模块简介与matplotlib基础
1、基本概念
1.1数据分析
对已知的数据进行分析,提取出一些有价值的信息。
1.2数据挖掘
对大量的数据进行分析与挖掘,得到一些未知的,有价值的信息。
1.3数据挖掘过程
定义目标
获取数据(爬虫采集或下载统计网站发布的数据)
数据探索
数据预处理(数据清洗【去掉脏数据】、数据集成【集中】、数据变换【规范化】、数据规约【精简】)
数据建模(分类、聚类、关联、预测)
模型评价与发布
1.4模块简介
numpy可以高效的处理数据、提供数组支持
pandas主要用于数据探索和数据分析
matplotlib作图模块,解决可视化问题
scipy主要进行数据计算,同时支持矩阵运算,提供很多高等处理功能,比如积分、傅里叶变化等
statsnodels用于统计分析
Gensim文本挖掘
sklearn、keras前者机器学习,后者深度学习
1.5模块基本操作
'''numpy'''
import numpy
#创建一维数组格式
#numpy.array([元素1,元素2,...,元素n])
x=numpy.array(["a","b","c"])
#创建二维数据格式
#numpy.array([[元素1,元素2,...,元素n],[元素1,元素2,...,元素n],[元素1,元素2,...,元素n],...,[元素1,元素2,...,元素n]])
y=numpy.array([[1,2,3],[4,5,6],[7,8,9]])
#排序sort
x.sort()
y.sort()
#取最大值和最小值
y1=y.max()
y2=y.min()
#切片
#数组[起始下标:最终下标+1]
x[1:3]#取得就是数组的1-2,相当于取得是左闭右开区间的。如果右边不写则取到最后,若左边不写,则从最开始取
'''pandas'''
import pandas #若import pandas as pda,则之后可以使用pd代替pandas
'''
Series #index索引
DataFrame
'''
a=pandas.Series([8,9,2,1])
b=pandas.Series([8,9,2,1],index=[1,2,3,4])#index里面的值可以自由指定
c=pandas.DataFrame([[5,6,2,3],[8,4,6,3],[6,4,31,2]])
d=pandas.DataFrame([[5,6,2,3],[8,4,6,3],[6,4,31,2]],columns=["one","two","three","four"])
e=pandas.DataFrame({
"one":3, #生成3个3,自动补全
"two":[6,2,3],
"three":list(str(982)) #生成9、8、2
})
d.head()#头部数据,默认前五行
#d.head(行数)
d.tail()#尾部数据,默认后五行
#d.tail(行数)
d.describe()#展示数据统计信息
d.T#对d转置
1.6数据导入
1.6.1导入csv数据
csv是一种常见的数据存储格式,可以使用pandas导入csv数据
import pandas as pd
i=pd.read_csv("文件地址")
i.sort_value(by="某列的第一个数据") #表示按照某列排序
j=pd.read_excel(文件地址导入Excel文件
1.6.2导入HTML数据
使用pandas可以直接从HTML网页中加载对应table表格中的数据
l=pd.read_html("网址或者本地网页的地址")
1.6.3导入TXT文本数据
m=pd.read_table("TXT文件地址")
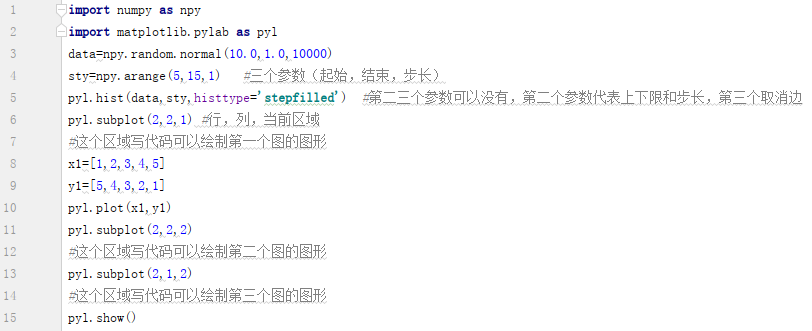
2、折线图、散点图和直方图的绘制
折线图和散点图用plot,直方图用hist

下面是直方图的绘制: