一、什么是顺序表:
线性表的两种基本的实现模型:
1.将表中元素顺序地存放在一大块连续的存储区里,这样实现的表称为顺序表(或连续表)。在这种实现中,元素间的顺序关系由它们的存储顺序自然表示。
2.将表中元素存放在通过链接构造起来的一系列存储模块里,这样实现的表称为链接表,简称链表。
二、顺序表两种基本形式:

三、顺序表结构:

四、实现方式:
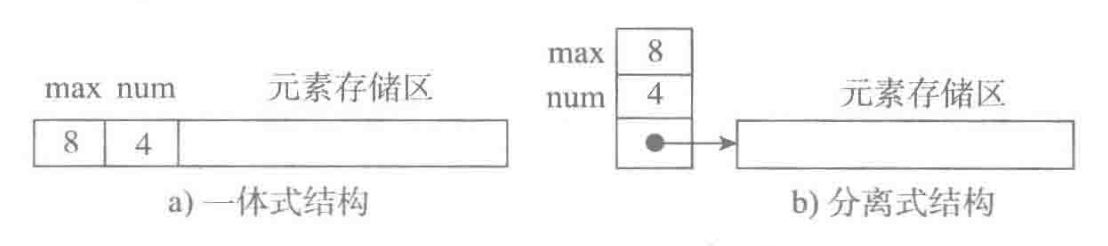
五、增加元素:
a. 尾端加入元素,时间复杂度为O(1)
b. 非保序的加入元素(不常见),时间复杂度为O(1)
c. 保序的元素加入,时间复杂度为O(n)
六、删除元素:
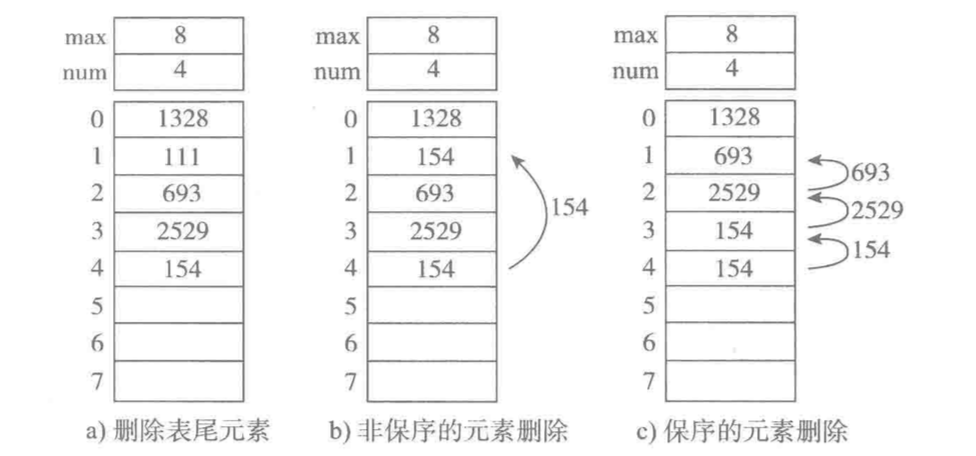
a. 删除表尾元素,时间复杂度为O(1)
b. 非保序的元素删除(不常见),时间复杂度为O(1)
c. 保序的元素删除,时间复杂度为O(n)
七、关于python中的list:(分离式的动态顺序表)
Python中的list和tuple两种类型采用了顺序表的实现技术,具有前面讨论的顺序表的所有性质。
tuple是不可变类型,即不变的顺序表,因此不支持改变其内部状态的任何操作,而其他方面,则与list的性质类似。
Python标准类型list就是一种元素个数可变的线性表,可以加入和删除元素,并在各种操作中维持已有元素的顺序(即保序),而且还具有以下行为特征:
-
基于下标(位置)的高效元素访问和更新,时间复杂度应该是O(1);
为满足该特征,应该采用顺序表技术,表中元素保存在一块连续的存储区中。
-
允许任意加入元素,而且在不断加入元素的过程中,表对象的标识(函数id得到的值)不变。
为满足该特征,就必须能更换元素存储区,并且为保证更换存储区时list对象的标识id不变,只能采用分离式实现技术。
在Python的官方实现中,list就是一种采用分离式技术实现的动态顺序表。这就是为什么用list.append(x) (或 list.insert(len(list), x),即尾部插入)比在指定位置插入元素效率高的原因。
在Python的官方实现中,list实现采用了如下的策略:在建立空表(或者很小的表)时,系统分配一块能容纳8个元素的存储区;在执行插入操作(insert或append)时,如果元素存储区满就换一块4倍大的存储区。但如果此时的表已经很大(目前的阀值为50000),则改变策略,采用加一倍的方法。引入这种改变策略的方式,是为了避免出现过多空闲的存储位置。