collection. They will be returned by calls to 358 `tf.global_variables()`. 359 360 Returns an op that updates all shadow variables as described above. 361 362 Note that `apply()` can be called multiple times with different lists of 363 variables. 364 365 Args: 366 var_list: A list of Variable or Tensor objects. The variables 367 and Tensors must be of types float16, float32, or float64. 368 369 Returns: 370 An Operation that updates the moving averages. 371 372 Raises: 373 TypeError: If the arguments are not all float16, float32, or float64. 374 ValueError: If the moving average of one of the variables is already 375 being computed. 376 """ 377 # TODO(touts): op_scope 378 if var_list is None: 379 var_list = variables.trainable_variables() 380 zero_debias_true = set() # set of vars to set `zero_debias=True` 381 for var in var_list: 382 if var.dtype.base_dtype not in [dtypes.float16, dtypes.float32, 383 dtypes.float64]: 384 raise TypeError("The variables must be half, float, or double: %s" % 385 var.name) 386 if var in self._averages: 387 raise ValueError("Moving average already computed for: %s" % var.name) 388 389 # For variables: to lower communication bandwidth across devices we keep 390 # the moving averages on the same device as the variables. For other 391 # tensors, we rely on the existing device allocation mechanism. 392 with ops.init_scope(): 393 if isinstance(var, variables.Variable): 394 avg = slot_creator.create_slot(var, 395 var.initialized_value(), 396 self._name, 397 colocate_with_primary=True) 398 # NOTE(mrry): We only add `tf.Variable` objects to the 399 # `MOVING_AVERAGE_VARIABLES` collection. 400 ops.add_to_collection(ops.GraphKeys.MOVING_AVERAGE_VARIABLES, var) 401 else: 402 avg = slot_creator.create_zeros_slot( 403 var, 404 self._name, 405 colocate_with_primary=(var.op.type in ["Variable", 406 "VariableV2", 407 "VarHandleOp"])) 408 if self._zero_debias: 409 zero_debias_true.add(avg) 410 self._averages[var] = avg 411 412 with ops.name_scope(self._name) as scope: 413 decay = ops.convert_to_tensor(self._decay, name="decay") 414 if self._num_updates is not None: 415 num_updates = math_ops.cast(self._num_updates, 416 dtypes.float32, 417 name="num_updates") 418 decay = math_ops.minimum(decay, 419 (1.0 + num_updates) / (10.0 + num_updates)) 420 updates = [] 421 for var in var_list: 422 zero_debias = self._averages[var] in zero_debias_true 423 updates.append(assign_moving_average( 424 self._averages[var], var, decay, zero_debias=zero_debias)) 425 return control_flow_ops.group(*updates, name=scope) 426 427 def average(self, var): 428 """Returns the `Variable` holding the average of `var`. 429 430 Args: 431 var: A `Variable` object. 432 433 Returns: 434 A `Variable` object or `None` if the moving average of `var` 435 is not maintained. 436 """ 437 return self._averages.get(var, None) 438 439 def average_name(self, var): 440 """Returns the name of the `Variable` holding the average for `var`. 441 442 The typical scenario for `ExponentialMovingAverage` is to compute moving 443 averages of variables during training, and restore the variables from the 444 computed moving averages during evaluations. 445 446 To restore variables, you have to know the name of the shadow variables. 447 That name and the original variable can then be passed to a `Saver()` object 448 to restore the variable from the moving average value with: 449 `saver = tf.train.Saver({ema.average_name(var): var})` 450 451 `average_name()` can be called whether or not `apply()` has been called. 452 453 Args: 454 var: A `Variable` object. 455 456 Returns: 457 A string: The name of the variable that will be used or was used 458 by the `ExponentialMovingAverage class` to hold the moving average of 459 `var`. 460 """ 461 if var in self._averages: 462 return self._averages[var].op.name 463 return ops.get_default_graph().unique_name( 464 var.op.name + "/" + self._name, mark_as_used=False) 465 466 def variables_to_restore(self, moving_avg_variables=None): 467 """Returns a map of names to `Variables` to restore. 468 469 If a variable has a moving average, use the moving average variable name as 470 the restore name; otherwise, use the variable name. 471 472 For example, 473 474 ```python 475 variables_to_restore = ema.variables_to_restore() 476 saver = tf.train.Saver(variables_to_restore) 477 ``` 478 479 Below is an example of such mapping: 480 481 ``` 482 conv/batchnorm/gamma/ExponentialMovingAverage: conv/batchnorm/gamma, 483 conv_4/conv2d_params/ExponentialMovingAverage: conv_4/conv2d_params, 484 global_step: global_step 485 ``` 486 Args: 487 moving_avg_variables: a list of variables that require to use of the 488 moving variable name to be restored. If None, it will default to 489 variables.moving_average_variables() + variables.trainable_variables() 490 491 Returns: 492 A map from restore_names to variables. The restore_name can be the 493 moving_average version of the variable name if it exist, or the original 494 variable name. 495 """ 496 name_map = {} 497 if moving_avg_variables is None: 498 # Include trainable variables and variables which have been explicitly 499 # added to the moving_average_variables collection. 500 moving_avg_variables = variables.trainable_variables() 501 moving_avg_variables += variables.moving_average_variables() 502 # Remove duplicates 503 moving_avg_variables = set(moving_avg_variables) 504 # Collect all the variables with moving average, 505 for v in moving_avg_variables: 506 name_map[self.average_name(v)] = v 507 # Make sure we restore variables without moving averages as well. 508 moving_avg_variable_names = set([v.name for v in moving_avg_variables]) 509 for v in list(set(variables.global_variables())): 510 if v.name not in moving_avg_variable_names and v.op.name not in name_map: 511 name_map[v.op.name] = v 512 return name_map
注释:
源代码读起来还是有一点吃力,可能我基础太差了,下面大概解读一下源代码。
1.class ExponentialMovingAverage(object)整个核心是寄托整个类进行的,下面的函数都是基于此
2.初始化函数
1 def __init__(self, decay, num_updates=None, zero_debias=False, 2 name="ExponentialMovingAverage") 3 decay: Float. The decay to use.初始化的权重 4 num_updates: Optional count of number of updates applied to variables.用来计算decay的一个迭代次数 5 zero_debias: If `True`, zero debias moving-averages that are initialized 6 with tensors. 7 name: String. Optional prefix name to use for the name of ops added in 8 `apply()`.
3.def apply(self, var_list=None)
var_list:当前已知的序列(用已知去预测未知)
最关键的一点是average函数的求解释在此函数之内进行的。
此函数释整个类的核心,滑动平均算法也是写在里面的。
4.def average_name(self, var)
读取平均值,也就是预测的值,上面讲解过了,此函数的代码实现是在apply中进行的。
5.def variables_to_restore(self, moving_avg_variables=None)
保存滑动平均数据
注释:让我最不能理解的是明明是min函数,最后得到的却是max~~~
decay = math_ops.minimum(decay,(1.0 + num_updates) / (10.0 + num_updates))
可能源代码有问题,反正实现很简单了。。