1 拷贝
1.1 浅拷贝
#浅拷贝在内存中只额外创建第一层数据
import copy
D = {'k1': 'he', 'k2': 123, 'k3': ['morra', 456]}
n2 = copy.copy(D) # 拷贝方式一
n2 = dict(D) # 拷贝方式二
# 对于列表来说还有如下几种拷贝方式
L = [1, 2, [2, 3]]
n2 = L[:]
n2 = list[L]
n3 = [x for x in L] #通过列表推倒式创建
在使用浅拷贝时,对象内部的属性和内容仍然引用原始对象,这样的操作速度很快,而且节省内存。
1.2 深拷贝
#在内存中将所有的数据创建一份(最后一层数据除外,这是由python内部对字符串和数字类型的优化导致的)
import copy
n1 = {'k1': 'he', 'k2': 123, 'k3': ['morra', 456]}
n2 = copy.deepcopy(n1)
如果需要拷贝一些容器对象,还必须递归地拷贝其内部引用的对象。这种深拷贝操作会消耗相当的时间和内存。
2 函数参数传递
2.1 值传递
def func(b):
b = 'spam'
a = 3
func(a)
print(a) # 结果是3
以上的参数传递过程可简化为一下步骤:
a = 3
b = a
b = 'spam'
多个变量名引用了同一引用,也叫做"共享引用":
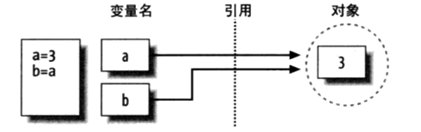
b = 'spam' #这个赋值运算改变的不是对象3,只是改变了变量a,而变量b并没有发生变化,所以上面的运行结果是3

所以我们一般说,str、int等不可变(immutable)对象的传递方式为值传递。
2.2 引用传递
引用传递就很好理解了:
def func(b):
b[0] = 'spam'
a = [3]
func(a)
print(a) # 结果是['spam']
对于list、dict这些书可变(mutable)对象而言,由于变量引用的是“对底层不可变数据的引用”,所以这些对象的传递方式往往是引用传递。