信息比较丰富的网站通常会以分页显示,在点“下一页”时,很多网站都采用了动态请求的方式,避免页面刷新。虽然大家都是ajax,但是从一些小的细节还是 可以区分优劣。一个小的细节是能否支持浏览器“后退”和“前进“键。本文讨论两种方法,让浏览器可以后退和前进,或者说让ajax就像重定向到新页面一样 拥有能够返回到上一页或者前进到下一页。
数据实现分页显示,最简单的做法是在网址后面加多个page的当数,点“下一页”时,让网页重定向到page+1的新地址。例如新浪的新闻网就 是这么做的,通过改变网址实现:index_1、index_2、index_3……。但是如果这个列表并不是页面的主体部分,或者页面的其它部分有很多 图片等丰富元素,例如导航是一个很大的slider,再使用这样的方式,整个页面会闪烁得厉害,并且很多资源得重新加载。所以使用ajax请求,动态改变 DOM。
但是普通的动态的请求不会使网址发生变化,用户点了下一页,或者点了第几页,想要返回到上一个页面时,可能会去点浏览器的返回键,这样就导致返回的时候不是返回到原先查看的页面了,而是上一个网址了。例如央视的新闻网就是这样的。下面从ajax请求开始说起,以一个完整的案例进行分析。
做了一个demo

首先,写一个请求:

//当前第几页
var pageIndex = 0;
//请求函数
function makeRequest(pageIndex){
var request = new XMLHttpRequest();
request.onreadystatechange = stateChange;
//请求传两个参数,一个是当前第几页,另一个是每页的数据条数
request.open("GET", "/getBook?page=" + pageIndex + "&limit=4", true);
request.send(null);
function stateChange(){
//状态码为4,表示loaded,请求完成
if(this.readyState !== 4 ){
return;
}
//请求成功
if(this.status >= 200 && this.status < 300 || this.status === 304){
var books = JSON.parse(request.responseText);
renderPage(books);
}
}
//避免内存泄漏
request = null;
}
拿到数据后进行渲染:
function renderPage(books){
var bookHtml =
"<table>" +
" <tr>" +
" <th>书名</th>" +
" <th>作者</th>" +
" <th>版本</th>" +
" </tr>";
for(var i in books){
bookHtml +=
"<tr>" +
" <td>" + books[i].book_name + "</td>" +
" <td>" + books[i].author + "</td>" +
" <td>" + books[i].edition + "</td>" +
"</tr>";
}
bookHtml += "</table>";
bookHtml +=
"<button>上一页</button>" +
"<button onclick='nextPage();'>下一页</button>";
var section = document.createElement("section");
section.innerHtml = bookHtml;
document.getElementById("book").appendChild(section);
}
这样一个基本的ajax请求就搭起来了,然后再响应“下一页”按钮:
function nextPage(){
//将页面的index加1
pageIndex++;
//重新发请求和页面加载
makeRequest(pageIndex);
}
到此,如果不做任何处理的话,就不能够发挥浏览器返回、前进按钮的作用。
如果能够检测用户点了后退、前进按钮的话,就可以做些文章。h5就是增加了这么一个事件window.onpopstate,当用户点击那两个按钮就会触 发这个事件。但是光检测到这个事件是不够的,还得能够传些参数,也就是说返回到之前那个页面的时候得知道那个页面的pageIndex。通过 history的pushState方法可以达到这个目的,pushState(pageIndex)将当前页的pageIndex存起来,再返回到这个 页面时获取到这个pageIndex。pushState的参数如下:
window.history.pushState(state, title, url);
其中state为一个object{},用来存放当前页面的数据,title标题没有多大的作用,url为当前页面的url,一旦更改了这个url,浏览器地址栏的地址也会跟着变化。
于是,在请求下一页数据的nextPage函数里面,加多一步操作:
function nextPage(){
pageIndex++;
makeRequest(pageIndex);
//存放当前页面的数据
window.history.pushState({page: pageIndex}, null, window.location.href);
}
然后监听popstate事件:
//如果用户点击返回或者前进按钮
window.addEventListener("popstate", function(event){
var page = 0;
//由于第一页没有pushState,所以返回到第一页的时候是没有数据的,因此得做下判断
if(event.state !== null){
page = event.state.page;
}
makeRequest(page);
pageIndex = page;
});
state数据通过event传进来,这样就可以得到pageIndex。

但是,这样实现还有问题,在第二页的时候如果刷新页面的话,会发生错乱,如下所示:首先点下一页到第二页,然后刷新页面,出现第一页,再点下一页,出现第二页,点返回时出现问题,显示还是第二页,不是期望的第一页,直到再次点返回时才是第一页:

从右边的工具栏可以发现,点第一次返回的时候获取到的pageIndex仍然是1。对于这种情况,需要分析history模型,如下所示:
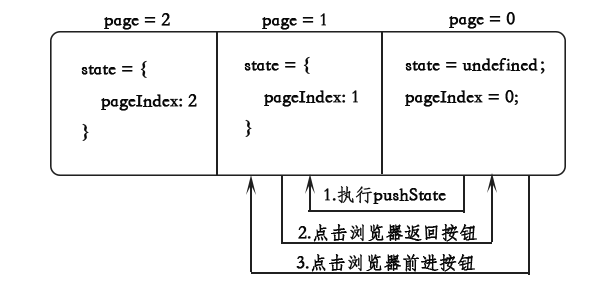
可以理解为对history的操作,浏览器有一个队列,用来存放访问的记录,包括每个访问的网址还有state数据。一开始,队列的首指针指向page = 0的位置,点下一页时,执行了pushState,在这个队列插入了一个元素,同时通过pushState操作记录了这个元素的url和state数据。 在这里可以看出,pushState的操作最重要的作用还是给history队列插入元素,这样浏览器的后退按钮才不是置灰的状态,其次才是上面说的存放 数据。点后退的时候,队首指针后退一步指向page = 0的位置,点前进时又前进指向page = 1的位置。
如果在page = 1的位置刷新页面,模型是这个样子的:
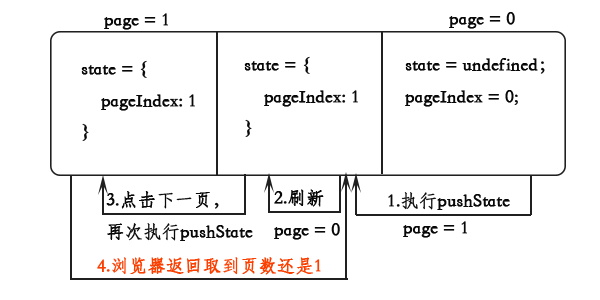
在第2步刷新的时候,页面的pageIndex又恢复成默认值0,所以page = 0,显示第一页数据,但是history所用的队列并没有改变。然后再点下一页时,又给这个队列push了一个元素,这个队列就有两个pageIndex 为1的元素,所以必须得两次返回才能回到page = 0的位置,也就是上面说的错乱的情况。
根据上面的分析,这样的实现是有问题的,一但用户不是在page = 0的位置刷新页面,就会出现需要点多次返回按钮才能够回到原先的页面。
所以得在刷新的时候,把当前页的state数据更新一下,用replaceState,替换队列队首指针的数据,也就是当前页的数据。方法是页面初始化时replace一下:
window.history.replaceState({page: pageIndex /*此处为0*/}, null, window.location.href);
这样模型就变成:
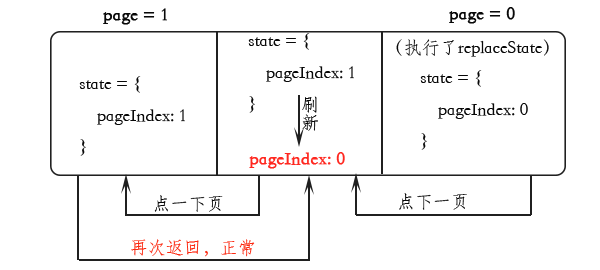
但其实用户刷新的时候更希望的是还是显示当前页,而不是回到第一页。一个解决办法是用当前页的window.history.state数据,这个属性浏览器支持得比较晚。在页面初始化时设置pageIndex时就从history.state取:
var pageIndex = window.history.state === null ? 0 : window.history.state.page;
safari里面的history.state是最近执行pushState传入的数据,因此这个办法在chrome/firefox里面行得通,但是safari行不通。
第二种办法是借助h5的localStorage存放当前页数:
//页面初始化,取当前第几页先从localStorage取
var pageIndex = window.localStorage.pageIndex || 0;
function nextPage(){
//将页面的index加1,同时存放在localStorage
window.localStorage.pageIndex = ++pageIndex;
//重新发请求和页面加载
makeRequest(pageIndex);
window.history.pushState({page: pageIndex}, null, window.location.href);
}
window.addEventListener("popstate", function(event){
var page = 0;
if(event.state !== null){
page = event.state.page;
}
makeRequest(page);
//点击返回或前进时,需要将page放到localStorage
window.localStorage.pageIndex = page;
});
将页面中所有改变pageIndex的地方,同时放到localStorage。这样刷新页面的时候就可以取到当前页的pageIndex。
上面的方法都是将pageIndex放到了state参数里,还有一种方法是把它放到第三个参数url里,也就是说通过改变当前页网址的办法。pageIndex从网址里面取:
1 //当前第几页
2 var pageIndex = window.location.search.replace("?page=", "") || 0;
3 function nextPage(){
4 //将页面的index加1
5 ++pageIndex;
6 //重新发请求和页面加载
7 makeRequest(pageIndex);
8 window.history.pushState(null, null, "?page=" + pageIndex);
9 }
注意,一旦执行了第8行的pushState,当前网址的地址就会发生变化。
有一点需要注意的是,window.history.length虽然返回是的当前队列的元素个数,但不代表history本身就是那个队列,通过不同浏览器的对history[i]的输出:

可以看到history是一个数组,它的作用是让用户拿到history.length,当前的长度,但是填充的内容是不确定的。
除了使用history之外,还有借助hash的方法,网易新闻就是使用了这样的方法:
1 //当前第几页
2 var pageIndex = window.location.hash.replace("#page=", "") || 0;
3 function nextPage(){
4 makeRequest(pageIndex);
5 window.location.hash = "#page=" + pageIndex;
6 }
7 window.addEventListener("hashchange", function(){
8 var page = window.location.hash.replace("#page=", "") || 0;
9 makeRequest(page);
10 });
关于支持性,参考caniuse网站:history IE10及以上支持,hashchange的支持性较好,IE8及以上都支持。
虽然hashchange的支持性较好,但是history的优点是可以传数据。对一些复杂的应用可能会有很大的发挥作用,同时history支持back/go操作。