lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高
from lxml import etree
有时候在使用的时候:from lxml import etree时报错,没有etree这个库,这是因为有的lxml包中没有集成etree
解决方法:可以自己再选择安装带etree的lxml,我的Python是3.6,下载的etree是4.2.1
一个demo(先研究,在上代码)
主页大概这样子

发现文件内容都在 id =contentText 的div 的p 标签中
我们写代码 写个面试类
import requests from lxml import etree class Pymianshi(): def __init__(self,url): self.url=url pass
获取返回信息
def huoquurlnr(self): '''这个方法 是 请求,解析url,返回信息''' reqdata=requests.get(self.url) reqdata.encoding='gbk' return reqdata.text
解析文本
def jiexidata(self): '''这个方法是解析返回的信息,筛选需要的信息与文本''' listdata=[] data=self.huoquurlnr() xml=etree.HTML(data) xmldata=xml.xpath("//div[@id='contentText']/p/text()") xmldatalen=len(xmldata) #从 6 开始的原因是因为 前面都是无用的 for i in range(0,xmldatalen): xmldata[i] listdata.append(xmldata[i]) return listdata
写入txt (每次写入完毕提醒)
def worktxt(self): '''这个方法表示写入成txt文档''' datas=self.jiexidata() for i in range(0,len(datas)): with open('python.txt','a',encoding='utf-8') as f: f.write(datas[i]+" ") print("已经完成")
调用
url='mianshiti/4064056.html' #python pym=Pymianshi(url=url) pym.worktxt()
存入txt 内容截图:
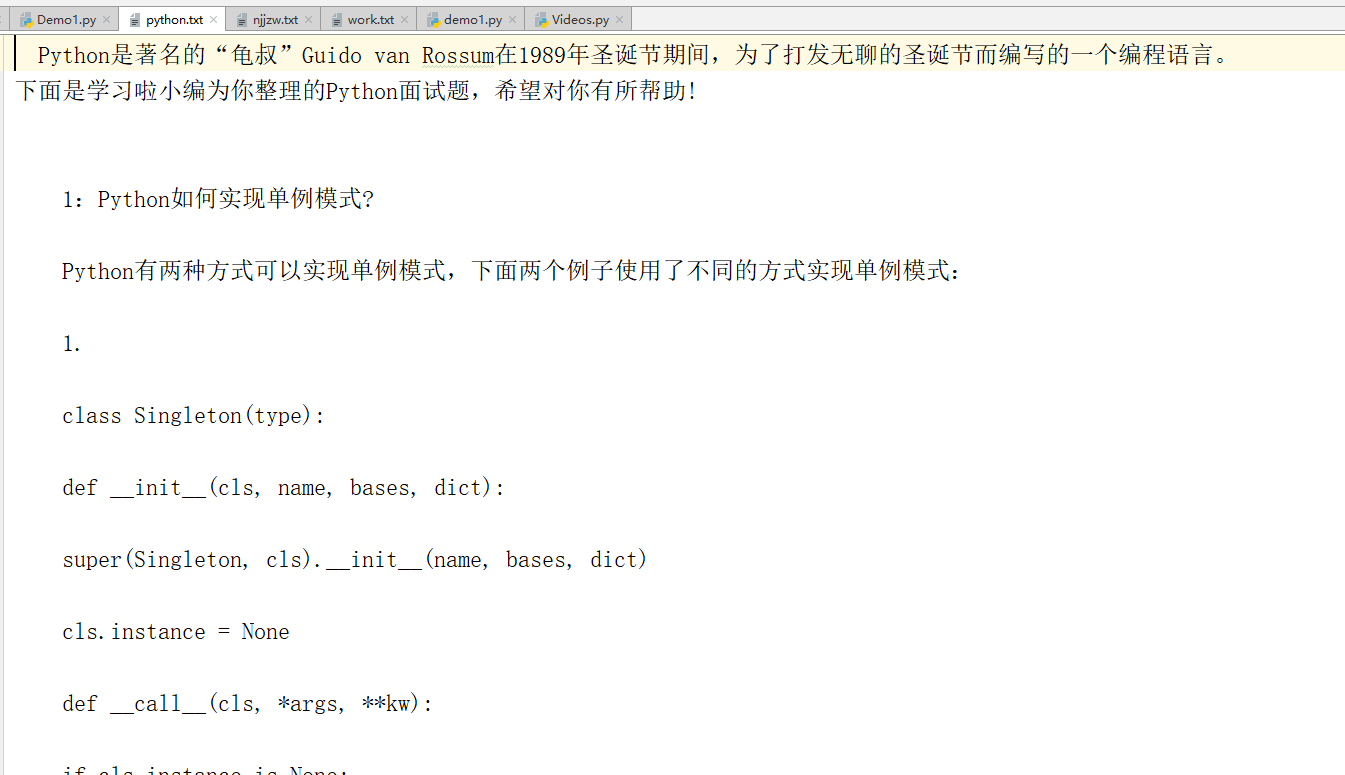
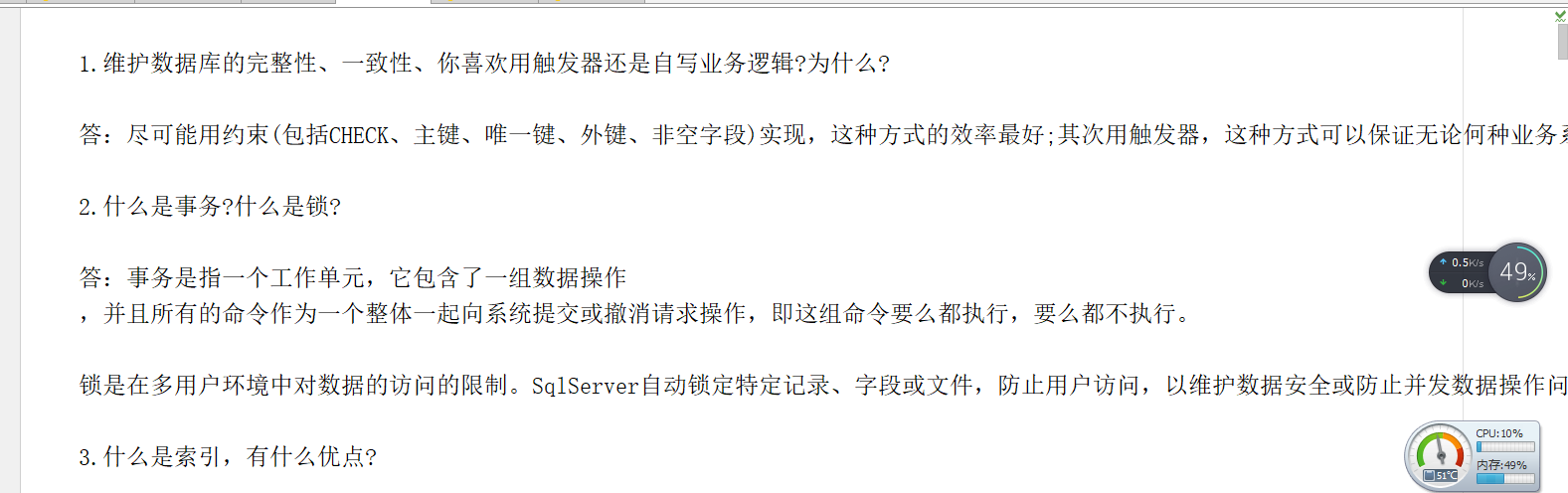

网站呢,为了引起不必要的纠纷,我已经把url修改,怕引起不必要的麻烦,需要的话,留个Email,我会把完整代码发给你(仅供学习交流)