背景:
在一个数据库中存在A表与B表,但AB两个表按目前架构边界划分的话,是属于两个组织下的两个系统,导致相互之间有稳定性风险。为增强系统稳定性,进行存储分离。准备将B表的所有数据,迁移到新库中。
可能存在的问题:
1、由于原来的AB表在一个数据库中,代码中可以用事务控制两个表,迁移后不支持本地事务,如何解决?
2、原来是一个数据源,现在分为两个数据源,如何解决?
3、由于这两个表,是核心链路的核心数据,迁移过程无法停机迁移,如何保证安全稳定的不停机平滑迁移?
4、迁移过程如何保证数据一致?
迁移准备工作:
1、表准备
2、事务支持需要找相关人员确认,应对事务解耦后的方案
3、数据源梳理
集群迁移方案:
一、整体方案
DBA线上创建新数据库,同步原数据库数据;
1、全量同步方案: 源库导出数据进行全量初始化,dba通过多线程抽取源数据进行插入
2、增量同步方案: 记录全量时刻的binlog位点,通过binlog进行数据增量同步 增量数据进行数据一致性校验,通过工具进行数据校验;
3、系统中配置多个数据源,涉及到的表具有开关;可进行双写、指定写新库/老库,指定读主库/新库
4、代码上线 ,上线后写老库,读老库;不做任何变更
5、增量数据此时已经开启;
6、选取流量低峰期打开双写开关,观察写新库是否存在报错,且对整体的tps是否有影响;大约5min左右
7、关闭增量数据同步,观察30min,无异常报错,且数据正常写入,只保留双写。 此时数据校验进行新增数据校验;如果产生问题,进行开关回切,增量binlog继续打开
8、观察业务有无异常,跑一周时间,观察数据是否有告警
9、切换读新库,跑一周时间
10、无异常,选取流量低峰期进行 大数据切换读新库备份机、binlog切换读新库备份机,此时会有一小段时间的重复数据产生,下游数据需要自己保证幂等性。
11、关闭老库写操作
12、跑一段时间,无问题,完全走新库
二、具体流程图
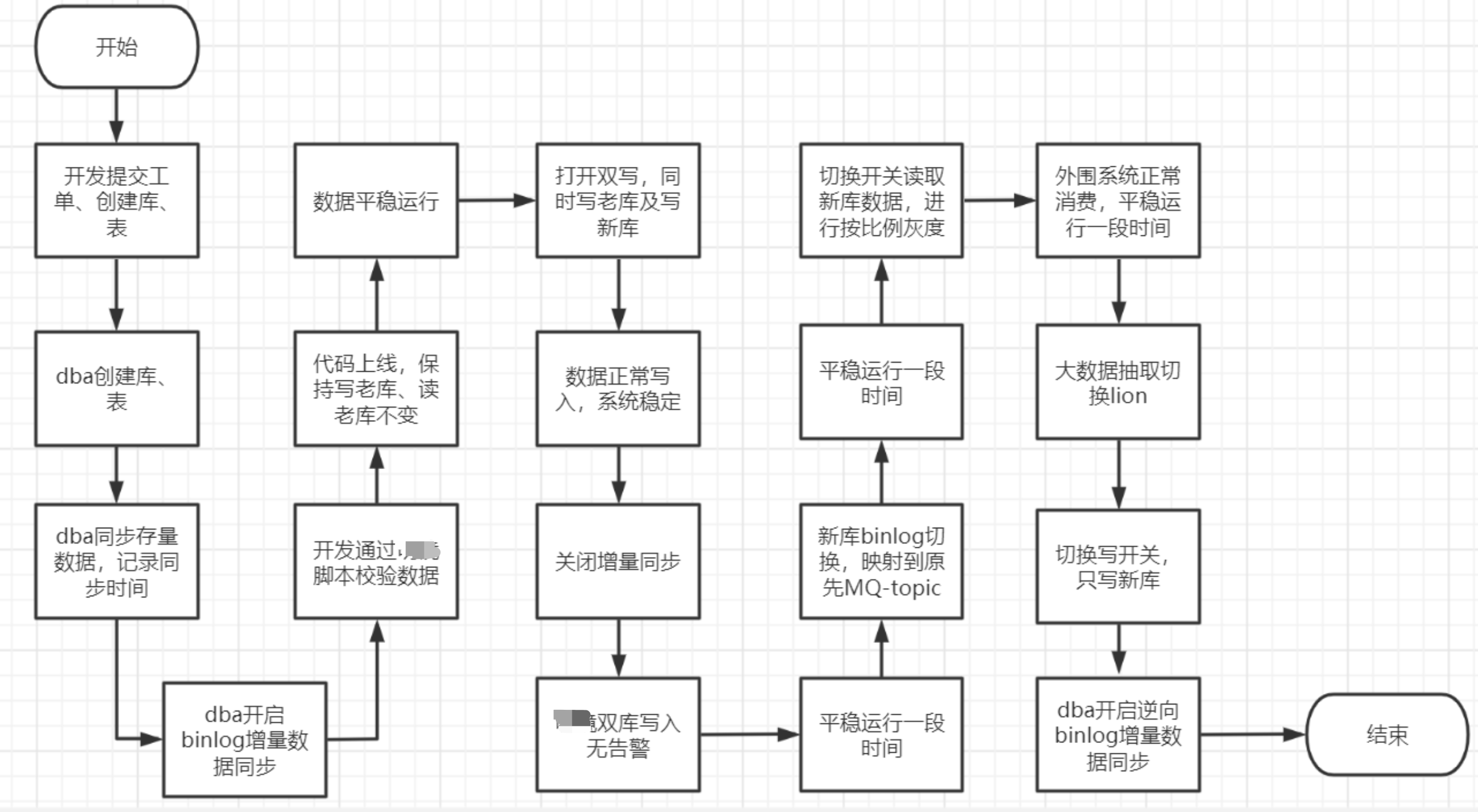
注意点:
原数据库的binlog事件,需要提前接入;binlog监听维度的切换是在代码上线之前即可监听,外围需要保证幂等性;
大数据是否有抽取数据,需要确认;切换完成后,需要抽取新的库数据; 大数据进行抽数需要进行lion变更;
确认update是否会进行覆盖,可能存在覆盖,但是两者应该最终一致
迁移过程可控,问题可发现;老库写入确保无问题
binlog数据消费可能早于新库写入,因此切换读流量前需要进行binlog切换
乐观锁多版本更新,系统异常可感知,业务异常不可感知,乐观锁更新双写情况下保证最终一致性
查询业务流量做比对
风险点:
由于连接修改在mapper层面,防止有mapper.method方法覆盖不全导致的写数据丢失
需要增加比对数据任务,进行数据比对
需要增加同步数据任务,防止切换过程数据丢失,进行数据弥补
数据比对、数据修复脚本、告警:
通过脚本(增量数据比对)
job手工比对(存量数据的比对)
修复数据job(指定表,指定更新时间范围)—相当于后门