图像读取
1、Pillow(python图像处理库(Python Imaging Library),简称:PIL):参考
用途
- 图像档案
python图像库是图像存档和批处理应用程序的理想选择。可以使用该库创建缩略图、在文件格式之间转换、打印图像等- 图像显示
当前版本(7.0.0)包括tk PhotoImage 和BitmapImage接口,以及Windows DIB interface,他可以与pythonwin和其他基于windows的工具包一起使用
对于调试,还有一个show()方法将图像保存在磁盘,并调用外部显示实用程序- 图像处理
该库中包含了基本的图像处理模块,包括点操作、实用一组内置卷积核进行过滤以及颜色空间转换,还支持图像大小调整、旋转和任意放射变换;有一种柱状图方法可以让你从图像中提取一些统计数据,这可以用于自动增强对比度,并用于全局统计分析。
读取图像
python 图像库中最重要的类就是Image类,在具有相同名称的模块中定义。可以通过多种方式创建这个类的实例:从文件中加载图像、处理其他图像或从头创建图像。
从文件中加载图像,需要使用Image模块中的open()方法:
from PIL import Image
image = Image.open('./dataset/mchar_train/000000.png')
若成功,该函数返回Image对象,可以使用实例属性检查文件内容:
print(image.format,image.size,image.mode)

这个 format 属性标识图像的源。如果图像不是从文件中读取的,则将其设置为“无”。大小属性是包含宽度和高度(以像素为单位)的2元组。这个 mode 属性定义图像中带区的编号和名称,以及像素类型和深度。常用模式有灰度图像的“L”(亮度)、真彩色图像的“RGB”和预压图像的“CMYK”。
如果无法打开这个文件,便会引发IOError异常
这样有了Image类,可以使用该类定义的方法来处理和操作图像。
几何变换
PIL.Image类中包含的方法resize():重置图像大小,参数为一元组。rotate():图像以逆时针多少度进行旋转
重置图像大小
out = image.resize((128,128))
print(out.size)
out

旋转:
out = image.rotate(45)
out

要将图像旋转90度,可以使用rotate()方法或transpose()方法。后者还可以用于围绕其水平或垂直轴翻转图像
一种更通用的图像转换形式可以通过 transform() 方法
颜色空间变换
使用convert()方法
颜色空间的转换:
image.convert('L')

该库支持各种模式与‘L’(灰度)和‘rgb’模式之间的转换。要在其他模式之间转换,需要使用中间图像(通常是‘rgb’图像)
图像增强
1、过滤器
ImageFilter模块中包含许多预定义的图像过滤器,可用不filter()方法
from PIL import ImageFilter
image.filter(ImageFilter.CONTOUR)
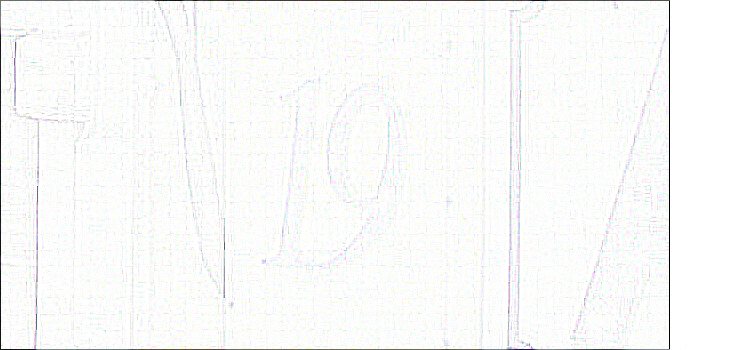
2、点操作
这个 point() 方法可用于转换图像的像素值(例如图像对比度操作)。在大多数情况下,需要一个参数的函数对象可以传递给这个方法。每个像素都根据该功能进行处理:
image.point(lambda i:i *5)
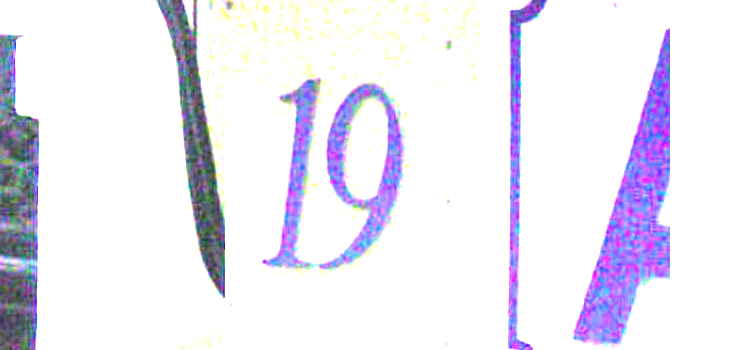
3、增强
对于更高级的图像增强,可以使用ImageEnhance模块。从图像创建增强对象快速尝试不同的设置
可通过此方法来调整对比度、亮度、颜色平衡和清晰度
(增加对比度)
from PIL import ImageEnhance
enh = ImageEnhance.Contrast(image)
enh.enhance(3)
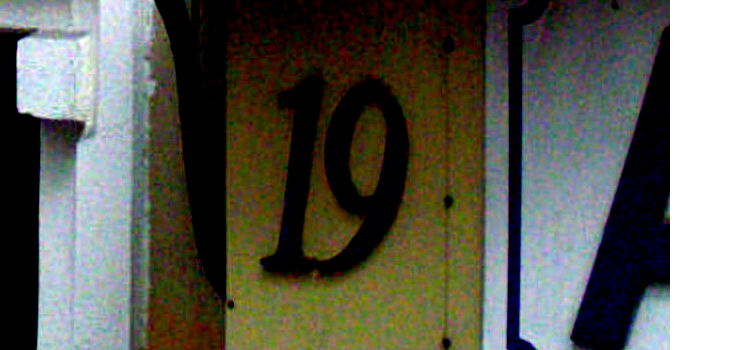
图像保存
image.save('./save_image.jpg','jpeg')

当然,pillow还有很多功能,暂时我们就介绍到这里。其他功能可具体查看参考链接
2、OpenCV(可参考:链接)
读取图像、并保存
img = cv2.imread('./dataset/mchar_train/000000.png')
cv2.namedWindow('test',cv2.WINDOW_NORMAL)
cv2.imshow("test",img)
k = cv2.waitKey(0)
if k == 27:
cv2.destroyAllWindows()
elif k == ord('s'):
cv2.imwrite('./test.png',img)
cv2.destroyAllWindows()
加载图片、显示图片、按下‘s’键保存退出,或按‘ESC’键退出不保存
cv2.imshow(filename)是在Jupyter之外显示的,并非在浏览器中显示,显示及保存效果如下:

为使图像显示到浏览器中,可使用matplotlib中的pyplot模块进行图像显示:
import matplotlib.pyplot as plt
plt.imshow(img,cmap='gray',interpolation='bicubic')
plt.xticks([]),plt.yticks([])#隐藏x,y轴上的数字
plt.show()

OpenCV包含了众多的图像处理的功能,OpenCV包含了只要与图像相关的操作。此外还内置了很多的图像特征处理算法,如关键点检测、边缘检测和直线检测等。
OpenCV官网:https://opencv.org/
OpenCV Github: https://github.com/opencv/opencv
OpenCV 扩展算法库:https://github.com/opencv/opencv_contrib
数据扩增方法
在赛题中需要对图像进行字符识别,需要完成对数据的读取操作,同时还得需要完成数据扩增(Data Augmentation)操作
1、数据扩增介绍
在深度学习中数据扩增方法非常重要,数据扩增可以增加训练集的样本,同时也可以缓解模型过拟合的情况,也给模型带来更强的泛化能力。

数据扩增为什么有用???
- 在深度学习模型的训练过程中,数据扩增是必不可少的环节。现有深度学习的参数非常多,一般的模型可训练的参数数量基本上达到万到百万级别,而训练集的样本又很难有那么多
- 其次数据扩增可以扩展样本空间,假设现在的分类模型需要对汽车进行分类,左边的是汽车A,右边为汽车B,如果不使用任何数据扩增方法,深度学习模型会从汽车车头的角度进行识别,而不是汽车具体的区别。
那有哪些数据扩增的方法呢?
数据扩增方法很多:从颜色空间、尺度空间到样本空间,同时根据不同任务数据扩增都有相应的区别
对于图像分类,数据扩增一般不会改变标签;
对于物体检测,数据扩增会改变物体坐标位置
对于图像分割,数据扩增会改变像素标签
2、常见的数据扩增方法
在常见的数据扩增方法中,一般会从图像颜色、尺寸、形态、空间和像素等角度进行交换。当然不同的数据扩增方法可以自由组合,得到更加丰富的数据扩增方法。以torchvision为例,常见的数据扩增方法包括:
- transforms.CenterCrop 对图像中间进行裁剪
- transforms.ColorJitter 对图像颜色的对比度、饱和度和零度进行变化
- transforms.FiveCrop 对图像四角和中心进行裁剪得到五分图像
- transforms.Grayscale 对图像进行灰度变化
- transforms.Pad 使用固定值进行像素填充
- transforms.RandomAffine 随机仿射变换
- transforms.RandomCrop 随机区域裁剪
- transforms.RandomHorizontalFlip 随机水平翻转
- transforms.RandomRotation 随机旋转
- transforms.RandomVerticalFlip 随机垂直翻转

本赛题任务需要对图像中的字符进行识别,因此对于字符图片不能进行翻转操作。比如字符6经过水平翻转就会变成9,改变了字符原本的含义。
2、常见的数据扩增库
- torchvision
https://github.com/pytorch/vision
pytourch官方提供的数据扩增库,提供了基本的数据扩增方法,可以无缝与torch进行集成,但数据扩增方法种类较少,且速度中等 - imgaug
https://github.com/aleju/imgaug
imgaug是常用的第三方数据扩增库,提供了多样的数据扩增方法,且结合起来非常方便,速度较快 - albumentations
https://albumentations.readthedocs.io
是常用的第三方数据扩增库,提供了多样的数据扩增方法,对图像分类、语义分割、物体检测和关键点检测都支持,速度较快
Pytorch读取数据
在pytorch中数据是通过Dataset进行封装,并通过DataLoader进行并行读取。
首先定义读取图像的Dataset
class SVHNDataset(Dataset):
def __init__(self,img_path,img_label,transform=None):
print('111')
self.img_path = img_path
self.img_label = img_label
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self,index):
print('222')
img = Image.open(self.img_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
#原始SVHN中类别10为0
lbl = np.array(self.img_label[index],dtype = np.int)
print('aaa'+str(lbl))
lbl = list(lbl) + (5 - len(lbl)) * [10]
print('bbb'+str(lbl))
return img,torch.from_numpy(np.array(lbl[:5]))
def __len__(self):
print('333')
return len(self.img_path)
torch.utils.data
class torch.utils.data.Dataset
表示Dataset的抽象类。所有其他数据集都应该进行子类化。所有子类应该override len和getitem,前者提供了数据集的大小,后者支持整数索引,范围从0到len(self)
参考:Pytorch中文文档
在python中所有以__双下划线包起来的方法,统称为“魔法方法”,比如接触最多的__init__方法
构造自定义容器(Container)
在python中,常见的容器类型有:dict、tuple、list、string
其中tuple、string是不可变容器,dict、list是可变容器
如果要自定义不可变容器类型,只需要定义len和getitem方法
如果要自定义可变容器类型,还需要在不可变容器的基础上增加定义setitem和delitem
如果还希望自定义数据结构支持“可迭代”,还需要定义iter
- len(self)
返回数值类型,以表示容器的长度,该方法在可变容器和不可变容器中必须实现。可直接通过len(data)进行访问- getitem(self,key)
当执行self[key]的时候,就调用了该方法。该方法在可变容器和不可变容器中都必须实现
调用的时候,如果key的类型错误,该方法应该抛出TypeError;
如果没法返回key对应的数值时,该方法应该抛出ValueError。
参考:介绍Python的魔术方法 - Magic Method
对图像数据和对应标签进行读取
train_path = glob.glob('./dataset/mchar_train/*.png')
train_path.sort()
train_json = json.load(open('./dataset/mchar_train.json'))
train_lebel = [train_json[x]['label'] for x in train_json]
查看上述魔法函数的调用
data = SVHNDataset(train_path,train_lebel)
data[2]
print(len(data))

glob的介绍
glob模块是最简单的模块之一,内容非常少。用它可以查找符合特定规则的文件路径名。跟使用windows下的文件搜索差不多。查找文件只用到三个匹配符:"", "?", "[]"。""匹配0个或多个字符;"?"匹配单个字符;"[]"匹配指定范围内的字符,如:[0-9]匹配数字。
在读取过程中进行数据扩增:
train_path = glob.glob('../input/train/*.png')
train_path.sort()
train_json = json.load(open('../input/train.json'))
train_label = [train_json[x]['label'] for x in train_json]
print(len(train_path), len(train_label))
train_loader = torch.utils.data.DataLoader(
SVHNDataset(train_path, train_label,
transforms.Compose([
transforms.Resize((64, 128)),
transforms.RandomCrop((60, 120)),
transforms.ColorJitter(0.3, 0.3, 0.2),
transforms.RandomRotation(5),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])),
batch_size=40,
shuffle=True,
num_workers=10,
)
val_path = glob.glob('../input/val/*.png')
val_path.sort()
val_json = json.load(open('../input/val.json'))
val_label = [val_json[x]['label'] for x in val_json]
print(len(val_path), len(val_label))
val_loader = torch.utils.data.DataLoader(
SVHNDataset(val_path, val_label,
transforms.Compose([
transforms.Resize((60, 120)),
# transforms.ColorJitter(0.3, 0.3, 0.2),
# transforms.RandomRotation(5),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])),
batch_size=40,
shuffle=False,
num_workers=10,
)

- Dataset:对数据集的封装,提供索引方式的数据样本进行读取
- DataLoader:对Dataset进行封装,提供批量读取的迭代读取
加入DataLoader后,数据读取代码为:
train_path = glob.glob('../input/train/*.png')
train_path.sort()
train_json = json.load(open('../input/train.json'))
train_label = [train_json[x]['label'] for x in train_json]
train_loader = torch.utils.data.DataLoader(
SVHNDataset(train_path, train_label,
transforms.Compose([
transforms.Resize((64, 128)),
transforms.ColorJitter(0.3, 0.3, 0.2),
transforms.RandomRotation(5),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])),
batch_size=10, # 每批样本个数
shuffle=False, # 是否打乱顺序
num_workers=10, # 读取的线程个数
)
for data in train_loader:
break
当程序执行到下述代码时,程序报错:
for data in train_loader: break报错信息:
解决方案:
修改调用torch.utils.data.DataLoader()函数时的num_works参数,该参数官方API解释如下:**num_workers **(int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)该参数是指在进行数据集加载时,启用的线程数目。截止当前2018年5月9日11:15:52,如官方未解决该BUG,则可以通过修改num_works参数为 0 ,只启用一个主进程加载数据集,避免在windows使用多线程即可。

在加入DataLoader后,数据按照批次获取,每批次调用Dataset读取单个样本进行拼接。此时的数据格式为:

格式为:torch.size([10,3,64,128]),torch.size([10,6])
前者为图像文件,为batchsize * channel * height * width次序;后者为字符标签。