C变量
C 语言是如何把各种类型的变量转换成对应的汇编语言呢?
高级语言更容易被工程师理解,而汇编语言这样的低级语言,则更容易被机器解读。这是因为汇编语言里的大部分内容都跟机器语言一一对应,你可以这样理解,汇编语言就是把机器语言符号化。
汇编器会将汇编源代码生成二进制程序文件。在程序二进制文件里有很多段。其中 text 段和 data 段在文件里占用位置空间,text 段存放了程序指令的二进制数据,data 段放着各种已经初始化的数据。二进制文件里还有个更特殊的 bss 段,它不占用文件的位置空间,而是在文件头里记录 bss 段的大小。
一旦 text、data 段加载到内存中运行,就会占用内存空间,自然也就对应到实际的内存。至于 bss 段,操作台会根据文件头里记录的大小给它分配内存空间,并初始为 0。
写代码来验证下:
//定义整型变量
int i = 5;
//定义字符变量
char chars = 'a';
//定义结构体
struct data
{
int a;
char c;
};
//定义结构体变量并初始化
struct data d = {10, 'b'};
在代码中定义了三个不同类型的变量。在 GCC 编译器后面加上 -save-temps 选项,就能留下 GCC 编译器各个步骤生成的临时文件(xxxx.i、xxxx.s、xxxx.bin),方便我们查看 GCC 逐步处理的结果。
其中,xxxx.i 是 gcc 编译器生成的预处理文件,xxxx.s 是 gcc 编译器生成的汇编文件,xxxx.o 是 gcc 编译器生成的可链接的目标文件,xxxx.bin 是去除了 ELF 文件格式数据的纯二进制文件,这是我用 objcopy 工具生成的,这个文件可以方便我们后续观察。
variable.s 文件,如下所示:
.globl i #导出全局标号i
.section .sdata,"aw" #创建sdata段,属性动态分配可读写
.size i, 4 #占用4字节大小
i: #标号i
.word 5 #定义一个字,初始化为5
.globl chars #导出全局标号chars
.size chars, 1 #占用1字节大小
chars: #标号chars
.byte 97 #定义一个字节,初始化为97,正是‘a’字符的ascii码
.globl d #导出全局标号d
.size d, 8 #占用8字节大小
d: #标号d
.word 10 #定义一个字,初始化为10
.byte 98 #定义一个字节,初始化为98,正是‘b’字符的ascii码
.zero 3 #填充3个字节,数据为0
上面的汇编代码和注释已经写得很清楚了,C 语言的变量名变成了汇编语言中的标号,根据每个变量的大小,用多个汇编代码中定义数据的操作符,比如.byte、.word,进行定义初始化。
C 语言结构体中的字段则要用多个.byte、.word 操作符的组合实现变量定义,汇编器会根据.byte、.word 来分配变量的内存空间,标号就是对应的地址。这个变量的内存空间,当程序处于非运行状态时就反映在程序文件中;一旦程序加载到内存中运行,其中的变量就会加载到内存里,对应在相应的内存地址上。
上述代码仍然是可读的文本代码,来看下汇编器生成的二进制文件variable.bin:
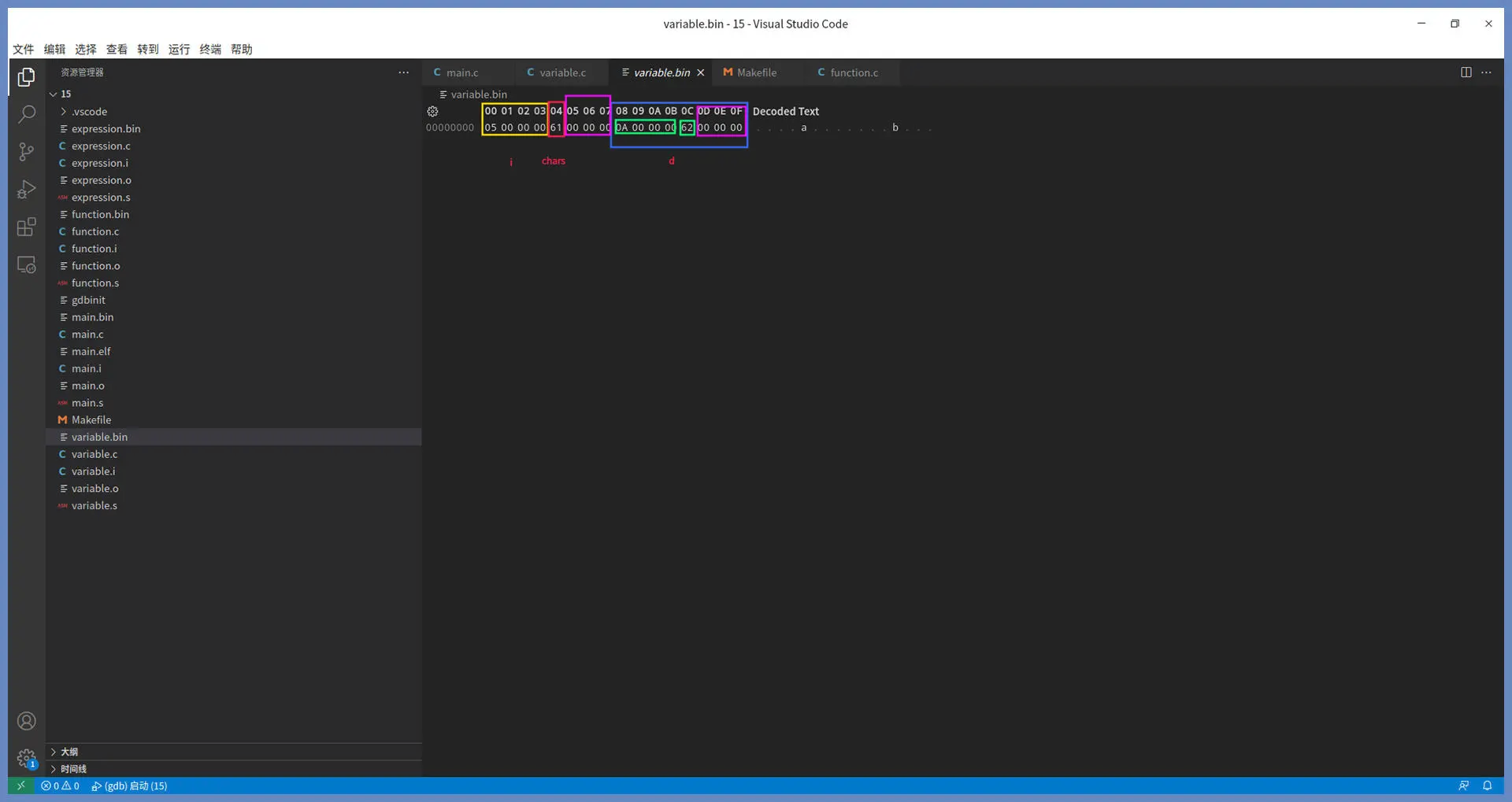
二进制文件 variable.bin 一共有 16 字节,第 5 到第 7 个字节和第 13 到第 15 个字节为填充字节,这是为了让地址可以按 32 位对齐。我们可以看到 i 变量占用 4 个字节空间,chars 变量占用 1 个字节空间,d 结构体变量占用 8 个字节,里面有两个成员变量 a 和 c。
截图中反映的情况,相当于从 0 开始分配地址空间,当然后面链接器会重新分配地址空间的,这里 i 变量地址为 0,chars 变量地址为 4,d 变量地址为 8。
总结一下,C 语言转化成汇编语言时发生了什么样的变化:C 语言的变量名成了汇编语言的标号,C 语言的变量对应的空间变成了汇编语言.byte、.word 之类的定义数据操作符。最终,汇编器会根据.byte、.word 分配内存空间。
C语言表达式
了解下C语言是怎样把各种表达式转换成对应的汇编语言的。
举例:
int add()
{
//定义三个局部整形变量
int a, b, c;
//赋值表达式
a = 125;
b = 100;
//运算表达式
c = a + b;
//返回表达式
return c;
}
直接看 GCC 编译器生成的汇编代码。GCC 在编译代码时我加了“-O0”,这表示让 GCC 不做代码优化,如下所示:
add:
addi sp,sp,-32
sw s0,28(sp)
addi s0,sp,32
li a5,125
sw a5,-20(s0)
li a5,100
sw a5,-24(s0)
lw a4,-20(s0)
lw a5,-24(s0)
add a5,a4,a5
sw a5,-28(s0)
lw a5,-28(s0)
mv a0,a5
lw s0,28(sp)
addi sp,sp,32
jr ra
在栈中分配变量的内存空间、给变量赋值、进行运算、处理返回值、回收栈中分配的空间、返回。
首先看看 C 语言中的“int a,b,c;”,这是三个局部变量。在 C 语言中局部变量是放在栈中的,这里就是给 a、b、c 这三个变量在栈中分配变量的内存空间,对应的代码如下所示:
# int a,b,c;
addi sp,sp,-32 #把栈指针寄存器减去32,相当于在栈中分配了32字节的空间
sw s0,28(sp) #首先把s0寄存器存放在(sp+28)的内存空间中
addi s0,sp,32 #然后把s0寄存器设为原来sp寄存器的值
上述代码通过减去 sp 寄存器的值,在栈中分配了内存空间。因为栈是由高地址内存空间向低地址内存空间生长的,所以分配栈内存空间是减去一个值。
接着来看看 C 语言中的“a=125;b=100;”,这两行代码就是给变量赋值,也可以叫做赋值表达式,对应的汇编代码如下所示:
# a=125;b=100;
li a5,125 #125加载到a5寄存器中
sw a5,-20(s0) #把a5寄存器储存到(s0-20)的内存空间中,即栈中
li a5,100 #100加载到a5寄存器中
sw a5,-24(s0) #把a5寄存器储存到(s0-24)的内存空间中,即栈中
已经看到了“=”赋值运算,被转化为机器的数据传输指令,即储存、加载和寄存器之间的传输指令。从 -20、-24 这些地址偏移量,我们可以推导出 a,b 两个整型变量各占 4 字节大小的空间。
然后,来看看 C 语言里“c = a + b;”这一行代码,它就是运算表达式,同时也赋值表达式,但运算表达式的优先级更高,对应的汇编代码如下所示:
#c=a+b;
lw a4,-20(s0) #把(s0-20)内存空间中的内容加载到a4寄存器中
lw a5,-24(s0) #把(s0-24)内存空间中的内容加载到a5寄存器中
add a5,a4,a5 #a4寄存器加上a5寄存器的结果送给a5寄存器
sw a5,-28(s0) #把a5寄存器储存到(s0-28)的内存空间中,即栈中
C 语言中的加法运算符被转化成了机器的加法指令,运算表达式中的变量放在寄存器中,就成了加法指令的操作数。但是运算结果也被放在寄存器中,而后又被储存到内存中了。
最后,来看看 C 语言中“return c;”这一行代码,也就是返回表达式。对应的汇编代码如下所示:
#return c;
lw a5,-28(s0) #把(s0-28)内存空间中的内容加载到a5寄存器中
mv a0,a5 #a5寄存器送给a0寄存器,作为返回值
lw s0,28(sp) #恢复s0寄存器
addi sp,sp,32 #把栈指针寄存器加上32,相当于在栈中回收了32字节的空间
jr ra #把ra寄存器送给pc寄存器实现返回
从上述代码块可以看到,先把 c 变量加载到 a5 寄存器中,又把 a5 寄存器送给了 a0 寄存器。
在语言调用标准中,a0 寄存器是作为返回值寄存器使用的,return 语句是流程控制语句,它被转换为机器对应的跳转指令,即 jr 指令。jr 指令会把操作数送给 pc 寄存器,这样就能实现程序的跳转。
C语言流程控制
通过流程控制,C 语言就能把程序的分支、循环结构转换成汇编语言。下面我们以 C 语言中最常用的 for 循环为例来理解流程控制。for 循环这个例子很有代表性,因为它包括了循环和分支,代码如下所示。
void flowcontrol()
{
//定义了整型变量i
int i;
for(i = 0; i < 5; i++)
{
;//什么都不做
}
return;
}
可以看到上述代码中,for 关键字后面的括号中有三个表达式。
开始第一步先执行的是第一个表达式:i = 0; 接着第二步,执行第二个表达式。如果表达式的运算结果为 false,就跳出 for 循环;然后到了第三步,执行大括号“{}”中的语句,这里是空语句,什么都不做;最后的第四步执行第三个表达式:i++,再回到第二步开始下一次循环。
来看下这四步对应的汇编程序,如下所示:
flowcontrol:
addi sp,sp,-32
sw s0,28(sp)
addi s0,sp,32 # int i 定义i变量
sw zero,-20(s0) # i = 0 第一步 第一个表达式
j .L2 # 无条件跳转到.L2标号处
.L3:
lw a5,-20(s0) # 加载i变量
addi a5,a5,1 # i++ 第四步 第三个表达式
sw a5,-20(s0) # 保存i变量
.L2:
lw a4,-20(s0) # 加载i变量
li a5,4 # 加载常量4
ble a4,a5,.L3 # i < 5 第二步 第二个表达式 如果i <= 4就跳转.L3标号,否则就执行后续指令,跳出循环
lw s0,28(sp) # 恢复s0寄存器
addi sp,sp,32 # 回收栈空间
jr ra # 返回
为什么代码的注释中没有看到第三步的内容?这是因为我们写了空语句,编译器没有生成相应的指令。一般 CPU 会提供多种形式的跳转指令,来实现程序的流程控制
C 语言正是用了这些跳转、条件分支指令,才实现了如 if、for、while、goto、return 等程序流程控制逻辑。
C语言函数
了解一下 C 语言是怎么把函数转换成汇编语言的。
函数是C语言中非常重要的组成部分,要用 C 语言完成一个实际的功能,就需要至少写一个函数,可见函数就是 C 语言中对一段功能代码的抽象。一个函数就是一个执行过程,有输入参数也有返回结果(根据需要可有可无),可以调用其它函数,也被其它函数调用。
用函数验证下:
//定义funcB
void funcB()
{
return;
}
//定义funcA
void funcA()
{
//调用funcB
funcB();
return;
}
上述代码中定义了 funcA、funcB 两个函数,函数 funcA 调用了函数 funcB,而函数 funcB 是个空函数,什么也不做。
直接看它们的汇编代码,如下所示:
funcB:
addi sp,sp,-16
sw s0,12(sp) #储存s0寄存器到栈中
addi s0,sp,16
nop
lw s0,12(sp) #从栈中加载s0寄存器
addi sp,sp,16
jr ra #函数返回
funcA:
addi sp,sp,-16
sw ra,12(sp)
sw s0,8(sp) #储存ra,s0寄存器到栈中
addi s0,sp,16
call funcB #调用funcB函数
nop
lw ra,12(sp) #从栈中加载ra,s0寄存器
lw s0,8(sp)
addi sp,sp,16
jr ra #函数返回
从上面的汇编代码可以看出,函数就是从一个标号开始到返回指令的一段汇编程序,并且 C 语言中的函数名就是标号,对应到汇编程序中就是地址。
即使是什么也不做的空函数,C 语言编译器也会把它翻译成相应的指令,分配栈空间,保存或者恢复相应的寄存器,回收栈空间,这相当于一个标准的代码模板。
其中的 call 其实完成了两个动作:一是把 call 下一条指令的地址保存到 ra 寄存器中;二是把后面标号地址赋值给 pc 寄存器,实现程序的跳转。由于被跳转的程序段最后会执行 jr ra,即把 ra 寄存器赋值给 pc 寄存器,然后再跳转到 call 指令的下一条指令开始执行,这样就能实现函数的返回。
C语言调用规范
现在来探讨另一个问题,就是一个函数调用另一个函数的情况,而且这两个函数不是同一种语言所写。
比如:
在汇编语言中调用 C 语言,或者反过来在 C 语言里调用汇编语言。这些情况要怎么办呢?这时候就需要有一种调用约定或者规范。
这个规范有什么用呢?CPU 中的一些寄存器有特定作用的,自然不能在函数中随便使用。即使用到了也要先在栈里保存起来,然后再恢复。
这就引发了三个问题:一是需要规定好寄存器的用途;二是明确哪些寄存器需要保存和恢复;第三则是规定函数如何传递参数和返回值,比如用哪些寄存器传递参数和返回值。
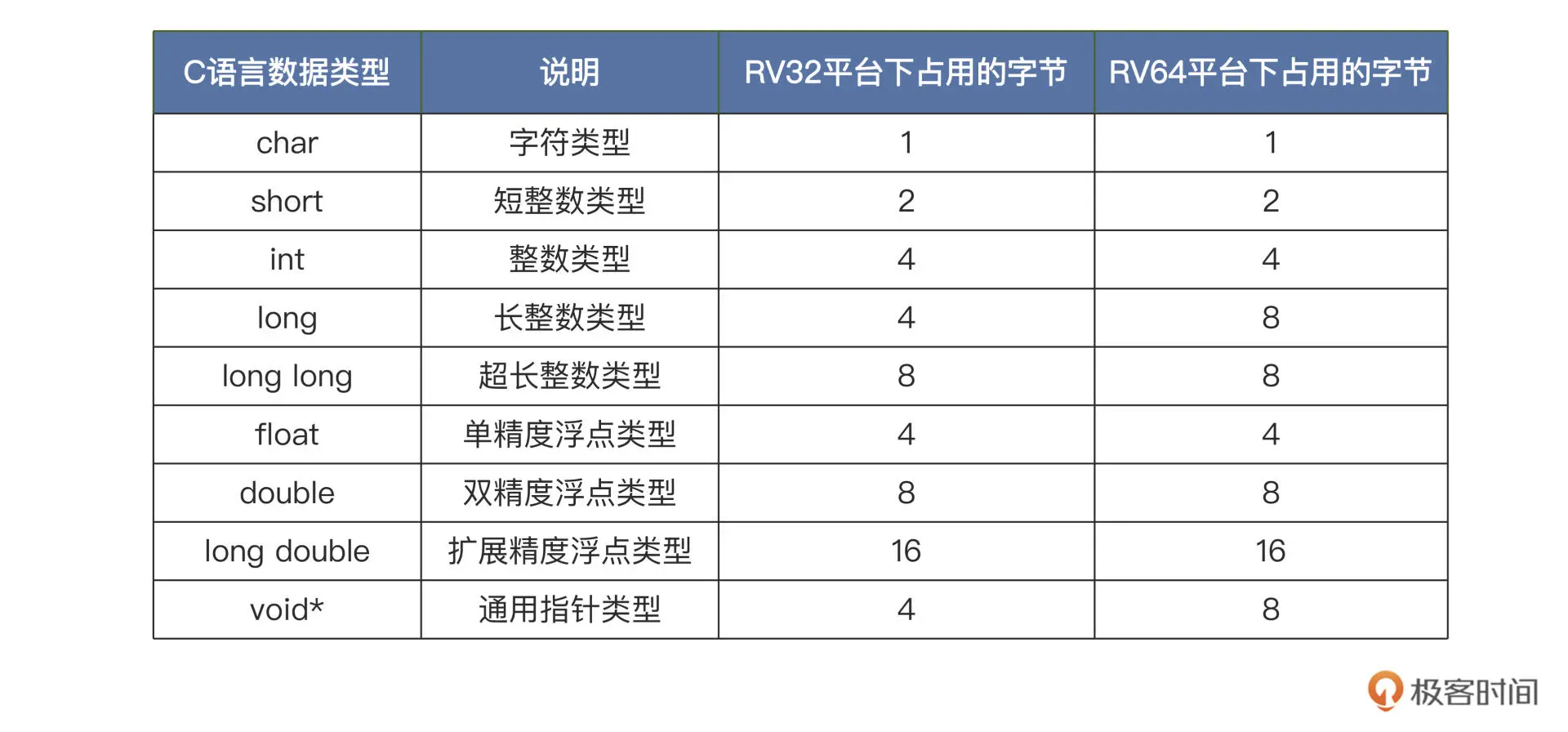
首先看一下,C 语言下的数据类型在 RISC-V 平台下所占据内存的大小,这也是调用规范的一部分,如下表:
下面我们结合实例来理解。我们先来写一段汇编代码和 C 代码,用汇编代码调用 C 函数,它们属于不同的文件,这些文件我已经在工程里给你准备好了。
首先,汇编代码如下:
.text //表明下列代码放在text段中
.globl main //导出main符号,链接器必须要找的到main符号
main:
addi sp,sp,-16
sw s0,12(sp) //保存s0寄存器
addi s0,sp,16
call C_function //调用C语言编写的C_function函数
li a0,0 //设置main函数的返回值为0
lw s0,12(sp) //恢复s0寄存器
addi sp,sp,16
jr ra //返回
这段代码主要处理了栈空间,保存了 s0 寄存器,然后调用了 C 语言编写的 C_function 函数,该函数我放在了 main_c.c 文件中,如下所示:
#include "stdio.h"
void C_function()
{
printf("This is C_function!\n");
return;
}
运行结果:
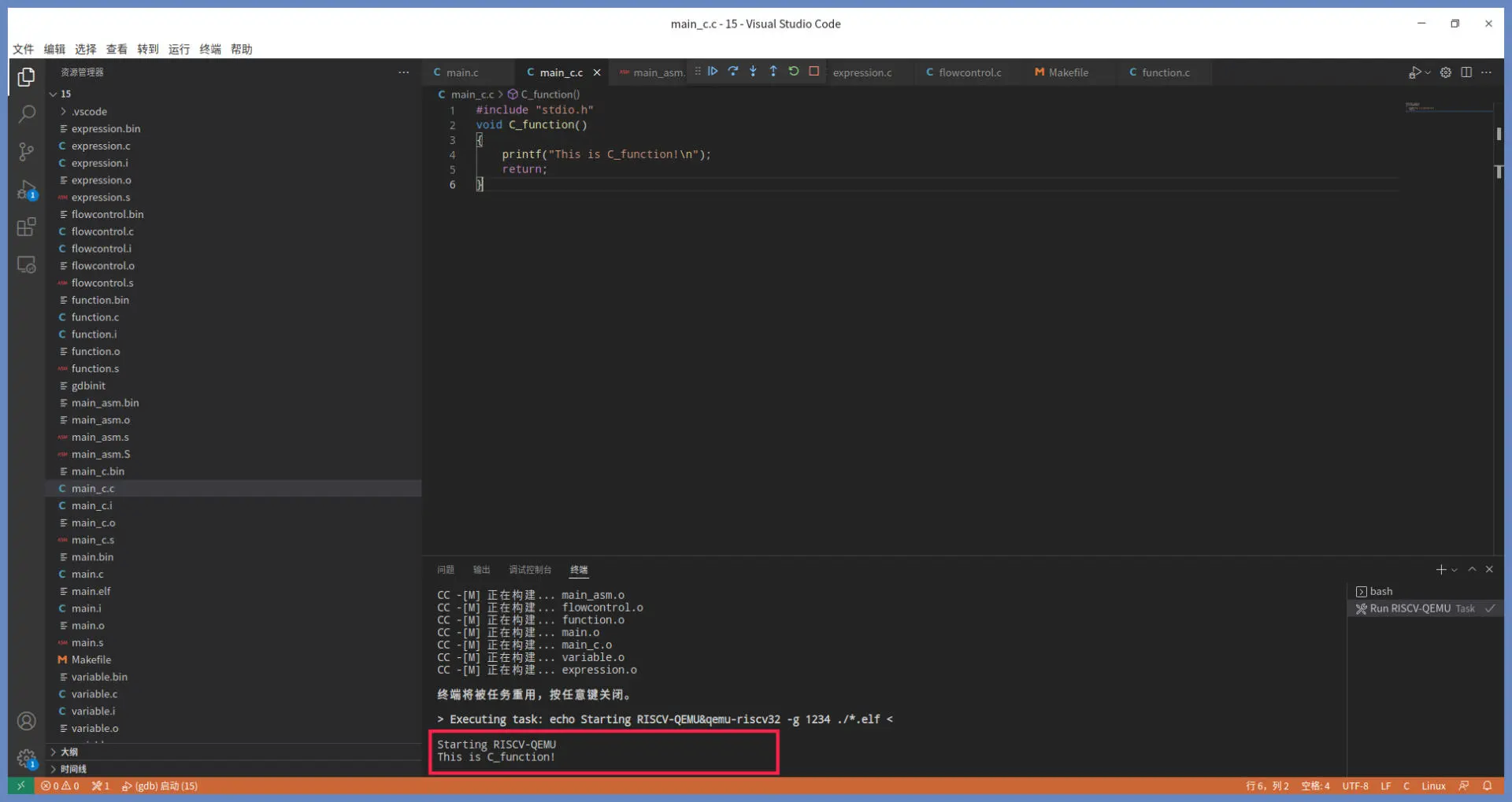
看到代码运行了,打印出了 This is C_function!,而且没有出现任何错误,这说明我们通过汇编代码调用 C 函数成功了
以上代码的功能很简单,很多寄存器没有用到,所以并没有保护和恢复相应的寄存器。在复杂的情况下,调用者函数应该保存和恢复临时寄存器:t0t6(整数寄存器),ft0ft11(浮点寄存器)。被调用者函数应该保存和恢复的寄存器:s0s11(整数寄存器),fs0fs11(浮点寄存器)。
现在只剩最后一个问题了,C 语言函数有参数和返回值。如果没有相应规范,一个 C 语言函数就不知道如何给另一个 C 语言函数传递参数,或者接收它的返回值。
同样用代码来验证一下,如下所示:
int addtest(int a, int b, int c,int d, int e, int f, int g, int h, int i)
{
return a + b + c + d+ e + f + g + h + i;
}
void C_function()
{
int s = 0;
s = addtest(1,2,3,4,5,6,7,8,9);
printf("This is C_function! s = %d\n", s);
return;
}
这段代码很简单,为了验证参数的传递,我们给 addtest 函数定义了 9 个参数,在 C_function 函数中调用它,并打印出它的返回值。
直接看看它生成的汇编代码,如下所示:
addtest:
addi sp,sp,-48
sw s0,44(sp)
addi s0,sp,48 #让s0变成原sp的值
#依次将a0~a7,8个寄存器放入栈中
sw a0,-20(s0)
sw a1,-24(s0)
sw a2,-28(s0)
sw a3,-32(s0)
sw a4,-36(s0)
sw a5,-40(s0)
sw a6,-44(s0)
sw a7,-48(s0)
#从栈中加载8个整型数据相加
lw a4,-20(s0)
lw a5,-24(s0)
add a4,a4,a5
lw a5,-28(s0)
add a4,a4,a5
lw a5,-32(s0)
add a4,a4,a5
lw a5,-36(s0)
add a4,a4,a5
lw a5,-40(s0)
add a4,a4,a5
lw a5,-44(s0)
add a4,a4,a5
lw a5,-48(s0)
add a4,a4,a5
#从栈中加载第9个参数的数据,参考第4行代码
lw a5,0(s0)
add a5,a4,a5
#把累加的结果放入a0寄存器,作为返回值
mv a0,a5
lw s0,44(sp)
addi sp,sp,48 #恢复栈空间
jr ra #返回
C_function:
addi sp,sp,-48
sw ra,44(sp)
sw s0,40(sp)
addi s0,sp,48
sw zero,-20(s0)
li a5,9
sw a5,0(sp) #将9保存到栈顶空间中
li a7,8
li a6,7
li a5,6
li a4,5
li a3,4
li a2,3
li a1,2
li a0,1 #将1~8,加载到a0~a7,8个寄存器中,作为addtest函数的前8个参数
call addtest #调用addtest函数
sw a0,-20(s0) #addtest函数返回值保存到s变量中
lw a1,-20(s0) #将s变量作为printf函数的第二个参数
lui a5,%hi(.LC0)
addi a0,a5,%lo(.LC0)
call printf
nop
lw ra,44(sp)
lw s0,40(sp)
addi sp,sp,48 #恢复栈空间
jr ra #返回
根据上面的代码,总结一下,C 语言函数用 a0~a7 这个 8 个寄存器,传递了一个函数的前 8 个参数。注意如果是浮点类型的参数,则使用对应的浮点寄存器 fa0~fa7,从第 9 个参数开始依次存放在栈中, 而函数的返回值通常放在 a0 寄存器中。
小结
C 语言变量经过编译器的加工,其变量名变成了汇编语言中的标号,也就是地址。变量空间由汇编语言中.byte、.word 等操作符分配空间,有的空间存在于二进制文件中,有的空间需要 OS 加载程序之后再进行分配。
接着是 C 语言表达式,C 语言表达式由 C 语言变量和 C 语言运算符组成,C 语言运算符被转换成了对应的 CPU 运算指令。变量由内存加载到寄存器,变成了指令的操作数,一起完成了运算功能。
之后借助 for 循环这个例子,发现 C 语言函数会被编译器“翻译”成一段带有标号的汇编代码,里面包含了流程控制指令(比如跳转指令)和各种运算指令。这些指令能修改 PC 寄存器,使之能跳转到相应的地址上运行,实现流程控制。
最后讨论了 C 语言的调用规范。“没有规矩不成方圆”,调用规范解决了函数之间的调用约束,比如哪些寄存器由调用者根据需要保存和恢复,哪些寄存器由被调用者根据需要保存和恢复,函数之间如何传递参数,又如何接收函数的返回值等等的问题。